WebCompass: Towards Multimodal Web Coding Evaluation for Code Language Models
Pith reviewed 2026-05-10 04:36 UTC · model grok-4.3
The pith
WebCompass provides a multimodal benchmark for evaluating code language models on full web engineering lifecycles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
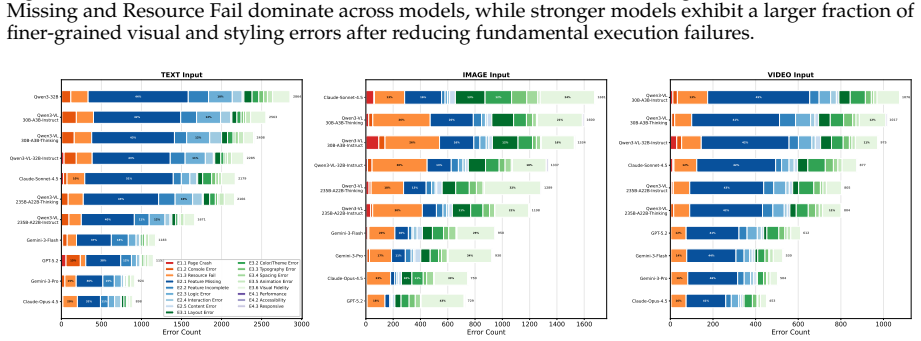
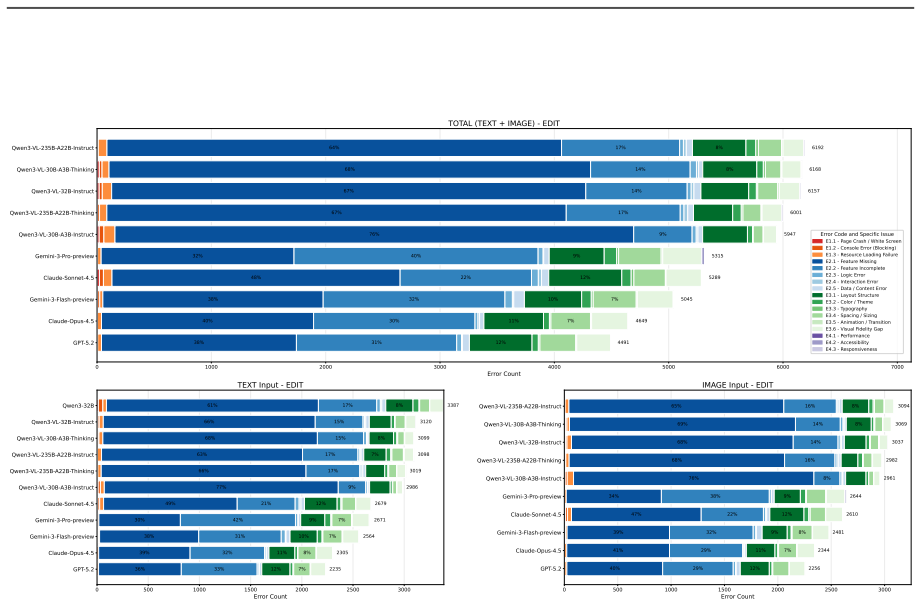
We introduce WebCompass, a multimodal benchmark that provides unified lifecycle evaluation of web engineering capability. It spans three input modalities (text, image, video) and three task types (generation, editing, repair), yielding seven task categories that mirror professional workflows. Instances cover 15 generation domains, 16 editing operation types, and 11 repair defect types, each at Easy/Medium/Hard levels. Evaluation adopts checklist-guided LLM-as-a-Judge for editing and repair, and Agent-as-a-Judge for generation that executes sites in a real browser, explores behaviors, and synthesizes test cases. Evaluations of models show closed-source models are stronger and more balanced,编辑
What carries the argument
The WebCompass benchmark with its seven task categories across modalities and the Agent-as-a-Judge protocol that autonomously tests generated websites in a browser using the Model Context Protocol to approximate human acceptance testing.
If this is right
- Closed-source models remain substantially stronger and more balanced in web coding tasks compared to open-source models.
- Editing and repair tasks show different difficulty profiles, with repair better preserving interactivity but being more challenging in execution.
- Aesthetics is the most persistent bottleneck, particularly for open-source models.
- Framework choice materially affects outcomes, with Vue consistently challenging while React and Vanilla/HTML perform more strongly depending on the task type.
Where Pith is reading between the lines
- Models trained with this benchmark in mind could develop better capabilities for iterative web development processes.
- The Agent-as-a-Judge approach might be extended to evaluate other interactive software outputs beyond websites.
- Future benchmarks in software engineering could adopt similar multimodal and lifecycle-spanning designs to better match real-world use.
Load-bearing premise
The LLM-as-a-Judge and Agent-as-a-Judge evaluation methods accurately measure quality in ways that match what human experts would accept in professional web engineering.
What would settle it
Conducting a study with human web developers rating the same set of model outputs and finding low agreement with the automated judge scores would challenge the benchmark's validity.
Figures

















read the original abstract
Large language models are rapidly evolving into interactive coding agents capable of end-to-end web coding, yet existing benchmarks evaluate only narrow slices of this capability, typically text-conditioned generation with static-correctness metrics, leaving visual fidelity, interaction quality, and codebase-level reasoning largely unmeasured. We introduce WebCompass, a multimodal benchmark that provides unified lifecycle evaluation of web engineering capability. Recognizing that real-world web coding is an iterative cycle of generation, editing, and repair, WebCompass spans three input modalities (text, image, video) and three task types (generation, editing, repair), yielding seven task categories that mirror professional workflows. Through a multi-stage, human-in-the-loop pipeline, we curate instances covering 15 generation domains, 16 editing operation types, and 11 repair defect types, each annotated at Easy/Medium/Hard levels. For evaluation, we adopt a checklist-guided LLM-as-a-Judge protocol for editing and repair, and propose a novel Agent-as-a-Judge paradigm for generation that autonomously executes generated websites in a real browser, explores interactive behaviors via the Model Context Protocol (MCP), and iteratively synthesizes targeted test cases, closely approximating human acceptance testing. We evaluate representative closed-source and open-source models and observe that: (1) closed-source models remain substantially stronger and more balanced; (2) editing and repair exhibit distinct difficulty profiles, with repair preserving interactivity better but remaining execution-challenging; (3) aesthetics is the most persistent bottleneck, especially for open-source models; and (4) framework choice materially affects outcomes, with Vue consistently challenging while React and Vanilla/HTML perform more strongly depending on task type.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WebCompass, a multimodal benchmark for unified lifecycle evaluation of code LLMs on web engineering. It spans three input modalities (text/image/video) and three task types (generation/editing/repair) to produce seven categories mirroring professional workflows. A human-in-the-loop pipeline curates instances across 15 generation domains, 16 editing operations, and 11 repair defects, each labeled Easy/Medium/Hard. Evaluation employs a checklist-guided LLM-as-a-Judge for editing/repair and a novel Agent-as-a-Judge for generation that executes sites in a browser, uses MCP to explore interactions, and synthesizes tests. Experiments on closed- and open-source models yield four observations: closed-source models are stronger and more balanced; editing and repair show distinct profiles; aesthetics remains the main bottleneck; and framework choice (e.g., Vue vs. React/Vanilla) affects results.
Significance. If the judge protocols are validated against human raters, WebCompass would provide a valuable advance over existing narrow web-coding benchmarks by measuring visual fidelity, interactivity, and iterative repair in addition to static correctness. The Agent-as-a-Judge paradigm, which autonomously generates targeted tests via real-browser execution, is a concrete methodological contribution that could be reused in other agentic coding evaluations. The human-curated coverage of domains and defect types also supplies a reusable resource for the community.
major comments (2)
- [Evaluation protocols] Evaluation section (Agent-as-a-Judge and LLM-as-a-Judge protocols): the claim that these protocols 'closely approximate human acceptance testing' is unsupported by any reported inter-rater agreement, expert correlation, or validation-subset results against human engineers. This directly undermines interpretation of all four experimental observations, especially claims about aesthetics as the persistent bottleneck and differences in interactivity preservation between editing and repair.
- [Benchmark curation] Benchmark construction and curation pipeline: no quantitative details are given on how data exclusions were decided, what inter-rater agreement was achieved during human annotation of Easy/Medium/Hard levels, or how many instances were discarded. These omissions affect the reliability of the 15/16/11 category counts and the difficulty stratification used to support the difficulty-profile findings.
minor comments (2)
- [Results] The abstract and results section should include at least one table or figure that reports per-model scores broken down by the seven task categories rather than only high-level aggregates, to allow readers to verify the 'distinct difficulty profiles' claim.
- [Evaluation protocols] Notation for the Model Context Protocol (MCP) and the exact checklist items used by the LLM-as-a-Judge should be defined in a dedicated subsection or appendix so that the evaluation can be reproduced.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and positive assessment of WebCompass's potential contributions. We address the major comments point-by-point below, proposing specific revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Evaluation protocols] Evaluation section (Agent-as-a-Judge and LLM-as-a-Judge protocols): the claim that these protocols 'closely approximate human acceptance testing' is unsupported by any reported inter-rater agreement, expert correlation, or validation-subset results against human engineers. This directly undermines interpretation of all four experimental observations, especially claims about aesthetics as the persistent bottleneck and differences in interactivity preservation between editing and repair.
Authors: We agree that explicit validation against human raters would strengthen the claims. The protocols were designed to approximate human acceptance testing through structured checklists for LLM-as-a-Judge and real-browser execution with automated test synthesis for Agent-as-a-Judge. However, the manuscript does not include quantitative agreement metrics. In the revision, we will add a new subsection reporting results from a human validation study on a representative subset (e.g., 100 instances), including inter-rater agreement (Cohen's kappa) between the judges and expert human engineers, as well as correlation with human acceptance decisions. This will directly support the four observations. We believe this addresses the concern without altering the core findings. revision: yes
-
Referee: [Benchmark curation] Benchmark construction and curation pipeline: no quantitative details are given on how data exclusions were decided, what inter-rater agreement was achieved during human annotation of Easy/Medium/Hard levels, or how many instances were discarded. These omissions affect the reliability of the 15/16/11 category counts and the difficulty stratification used to support the difficulty-profile findings.
Authors: We acknowledge the need for greater transparency in the curation process. The human-in-the-loop pipeline involved multiple annotators, but specific quantitative details such as inter-annotator agreement and discard rates were not reported. In the revised manuscript, we will expand the benchmark construction section to include: (1) the total number of candidate instances collected, (2) criteria and numbers for exclusions at each stage, (3) inter-rater agreement statistics (e.g., Fleiss' kappa) for the Easy/Medium/Hard annotations across the 15/16/11 categories, and (4) final counts after curation. These details are available from our annotation logs and will be added to ensure the reliability of the difficulty profiles. revision: yes
Circularity Check
No circularity: benchmark introduction and empirical evaluation are self-contained
full rationale
The paper presents WebCompass as a new multimodal benchmark spanning generation/editing/repair tasks across modalities, with human-in-the-loop curation and two proposed judge protocols (checklist-guided LLM-as-Judge and Agent-as-a-Judge using browser execution + MCP). No equations, fitted parameters, or first-principles derivations appear; the central claims are definitional descriptions of the benchmark construction and empirical observations on existing models. The 'mirrors professional workflows' framing is an interpretive assertion supported by curation process rather than any reduction to self-citation or input-by-construction. Evaluation results (model rankings, difficulty profiles) are direct measurements on the introduced data, not predictions derived from within-paper fits. This is the standard non-circular pattern for benchmark papers.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Checklist-guided LLM-as-a-Judge reliably evaluates editing and repair quality
- domain assumption Agent-as-a-Judge with browser execution and MCP approximates human acceptance testing for generated websites
Reference graph
Works this paper leans on
-
[1]
Does the page crash or show blocking console errors? -> E1.x
-
[2]
Does a required feature not work as specified? -> E2.x
-
[3]
Does it work but look wrong? -> E3.x
-
[4]
checklist_id
Does it look right but have non-functional issues? -> E4.x == Points Allocation Rule == When a single checklist item has multiple issues mentioned in reason: - Allocate points proportionally to issue severity - If unclear, split evenly among identified issues - Critical failures get more points than minor issues == Output Format == Return a JSON array: [{...
-
[5]
sum(points_deducted) must equal max_score - score for each item
-
[6]
Each error gets exactly ONE type code
-
[7]
Full-score items -> empty errors array
-
[8]
id":1, "task
Multiple distinct issues -> separate error objects Error Analysis Prompt (Part 2: Few-Shot Examples) == Example 1: Runtime error == Input: {"id":1, "task":"Page loads correctly", "max_score":5, "score":0, "reason":"Uncaught ReferenceError: initApp is not defined. Page shows white screen."} Output: [{"checklist_id":1, "task":"Page loads correctly", "score"...
-
[9]
, "expected_result
Check for red error messages 4. Check Network for 404/500", "expected_result": "Page loads completely, no Console errors, no failed requests, all static resources load successfully", "criteria": "Full 10 pts; JS errors -5; Resource 404 -3; White screen = 0; Warnings do not deduct", "max_score": 10} ### 2. Spec Implementation (6-10 items, worth 60-70 point...
-
[10]
, "expected_result
Verify highlights and move indicators 4. Click valid square to confirm move with animation", "expected_result": "Piece highlighted, dots on empty squares, rings on captures, smooth ~200ms animation", "criteria": "Full 12; no highlight -4; no indicators -4; no animation -2; wrong move -2", "max_score": 12}, {"task": "Verify dark theme with correct primary/...
-
[11]
, "expected_result
Verify dark gradient background 3. Check primary/accent colors 4. Verify semi-transparent cards", "expected_result": "Dark gradient bg, wood-brown primary, royal blue interactive, gold accents, cohesive dark theme", "criteria": "Full 5; light theme -5; inconsistent colors -2", "max_score": 5}, ... (10 more items omitted for brevity)] Query: --- [QUERY] --...
-
[12]
Your entire response MUST be pure Markdown text
-
[13]
ABSOLUTELY NO explanations, no extra commentary
-
[14]
Every file MUST be emitted using the following format: # path/to/file.ext ```ext <full file content> ```
-
[15]
The heading line MUST start with'#'followed by the file path (relative path)
-
[16]
The code fence language MUST match the file type
-
[17]
Include all necessary files so the project can run
-
[18]
utf-8" /> <title>Demo</title> <link rel=
Do NOT nest triple backticks inside code blocks. Few-shot examples: # index.html ```html <!doctype html> <html> <head> <meta charset="utf-8" /> <title>Demo</title> <link rel="stylesheet" href="styles.css" /> </head> <body> Hello <script type="module" src="main.js"></script> </body> </html> ``` # styles.css ```css body { font-family: system-ui; } ``` # mai...
-
[19]
TEMPORAL SEQUENCE ANALYSIS: - Study frame progression to understand user interactions - Identify animation sequences, timing, and easing patterns - Map state transitions and user feedback mechanisms - Recognize loading states, hover effects, micro-interactions - Document exact timing and duration of animations
-
[20]
VISUAL DESIGN EXTRACTION: - Extract precise color values (prefer hex codes: #RRGGBB) - Identify typography: families, sizes, weights, line heights - Measure spacing: margins, padding, gaps (use rem/em units) - Analyze shadows: box-shadow values, blur, spread, inset - Document border radius, opacity, and gradient effects - Note z-index layering and stackin...
-
[21]
LAYOUT & STRUCTURE ANALYSIS: - Identify layout systems: Flexbox, CSS Grid, or positioning - Map responsive breakpoints and mobile adaptations - Document component hierarchy and nesting structure - Analyze alignment, distribution, and spacing patterns
-
[22]
"> </search_replace> tags - The`path`attribute must specify the relative file path (e.g.,
INTERACTION PATTERN RECOGNITION: - Button states: normal, hover, active, focus, disabled - Animation triggers: click, hover, scroll, load events - State management: data flow and component updates - User feedback: visual confirmations and error states Video-Guided Generation Prompt (Part 2: Implementation) TECHNICAL IMPLEMENTATION REQUIREMENTS: HTML5 STRU...
-
[23]
Task Instructions: multi-line text, each line follows: Task <idx> - <task_type>: <description>
-
[24]
Generated Code Modifications: the search/replace blocks
-
[25]
Original UI Screenshot: the before-modification state
-
[26]
task_scores
Modified UI Screenshot: the after-modification visual result ## Evaluation Framework Score each task independently across three dimensions (0-10): - Instruction Targeting: Patch applicability and task-attempt coverage - Feature Integrity: Whether original and new functionality is correct - Style Conformance: Visual quality and consistency with original st...
-
[27]
Defect Description: multi-line text, each line follows: Defect <idx> - <task_type>: <description>
-
[28]
Ground-Truth Code Modifications: the ideal fix (reference)
-
[29]
Generated Code Modifications: the produced fix
-
[30]
Before-Fix UI Screenshot: defective state (red box markers)
-
[31]
After-Fix UI Screenshot: the actual repair result
-
[32]
task_scores
Ground-Truth Fixed UI Screenshot: the ideal fix result ## Evaluation Framework Score each defect repair independently (0-10 per dimension): - Root-Cause Targeting: Patch applicability and root-cause localization - Interaction Integrity: Whether original and repaired functionality is correct - Reference Fidelity: Visual quality vs. ground-truth reference #...
-
[33]
Absolutely do not modify/fix the original website project code
-
[34]
The only content you are allowed to create/modify is: - checklist.json - Screenshot files in the image/ directory
-
[35]
Before all tasks are completed, you must call tools for verification in every round
Complete all tasks in a single run. Before all tasks are completed, you must call tools for verification in every round. Agent-as-a-Judge: Verification Prompt (Part 2: Execution Flow) ======================== Mandatory Execution Flow (No Steps May Be Skipped) ======================== Step 0: Prepare Output Directory
-
[36]
Ensure image/ folder exists in the project directory
-
[37]
Step 1: Conduct Code Review First (Read-Only)
Take screenshots for every key state verification. Step 1: Conduct Code Review First (Read-Only)
-
[38]
Read repository code related to page entry points, routing, interactions, requests, and error handling
-
[39]
Compile verifiable points: entry URLs, key buttons/forms, potential error points, data sources and loading logic
-
[40]
Step 2: Read checklist.json
Code review only guides test paths; final scores must be based on actual webpage behavior. Step 2: Read checklist.json
-
[41]
Locate all entries where score is null
-
[42]
Step 3: Open and Actually Test the Webpage
Extract task / operation_sequence / expected_result. Step 3: Open and Actually Test the Webpage
-
[43]
Use mcp__chrome-devtools for interactive verification 35 (clicking, typing, navigating, scrolling, etc.)
-
[44]
For aesthetics tasks, combine UI screenshots for scoring
For each item: perform operations, observe expectations, take screenshots as evidence. For aesthetics tasks, combine UI screenshots for scoring. Step 4: Immediately Write Back to Checklist
-
[45]
- reason: Single-line string with reproducible evidence
After each verification, write back to checklist.json: - score: Change from null to a definitive score. - reason: Single-line string with reproducible evidence. ======================== Key Rule: Entry Point Failure => Cascading Failure ======================== If the website entry point is unavailable (blank screen/crash/ infinite loading): take screensh...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.