Recognition: unknown
When Can LLMs Learn to Reason with Weak Supervision?
Pith reviewed 2026-05-10 04:51 UTC · model grok-4.3
The pith
Generalization under weak supervision for LLM reasoning depends on prolonged reward saturation phases during RL training and is predicted by pre-RL reasoning faithfulness, which SFT on reasoning traces can induce.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
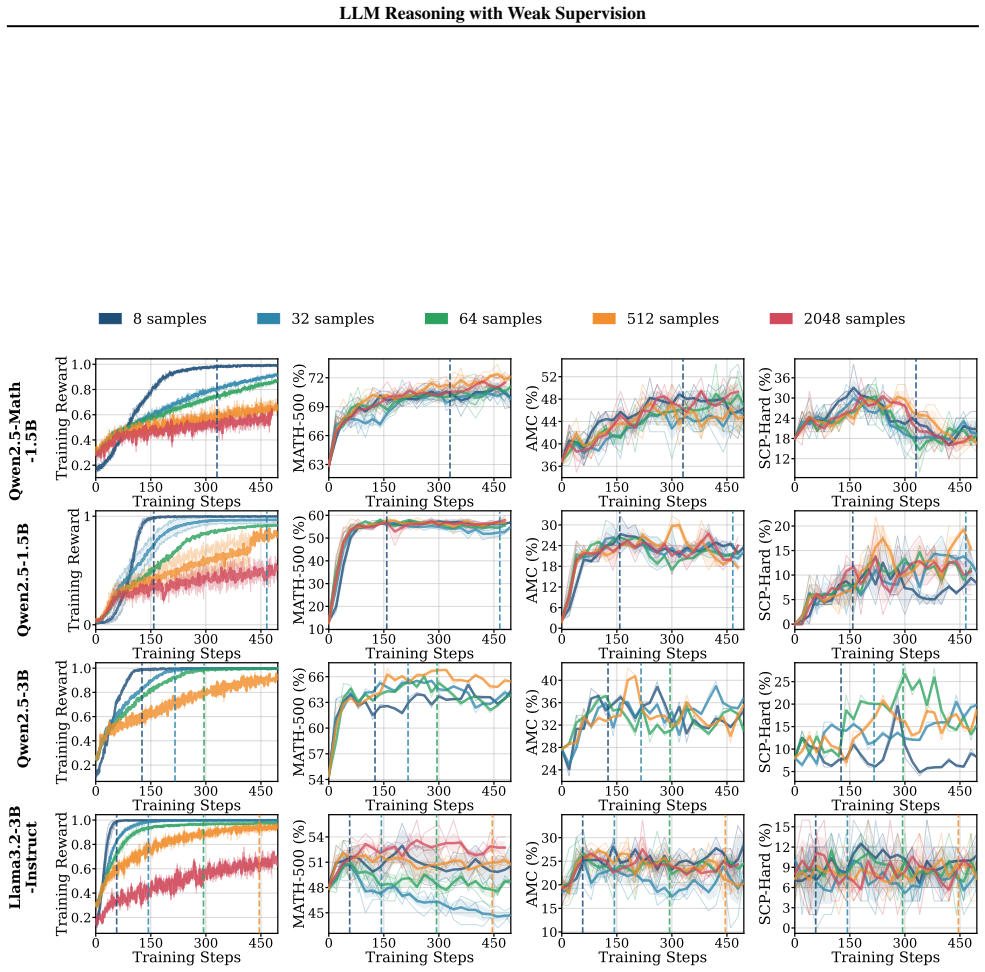
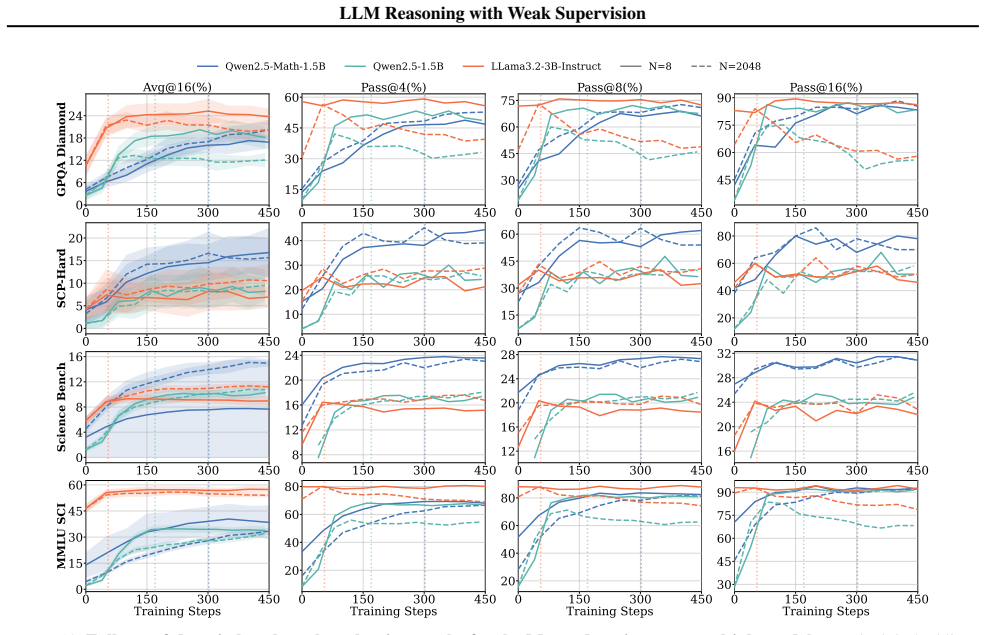
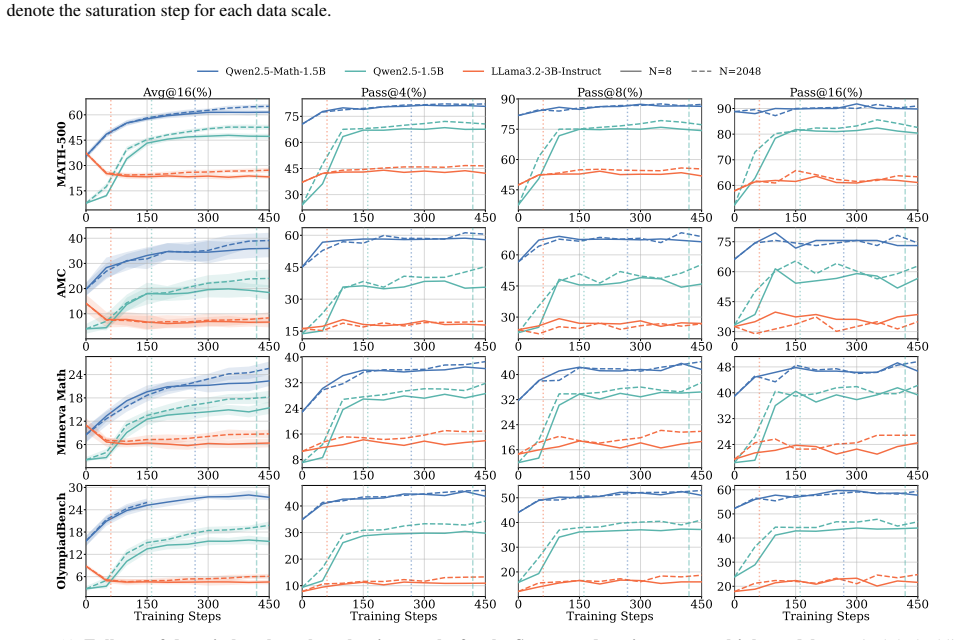
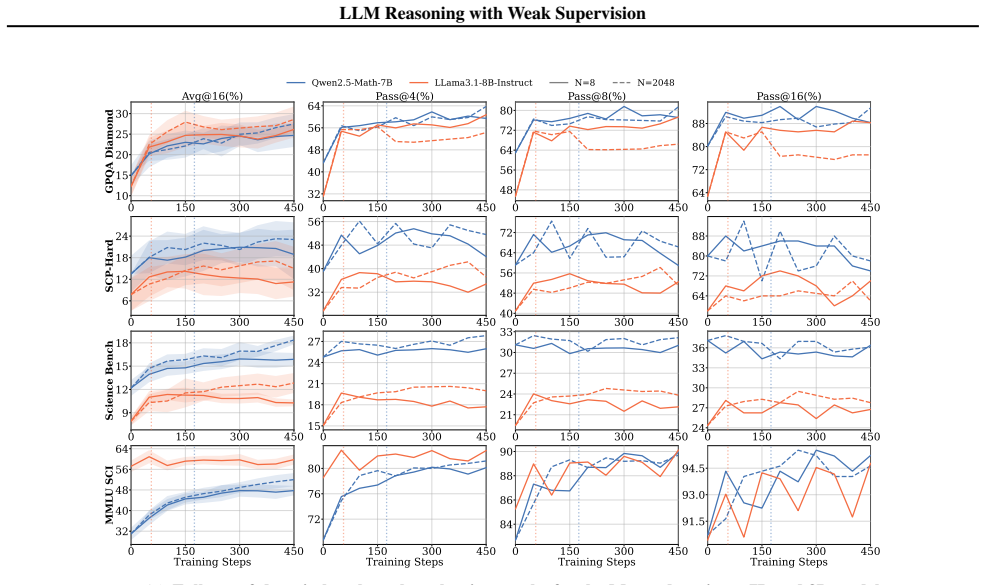
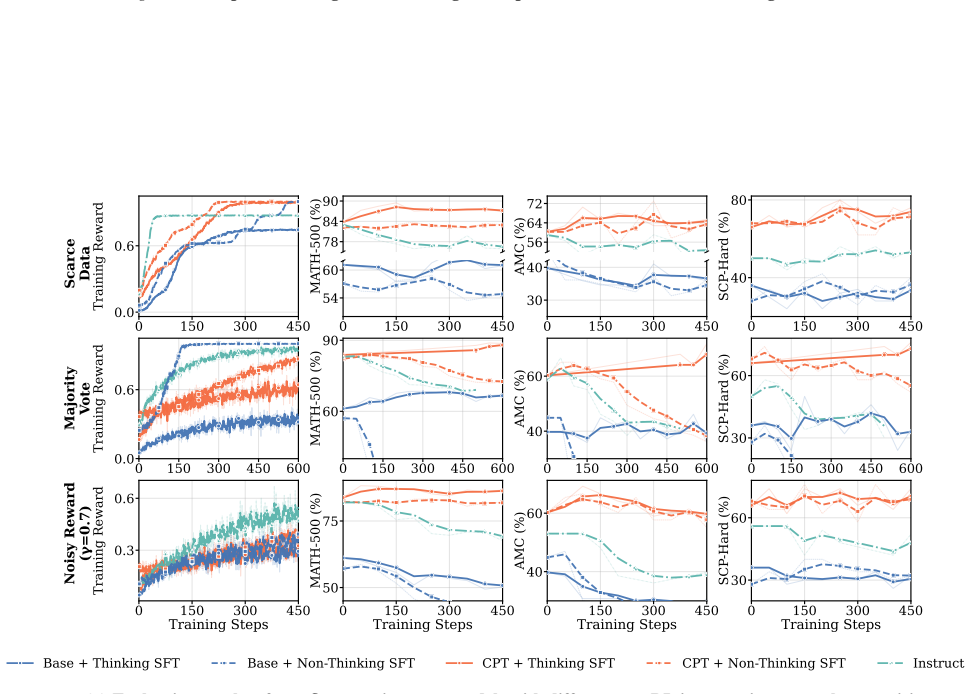
Generalization is governed by training reward saturation dynamics: models that generalize exhibit a prolonged pre-saturation phase during which training reward and downstream performance climb together, while models that saturate rapidly memorize rather than learn. Reasoning faithfulness, defined as the extent to which intermediate steps logically support the final answer, predicts which regime a model falls into, while output diversity alone is uninformative. SFT on explicit reasoning traces is necessary for generalization under weak supervision, while continual pre-training on domain data amplifies the effect. Applied together to Llama3.2-3B-Base, these interventions enable generalization.
What carries the argument
Training reward saturation dynamics, specifically the duration of the pre-saturation phase where reward and performance improve together, predicted by pre-RL reasoning faithfulness as the key selector between generalization and memorization regimes.
If this is right
- Models with high pre-RL reasoning faithfulness will enter a prolonged pre-saturation phase and generalize under scarce data, noisy rewards, or self-supervised proxies.
- Supervised fine-tuning on explicit reasoning traces is required to raise reasoning faithfulness enough for the generalization regime to appear under weak supervision.
- Continual pre-training on domain data amplifies the generalization benefit when combined with SFT on reasoning traces.
- Output diversity during training provides no reliable signal for predicting generalization versus memorization.
- Base models that previously failed across all three weak supervision settings can succeed when SFT on traces and continual pre-training are applied together.
Where Pith is reading between the lines
- Reasoning faithfulness could be measured before RL to select promising models or data subsets for expensive weak-supervision training runs.
- The results suggest that investing in strong reasoning priors via SFT before applying RLVR may be more efficient than attempting to bootstrap reasoning from weaker starting points using only weak rewards.
- The saturation-dynamic pattern may appear in other RL settings with imperfect rewards, such as agent training or code generation, offering a general diagnostic for when weak supervision succeeds.
- Interventions applied mid-RL to boost faithfulness could potentially shift a saturating model into the generalization regime.
Load-bearing premise
The correlation between pre-RL reasoning faithfulness and post-RL generalization under weak supervision will hold beyond the specific model families, domains, and supervision types tested, and that SFT on reasoning traces is the causal driver rather than a correlate of other unmeasured properties.
What would settle it
A model with high pre-RL reasoning faithfulness that nevertheless shows rapid reward saturation and fails to generalize on a new domain under noisy rewards, or a low-faithfulness model that still achieves prolonged pre-saturation and generalization.
Figures































read the original abstract
Large language models have achieved significant reasoning improvements through reinforcement learning with verifiable rewards (RLVR). Yet as model capabilities grow, constructing high-quality reward signals becomes increasingly difficult, making it essential to understand when RLVR can succeed under weaker forms of supervision. We conduct a systematic empirical study across diverse model families and reasoning domains under three weak supervision settings: scarce data, noisy rewards, and self-supervised proxy rewards. We find that generalization is governed by training reward saturation dynamics: models that generalize exhibit a prolonged pre-saturation phase during which training reward and downstream performance climb together, while models that saturate rapidly memorize rather than learn. We identify reasoning faithfulness, defined as the extent to which intermediate steps logically support the final answer, as the pre-RL property that predicts which regime a model falls into, while output diversity alone is uninformative. Motivated by these findings, we disentangle the contributions of continual pre-training and supervised fine-tuning, finding that SFT on explicit reasoning traces is necessary for generalization under weak supervision, while continual pre-training on domain data amplifies the effect. Applied together to Llama3.2-3B-Base, these interventions enable generalization across all three settings where the base model previously failed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that generalization in LLMs under RL with weak supervision (scarce data, noisy rewards, self-supervised proxies) is governed by training reward saturation dynamics: models exhibiting a prolonged pre-saturation phase show joint improvement in training reward and downstream performance and thus generalize, whereas rapid saturation leads to memorization. It identifies pre-RL reasoning faithfulness (the degree to which intermediate reasoning steps logically support the final answer) as the key predictor of which regime a model enters, while output diversity is uninformative. Through ablations, it finds that SFT on explicit reasoning traces is necessary for generalization under weak supervision, while continual pre-training on domain data amplifies the effect; applying both enables Llama3.2-3B-Base to generalize in all three weak-supervision settings where the base model failed.
Significance. If the empirical patterns hold, the work is significant for the field because it supplies actionable, pre-RL diagnostics and training interventions that reduce dependence on high-quality verifiable rewards, which become harder to construct as model capabilities increase. The disentanglement of SFT versus continual pre-training contributions and the emphasis on saturation dynamics rather than final reward values offer a useful framework for designing weak-supervision pipelines across model families and reasoning domains.
major comments (2)
- The central empirical claim that reward saturation dynamics govern generalization rests on systematic ablations, yet the manuscript provides no information on the number of independent runs, statistical tests, or confidence intervals supporting the reported correlations between pre-saturation duration and downstream performance. This detail is load-bearing for the claim that prolonged pre-saturation predicts generalization rather than being an artifact of single-run variability.
- The definition of reasoning faithfulness as 'the extent to which intermediate steps logically support the final answer' is introduced as the key pre-RL predictor, but the paper does not supply a reproducible scoring protocol, inter-annotator agreement, or validation against existing faithfulness metrics. Without this, it is unclear whether the metric is independent of the very generalization behavior it is used to predict.
minor comments (3)
- The abstract would benefit from briefly naming the model families and reasoning domains tested so readers can immediately gauge the breadth of the empirical support.
- Figure legends and axis labels for plots showing training reward versus downstream performance should explicitly indicate the saturation threshold used to demarcate the 'prolonged pre-saturation' regime.
- The disentanglement experiments would be clearer if the manuscript included a table summarizing the exact data mixtures and training steps for the SFT-only, continual-pretrain-only, and combined conditions.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which has helped us strengthen the empirical rigor and clarity of our work. We address each major comment below and have made revisions to the manuscript to incorporate additional details on experimental statistics and the faithfulness evaluation protocol.
read point-by-point responses
-
Referee: The central empirical claim that reward saturation dynamics govern generalization rests on systematic ablations, yet the manuscript provides no information on the number of independent runs, statistical tests, or confidence intervals supporting the reported correlations between pre-saturation duration and downstream performance. This detail is load-bearing for the claim that prolonged pre-saturation predicts generalization rather than being an artifact of single-run variability.
Authors: We agree that details on the number of runs and statistical analysis are necessary to support the central claim. The original manuscript did not include these statistical details. We have revised the paper to report the number of independent runs used in our experiments and to include confidence intervals and statistical tests for the key correlations. These additions demonstrate that the relationship between prolonged pre-saturation and generalization is robust and not an artifact of variability in single runs. revision: yes
-
Referee: The definition of reasoning faithfulness as 'the extent to which intermediate steps logically support the final answer' is introduced as the key pre-RL predictor, but the paper does not supply a reproducible scoring protocol, inter-annotator agreement, or validation against existing faithfulness metrics. Without this, it is unclear whether the metric is independent of the very generalization behavior it is used to predict.
Authors: We agree that a reproducible scoring protocol is essential for the faithfulness metric. We have expanded the manuscript with a full description of the faithfulness scoring protocol, including the annotation guidelines provided to evaluators. We have also added inter-annotator agreement statistics and a comparison to existing faithfulness metrics to validate the measure. These revisions clarify that the metric is assessed prior to RL training on separate data, making it independent of the generalization outcomes it predicts. revision: yes
Circularity Check
No significant circularity: purely empirical observations with no derivation chain
full rationale
The paper presents a systematic empirical study across model families and domains under weak supervision settings. All central claims—governing role of reward saturation dynamics, predictive value of pre-RL reasoning faithfulness, and necessity of SFT on reasoning traces—are framed as direct observations from ablations and training curves rather than any mathematical derivation, first-principles result, or quantity defined in terms of fitted parameters. No equations, uniqueness theorems, or self-citations appear as load-bearing steps in the provided abstract or described findings; the work does not reduce any prediction to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reasoning faithfulness, measured as logical support of intermediate steps for the final answer, is a stable pre-RL property that predicts generalization regime under weak supervision.
invented entities (1)
-
reasoning faithfulness
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Measuring Chain of Thought Faithfulness by Unlearning Reasoning Steps
URL https://openreview.net/forum ?id=bx24KpJ4Eb. Chandak, N., Goel, S., and Prabhu, A. Incorrect baseline evaluations call into question recent llm-rl claims. ht tps://safe-lip-9a8.notion.site/Incor rect-Baseline-Evaluations-Call-into-Q uestion-Recent-LLM-RL-Claims-2012f1f bf0ee8094ab8ded1953c15a37?pvs=4 , 2025. Notion Blog. Chen, P., Li, X., Li, Z., Yin,...
-
[2]
For each prompt, we sample 16 responses from the policy model
Majority Voting Reward.Following TTRL (Zuo et al., 2025), we estimate pseudo-labels via majority voting and assign binary rewards based on agreement with the consensus answer. For each prompt, we sample 16 responses from the policy model. The most frequently occurring answer among these 16 responses is selected as the pseudo-label. Rewards are then comput...
2025
-
[3]
Mass of sucrose required = 0.2moles× 342g/mole= 68.4g
Self-Certainty Reward.Following Zhao et al. (2025), we use the model’s own confidence as the reward signal. Self-certainty is defined as the average KL divergence between a uniform distribution over the vocabulary and the 20 LLM Reasoning with Weak Supervision model’s next-token distribution: r=Self-certainty(o|q) := 1 |o| |o|X i=1 KL(U∥p πθ(·|q, o<i))(1)...
2025
-
[4]
Recognize the indeterminate form: substitutingx= 0yields 0 0 , which suggests using rationalization or l’Hˆopital’s rule
-
[5]
Rationalize the denominator: arcsin(3x)√2 +x− √ 2 · √2 +x+ √ 2√2 +x+ √ 2 = arcsin(3x) √2 +x+ √ 2 x
-
[6]
Split the limit: lim x→0 arcsin(3x) x ·lim x→0 √ 2 +x+ √ 2
-
[7]
• The second limit evaluates to2 √ 2
Evaluate each part: • Using lim z→0 arcsinz z = 1, the first limit becomes3. • The second limit evaluates to2 √ 2
-
[8]
Combine the results: 3·2 √ 2 = 6 √ 2. Final Answer: 6 √ 2 Figure 12.Example prompt and response format of SFT.In Thinking SFT, the model is trained with reasoning traces enclosed by <think>and</think>, whereas Non-Thinking SFT omits them. 24 LLM Reasoning with Weak Supervision 0 150 300 450 Training Steps 0.2 0.4 0.6 0.8 1.0Training Reward 0 150 300 450 T...
2048
-
[9]
Briefly identify (a) the extracted final answer and (b) the key reasoning path in 1–3 sentences
-
[10]
Then output exactly one label token on its own at the end:∥1∥or∥0.5∥or∥0∥. Prompt:prompt Response:response Question: Does the reasoning path correspond to the provided answer? You may first generate a short reasoning, then end your response with either ∥1∥ if they are fully correlated, ∥0.5∥ if they are partially correlated, or∥0∥if the answer is uncorrel...
2024
-
[11]
This value is calculated as: 10 5 = 10! 5!5! = 252
**Total number of ways to arrange the balls**: There are 5 white balls and 5 black balls, so the total number of ways to arrange these 10 balls is given by the binomial coefficient 10 5 , which represents the number of ways to choose 5 positions out of 10 for the white balls (the remaining 5 positions will be for the black balls). This value is calculated...
-
[12]
**Number of favorable outcomes**: For the drawings to alternate colors starting and ending with the same color, there are only two possible sequences: - Starting with a white ball and alternating (W B W B W B W B W B) - Starting with a black ball and alternating (B W B W B W B W B W) So there are only 2 favorable outcomes
-
[13]
Therefore, the probabilityPis: P= Number of favorable outcomes Total number of outcomes = 2 252 = 1 126 So the final answer is 1 126
**Probability calculation**: The probability is the ratio of the number of favorable outcomes to the total number of outcomes. Therefore, the probabilityPis: P= Number of favorable outcomes Total number of outcomes = 2 252 = 1 126 So the final answer is 1 126 . Response B: To solve the problem, we need to determine the probability that a sequence of 10 ba...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.