Recognition: unknown
LePREC: Reasoning as Classification over Structured Factors for Assessing Relevance of Legal Issues
Pith reviewed 2026-05-10 02:08 UTC · model grok-4.3
The pith
Legal issue relevance improves when LLMs generate factor questions that a sparse linear model then classifies from case facts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
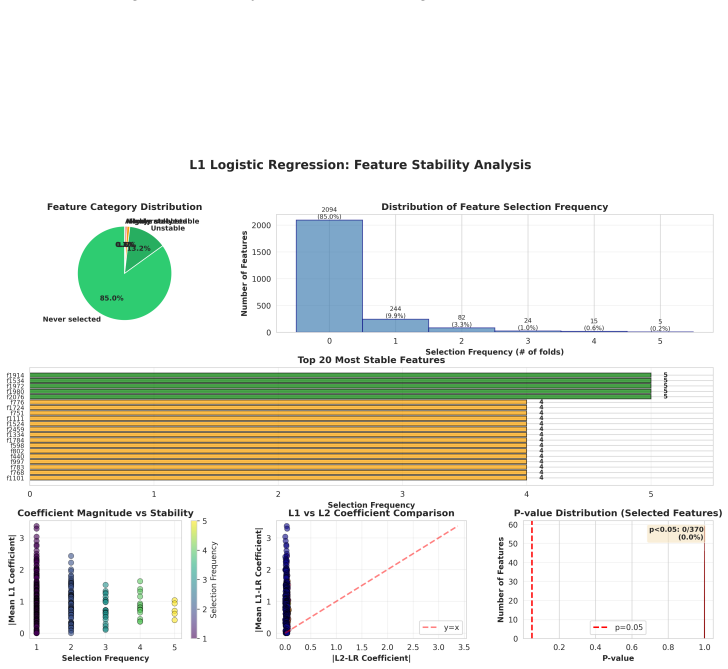
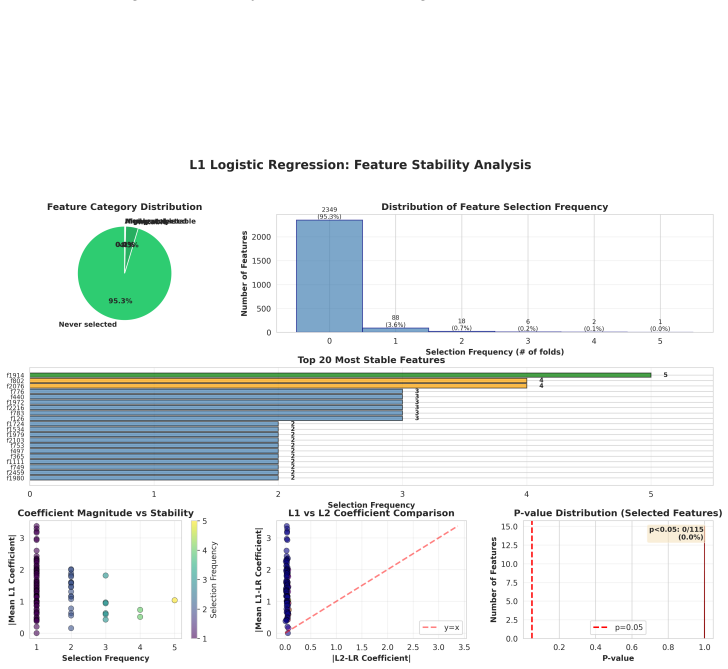
Relevance of candidate legal issues is decided more accurately by first using an LLM to produce structured question-answer pairs that encode the analytical factors present in a case description and then training a sparse linear model over those discrete features to learn transparent algebraic weights that rank which factors determine relevance.
What carries the argument
The neuro-symbolic pipeline that converts legal facts into discrete factor question-answer pairs and performs relevance classification with sparse linear models over those pairs.
If this is right
- The learned weights directly reveal which analytical factors drive relevance decisions, giving lawyers an auditable explanation for each classification.
- The approach needs far fewer labeled examples than fine-tuning or prompting large end-to-end models for the same relevance task.
- The separation of factor generation from factor weighting allows the symbolic classifier to be retrained or updated independently of the underlying language model.
- Performance gains appear consistently when the generation step uses different LLM backbones, indicating the benefit comes from the structured classification layer rather than any single generator.
Where Pith is reading between the lines
- The same factor-extraction-plus-linear-classification pattern could be tested on issue-spotting tasks in medical records or regulatory filings where explicit reasoning chains matter.
- If important factor interactions are missed by the linear model, adding limited pairwise terms or small decision trees over the same features would be a direct next experiment.
- Because the method keeps the LLM only for generation and not for final classification, it reduces both compute cost and the risk of hallucinated legal conclusions at inference time.
Load-bearing premise
The assumption that LLM-generated question-answer pairs capture all the interacting analytical factors required for correct relevance decisions without omitting critical legal nuances or interactions.
What would settle it
A held-out set of expert-annotated cases in which a model misses a relevant issue because the decisive factor never appeared in the generated question-answer pairs or received near-zero weight in the learned linear model.
Figures








read the original abstract
More than half of the global population struggles to meet their civil justice needs due to limited legal resources. While Large Language Models (LLMs) have demonstrated impressive reasoning capabilities, significant challenges remain even at the foundational step of legal issue identification. To investigate LLMs' capabilities in this task, we constructed a dataset from 769 real-world Malaysian Contract Act court cases, using GPT-4o to extract facts and generate candidate legal issues, annotated by senior legal experts, which reveals a critical limitation: while LLMs generate diverse issue candidates, their precision remains inadequate (GPT-4o achieves only 62%). To address this gap, we propose LePREC (Legal Professional-inspired Reasoning Elicitation and Classification), a neuro-symbolic framework combining neural generation with structured statistical reasoning. LePREC consists of: (1) a neuro component leverages LLMs to transform legal descriptions into question-answer pairs representing diverse analytical factors, and (2) a symbolic component applies sparse linear models over these discrete features, learning explicit algebraic weights that identify the most informative reasoning factors. Unlike end-to-end neural approaches, LePREC achieves interpretability through transparent feature weighting while maintaining data efficiency through correlation-based statistical classification. Experiments show a 30-40% improvement over advanced LLM baselines, including GPT-4o and Claude, confirming that correlation-based factor-issue analysis offers a more data-efficient solution for relevance decisions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs achieve only 62% precision on legal issue identification in a new dataset of 769 Malaysian Contract Act cases (constructed via GPT-4o fact extraction and issue proposal, followed by expert annotation). It proposes LePREC, a neuro-symbolic method that (1) uses LLMs to convert legal descriptions into QA pairs encoding analytical factors and (2) applies sparse linear models over these discrete features to learn explicit weights for relevance classification. Experiments reportedly show 30-40% gains over end-to-end LLM baselines including GPT-4o and Claude, arguing for superior data efficiency and interpretability via correlation-based factor analysis.
Significance. If the performance claims hold under rigorous controls, the work would contribute a concrete neuro-symbolic template for legal reasoning that trades end-to-end neural opacity for transparent, learnable factor weights. The explicit algebraic weighting and data-efficiency emphasis are genuine strengths that could inform hybrid systems in other high-stakes domains where pure LLMs currently lack precision.
major comments (3)
- [Experiments] Experiments section (and abstract): the 30-40% improvement is stated without reporting the precise metric (precision@K, F1, accuracy?), the exact baseline prompts and decoding settings for GPT-4o/Claude, statistical significance tests, or ablation on the number of QA pairs. Because the dataset itself was generated by GPT-4o, these omissions make it impossible to assess whether the reported gap reflects genuine method superiority or artifacts of the construction pipeline.
- [Dataset Construction] Dataset construction and neuro component: GPT-4o is used both to propose candidate issues for the gold labels and to generate the QA-pair factors that feed the symbolic classifier. This creates a circularity risk—the sparse linear model may simply be fitting correlations that are easier to exploit on LLM-generated distributions rather than demonstrating superior reasoning over the true legal factor space. A control experiment that replaces the neuro-generated factors with expert-authored factors is needed to isolate the contribution.
- [Symbolic Component] Symbolic component: the paper asserts that sparse linear models over discrete QA features suffice for relevance decisions, yet provides no analysis of whether linear separability holds for the legal interactions present in the Contract Act cases. If higher-order dependencies among factors are common, the claimed interpretability advantage could be illusory.
minor comments (2)
- [Abstract] The abstract states LLMs achieve 'only 62%' precision but does not specify whether this is micro- or macro-averaged, nor the exact definition of a correct issue identification.
- [Method] Notation for the sparse linear model (feature vector, weight vector, decision threshold) should be introduced once with consistent symbols across equations.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of experimental rigor, potential biases in data construction, and the assumptions underlying our symbolic component. We address each point below and commit to revisions that strengthen the manuscript without misrepresenting our contributions.
read point-by-point responses
-
Referee: [Experiments] Experiments section (and abstract): the 30-40% improvement is stated without reporting the precise metric (precision@K, F1, accuracy?), the exact baseline prompts and decoding settings for GPT-4o/Claude, statistical significance tests, or ablation on the number of QA pairs. Because the dataset itself was generated by GPT-4o, these omissions make it impossible to assess whether the reported gap reflects genuine method superiority or artifacts of the construction pipeline.
Authors: We agree these details are necessary for full reproducibility and to address potential artifacts. The improvement refers to precision (consistent with the reported 62% for GPT-4o). In the revised version, we will: explicitly state 'precision' in the abstract and experiments; append the exact prompts, system instructions, and decoding settings (e.g., temperature=0 for deterministic output) used for GPT-4o and Claude baselines; report statistical significance via McNemar's test on paired predictions across 5 runs; and include an ablation varying the number of QA pairs (5/10/20/30) with corresponding precision curves. We will also add a paragraph clarifying that while GPT-4o generated initial candidates, expert annotators independently verified and corrected all gold labels, reducing pipeline bias. revision: yes
-
Referee: [Dataset Construction] Dataset construction and neuro component: GPT-4o is used both to propose candidate issues for the gold labels and to generate the QA-pair factors that feed the symbolic classifier. This creates a circularity risk—the sparse linear model may simply be fitting correlations that are easier to exploit on LLM-generated distributions rather than demonstrating superior reasoning over the true legal factor space. A control experiment that replaces the neuro-generated factors with expert-authored factors is needed to isolate the contribution.
Authors: We recognize the circularity risk as a substantive concern. Expert annotation does provide an independent gold standard (senior lawyers reviewed and edited all proposed issues), but the factors themselves remain LLM-derived. To isolate the neuro component's contribution, we will add a control experiment in the revision: for a random subset of 150 cases, legal experts will manually author a comparable set of QA factors based on the same case descriptions. We will then retrain the sparse linear classifier on these expert factors and report precision relative to the LLM-generated factors. This will quantify any performance difference and allow discussion of whether the gains stem from factor quality or the classification approach itself. revision: partial
-
Referee: [Symbolic Component] Symbolic component: the paper asserts that sparse linear models over discrete QA features suffice for relevance decisions, yet provides no analysis of whether linear separability holds for the legal interactions present in the Contract Act cases. If higher-order dependencies among factors are common, the claimed interpretability advantage could be illusory.
Authors: The empirical success of the sparse linear model (30-40% precision lift) indicates that the selected discrete factors capture sufficient signal for this task under linear weighting. Interpretability is realized through the learned coefficients, which we already correlate with legal concepts in the current analysis. Nevertheless, we agree higher-order interactions may exist in Contract Act cases (e.g., joint conditions on consideration and capacity). In revision we will: (1) add a comparison of the linear model against a non-linear baseline (gradient-boosted trees) on the same features to measure any lift from interactions; (2) inspect the top-10 weighted factors for legal coherence; and (3) explicitly discuss the limitation that linear separability may not fully model all multi-factor dependencies, while noting that the current approach still yields transparent, actionable weights. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's core derivation proceeds from expert-annotated labels on a GPT-4o-generated candidate set, through LLM-produced QA-pair features, to a sparse linear classifier whose weights are fitted on those features. This chain does not reduce by construction to its inputs: the symbolic step learns explicit algebraic weights on discrete factors rather than renaming or re-predicting the LLM generation process itself. No self-citations, uniqueness theorems, or ansatzes are invoked to force the result. The evaluation against end-to-end LLM baselines therefore rests on an independent statistical classification step and remains self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- sparse linear model weights
axioms (1)
- domain assumption Relevance of legal issues can be modeled as a linear combination of discrete analytical factors extracted from case descriptions.
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925. Danial Alihosseini, Ehsan Montahaei, and Mahdieh So- leymani Baghshah. 2019. Jointly measuring diversity and quality in text generation models. InProceed- ings of the Workshop on Methods for Optimizing and Evaluating Neural Language Generation, pages 90– 98. Ibrahim Alsolami and T. Fuk...
work page internal anchor Pith review arXiv 2019
-
[2]
Legal-bert: The muppets straight out of law school.arXiv preprint arXiv:2010.02559. Claude3.5. Claude3.5 official technical report. CLJ Legal Network. 2024. CLJ Law – Current Law Journal Malaysia. Accessed: 2024-05-27. Commonwealth Secretariat. n.d. Member countries. Tao Feng, Lizhen Qu, and Gholamreza Haffari. 2023. Less is more: Mitigate spurious correl...
-
[3]
Can chatgpt perform reasoning using the irac method in analyzing legal scenarios like a lawyer? InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 13900–13923. Mikhail Fedorovich Kazantsev. 2022. The civilizational value of a contract. InSHS Web of Conferences, volume 134, page 00057. EDP Sciences. Seungone Kim, Juyoung Suk, Sh...
-
[4]
Classification of parkinson’s disease and other neurological disorders using voice features extraction and reduction techniques.Informatyka Automatyka Pomiary w Gospodarce i Ochronie ´Srodowiska. Mary L McHugh. 2012. Interrater reliability: the kappa statistic.Biochemia medica, 22(3):276–282. Ricardo Montañana, Jos’e A. G’amez, and Jos’e M. Puerta. 2024. ...
-
[5]
Lunjun Zhang, Arian Hosseini, Hritik Bansal, Mehran Kazemi, Aviral Kumar, and Rishabh Agarwal
Llm-lasso: A robust framework for domain- informed feature selection and regularization.arXiv preprint arXiv:2502.10648. Lunjun Zhang, Arian Hosseini, Hritik Bansal, Mehran Kazemi, Aviral Kumar, and Rishabh Agarwal. 2024. Generative verifiers: Reward modeling as next-token prediction.arXiv preprint arXiv:2408.15240. Lianmin Zheng, Wei-Lin Chiang, Ying She...
-
[6]
Example: Smith v
**Case Name**: Extract the full official case name. Example: Smith v. Jones [2020] 2 MLJ 35
2020
-
[7]
Focus on those that establish the dispute, actions, and agreements
**Facts**: Identify the facts directly related to the legal issues. Focus on those that establish the dispute, actions, and agreements
-
[8]
case_name
**Held (Conclusion)**: Provide the court’s final decision, including penalties, remedies, or significant conclusions. Output Format: { "case_name": "Extracted case name", "facts": [ "Fact 1...", "Fact 2..." ], "held": "Holding or judgment of the court." } Case Text: {case_text} Listing 1: Prompt for Fact and Held Extraction The prompt below is used for is...
-
[9]
Whether
Identify each legal issue in the case by framing a question starting with "Whether..."
-
[10]
if...then
For each issue, apply the relevant rules to the facts using an "if...then" structure
-
[11]
Provide a clear answer (Yes/No or another legal conclusion) for each issue, based on legal reasoning
-
[12]
issues": [ {
Multiple applications may be required if more than one rule applies or if multi-step reasoning is necessary. Output Format: { "issues": [ { "issue": "Whether issue 1...", "application": [ "If [specific fact]... then [ application of legal rule]...", "If [specific fact]... then [ application of another legal rule]..." ], "answer": "Yes/No or detailed legal...
2024
-
[13]
Asean Security Paper Mills Sdn Bhd (the respondent/appellant) made a claim on an insurance policy after a fire destroyed their warehouse containing security paper
-
[14]
The insurance companies, including Mitsui Sumitomo Insurance (the applicant/respondent), denied the claim on grounds of fraud, alleging that the fire was caused by arson rather than spontaneous combustion
-
[15]
The High Court found that the fire was due to spontaneous combustion; this decision was overturned by the Court of Appeal, which concluded that the fire was an act of arson
-
[16]
The respondent/appellant appealed to the Federal Court, leading to the reinstatement of the High Court’s original decision. Ground Truth Legal Issues: - Whether the Federal Court should exercise its review jurisdiction under Rule 137 of the Rules of the Federal Court 1995 to prevent injustice in this case. - Whether the findings of fact made by the High C...
1995
-
[17]
Whether the fire damage to the warehouse containing se- curity paper is covered under the terms of the insurance policy, including any applicable exclusions or conditions
6 CLJ. Fact List: • The appellant, Encony Development Sdn Bhd, executed a sale and purchase agreement (SPA) with the respondents on 2 September 2010 for a condominium unit, whereby the respondents paid an initial deposit and subsequently the balance ten percent deposit. • The statutory SPA included clauses that made timely payment of installments essentia...
2010
-
[18]
Whether the alleged pre-SPA representations created a binding collateral contract that could override the terms of the statutory SPA
-
[19]
Whether the clauses in the statutory SPA mak- ing timely payment of instalments essential were valid and enforceable
-
[20]
Whether the respondents breached a funda- mental term of the SPA by failing to make required progress payments
-
[21]
Whether the notice of default issued on 12 November 2010 was sufficient and in compli- ance with the terms of the SPA
2010
-
[22]
almost entirely consistent
Whether the appellant’s termination of the SPA was lawful given the respondents’ failure to make progress payments. Reasoning Questions.LEPREC selected 50 rea- soning questions from the learned linear model: the top 25 positively weighted questions (indicative of relevance) and the top 25 negatively weighted ques- tions (indicative of irrelevance), listed...
2012
-
[23]
Whether the late delivery claim ought to be calculated from the expiry of 42 months from the date of the SPA of 28 June 2012 until the date of delivery of vacant possession
2012
-
[24]
A.8.3 Issue Candidates Scenario#1:
Whether the purchase price for the calculation of the late delivery claim should be based on the price as stated in the SPA or the reduced price via the device of a credit note issued by the developer. A.8.3 Issue Candidates Scenario#1:
-
[25]
Generated Issue Candidates Given Scenario#1:
The developer, Sri Damansara Sdn Bhd, col- lected a booking fee of RM10,000 on 6 Jan- uary 2012 prior to signing the sale and pur- chase agreement (SPA) dated 28 June 2012, which contravened Housing Development reg- ulations. Generated Issue Candidates Given Scenario#1:
2012
-
[26]
Whether the collection of a booking fee by Sri Damansara Sdn Bhd prior to signing the sale and purchase agreement (SPA) is in violation of Housing Development regulations
-
[27]
Scenario#2:
Whether the developer’s action of collecting a booking fee on 6 January 2012, nearly six months before the SPA was signed on 28 June 2012, is legal and permissible under applica- ble housing laws. Scenario#2:
2012
-
[29]
Generated Issue Candidates Given Scenario#2:
When the vacant possession was delivered on 22 December 2016, the purchasers filed a claim for damages for late delivery, calculat- ing it from the booking fee payment date to the delivery date, which the Tribunal upheld. Generated Issue Candidates Given Scenario#2:
2016
-
[30]
Whether the developer’s collection of a book- ing fee prior to signing the sale and pur- chase agreement (SPA) was in contravention of Housing Development regulations
-
[31]
Scenario#3:
Whether the calculation of late delivery dam- ages should commence from the date of the booking fee payment or from the date of the signed sale and purchase agreement (SPA). Scenario#3:
-
[32]
The developer, Sri Damansara Sdn Bhd, col- lected a booking fee of RM10,000 on 6 Jan- uary 2012 prior to signing the sale and pur- chase agreement (SPA) dated 28 June 2012, which contravened Housing Development reg- ulations
2012
-
[33]
When the vacant possession was delivered on 22 December 2016, the purchasers filed a claim for damages for late delivery, calculat- ing it from the booking fee payment date to the delivery date, which the Tribunal upheld
2016
-
[34]
Generated Issue Candidates Given Scenario#3:
The developer argued that the calculation should start from the SPA date and questioned the validity of the Tribunal’s decision and the method of calculating the purchase price con- sidering a credit note provided. Generated Issue Candidates Given Scenario#3:
-
[35]
Whether the developer’s collection of a book- ing fee prior to signing the Sale and Purchase Agreement (SPA) was in contravention of Housing Development regulations
-
[36]
Whether the calculation of damages for late delivery should start from the date of the book- ing fee payment or the date of the SPA
-
[37]
Whether the Tribunal’s decision to uphold the purchasers’ claim for damages based on the booking fee payment date is valid
-
[38]
A.9 Example of Sparsity of Mutual Information Legal Facts:
Whether the method of calculating the pur- chase price should consider the credit note provided by the developer. A.9 Example of Sparsity of Mutual Information Legal Facts:
-
[39]
The Appellants, Tioh Chee Seng and Hew Fui Li, purchased a residential unit in Ayuman Suites under a sale and purchase agreement dated 21 October 2015
Fact#1. The Appellants, Tioh Chee Seng and Hew Fui Li, purchased a residential unit in Ayuman Suites under a sale and purchase agreement dated 21 October 2015
2015
-
[40]
The 1st Respondent, Talent Team Sdn
Fact#2. The 1st Respondent, Talent Team Sdn. Bhd., is the developer responsible for constructing Ayuman Suites, while the 2nd Respondent, a legal firm, is alleged to be the stakeholder of certain sums related to the pur- chase
-
[41]
The Appellants claimed late delivery of the property, seeking liquidated ascertained damages (LAD) based on delays exceeding the stipulated timeframes for completion
Fact#3. The Appellants claimed late delivery of the property, seeking liquidated ascertained damages (LAD) based on delays exceeding the stipulated timeframes for completion
-
[42]
Fact#4. The main dispute centers on the cal- culation of the delay—specifically, whether it should be based on the booking fee pay- ment date or the date of signing the sales and purchase agreement
-
[43]
The Sessions Court ruled that the LAD calculation should commence from the signing of the sales and purchase agreement
Fact#5. The Sessions Court ruled that the LAD calculation should commence from the signing of the sales and purchase agreement. Identified Legal Issues (Selected):
-
[44]
Issue #1 (Identified when providing Facts 1–3): Whether the 2nd Respondent, as the alleged stakeholder, has any liability regard- ing the sums related to the purchase
-
[45]
Issue #2 (Identified when providing Facts 1–4): Whether the legal firm, acting as the alleged stakeholder, bears any responsibility in the dispute over the late delivery and calcu- lation of LAD
-
[46]
In this case, Issues #1, #2, and #3 all relate to the liability of the 2nd Respondent (Legal Firm)
Issue #3 (Identified when providing Facts 1–5): Whether the 2nd Respondent (legal firm) has any liability as the alleged stakeholder of certain sums related to the purchase. In this case, Issues #1, #2, and #3 all relate to the liability of the 2nd Respondent (Legal Firm). Once Issue #1 is identified based on Facts 1–3, the sub- sequent iterations—despite...
-
[47]
Do not alter or deviate from the meaning presented in the scenario
-
[48]
Whether
Format each legal issue as "Whether ...", for example: "Whether the alleged agreement between the plaintiff and defendant is enforceable considering the Statute of Frauds."
-
[49]
YOUR FIRST LEGAL ISSUE
Provide your response strictly in JSON format as shown below: {["YOUR FIRST LEGAL ISSUE","YOUR SECOND LEGAL ISSUE", ...} Listing 3: Prompt for Incremental Issue Generation A.11 Evaluation Guideline for Human Facts Evaluation High Distinction (HD): • Facts are presented clearly and concisely in a structured point form. • Closely aligned with statutory lang...
-
[50]
Identify the main dispute and the core facts from the Scenario Facts
-
[51]
Compare the candidate Issue to the dispute: does it address that dispute directly, or is it merely background/ unrelated?
-
[52]
Decide if the Issue adds substantive analysis beyond a basic legal truism
-
[53]
Relevant
Conclude "Relevant" or "Irrelevant" based on the definitions. - Do NOT reveal your reasoning or the steps above. - After finishing your internal analysis, output **exactly one word**- either "Relevant" or "Irrelevant"-and nothing else. ### Scenario Facts {facts} ### Issue {issue} ### Instruction First reason internally following the steps. Then output one...
2094
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.