Exploring High-Order Self-Similarity for Video Understanding
Pith reviewed 2026-05-10 00:55 UTC · model grok-4.3
The pith
Integrating multi-order space-time self-similarities via a lightweight module improves motion modeling across video tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
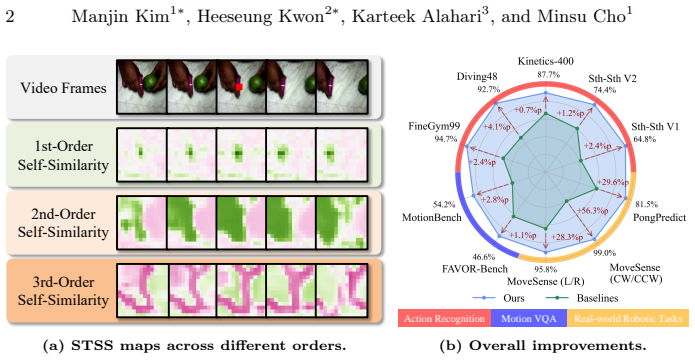
Space-time self-similarity at higher orders reveals distinct aspects of temporal dynamics. The Multi-Order Self-Similarity module is a lightweight neural component that learns and integrates multi-order STSS features to enhance motion modeling capabilities with only marginal computational cost and memory usage. Applied to diverse video tasks, it produces substantial improvements on action recognition, motion-centric video VQA, and real-world robotic tasks.
What carries the argument
The Multi-Order Self-Similarity (MOSS) module, a neural module that learns and integrates multi-order space-time self-similarity features for temporal dynamics.
Load-bearing premise
Higher-order space-time self-similarities supply distinct and complementary information on temporal dynamics that a lightweight integration module can combine effectively without meaningful overhead or loss of accuracy.
What would settle it
Inserting the MOSS module into standard video models and measuring no accuracy gains on action recognition or VQA benchmarks together with increased runtime or memory usage would show the approach does not deliver substantial improvements at marginal cost.
Figures














read the original abstract
Space-time self-similarity (STSS), which captures visual correspondences across frames, provides an effective way to represent temporal dynamics for video understanding. In this work, we explore higher-order STSS and demonstrate how STSSs at different orders reveal distinct aspects of these dynamics. We then introduce the Multi-Order Self-Similarity (MOSS) module, a lightweight neural module designed to learn and integrate multi-order STSS features. It can be applied to diverse video tasks to enhance motion modeling capabilities while consuming only marginal computational cost and memory usage. Extensive experiments on video action recognition, motion-centric video VQA, and real-world robotic tasks consistently demonstrate substantial improvements, validating the broad applicability of MOSS as a general temporal modeling module. The source code and checkpoints will be publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper explores higher-order space-time self-similarity (STSS) for representing temporal dynamics in videos, arguing that STSS at different orders capture distinct aspects of motion. It introduces the Multi-Order Self-Similarity (MOSS) module, a lightweight neural module to learn and integrate these multi-order features. The module is presented as a general-purpose component that can be inserted into video architectures to enhance motion modeling at marginal computational and memory cost. Claims are supported by experiments on action recognition, motion-centric video VQA, and real-world robotic tasks showing consistent improvements, with code and checkpoints to be released.
Significance. If the empirical results hold, MOSS offers a practical, efficient temporal modeling primitive with broad applicability across video tasks. Its lightweight design and plug-and-play nature could see adoption in existing pipelines, particularly if gains are reproducible across datasets and architectures. The planned public release of code and checkpoints strengthens the contribution by enabling verification and extension.
minor comments (3)
- [Abstract] Abstract: the phrasing 'higher-order STSS' and 'multi-order STSS features' is used interchangeably without an explicit definition of the orders considered (e.g., first-order vs. second-order correspondences); a short clarifying sentence would aid readers.
- [§4 or §5] The manuscript states that MOSS consumes 'only marginal computational cost and memory usage'; providing a table or paragraph with exact FLOPs and parameter overhead relative to the backbone (e.g., in §4 or §5) would make this claim more precise and verifiable.
- [Experiments] Experiments section: while tables are referenced, ensuring that every reported improvement includes the corresponding baseline value, metric (e.g., top-1 accuracy, mAP), and dataset split would allow direct assessment of effect sizes.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation for minor revision. We appreciate the recognition that MOSS provides a practical, efficient temporal modeling primitive with broad applicability, and we value the note on the planned public release of code and checkpoints.
Circularity Check
No significant circularity; MOSS module is an independent architectural contribution
full rationale
The paper presents MOSS as a new lightweight neural module for learning and integrating multi-order space-time self-similarity features, with claims supported directly by its definition, integration details, and empirical results across video tasks. No derivation chain, equations, or predictions are shown that reduce by construction to fitted inputs or prior self-citations. The abstract and context describe an empirical validation approach without self-definitional loops, uniqueness theorems, or ansatz smuggling. This is a standard case of a self-contained neural architecture paper whose central claims rest on experimental tables rather than internal reductions.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Multi-Order Self-Similarity (MOSS) module
no independent evidence
Forward citations
Cited by 2 Pith papers
-
RLDX-1 Technical Report
RLDX-1 achieves 86.8% success on complex ALLEX humanoid manipulation tasks where prior VLAs reach only around 40%.
-
RLDX-1 Technical Report
RLDX-1 outperforms frontier VLAs such as π0.5 and GR00T N1.6 on dexterous manipulation benchmarks, reaching 86.8% success on ALLEX humanoid tasks versus around 40% for the baselines.
Reference graph
Works this paper leans on
-
[1]
Vivit: A video vision transformer,
Arnab, A., Dehghani, M., Heigold, G., Sun, C., Lučić, M., Schmid, C.: Vivit: A video vision transformer. arXiv preprint arXiv:2103.15691 (2021)
-
[2]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Assran, M., Bardes, A., Fan, D., Garrido, Q., Howes, R., Muckley, M., Rizvi, A., Roberts, C., Sinha, K., Zholus, A., et al.: V-jepa 2: Self-supervised video models enable understanding, prediction and planning. arXiv preprint arXiv:2506.09985 (2025)
work page internal anchor Pith review arXiv 2025
-
[3]
arXiv preprint arXiv:2312.00826 (2023)
Bae, K., Ahn, G., Kim, Y., Choi, J.: Devias: Learning disentangled video repre- sentations of action and scene for holistic video understanding. arXiv preprint arXiv:2312.00826 (2023)
-
[4]
Revisiting Feature Prediction for Learning Visual Representations from Video
Bardes, A., Garrido, Q., Ponce, J., Chen, X., Rabbat, M., LeCun, Y., Assran, M., Ballas, N.: Revisiting feature prediction for learning visual representations from video. arXiv preprint arXiv:2404.08471 (2024)
work page internal anchor Pith review arXiv 2024
- [5]
- [6]
-
[7]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Bjorck, J., Castañeda, F., Cherniadev, N., Da, X., Ding, R., Fan, L., Fang, Y., Fox, D., Hu, F., Huang, S., et al.: Gr00t n1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734 (2025)
work page internal anchor Pith review arXiv 2025
-
[8]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al.: pi0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164 (2024)
work page internal anchor Pith review arXiv 2024
-
[9]
In: Proceedings of the IEEE/CVF international conference on computer vision
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9650–9660 (2021)
work page 2021
-
[10]
Carreira, J., Zisserman, A.: Quo vadis, action recognition? a new model and the kinetics dataset. In: CVPR (2017)
work page 2017
-
[11]
Chen, Z., Wang, W., Cao, Y., Liu, Y., Gao, Z., Cui, E., Zhu, J., Ye, S., Tian, H., Liu, Z., et al.: Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling. arXiv preprint arXiv:2412.05271 (2024)
work page internal anchor Pith review arXiv 2024
-
[12]
In: European Conference on Computer Vision
Cheng, F., Bertasius, G.: Tallformer: Temporal action localization with a long- memory transformer. In: European Conference on Computer Vision. pp. 503–521. Springer (2022)
work page 2022
-
[13]
Choi, J., Gao, C., Messou, J.C., Huang, J.B.: Why can’t i dance in the mall? learning to mitigate scene bias in action recognition. NeurIPS32(2019)
work page 2019
-
[14]
Chung, J., Wu, Y., Russakovsky, O.: Enabling detailed action recognition evaluation through video dataset augmentation. NeurIPS35, 39020–39033 (2022)
work page 2022
-
[15]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy,A.,Beyer,L.,Kolesnikov,A.,Weissenborn,D.,Zhai,X.,Unterthiner,T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[16]
Dosovitskiy, A., Fischer, P., Ilg, E., Hausser, P., Hazirbas, C., Golkov, V., Van Der Smagt, P., Cremers, D., Brox, T.: Flownet: Learning optical flow with convolu- tional networks. In: ICCV (2015)
work page 2015
-
[17]
Fan, H., Xiong, B., Mangalam, K., Li, Y., Yan, Z., Malik, J., Feichtenhofer, C.: Multiscale vision transformers. arXiv preprint arXiv:2104.11227 (2021) 16 Manjin Kim 1∗, Heeseung Kwon2∗, Karteek Alahari3, and Minsu Cho1
-
[18]
Feichtenhofer, C.: X3d: Expanding architectures for efficient video recognition. In: CVPR (2020)
work page 2020
-
[19]
Feichtenhofer, C., Fan, H., Malik, J., He, K.: Slowfast networks for video recognition. In: ICCV (2019)
work page 2019
-
[20]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Fu, C., Dai, Y., Luo, Y., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y., Zhang, M., et al.: Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24108–24118 (2025)
work page 2025
-
[21]
Goyal, R., Kahou, S.E., Michalski, V., Materzynska, J., Westphal, S., Kim, H., Haenel, V., Fruend, I., Yianilos, P., Mueller-Freitag, M., et al.: The" something something" video database for learning and evaluating visual common sense. In: ICCV (2017)
work page 2017
-
[22]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16000–16009 (2022)
work page 2022
- [23]
- [24]
-
[25]
Qwen2.5-Coder Technical Report
Hui, B., Yang, J., Cui, Z., Yang, J., Liu, D., Zhang, L., Liu, T., Zhang, J., Yu, B., Lu, K., et al.: Qwen2. 5-coder technical report. arXiv preprint arXiv:2409.12186 (2024)
work page internal anchor Pith review arXiv 2024
-
[26]
Idrees, H., Zamir, A.R., Jiang, Y.G., Gorban, A., Laptev, I., Sukthankar, R., Shah, M.: The thumos challenge on action recognition for videos “in the wild”. Computer Vision and Image Understanding155, 1–23 (2017)
work page 2017
-
[27]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Intelligence, P., Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., et al.: pi0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Jang, H., Yu, S., Kwon, H., Jeon, H., Seo, Y., Shin, J.: Contextvla: Vision-language- action model with amortized multi-frame context. arXiv preprint arXiv:2510.04246 (2025)
-
[29]
Junejo, I.N., Dexter, E., Laptev, I., Perez, P.: View-independent action recognition from temporal self-similarities. IEEE TPAMI (2010)
work page 2010
-
[30]
Junejo, I.N., Dexter, E., Laptev, I., PÚrez, P.: Cross-view action recognition from temporal self-similarities. In: ECCV (2008)
work page 2008
-
[31]
The Kinetics Human Action Video Dataset
Kay, W., Carreira, J., Simonyan, K., Zhang, B., Hillier, C., Vijayanarasimhan, S., Viola, F., Green, T., Back, T., Natsev, P., et al.: The kinetics human action video dataset. arXiv preprint arXiv:1705.06950 (2017)
work page internal anchor Pith review arXiv 2017
-
[32]
Kim, M., Kwon, H., Wang, C., Kwak, S., Cho, M.: Relational self-attention: What’s missing in attention for video understanding. NeurIPS34, 8046–8059 (2021)
work page 2021
- [33]
-
[34]
arXiv preprint arXiv:2007.09933 (2020)
Kwon, H., Kim, M., Kwak, S., Cho, M.: Motionsqueeze: Neural motion feature learning for video understanding. arXiv preprint arXiv:2007.09933 (2020)
-
[35]
arXiv preprint arXiv:2102.07092 (2021)
Kwon, H., Kim, M., Kwak, S., Cho, M.: Learning self-similarity in space and time as generalized motion for action recognition. arXiv preprint arXiv:2102.07092 (2021)
-
[36]
Leong, M.C., Zhang, H., Tan, H.L., Li, L., Lim, J.H.: Combined cnn trans- former encoder for enhanced fine-grained human action recognition. arXiv preprint arXiv:2208.01897 (2022) Exploring High-Order Self-Similarity for Video Understanding 17
-
[37]
arXiv preprint arXiv:2206.02985 (2022)
Li, C., Wang, X., Hong, D., Wang, Y., Zhang, L., Luo, T., Wen, L.: Struc- tured context transformer for generic event boundary detection. arXiv preprint arXiv:2206.02985 (2022)
-
[38]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, K., Wang, Y., He, Y., Li, Y., Wang, Y., Liu, Y., Wang, Z., Xu, J., Chen, G., Luo, P., et al.: Mvbench: A comprehensive multi-modal video understanding benchmark. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22195–22206 (2024)
work page 2024
-
[39]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, K., Wang, Y., He, Y., Li, Y., Wang, Y., Wang, L., Qiao, Y.: Uniformerv2: Unlocking the potential of image vits for video understanding. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 1632–1643 (2023)
work page 2023
-
[40]
IEEE Transactions on Pattern Analysis and Machine Intelligence45(10), 12581–12600 (2023)
Li, K., Wang, Y., Zhang, J., Gao, P., Song, G., Liu, Y., Li, H., Qiao, Y.: Uniformer: Unifying convolution and self-attention for visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence45(10), 12581–12600 (2023)
work page 2023
-
[41]
Evaluating Real-World Robot Manipulation Policies in Simulation
Li, X., Hsu, K., Gu, J., Pertsch, K., Mees, O., Walke, H.R., Fu, C., Lunawat, I., Sieh, I., Kirmani, S., et al.: Evaluating real-world robot manipulation policies in simulation. arXiv preprint arXiv:2405.05941 (2024)
work page internal anchor Pith review arXiv 2024
- [42]
-
[43]
Li, Y., Li, Y., Vasconcelos, N.: Resound: Towards action recognition without representation bias. In: ECCV (2018)
work page 2018
-
[44]
In: Proceedings of the 2024 conference on empirical methods in natural language processing
Lin, B., Ye, Y., Zhu, B., Cui, J., Ning, M., Jin, P., Yuan, L.: Video-llava: Learning united visual representation by alignment before projection. In: Proceedings of the 2024 conference on empirical methods in natural language processing. pp. 5971–5984 (2024)
work page 2024
-
[45]
Lin, J., Gan, C., Han, S.: Tsm: Temporal shift module for efficient video under- standing. In: ICCV (2019)
work page 2019
- [46]
-
[47]
Advances in Neural Information Processing Systems36, 44776–44791 (2023)
Liu, B., Zhu, Y., Gao, C., Feng, Y., Liu, Q., Zhu, Y., Stone, P.: Libero: Benchmarking knowledge transfer for lifelong robot learning. Advances in Neural Information Processing Systems36, 44776–44791 (2023)
work page 2023
-
[48]
Liu, H., Li, X., Li, P., Liu, M., Wang, D., Liu, J., Kang, B., Ma, X., Kong, T., Zhang, H.: Towards generalist robot policies: What matters in building vision- language-action models (2025)
work page 2025
-
[49]
arXiv preprint arXiv:2408.06158 (2024)
Liu, M., Li, B., Yu, Y.: Omniclip: Adapting clip for video recognition with spatial- temporal omni-scale feature learning. arXiv preprint arXiv:2408.06158 (2024)
- [50]
-
[51]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, S., Zhang, C.L., Zhao, C., Ghanem, B.: End-to-end temporal action detection with 1b parameters across 1000 frames. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18591–18601 (2024)
work page 2024
- [52]
-
[53]
In: Proceedings of the 30th ACM International Conference on Multimedia
Ma, Y., Xu, G., Sun, X., Yan, M., Zhang, J., Ji, R.: X-clip: End-to-end multi- grained contrastive learning for video-text retrieval. In: Proceedings of the 30th ACM International Conference on Multimedia. pp. 638–647 (2022) 18 Manjin Kim 1∗, Heeseung Kwon2∗, Karteek Alahari3, and Minsu Cho1
work page 2022
-
[54]
On the effectiveness of task granularity for transfer learning
Mahdisoltani, F., Berger, G., Gharbieh, W., Fleet, D., Memisevic, R.: On the effec- tiveness of task granularity for transfer learning. arXiv preprint arXiv:1804.09235 (2018)
work page Pith review arXiv 2018
-
[55]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Nasiriany, S., Maddukuri, A., Zhang, L., Parikh, A., Lo, A., Joshi, A., Mandlekar, A., Zhu, Y.: Robocasa: Large-scale simulation of everyday tasks for generalist robots. arXiv preprint arXiv:2406.02523 (2024)
work page internal anchor Pith review arXiv 2024
- [56]
-
[57]
Advances in Neural Information Processing Systems37, 81808–81835 (2024)
Nie, M., Ding, D., Wang, C., Guo, Y., Han, J., Xu, H., Zhang, L.: Slowfocus: Enhancing fine-grained temporal understanding in video llm. Advances in Neural Information Processing Systems37, 81808–81835 (2024)
work page 2024
-
[58]
Pan, J., Lin, Z., Zhu, X., Shao, J., Li, H.: St-adapter: Parameter-efficient image-to- video transfer learning. NeurIPS35, 26462–26477 (2022)
work page 2022
- [59]
- [60]
- [61]
- [62]
-
[63]
arXiv preprint arXiv:2510.26027 (2025)
Rasekh,A.,Soula,E.B.,Daliran,O.,Gottschalk,S.,Fayyaz,M.:Enhancingtemporal understanding in video-llms through stacked temporal attention in vision encoders. arXiv preprint arXiv:2510.26027 (2025)
-
[64]
Shao, D., Zhao, Y., Dai, B., Lin, D.: Finegym: A hierarchical video dataset for fine-grained action understanding. In: CVPR (2020)
work page 2020
-
[65]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Shao, D., Zhao, Y., Dai, B., Lin, D.: Intra-and inter-action understanding via temporal action parsing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 730–739 (2020)
work page 2020
- [66]
-
[67]
Shechtman, E., Irani, M.: Matching local self-similarities across images and videos. In: CVPR (2007)
work page 2007
-
[68]
Shi, D., Cao, Q., Zhong, Y., An, S., Cheng, J., Zhu, H., Tao, D.: Temporal action localization with enhanced instant discriminability. arXiv preprint arXiv:2309.05590 (2023)
-
[69]
In: Proceedings of the IEEE/CVF international conference on computer vision
Shou, M.Z., Lei, S.W., Wang, W., Ghadiyaram, D., Feiszli, M.: Generic event boundary detection: A benchmark for event segmentation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 8075–8084 (2021)
work page 2021
-
[70]
Simonyan, K., Zisserman, A.: Two-stream convolutional networks for action recog- nition in videos. In: NeurIPS (2014)
work page 2014
- [71]
-
[72]
Sun, D., Yang, X., Liu, M.Y., Kautz, J.: Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume. In: CVPR (2018)
work page 2018
-
[73]
EVA-CLIP: Improved Training Techniques for CLIP at Scale
Sun, Q., Fang, Y., Wu, L., Wang, X., Cao, Y.: Eva-clip: Improved training techniques for clip at scale. arXiv preprint arXiv:2303.15389 (2023) Exploring High-Order Self-Similarity for Video Understanding 19
work page internal anchor Pith review arXiv 2023
-
[74]
arXiv preprint arXiv:2402.04252 (2023) 32 Leong, et al
Sun, Q., Wang, J., Yu, Q., Cui, Y., Zhang, F., Zhang, X., Wang, X.: Eva-clip-18b: Scaling clip to 18 billion parameters. arXiv preprint arXiv:2402.04252 (2024)
-
[75]
IEEE Transactions on Pattern Analysis and Machine Intelligence45(10), 12506–12520 (2023)
Tan, J., Wang, Y., Wu, G., Wang, L.: Temporal perceiver: A general architecture for arbitrary boundary detection. IEEE Transactions on Pattern Analysis and Machine Intelligence45(10), 12506–12520 (2023)
work page 2023
-
[76]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Tang, J., Liu, Z., Qian, C., Wu, W., Wang, L.: Progressive attention on multi-level dense difference maps for generic event boundary detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3355–3364 (2022)
work page 2022
-
[77]
Octo: An Open-Source Generalist Robot Policy
Team, O.M., Ghosh, D., Walke, H., Pertsch, K., Black, K., Mees, O., Dasari, S., Hejna, J., Kreiman, T., Xu, C., et al.: Octo: An open-source generalist robot policy. arXiv preprint arXiv:2405.12213 (2024)
work page internal anchor Pith review arXiv 2024
-
[78]
Teed, Z., Deng, J.: Raft: Recurrent all-pairs field transforms for optical flow. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16. pp. 402–419. Springer (2020)
work page 2020
-
[79]
Tran, D., Bourdev, L., Fergus, R., Torresani, L., Paluri, M.: Learning spatiotemporal features with 3d convolutional networks. In: ICCV (2015)
work page 2015
-
[80]
Tran, D., Wang, H., Torresani, L., Feiszli, M.: Video classification with channel- separated convolutional networks. In: ICCV (2019)
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.