TraceScope: Interactive URL Triage via Decoupled Checklist Adjudication
Pith reviewed 2026-05-09 21:18 UTC · model grok-4.3
The pith
TraceScope decouples page interaction from checklist verification to triage evasive phishing URLs safely at scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TraceScope operationalizes interactive URL triage through a decoupled pipeline: a sandboxed operator agent drives a GUI browser guided by visual motivation to elicit and freeze page behavior into an immutable evidence bundle, while a separate adjudicator agent circumvents context limits by querying the bundle on demand to verify a MITRE ATT&CK checklist, extract indicators of compromise, and issue a final verdict with an audit-ready report.
What carries the argument
The decoupled triage pipeline that separates a sandboxed operator agent (which elicits behavior via visual motivation and freezes an evidence bundle) from an adjudicator agent (which verifies the MITRE ATT&CK checklist via on-demand evidence queries).
If this is right
- Analysts receive reproducible evidence bundles that can be reviewed or re-queried without re-running the live page.
- The approach scales interactive forensics to larger volumes while isolating humans from runtime threats.
- Detection recall rises for phishing that uses delayed rendering or logo-less harvesters compared with snapshot-based tools.
- Automatic extraction of indicators of compromise accompanies each verdict for downstream blocking or investigation.
- The same evidence can support human audit or integration into existing security workflows.
Where Pith is reading between the lines
- The evidence-bundle model could extend to other interactive security tasks such as malware sandboxing or web exploit analysis where live observation is risky.
- If the visual-motivation prompts prove robust across many site designs, the operator agent might reduce the need for per-URL human scripting.
- A measurable drop in false negatives on gated credential pages in controlled red-team tests would strengthen the claim that the separation preserves detection power.
- Longer-term, the checklist-driven adjudication might serve as a template for other domain-specific verification tasks that currently overload LLM context windows.
Load-bearing premise
The operator agent can reliably draw out malicious page behavior through visual cues without missing gated content or triggering exploits, and the adjudicator agent can accurately verify the checklist from the evidence without hallucination or context loss.
What would settle it
A documented case where the operator fails to surface the phishing payload on a known interactive site or where the adjudicator classifies a verified phishing page as benign after reviewing the evidence bundle would falsify the pipeline's reliability.
Figures















read the original abstract
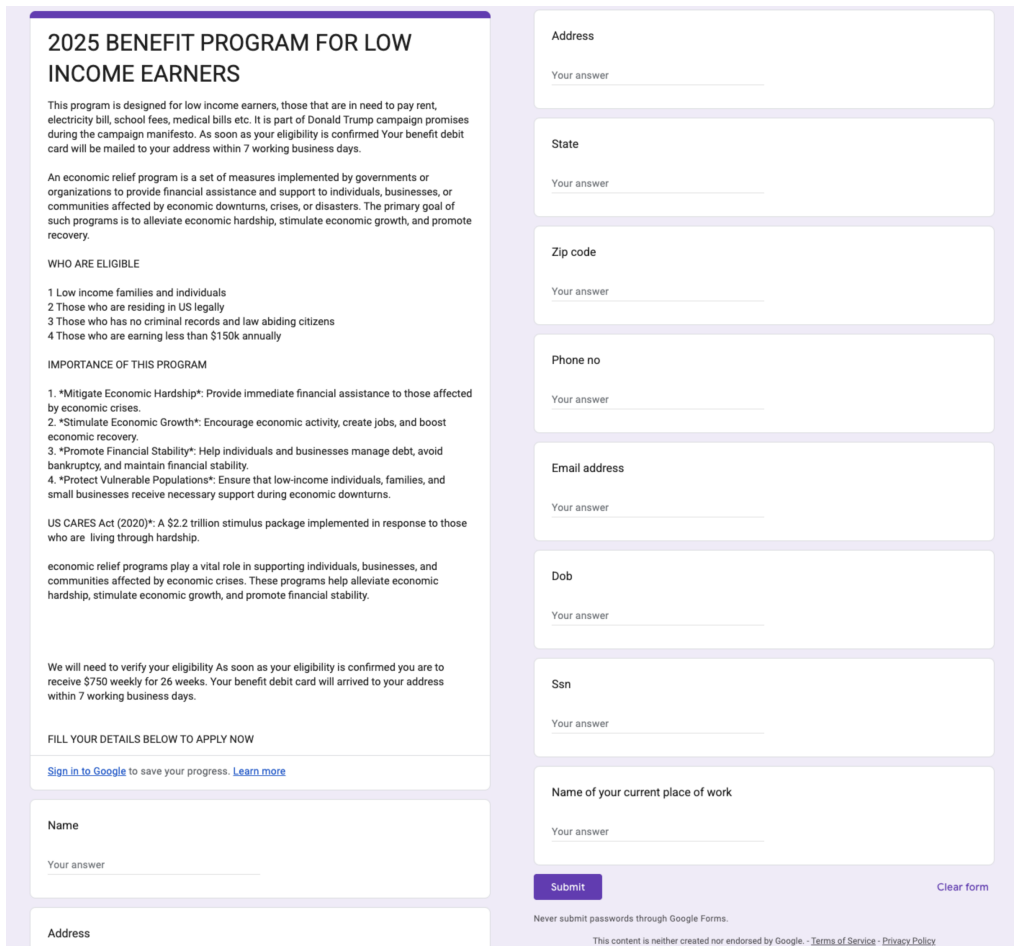
Modern phishing campaigns increasingly evade snapshot-based URL classifiers using interaction gates (e.g., checkbox/slider challenges), delayed content rendering, and logo-less credential harvesters. This shifts URL triage from static classification toward an interactive forensics task: an analyst must actively navigate the page while isolating themselves from potential runtime exploits. We present TraceScope, a decoupled triage pipeline that operationalizes this workflow at scale. To prevent the observer effect and ensure safety, a sandboxed operator agent drives a real GUI browser guided by visual motivation to elicit page behavior, freezing the session into an immutable evidence bundle. Separately, an adjudicator agent circumvents LLM context limitations by querying evidence on demand to verify a MITRE ATT&CK checklist, and generates an audit-ready report with extracted indicators of compromise (IOCs) and a final verdict. Evaluated on 708 reachable URLs from existing dataset (241 verified phishing from PhishTank and 467 benign from Tranco-derived crawling), TraceScope achieves 0.94 precision and 0.78 recall, substantially improving recall over three prior visual/reference-based classifiers while producing reproducible, analyst-grade evidence suitable for review. More importantly, we manually curated a dataset of real-world phishing emails to evaluate our system in a practical setting. Our evaluation reveals that TraceScope demonstrates superior performance in a real-world scenario as well, successfully detecting sophisticated phishing attempts that current state-of-the-art defenses fail to identify.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents TraceScope, a decoupled triage pipeline for interactive URL forensics against evasive phishing. A sandboxed operator agent drives a real GUI browser using visual motivation to elicit gated or delayed page behavior and freeze an immutable evidence bundle; separately, an adjudicator agent queries this bundle on demand to verify a MITRE ATT&CK checklist, extract IOCs, and issue an audit-ready verdict. On 708 reachable URLs (241 verified phishing from PhishTank and 467 benign from Tranco-derived sources), the system reports 0.94 precision and 0.78 recall while outperforming three prior visual/reference-based classifiers; it also shows superior performance on a manually curated real-world phishing email dataset.
Significance. If the agent reliability claims hold, the work offers a practical advance over static snapshot classifiers by addressing interaction gates, delayed rendering, and logo-less harvesters common in modern campaigns. The production of reproducible, analyst-reviewable evidence bundles is a clear strength that could support operational deployment. Evaluation on public datasets plus a real-world email corpus provides a useful benchmark, though the absence of internal validation for the LLM steps limits immediate impact.
major comments (3)
- [Evaluation section] Evaluation section: The 0.94 precision / 0.78 recall figures on the 708-URL set are reported without baseline implementation details, statistical significance tests, or per-class error breakdowns. This weakens the claim of substantial recall improvement over the three prior classifiers.
- [Adjudicator agent description (likely §3.2)] Adjudicator agent description (likely §3.2): No validation, error analysis, or hallucination checks are provided for the on-demand MITRE ATT&CK checklist verification step. Because the final verdict and IOC extraction depend entirely on this LLM-driven query process, any systematic context loss or fabrication would directly inflate the reported metrics and undermine the 'analyst-grade evidence' claim.
- [Operator agent and evidence collection (likely §3.1)] Operator agent and evidence collection (likely §3.1): The sandboxing description does not address failure modes such as missing gated content after visual motivation or the risk of triggering exploits despite isolation; completeness of the immutable evidence bundle is therefore unverified and load-bearing for downstream adjudicator accuracy.
minor comments (3)
- [Abstract] Abstract: 'Tranco-derived crawling' for the 467 benign samples is undefined, leaving the benign-set construction opaque.
- [Abstract] Abstract: The three prior visual/reference-based classifiers are not named or cited, reducing immediate clarity.
- [Real-world evaluation] Real-world evaluation: The manually curated phishing email dataset lacks size, curation criteria, and ground-truth establishment details.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for strengthening the evaluation and agent descriptions. We address each major comment below and will incorporate revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section: The 0.94 precision / 0.78 recall figures on the 708-URL set are reported without baseline implementation details, statistical significance tests, or per-class error breakdowns. This weakens the claim of substantial recall improvement over the three prior classifiers.
Authors: We agree that the evaluation would benefit from greater transparency. In the revised manuscript, we will add detailed implementation descriptions for the three baseline classifiers (including any adaptations made to the original works), report statistical significance tests (e.g., McNemar's test for paired classifier comparisons on the same URL set), and include a per-class error breakdown table or confusion matrix. These additions will better substantiate the recall improvements, particularly for interactive phishing cases. revision: yes
-
Referee: [Adjudicator agent description (likely §3.2)] Adjudicator agent description (likely §3.2): No validation, error analysis, or hallucination checks are provided for the on-demand MITRE ATT&CK checklist verification step. Because the final verdict and IOC extraction depend entirely on this LLM-driven query process, any systematic context loss or fabrication would directly inflate the reported metrics and undermine the 'analyst-grade evidence' claim.
Authors: We acknowledge this as a valid concern given the reliance on LLM adjudication. While the original submission focused on the decoupled design and end-to-end metrics, we will add a dedicated error analysis subsection. This will include manual review of a sampled subset of checklist verifications, discussion of observed hallucination or context-loss cases, and grounding mechanisms (e.g., requiring explicit evidence citations in queries). We note that exhaustive automated validation of all LLM steps is resource-intensive but will strengthen the analyst-grade evidence claim. revision: partial
-
Referee: [Operator agent and evidence collection (likely §3.1)] Operator agent and evidence collection (likely §3.1): The sandboxing description does not address failure modes such as missing gated content after visual motivation or the risk of triggering exploits despite isolation; completeness of the immutable evidence bundle is therefore unverified and load-bearing for downstream adjudicator accuracy.
Authors: We will expand §3.1 to explicitly address these failure modes. The revision will describe how visual motivation prompts are designed to trigger gated or delayed content, the composition of the immutable evidence bundle (screenshots, DOM snapshots, network traces, console logs), observed completeness rates from the evaluation, and sandbox safeguards (restricted privileges, no file system writes, network isolation beyond the target URL). Any cases of incomplete elicitation will be noted as limitations. revision: yes
Circularity Check
No circularity: empirical evaluation on external datasets with no self-referential derivations
full rationale
The paper describes an empirical systems contribution: a decoupled LLM-agent pipeline for interactive URL triage, with performance measured directly against ground-truth labels from independent external sources (PhishTank verified phishing URLs, Tranco-derived benign URLs, and a manually curated real-world phishing email set). No equations, fitted parameters presented as predictions, ansatzes, or uniqueness theorems appear in the provided text. The 0.94 precision / 0.78 recall figures are end-to-end comparisons to those external labels rather than quantities constructed from the system's own outputs or prior self-citations. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM-based agents can safely and reliably drive a real GUI browser to elicit page behavior while remaining isolated from exploits
- domain assumption On-demand evidence querying by the adjudicator agent can overcome LLM context limits and produce accurate MITRE ATT&CK checklist verification
Reference graph
Works this paper leans on
-
[1]
Phishlive: A view of phishing and malware attacks from an edge router
Lianjie Cao, Thibaut Probst, and Ramana Kompella. Phishlive: A view of phishing and malware attacks from an edge router. 03 2013
work page 2013
-
[2]
Sean Gallagher, 2021
work page 2021
-
[3]
The un- reasonable effectiveness of scaling agents for computer use, 2025
Gonzalo Gonzalez-Pumariega, Vincent Tu, Chih-Lun Lee, Jiachen Yang, Ang Li, and Xin Eric Wang. The un- reasonable effectiveness of scaling agents for computer use, 2025
work page 2025
-
[4]
So long, and no thanks for the external- ities: the rational rejection of security advice by users
Cormac Herley. So long, and no thanks for the external- ities: the rational rejection of security advice by users. InProceedings of the 2009 Workshop on New Security Paradigms Workshop, NSPW ’09, page 133–144, New York, NY , USA, 2009. Association for Computing Ma- chinery
work page 2009
-
[5]
Evaluating the effectiveness and robustness of vi- sual similarity-based phishing detection models
Fujiao Ji, Kiho Lee, Hyungjoon Koo, Wenhao You, Euijin Choo, Hyoungshick Kim, and Doowon Kim. Evaluating the effectiveness and robustness of vi- sual similarity-based phishing detection models. In34th USENIX Security Symposium (USENIX Security), 2025. https://www.usenix.org/ system/files/conference/usenixsecurity25/ sec25cycle1-prepub-483-ji.pdf
work page 2025
-
[6]
Guide to integrating forensic techniques into incident response:, 2006-01-01 05:01:00 2006
K Kent, S Chevalier, T Grance, and H Dang. Guide to integrating forensic techniques into incident response:, 2006-01-01 05:01:00 2006
work page 2006
-
[7]
Protecting users against phishing attacks.Comput
Engin Kirda and Christopher Kruegel. Protecting users against phishing attacks.Comput. J., 49(5):554–561, September 2006
work page 2006
-
[8]
Tranco: A research-oriented top sites ranking hard- ened against manipulation
Victor Le Pochat, Tom Van Goethem, Samaneh Tajal- izadehkhoob, Maciej Korczy´nski, and Wouter Joosen. Tranco: A research-oriented top sites ranking hard- ened against manipulation. InNDSS, 2019. https: //tranco-list.eu/assets/tranco-ndss19.pdf
work page 2019
-
[9]
D-fence: A flexible, efficient, and comprehensive phishing email detection system
Jehyun Lee, Farren Tang, Pingxiao Ye, Fahim Abbasi, Phil Hay, and Dinil Mon Divakaran. D-fence: A flexible, efficient, and comprehensive phishing email detection system. In2021 IEEE European Symposium on Security and Privacy (EuroS&P), pages 578–597, 2021
work page 2021
-
[10]
Phishpedia: A hybrid deep learning based approach to visually identify phishing webpages
Yun Lin, Ruofan Liu, Dinil Mon Divakaran, Jun Yang Ng, Qing Zhou Chan, Yiwen Lu, Yuxuan Si, Fan Zhang, and Jin Song Dong. Phishpedia: A hybrid deep learning based approach to visually identify phishing webpages. In30th USENIX Security Symposium (USENIX Security 21), pages 3793–3810. USENIX Association, August 2021. 14
work page 2021
-
[11]
linuxserver/webtop (containerized desktop environment), 2025
LinuxServer.io. linuxserver/webtop (containerized desktop environment), 2025. https://github.com/ linuxserver/docker-webtop
work page 2025
-
[12]
Ruofan Liu, Yun Lin, Xiwen Teoh, Gongshen Liu, Zhiyong Huang, and Jin Song Dong. Less defined knowledge and more true alarms: Reference-based phishing detection without a pre-defined reference list. In33rd USENIX Security Symposium (USENIX Secu- rity), 2024. https://www.usenix.org/conference/ usenixsecurity24/presentation/liu-ruofan
work page 2024
-
[13]
In- ferring phishing intention via webpage appearance and dynamics: A deep vision based approach
Ruofan Liu, Yun Lin, Xianglin Yang, Siang Hwee Ng, Dinil Mon Divakaran, and Jin Song Dong. In- ferring phishing intention via webpage appearance and dynamics: A deep vision based approach. In 31st USENIX Security Symposium (USENIX Security),
-
[14]
https://www.usenix.org/system/files/ sec22-liu-ruofan.pdf
-
[15]
Knowledge expansion and counterfac- tual interaction for Reference-Based phishing detection
Ruofan Liu, Yun Lin, Yifan Zhang, Penn Han Lee, and Jin Song Dong. Knowledge expansion and counterfac- tual interaction for Reference-Based phishing detection. In32nd USENIX Security Symposium (USENIX Secu- rity 23), pages 4139–4156, Anaheim, CA, August 2023. USENIX Association
work page 2023
-
[16]
Samuel Marchal, Jérôme François, Radu State, and Thomas Engel. Phishstorm: Detecting phishing with streaming analytics.IEEE Transactions on Network and Service Management, 11(4):458–471, 2014
work page 2014
- [17]
-
[18]
How fraudsters abuse google forms to spread scams, Apr 2025
Phil Muncaster. How fraudsters abuse google forms to spread scams, Apr 2025
work page 2025
-
[19]
Cloudeforce One, Jan 2026
work page 2026
-
[20]
Phishtank: Community phish- ing url feed, 2025.https://phishtank.org/
OpenDNS / Cisco Talos. Phishtank: Community phish- ing url feed, 2025.https://phishtank.org/
work page 2025
-
[21]
E- phishgen: Unlocking novel research in phishing email detection
Luca Pajola, Eugenio Caripoti, Stefan Banzer, Sime- one Pizzi, Mauro Conti, and Giovanni Apruzzese. E- phishgen: Unlocking novel research in phishing email detection. InProceedings of the 18th ACM Workshop on Artificial Intelligence and Security, AISec ’25, page 64–76, New York, NY , USA, 2026. Association for Com- puting Machinery
work page 2026
-
[22]
Phish- ing campaigns targeting higher education institutions | google cloud blog, Feb 2025
Ashley Pearson, Jessica Wilbur, Ryan Magaw, Brian Timberlake, Gabriel Simches, and Ryan Rath. Phish- ing campaigns targeting higher education institutions | google cloud blog, Feb 2025
work page 2025
-
[23]
The Human Factor 2025: Phishing and URL- Based Threats
Proofpoint. The Human Factor 2025: Phishing and URL- Based Threats. Threat report (PDF), 2025. Accessed: 2026-01-08
work page 2025
-
[24]
Niels Provos, Panayiotis Mavrommatis, Moheeb Abu Rajab, and Fabian Monrose. All your iframes point to us. InProceedings of the 17th Conference on Security Symposium, SS’08, page 1–15, USA, 2008. USENIX Association
work page 2008
-
[25]
Ui-tars: Pioneering automated gui interaction with native agents, 2025
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shi- hao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, Wanjun Zhong, Kuanye Li, Jiale Yang, Yu Miao, Woyu Lin, Longxiang Liu, Xu Jiang, Qianli Ma, Jingyu Li, Xiaojun Xiao, Kai Cai, Chuang Li, Yaowei Zheng, Chaolin Jin, Chen Li, Xiao Zhou, Minchao Wang, Haoli Chen, Zhaojian Li, Haihua ...
work page 2025
-
[26]
Bradley Reaves, Logan Blue, Dave Tian, Patrick Traynor, and Kevin R.B. Butler. Detecting sms spam in the age of legitimate bulk messaging. InProceedings of the 9th ACM Conference on Security & Privacy in Wire- less and Mobile Networks, WiSec ’16, page 165–170, New York, NY , USA, 2016. Association for Computing Machinery
work page 2016
-
[27]
Bradley Reaves, Nolen Scaife, Adam Bates, Patrick Traynor, and Kevin R.B. Butler. Mo(bile) money, mo(bile) problems: Analysis of branchless banking ap- plications in the developing world. In24th USENIX Se- curity Symposium (USENIX Security 15), pages 17–32, Washington, D.C., August 2015. USENIX Association
work page 2015
-
[28]
Scam sniffer 2024: Web3 phishing attacks - wallet drainers drain $494 million, Jan 2025
Researcher. Scam sniffer 2024: Web3 phishing attacks - wallet drainers drain $494 million, Jan 2025
work page 2024
-
[29]
Filipo Sharevski and Aziz Zeidieh. Assessing suspi- cious emails with banner warnings among blind and Low-Vision users in realistic settings. In33rd USENIX Security Symposium (USENIX Security 24), pages 2083– 2100, Philadelphia, PA, August 2024. USENIX Associ- ation
work page 2083
-
[30]
Reflexion: Language agents with verbal reinforcement learning, 2023
Noah Shinn, Federico Cassano, Edward Berman, Ash- win Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning, 2023
work page 2023
-
[31]
Who is targeted by email-based phishing and malware? measuring factors that differentiate risk
Camelia Simoiu, Ali Zand, Kurt Thomas, and Elie Bursztein. Who is targeted by email-based phishing and malware? measuring factors that differentiate risk. InProceedings of the ACM Internet Measurement Con- ference, IMC ’20, page 567–576, New York, NY , USA,
-
[32]
Association for Computing Machinery
-
[33]
Mitre att&ck: Design and philosophy
Blake E Strom, Andy Applebaum, Doug P Miller, Kathryn C Nickels, Adam G Pennington, and Cody B Thomas. Mitre att&ck: Design and philosophy. In Technical report. The MITRE Corporation, 2018. 15
work page 2018
-
[34]
Understanding crypto drainers, May 2024
Chainalysis Team. Understanding crypto drainers, May 2024
work page 2024
-
[35]
Xiwen Teoh, Yun Lin, Ruofan Liu, Zhiyong Huang, and Jin Song Dong. PhishDecloaker: Detecting CAPTCHA- cloaked phishing websites via hybrid vision-based in- teractive models. In33rd USENIX Security Symposium (USENIX Security 24), pages 505–522, Philadelphia, PA, August 2024. USENIX Association
work page 2024
-
[36]
Users really do answer telephone scams
Huahong Tu, Adam Doupé, Ziming Zhao, and Gail- Joon Ahn. Users really do answer telephone scams. In28th USENIX Security Symposium (USENIX Security 19), pages 1327–1340, Santa Clara, CA, August 2019. USENIX Association
work page 2019
-
[37]
2025 Data Breach Investigations Report
Verizon. 2025 Data Breach Investigations Report. PDF,
work page 2025
-
[38]
Accessed: 2026-01-08
work page 2026
-
[39]
Llm-powered autonomous agents.lilian- weng.github.io, Jun 2023
Lilian Weng. Llm-powered autonomous agents.lilian- weng.github.io, Jun 2023
work page 2023
-
[40]
TRIDENT: Towards detect- ing and mitigating web-based social engineering attacks
Zheng Yang, Joey Allen, Matthew Landen, Roberto Perdisci, and Wenke Lee. TRIDENT: Towards detect- ing and mitigating web-based social engineering attacks. In32nd USENIX Security Symposium (USENIX Secu- rity 23), pages 6701–6718, Anaheim, CA, August 2023. USENIX Association
work page 2023
-
[41]
The dawn of lmms: Preliminary explorations with gpt- 4v(ision), 2023
Zhengyuan Yang, Linjie Li, Kevin Lin, Jianfeng Wang, Chung-Ching Lin, Zicheng Liu, and Lijuan Wang. The dawn of lmms: Preliminary explorations with gpt- 4v(ision), 2023
work page 2023
-
[42]
Penghui Zhang, Zhibo Sun, Sukwha Kyung, Hans Wal- ter Behrens, Zion Leonahenahe Basque, Haehyun Cho, Adam Oest, Ruoyu Wang, Tiffany Bao, Yan Shoshi- taishvili, Gail-Joon Ahn, and Adam Doupé. I’m sparta- cus, no, i’m spartacus: Proactively protecting users from phishing by intentionally triggering cloaking behavior. InProceedings of the 2022 ACM SIGSAC Con...
work page 2022
-
[43]
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neu- big. Webarena: A realistic web environment for building autonomous agents, 2024. A System Prompts and Agent Instructions This appendix provides the system prompts used to initialize the core agents with...
work page 2024
- [44]
- [45]
-
[46]
TEXT: “Contact Support” - URL: “https://example.com/support” Based on the image, which link is the primary CTA? Respond with the number of the link from the list above. Only respond with the number. Figure 11: The zero-shot prompt template used to guide the Vision-Language Model. The model receives this text prompt alongside the sanitized email screenshot...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.