Optimal Question Selection from a Large Question Bank for Clinical Field Recovery in Conversational Psychiatric Intake
Pith reviewed 2026-05-09 21:08 UTC · model grok-4.3
The pith
An LLM-guided policy for selecting questions from a large bank recovers more target clinical information than fixed forms or random selection in psychiatric intake conversations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
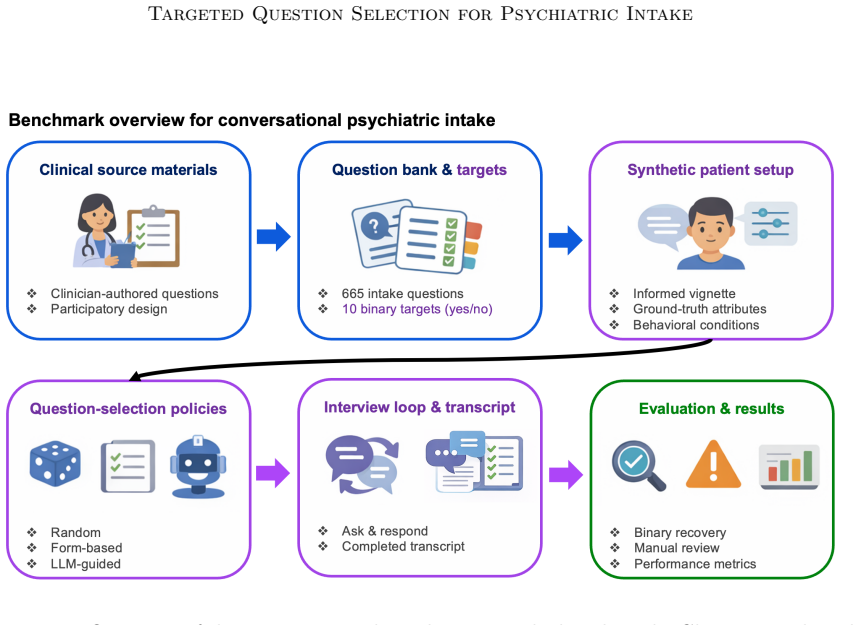
The LLM-guided adaptive policy achieves the strongest overall recovery of target clinical fields across the benchmark, and its advantage over the fixed clinical intake form grows sharply under patient behaviors less amenable to field recovery, especially guarded-concise conditions. The evaluation compares this policy against random questioning and the standard ordered form in 300 interview sessions spanning four patients and five behavioral conditions.
What carries the argument
The LLM-guided adaptive policy that chooses the next question from the 655-question bank by conditioning on the current conversation state and remaining information targets.
If this is right
- Clinical conversational systems must incorporate explicit mechanisms for choosing which topics to pursue rather than relying solely on response interpretation after disclosure.
- Adaptation yields the largest gains precisely when patient responses are least forthcoming, implying that static forms leave recoverable information on the table under realistic reluctance.
- A controlled benchmark with known targets and variable patient difficulty enables systematic testing of question-selection strategies before deployment.
- Performance in high-stakes intake depends on reaching the right subset of questions within a fixed interaction length.
Where Pith is reading between the lines
- The same selection approach could be tested in other structured medical interviews where clinicians must cover a known set of topics under variable patient cooperation.
- If the advantage holds, training data for clinical dialogue agents should emphasize decision traces over question order rather than only final answers.
- Extending the benchmark to include real-time patient simulators with evolving internal states would allow measurement of policy robustness beyond fixed vignettes.
Load-bearing premise
The synthetic patient vignettes with five behavioral conditions and controllable difficulty levels sufficiently capture the ambiguity, reluctance, and response patterns of real patients during live psychiatric intake.
What would settle it
A direct comparison of the LLM-guided policy versus the fixed clinical form in live sessions with actual patients, measuring the fraction of target clinical fields recovered within the same turn budget.
Figures





read the original abstract
Psychiatric intake is a sequential, high-stakes information-gathering process in which clinicians must decide what to ask, in what order, and how to interpret incomplete or ambiguous responses under limited time. Despite growing interest in conversational AI for healthcare, there is still limited infrastructure for conversational AI in this application. Accordingly, we formulate this task as a question-selection problem with clinically grounded questions, known target information, and controllable patient difficulty. We also introduce a task-specific question-selection benchmark based on a bank of 655 clinician-authored intake questions and corresponding synthetic patient vignettes with 5 different behavioral conditions. In our evaluation, we compare random questioning, a clinical psychiatric intake form baseline, and an LLM-guided adaptive policy across 300 interview sessions spanning four patients and five behavioral conditions. Across the benchmark, the clinically ordered fixed form substantially outperforms random questioning, and the LLM-guided policy achieves the strongest overall recovery. The advantage of adaptation grows sharply under patient behavior that is less amenable to field recovery, especially under guarded-concise conditions. These findings suggest that performance in conversational clinical systems depends not only on language understanding after information is disclosed, but also on whether the system reaches the right topics within a limited interaction budget. More broadly, the benchmark provides a controlled framework for studying how clinical structure and adaptive follow-up contribute to information recovery in interactive clinical machine learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formulates psychiatric intake as a sequential question-selection problem with clinically grounded questions and known target fields. It introduces a benchmark based on a bank of 655 clinician-authored questions and synthetic patient vignettes under five controllable behavioral conditions, then evaluates random questioning, a fixed clinical form baseline, and an LLM-guided adaptive policy over 300 synthetic interview sessions spanning four patients. The central empirical claim is that the LLM-guided policy achieves the strongest overall information recovery, with its advantage increasing sharply under less amenable patient behaviors, particularly guarded-concise conditions.
Significance. If the synthetic benchmark is shown to be representative, the work supplies a reproducible, controlled testbed for studying adaptive question selection in clinical dialogue systems—an area that currently lacks such infrastructure. The clinician-authored question bank and the five behavioral conditions with controllable difficulty constitute a clear methodological contribution that enables systematic head-to-head comparisons of static versus adaptive policies.
major comments (3)
- [Evaluation] Evaluation section: the comparative results for the LLM-guided policy are reported without any implementation details on policy mechanics (prompt construction, state tracking, or selection criterion), the generative process for synthetic patient responses under each of the five behavioral conditions, or the exact operational definition and computation of field recovery. These omissions are load-bearing for the claim that the LLM policy delivers the strongest recovery.
- [Benchmark description] Benchmark and results: recovery is defined solely relative to target fields in the synthetic vignettes, yet no validation is provided (clinician ratings of vignette realism, alignment with real intake transcripts, or live-patient pilot) that the five behavioral conditions capture the range of ambiguity, reluctance, and multi-turn withholding seen in actual psychiatric intake. This directly affects the generalizability of the reported finding that adaptation advantage grows under guarded-concise conditions.
- [Results] Results: no quantitative recovery percentages, standard deviations across the 300 sessions, statistical significance tests, or ablation studies are supplied to substantiate the statements of 'strongest overall recovery' and 'advantage grows sharply.' Without these, the magnitude and reliability of the policy differences cannot be assessed.
minor comments (2)
- [Abstract] The abstract states that sessions 'span four patients and five behavioral conditions' but does not specify session length, termination criteria, or how the 300 sessions are allocated across conditions.
- [Introduction] Additional citations to prior adaptive dialogue work in medical domains would help situate the benchmark relative to existing conversational AI literature.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. We address each major comment below and have revised the manuscript to improve transparency and completeness.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the comparative results for the LLM-guided policy are reported without any implementation details on policy mechanics (prompt construction, state tracking, or selection criterion), the generative process for synthetic patient responses under each of the five behavioral conditions, or the exact operational definition and computation of field recovery. These omissions are load-bearing for the claim that the LLM policy delivers the strongest recovery.
Authors: We agree that these details are essential for reproducibility. In the revised manuscript, we have expanded Section 4 (Evaluation) with a full description of the LLM-guided policy (including prompt templates, state tracking via conversation history, and selection criterion based on expected information gain), the generative process for synthetic responses under each behavioral condition (with explicit rules and examples for guarded-concise, etc.), and the precise operational definition of field recovery (exact string matching plus semantic equivalence checks against target fields, computed per session). revision: yes
-
Referee: [Benchmark description] Benchmark and results: recovery is defined solely relative to target fields in the synthetic vignettes, yet no validation is provided (clinician ratings of vignette realism, alignment with real intake transcripts, or live-patient pilot) that the five behavioral conditions capture the range of ambiguity, reluctance, and multi-turn withholding seen in actual psychiatric intake. This directly affects the generalizability of the reported finding that adaptation advantage grows under guarded-concise conditions.
Authors: We acknowledge this limitation: the benchmark is synthetic by design to provide controllable ground truth, and we did not perform clinician ratings or real-transcript alignment in this study. In the revised Discussion (new Limitations subsection), we explicitly note the absence of such validation, describe how the conditions were derived from clinician-authored questions, and outline future work involving expert review. We have tempered claims about real-world generalizability while arguing that the controlled testbed remains valuable for comparing policies. revision: partial
-
Referee: [Results] Results: no quantitative recovery percentages, standard deviations across the 300 sessions, statistical significance tests, or ablation studies are supplied to substantiate the statements of 'strongest overall recovery' and 'advantage grows sharply.' Without these, the magnitude and reliability of the policy differences cannot be assessed.
Authors: We apologize for the lack of explicit numbers in the main text. The revised manuscript now includes Table 2 reporting mean field recovery percentages and standard deviations for each policy across the 300 sessions, results of statistical tests (paired t-tests with p-values and effect sizes), and an ablation study on the LLM policy's components (e.g., removing state tracking). These additions directly support the claims with quantitative evidence. revision: yes
Circularity Check
Empirical benchmark evaluation is self-contained with no circular derivations
full rationale
The paper formulates the task as a question-selection problem and evaluates policies empirically on a benchmark consisting of 655 clinician-authored questions and synthetic patient vignettes under 5 behavioral conditions. Performance is measured by information field recovery across 300 sessions. No mathematical derivations, parameter fittings, or self-citations are presented that would make the reported advantages equivalent to the inputs by construction. The comparisons (random, fixed form, LLM-guided) are direct and externally benchmarked.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic vignettes with five behavioral conditions accurately represent real patient response patterns and ambiguity in psychiatric intake
Reference graph
Works this paper leans on
- [1]
-
[2]
Journal of Medical Internet Research , volume=
Virtual Patient Simulations in Health Professions Education: Systematic Review and Meta-Analysis by the Digital Health Education Collaboration , author=. Journal of Medical Internet Research , volume=
-
[3]
Uptake, Adherence, and Attrition in Clinical Trials of Depression and Anxiety Apps: A Systematic Review and Meta-Analysis , author=. JAMA psychiatry , volume=. 2026 , publisher=
work page 2026
-
[4]
The Canadian Journal of Psychiatry , volume=
Chatbots and Conversational Agents in Mental Health: A Review of the Psychiatric Landscape , author=. The Canadian Journal of Psychiatry , volume=
-
[5]
Journal of the American Medical Informatics Association , volume=
Conversational Agents in Healthcare: A Systematic Review , author=. Journal of the American Medical Informatics Association , volume=
-
[6]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
work page 2023
-
[7]
arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Proceedings of the 5th Machine Learning for Healthcare Conference , series=
Clinical Collabsheets: 53 Questions to Guide a Clinical Collaboration , author=. Proceedings of the 5th Machine Learning for Healthcare Conference , series=
-
[9]
American Journal of Psychiatry , volume=
The American Psychiatric Association Practice Guidelines for the Psychiatric Evaluation of Adults , author=. American Journal of Psychiatry , volume=. 2015 , doi=
work page 2015
-
[10]
arXiv preprint arXiv:2602.02034 , year=
Constrained Process Maps for Multi-Agent Generative AI Workflows , author=. arXiv preprint arXiv:2602.02034 , year=
-
[11]
R3 Report Issue 18: National Patient Safety Goal for Suicide Prevention , author=. 2018 , journal=
work page 2018
-
[12]
Clinical Psychology Review , volume=
Disclosure of suicidal ideation and behaviours: A systematic review and meta-analysis of prevalence , author=. Clinical Psychology Review , volume=. 2023 , doi=
work page 2023
-
[13]
Screening and Behavioral Counseling Interventions to Reduce Unhealthy Alcohol Use in Adolescents and Adults:. JAMA , volume=. 2018 , doi=
work page 2018
-
[14]
Interventions for Tobacco Smoking Cessation in Adults, Including Pregnant Persons:. JAMA , volume=. 2021 , doi=
work page 2021
-
[15]
American Family Physician , volume=
Patient-Centered Communication: Basic Skills , author=. American Family Physician , volume=. 2017 , pmid=
work page 2017
-
[16]
Future Healthcare Journal , volume=
An evaluation of automated, internet-based psychiatric history taking , author=. Future Healthcare Journal , volume=. 2018 , doi=
work page 2018
-
[17]
Medical Clinics of North America , volume=
Psychiatric Emergencies: Assessing and Managing Suicidal Ideation , author=. Medical Clinics of North America , volume=. 2017 , doi=
work page 2017
-
[18]
MedDialog: Large-scale Medical Dialogue Datasets , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=. 2020 , doi=
work page 2020
-
[19]
American Journal of Psychiatry , volume=
Practice Guideline for the Psychiatric Evaluation of Adults, Second Edition , author=. American Journal of Psychiatry , volume=
-
[20]
First, Michael B. and Williams, Janet B. W. and Karg, Ren. Structured Clinical Interview for. 2016 , publisher=
work page 2016
-
[21]
and Lecrubier, Yves and Sheehan, K
Sheehan, David V. and Lecrubier, Yves and Sheehan, K. Harnett and Amorim, Patr. The. Journal of Clinical Psychiatry , volume=
-
[22]
and Stanley, Barbara and Brent, David A
Posner, Kelly and Brown, Gregory K. and Stanley, Barbara and Brent, David A. and Yershova, Kseniya V. and Oquendo, Maria A. and Currier, Glenn W. and Melvin, Glenn A. and Greenhill, Laurence and Sackeim, Sarah and Mann, J. John , journal=. The
- [23]
-
[24]
Do no harm: a roadmap for responsible machine learning for health care , author=. Nature Medicine , volume=. 2019 , doi=
work page 2019
-
[25]
Kroenke, Kurt and Spitzer, Robert L. and Williams, Janet B. W. , journal=. The. 2001 , doi=
work page 2001
-
[26]
and Kroenke, Kurt and Williams, Janet B
Spitzer, Robert L. and Kroenke, Kurt and Williams, Janet B. W. and L. A brief measure for assessing generalized anxiety disorder: the. Archives of Internal Medicine , volume=. 2006 , doi=
work page 2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.