Insect-inspired modular architectures as inductive biases for reinforcement learning
Pith reviewed 2026-05-09 21:56 UTC · model grok-4.3
The pith
Insect-inspired modular RL policies outperform centralized controllers on navigation tasks with competing objectives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
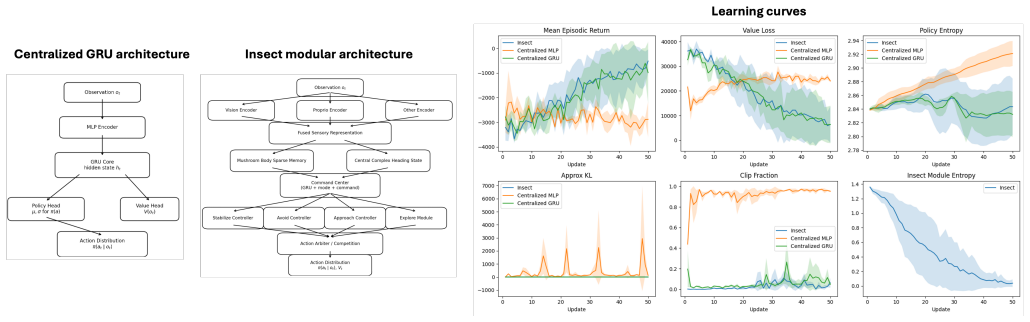
The authors show that their insect-inspired modular policy architecture, which separates control into interacting modules for sensory processing, heading, memory, command generation, and local actuation with a learned arbitration mechanism, achieves a final mean episodic return of -2798.8 ± 964.4 in a predator-navigation experiment after 75 PPO updates, outperforming a centralized GRU (-3778.0 ± 628.1) and MLP (-4727.5 ± 772.5) while also exhibiting the lowest value loss and driving module assignment entropy to 0.0457 ± 0.0244.
What carries the argument
The modular policy with learned arbitration mechanism that allocates motor authority across specialized modules for encoding, heading, memory, commands, and control.
Load-bearing premise
Performance differences arise from the modular decomposition and arbitration mechanism rather than from differences in total parameter count or hyperparameter choices.
What would settle it
Re-running the experiment with all architectures adjusted to have identical parameter counts and the same hyperparameter settings, then checking whether the modular version still shows superior returns and stability.
Figures
read the original abstract
Most reinforcement-learning (RL) controllers used in continuous control are architecturally centralized: observations are compressed into a single latent state from which both value estimates and actions are produced. Biological control systems are often organized differently. Insects, in particular, coordinate navigation, heading stabilization, memory, and context-dependent action selection through distributed circuits rather than a single monolithic controller. Motivated by this contrast, we study an RL policy architecture that decomposes control into interacting modules for sensory encoding, heading representation, sparse associative memory, recurrent command generation, and local motor control, with a learned arbitration mechanism that allocates motor authority across modules. The model is evaluated on a two-dimensional navigation task that require simultaneous food seeking, obstacle avoidance, and predator escape. In a six-seed predator-navigation experiment trained with Proximal Policy Optimization (PPO) for 75 updates, the modular policy achieves the strongest final mean performance among the tested controllers, with final episodic return $-2798.8\pm964.4$ versus $-3778.0\pm628.1$ for a centralized gated recurrent unit (GRU) and $-4727.5\pm772.5$ for a centralized multilayer perceptron (MLP). The modular policy also attains the lowest final value loss and stable PPO optimization statistics while driving module-assignment entropy to $0.0457\pm0.0244$, indicating highly selective control allocation. These results suggest that distributed control can serve as a useful inductive bias for RL problems involving dynamically competing behavioral objectives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an insect-inspired modular RL policy architecture decomposing control into modules for sensory encoding, heading representation, sparse associative memory, recurrent command generation, and local motor control, coordinated by a learned arbitration mechanism. On a 2D predator-navigation task with competing objectives (food seeking, obstacle avoidance, predator escape), trained via PPO for 75 updates, the modular policy reports superior final mean episodic return of −2798.8±964.4 (six seeds) versus −3778.0±628.1 for a centralized GRU and −4727.5±772.5 for a centralized MLP, along with lowest value loss, stable optimization, and low module-assignment entropy of 0.0457±0.0244.
Significance. If the performance ordering holds under capacity-matched conditions, the work shows that biologically motivated modular decompositions with arbitration can act as useful inductive biases for RL in multi-objective continuous control, promoting specialization and training stability. The multi-seed statistics and entropy metric are strengths that support the empirical claims.
major comments (1)
- [predator-navigation experiment] In the predator-navigation experiment (abstract and results): the central performance claim that the modular architecture outperforms the baselines (−2798.8±964.4 vs. −3778.0±628.1 and −4727.5±772.5) specifically due to the decomposition and arbitration is load-bearing, yet the manuscript provides no parameter counts for any model and no statement that hidden sizes were chosen to equalize total capacity. This leaves open that the gap may arise from unmatched model size or tuning rather than the inductive bias.
minor comments (1)
- The abstract notes 'lowest value loss' and 'stable PPO statistics' without providing the numerical values or referencing specific figures/tables; adding these would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's significance. We address the major comment on the predator-navigation experiment below and will revise the manuscript to strengthen the empirical claims.
read point-by-point responses
-
Referee: In the predator-navigation experiment (abstract and results): the central performance claim that the modular architecture outperforms the baselines (−2798.8±964.4 vs. −3778.0±628.1 and −4727.5±772.5) specifically due to the decomposition and arbitration is load-bearing, yet the manuscript provides no parameter counts for any model and no statement that hidden sizes were chosen to equalize total capacity. This leaves open that the gap may arise from unmatched model size or tuning rather than the inductive bias.
Authors: We agree this is a valid concern and that explicit capacity matching strengthens the interpretation. In the revised manuscript we will add a dedicated subsection (and table) reporting the exact parameter counts for the modular policy, the centralized GRU, and the centralized MLP. Hidden sizes were chosen via preliminary sweeps to yield stable training and reasonable performance for each architecture; the modular design inherently distributes parameters across specialized sub-networks, which precludes exact one-to-one matching but was intended to keep total capacity comparable. We will also state this selection criterion explicitly. The performance advantage is further corroborated by the modular policy's lowest value loss and near-zero module-assignment entropy, metrics that are not solely explained by raw parameter count. We thank the referee for highlighting this omission. revision: yes
Circularity Check
No circularity: empirical RL training results are direct experimental outputs, not self-referential derivations
full rationale
The paper reports side-by-side PPO training outcomes (episodic returns, value loss, module entropy) for a proposed modular architecture versus centralized GRU and MLP baselines on a predator-navigation task. No equations, fitted parameters, or predictions are defined in terms of the reported metrics themselves, and no self-citation chains or uniqueness theorems are invoked to derive the performance ordering. The central claim rests on observed training statistics rather than any reduction of outputs to inputs by construction, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The navigation environment can be treated as a Markov decision process amenable to PPO training.
- domain assumption Differences in final episodic return and value loss are attributable to the modular architecture rather than confounding factors such as parameter count.
Reference graph
Works this paper leans on
- [1]
-
[2]
J. E. M. Bennett, A. Philippides, and T. Nowotny. Learning with reinforcement prediction errors in a model of the Drosophila mushroom body.Nature Communications, 12:2569, 2021
work page 2021
-
[3]
P. Dayan and G. E. Hinton. Feudal reinforcement 4 learning. InAdvances in Neural Information Process- ing Systems 5, pages 271–278, 1993
work page 1993
-
[4]
R. Goulard, A. Adden, and B. Webb. Emergent spatial goals in an integrative model of the in- sect central complex.PLoS Computational Biology, 19(11):e1011480, 2023
work page 2023
-
[5]
S. Heinze. Variations on an ancient theme—the cen- tral complex.Current Opinion in Insect Science, 64:101205, 2024
work page 2024
-
[6]
A. Honkanen, A. Adden, J. da Silva Freitas, and S. Heinze. The insect central complex and the neural ba- sis of navigational strategies.Journal of Experimental Biology, 222(Suppl 1):jeb188854, 2019
work page 2019
-
[7]
R. A. Jacobs, M. I. Jordan, S. J. Nowlan, and G. E. Hinton. Adaptive mixtures of local experts.Neural Computation, 3(1):79–87, 1991
work page 1991
-
[8]
S. S. Kim, H. Rouault, S. Druckmann, and V. Ja- yaraman. Ring attractor dynamics in the Drosophila central brain.Science, 356(6340):849–853, 2017
work page 2017
-
[9]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms. arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
J. D. Seelig and V. Jayaraman. Neural dynamics for landmark orientation and angular path integration. Nature, 521:186–191, 2015
work page 2015
-
[11]
R. S. Sutton, D. Precup, and S. Singh. Between MDPs and semi-MDPs: A framework for temporal abstrac- tion in reinforcement learning.Artificial Intelligence, 112(1–2):181–211, 1999
work page 1999
-
[12]
B. Webb. Beyond prediction error: 25 years of modeling the mushroom body.Learning Memory, 31:a053824, 2024. 5
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.