DPRM: A Plug-in Doob h transform-induced Token-Ordering Module for Diffusion Language Models
Pith reviewed 2026-05-08 04:09 UTC · model grok-4.3
The pith
DPRM introduces a plug-in module that shifts token ordering in diffusion language models from confidence rules to Doob h-transform process reward guidance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
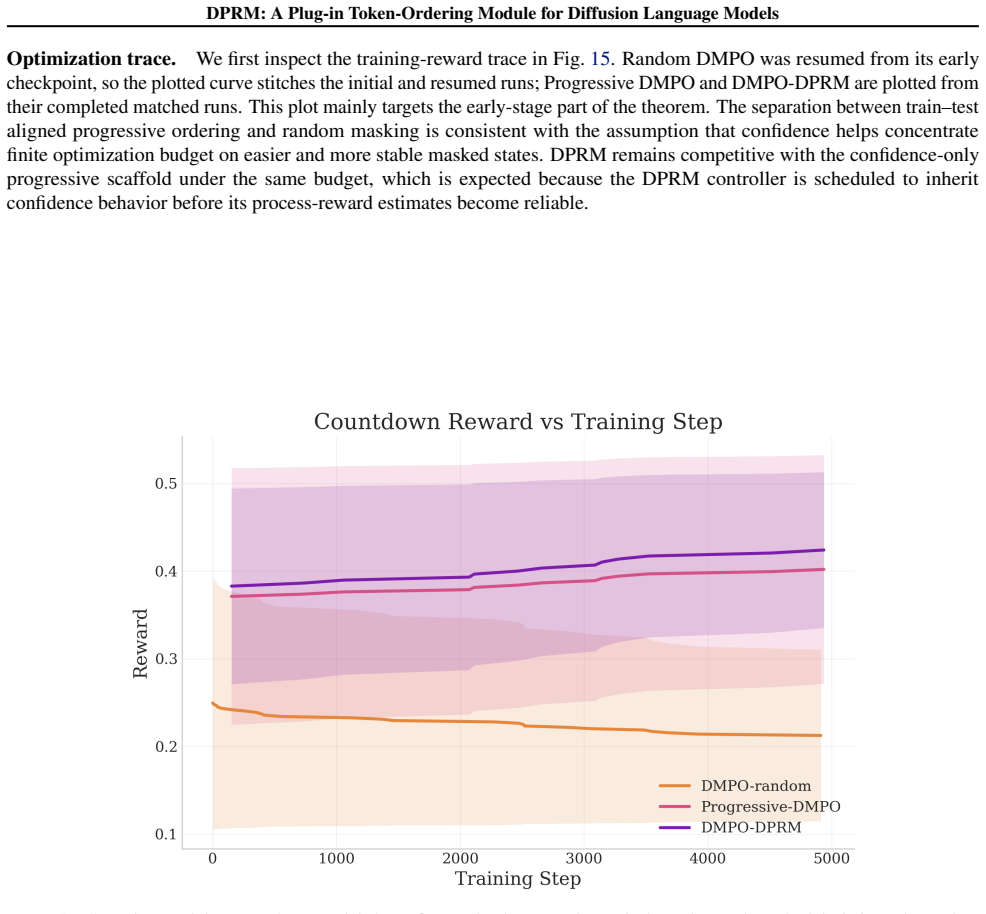
DPRM keeps the host architecture, denoising objective and supervision unchanged, and changes only the ordering policy. It starts from confidence-driven progressive ordering and gradually shifts to Doob h transform Process Reward guided ordering through online estimates. The exact DPRM policy is characterized as a reward-tilted Gibbs reveal law, with O(1/N) convergence of the stagewise Soft-BoN approximation and online bucketized controller tracking at empirical-Bernstein rates. Under tractable optimization assumptions this yields a sample-complexity advantage over random and confidence-only ordering, with observed gains over baselines in pretraining, post-training, test-time scaling and mask
What carries the argument
The DPRM policy, defined as the reward-tilted Gibbs reveal law induced by the Doob h-transform of the process reward, which gradually replaces confidence-driven ordering via online estimates.
Load-bearing premise
The online bucketized controller tracks the exact DPRM score at empirical-Bernstein rates and tractable optimization assumptions hold to deliver sample-complexity advantage over random and confidence-only ordering.
What would settle it
A controlled experiment on a hard reasoning benchmark that finds no accuracy improvement when the full DPRM policy is used versus a confidence-only baseline would falsify the central performance claims.
Figures

















read the original abstract
Diffusion language models generate without a fixed left-to-right order, making token ordering a central algorithmic choice: which tokens should be revealed, retained, revised or verified at each step? Existing systems mainly use random masking or confidence-driven ordering. Random masking creates train--test mismatch, while confidence-only rules are efficient but can be myopic and suppress useful exploration. We introduce DPRM (Doob h-transform Process Reward Model), a plug-in token-ordering module for diffusion language models. DPRM keeps the host architecture, denoising objective and supervision unchanged, and changes only the ordering policy. It starts from confidence-driven progressive ordering and gradually shifts to Doob h transform Process Reward guided ordering through online estimates. We characterize the exact DPRM policy as a reward-tilted Gibbs reveal law, prove O(1/N) convergence of the stagewise Soft-BoN approximation, and show that the online bucketized controller tracks the exact DPRM score at empirical-Bernstein rates. Under tractable optimization assumptions, DPRM also yields a sample-complexity advantage over random and confidence-only ordering. DPRM improves over confidence-based baselines in pretraining, post-training, test-time scaling, and single-cell masked diffusion, with particularly strong gains on harder reasoning subsets. In protein, molecular generation and DNA design, the effect is more multi-objective: ordering-aware variants significantly improve selected structural or fragment-constrained metrics while not uniformly dominating the host baseline on every quality metric. These results identify token ordering as a fundamental control axis in diffusion language models and establish DPRM as a general-purpose module for improving it. Code is available at https://github.com/DakeBU/DPRM-DLLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DPRM, a plug-in Doob h-transform-induced token-ordering module for diffusion language models. It claims to keep the host architecture, denoising objective and supervision unchanged while shifting the ordering policy from confidence-driven progressive ordering to Doob h-transform Process Reward guided ordering through online estimates. The manuscript characterizes the exact DPRM policy as a reward-tilted Gibbs reveal law, proves O(1/N) convergence of the stagewise Soft-BoN approximation, shows that the online bucketized controller tracks the exact DPRM score at empirical-Bernstein rates, and claims a sample-complexity advantage over random and confidence-only ordering under tractable optimization assumptions. Empirically, DPRM improves over confidence-based baselines in pretraining, post-training, test-time scaling, and single-cell masked diffusion (with strong gains on harder reasoning subsets); in protein, molecular generation and DNA design the gains are multi-objective, improving selected structural or fragment-constrained metrics without uniformly dominating every quality metric.
Significance. If the theoretical results hold, DPRM provides a general-purpose, architecture-preserving module that treats token ordering as a controllable axis in diffusion LMs, potentially improving sample efficiency and performance on reasoning and generative tasks. The plug-in design and public code release are strengths that facilitate adoption and reproducibility. The multi-objective empirical profile in biological domains suggests practical utility but also indicates that benefits are metric-dependent rather than blanket improvements.
major comments (2)
- [Abstract] Abstract: the claim that DPRM 'yields a sample-complexity advantage over random and confidence-only ordering' under 'tractable optimization assumptions' is load-bearing for the theoretical contribution, yet the assumptions (convexity, Lipschitz constants on the reward tilt, bounded variance of the Doob h-transform estimator, etc.) are never stated. Without them it is impossible to verify whether the stated O(1/N) convergence of Soft-BoN and empirical-Bernstein tracking of the bucketized controller actually produce the promised rate advantage in the diffusion-LM regime; the empirical sections report only final performance metrics, not direct measurements of sample complexity or tracking error versus N.
- [Abstract] Abstract: the characterizations of the DPRM policy as a reward-tilted Gibbs reveal law, the O(1/N) convergence proof, and the empirical-Bernstein tracking claim are presented as central results, but the abstract supplies no key steps, conditions, or equation references. Given that the full derivations and experimental protocols are required to assess soundness, these claims must be expanded with explicit statements of all assumptions and direct empirical validation of the rates before the theoretical superiority can be accepted.
minor comments (2)
- Notation for 'Doob h-transform' is inconsistent between the title ('Doob h transform-induced') and the abstract ('Doob h-transform'); standardize throughout.
- The multi-objective nature of results in protein/molecular/DNA tasks is noted, but uniform reporting of all quality metrics (not only the improved subset) in a single table would clarify trade-offs.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We agree that the abstract would benefit from greater explicitness regarding assumptions, characterizations, and empirical validation of rates. We address each major comment below and will revise the manuscript to incorporate these improvements.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that DPRM 'yields a sample-complexity advantage over random and confidence-only ordering' under 'tractable optimization assumptions' is load-bearing for the theoretical contribution, yet the assumptions (convexity, Lipschitz constants on the reward tilt, bounded variance of the Doob h-transform estimator, etc.) are never stated. Without them it is impossible to verify whether the stated O(1/N) convergence of Soft-BoN and empirical-Bernstein tracking of the bucketized controller actually produce the promised rate advantage in the diffusion-LM regime; the empirical sections report only final performance metrics, not direct measurements of sample complexity or tracking error versus N.
Authors: We agree that the abstract does not enumerate the assumptions, even though they are formally stated in Section 3. In the revised version we will explicitly list the key assumptions (convexity of the optimization landscape, Lipschitz continuity of the reward tilt, and bounded variance of the Doob h-transform estimator) directly in the abstract. We will also add a supplementary analysis with plots of tracking error and effective sample complexity versus N to provide direct empirical validation of the O(1/N) and empirical-Bernstein rates. revision: yes
-
Referee: [Abstract] Abstract: the characterizations of the DPRM policy as a reward-tilted Gibbs reveal law, the O(1/N) convergence proof, and the empirical-Bernstein tracking claim are presented as central results, but the abstract supplies no key steps, conditions, or equation references. Given that the full derivations and experimental protocols are required to assess soundness, these claims must be expanded with explicit statements of all assumptions and direct empirical validation of the rates before the theoretical superiority can be accepted.
Authors: We acknowledge that the abstract is concise and omits explicit references to theorems or equation numbers. We will revise the abstract to include brief statements of the main results (reward-tilted Gibbs characterization, O(1/N) convergence of the stagewise Soft-BoN approximation, and empirical-Bernstein tracking) together with pointers to the relevant theorems and sections. The full derivations, conditions, and experimental protocols already appear in the main text and appendix; the revision will make these connections clearer to readers. revision: yes
Circularity Check
No significant circularity; derivations rely on external mathematical tools and standard statistical bounds.
full rationale
The paper characterizes the DPRM policy as a reward-tilted Gibbs reveal law, proves O(1/N) convergence of the Soft-BoN approximation, and invokes empirical-Bernstein rates for the bucketized controller. These steps are presented as independent mathematical results rather than reductions to fitted parameters or self-referential definitions. The sample-complexity advantage is explicitly conditioned on unspecified 'tractable optimization assumptions' without claiming it follows by construction from the inputs. No self-citations appear load-bearing in the abstract or description, and the Doob h-transform is treated as an external tool. The chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cui, H., Wang, C., Maan, H., Pang, K., Luo, F., Duan, N., and Wang, B
URL https://proceedings.mlr.pres s/v206/chen23i.html. Cui, H., Wang, C., Maan, H., Pang, K., Luo, F., Duan, N., and Wang, B. scgpt: toward building a foundation model for single-cell multi-omics using generative ai.Nature Methods, 21:1470–1480, 2024. doi: 10.1038/s41592-024 -02201-0. DaSilva, L. F., Senan, S., Kribelbauer-Swietek, J. F., Patel, Z. M., Lou...
-
[2]
URL https://proceedings.mlr.pres s/v162/hanchi22a.html. Fang, L., Liu, A., Zou, H. P., Chen, Y ., Ma, E., Pan, L., Miao, C., Huang, W.-C., Liu, X., and Yu, P. S. Locally confident, globally stuck: The quality-exploration dilemma in diffu- sion language models.arXiv preprint arXiv:2604.00375, 2026. Gayoso, A., Steier, Z., Lopez, R., Regier, J., Nazor, K. L...
-
[3]
doi: 10.1093/bioinformatics/btae518
doi: 10.1093/bioinformatics/btae518. Ma, X., Yu, R., Fang, G., and Wang, X. dKV-Cache: The cache for diffusion language models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net /forum?id=Gppo2JImHs. Maurer, A. and Pontil, M. Empirical bernstein bounds and sample variance penalization.arXiv pre...
-
[4]
Progressive DMPO: our PUMA-inspired finetuning baseline, which uses teacher-forced progressive masking together with the decoder’s confidence top-kreveal order
-
[5]
DMPO-DPRM: our method, which keeps the Progressive DMPO hyperparameters fixed and changes only the reveal policy to DPRM Soft-BoN. 18 DPRM: A Plug-in Token-Ordering Module for Diffusion Language Models Figure 5.MATH pass@ K curves by difficulty level (1: trivial, 2: easy, 3: medium, 4: hard, 5: OOD). DPRM-DMPO provides consistent gains on hard and OOD sub...
work page 2000
-
[6]
performs hierarchical trajectory search (HTS) with self-verification as reward (SVF). We run two configurations that 20 DPRM: A Plug-in Token-Ordering Module for Diffusion Language Models Figure 7.Per-rank accuracy comparison on GSM8K. Rank 1 is the highest-scored survivor after pruning. DPRM-Prism improves at every rank position. differ only in the token...
-
[7]
Prism (confidence): the original Prism baseline, which uses confidence top- k to rank and select tokens at each unmasking step
-
[8]
DPRM-Prism: our method, which replaces confidence top-k by DPRM Soft-BoN. The DPRM controller uses 8 phase buckets, 16 confidence bins, reward temperature β= 1.0 , (Twarm, Tswitch, Nready) = (6,22,64) over the 32 decode steps, and sampled shortlistN t = min{64,max(8,4m t)}. Shared hyperparameters.Both configurations use identical Prism search scaffolds: i...
work page 2000
-
[9]
the posterior satisfies P(O=o|Q=q, Z=z, t)∝p ∗(o|q)1{o um(z) =z um(z)},(15) so it is independent ofα t(q, z)
-
[10]
every minimizerθ ⋆ of(14)satisfies pθ⋆(u|z, q) =P(O i =u|Q=q, Z=z)for almost every(q, z, i)withi∈M(z). Proof.Fixq,t, andz. By Bayes’ rule and (13), P(O=o|Q=q, Z=z, t)∝P(Z t =z|Q=q, O=o, t)p ∗(o|q)∝α t(q, z)1{o um(z) =z um(z)}p ∗(o|q). Sinceα t(q, z)does not depend ono, it cancels under normalization. This proves (15). Now fix a coordinateiand define X:= (...
work page 2026
-
[11]
for every reachable states= (q, z, t)and everyi∈M(z), |R⋆ t (i;s)− ¯Rϕ,bi(s),t| ≤ε abs,t(s); 3.µ ϕ,b,t ≥µ >0for every bucket and time. Then, with probability at least1−δ, for all reachable statess= (q, z, t)and allt≤T, sup i∈M(z) |bgt(i;s)−g ⋆ t (i;s)| ≤ε t(s;δ).(18) Moreover, ifbAt(s)is chosen by the practical controller and A⋆ t (s)∈arg max |A|=m(s) X i...
work page 2009
-
[12]
Residual KL contraction.Let Kres t (θ) denote the contribution of Rt to the stagewise forward KL. There exists γt ∈(0,1]such that, conditional on sampling an order fromR t(s), E[Kres t+1(θ)|θ t, O t ∈ R t(s)]≤(1−γ t)Kres t (θt), whereas conditional on sampling outsideR t(s), E[Kres t+1(θ)|θ t, O t /∈ Rt(s)]≤ K res t (θt). Theorem C.32(Late-stage exponenti...
-
[13]
the practical stage-2 proposal overO t(s)assigns residual-family mass at least bπt(Rt(s)|s)≥ |Rt(s)|e ∆res t (s)−2ϵt(s) |Rt(s)|e ∆res t (s)−2ϵt(s) +|O t(s)\ R t(s)|;(42)
-
[14]
if, in addition, ∆res t (s)−2ϵ t(s)≥b tht + log |Ot(s)\ R t(s)| |Rt(s)| +c t for somec t >0, then bπt(Rt(s)|s)≥ 1 1 +e −ct =:p DPRM t ,(43) whereas πconf t (Rt(s)|s)≤C te−btht . Consequently, if T (conf) t,late (ε)andT (DPRM) t,late (ε) denote the numbers of late-stage updates needed to drive the residual forward KL belowε, then T (conf) t,late (ε) = Ω eb...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.