Recognition: unknown
Culture-Aware Machine Translation in Large Language Models: Benchmarking and Investigation
Pith reviewed 2026-05-08 03:40 UTC · model grok-4.3
The pith
Large language models recognize culture-specific knowledge yet persistently fail to apply it correctly when producing translations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Leveraging the CanMT dataset and evaluation framework, the authors show substantial performance differences across models, that translation strategies exert systematic effects on behavior, that difficulty varies by type of culture-specific item, and that a persistent gap exists between models' recognition of culture-specific knowledge and their ability to correctly operationalize it in translation outputs. Reference translations further improve the reliability of LLM-as-a-judge assessments.
What carries the argument
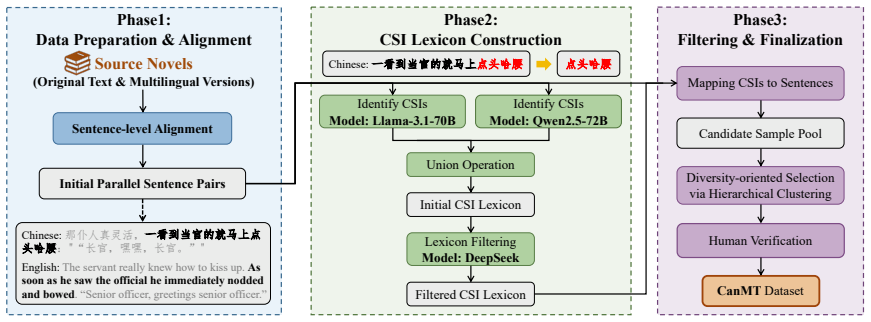
The CanMT dataset of culture-aware novel-driven parallel texts together with a multi-dimensional evaluation framework that scores cultural translation quality.
If this is right
- Different translation strategies produce consistent and measurable differences in how models handle cultural content.
- Performance varies systematically by the category of culture-specific item being translated.
- Models show a repeatable separation between detecting cultural knowledge and using it correctly in generated text.
- Adding reference translations markedly increases the trustworthiness of LLM-based judges for this task.
Where Pith is reading between the lines
- Training methods that explicitly link detected cultural facts to generation steps could narrow the observed gap.
- Future machine-translation benchmarks may need separate tracks for cultural items to avoid overestimating general capability.
- The dataset could support targeted fine-tuning experiments that test whether more exposure to similar novel contexts reduces the recognition-operationalization split.
Load-bearing premise
The CanMT dataset and multi-dimensional evaluation framework accurately and unbiasedly measure cultural translation quality without selection or scoring biases.
What would settle it
An independent expert rating study in which human translators assign substantially different quality scores to the same model outputs than the framework does, or a replication where models close the recognition-to-translation gap on the same items.
Figures




















read the original abstract
Large language models (LLMs) have achieved strong performance in general machine translation, yet their ability in culture-aware scenarios remains poorly understood. To bridge this gap, we introduce CanMT, a Culture-Aware Novel-Driven Parallel Dataset for Machine Translation, together with a theoretically grounded, multi-dimensional evaluation framework for assessing cultural translation quality. Leveraging CanMT, we systematically evaluate a wide range of LLMs and translation systems under different translation strategy constraints. Our findings reveal substantial performance disparities across models and demonstrate that translation strategies exert a systematic influence on model behavior. Further analysis shows that translation difficulty varies across types of culture-specific items, and that a persistent gap remains between models' recognition of culture-specific knowledge and their ability to correctly operationalize it in translation outputs. In addition, incorporating reference translations is shown to substantially improve evaluation reliability in LLM-as-a-judge, underscoring their essential role in assessing culture-aware translation quality. The corpus and code are available at CanMT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CanMT, a novel parallel dataset of culture-specific items extracted from novels, paired with a multi-dimensional evaluation framework for cultural translation quality. It systematically benchmarks a range of LLMs and MT systems under varying translation strategy constraints, reporting substantial performance disparities across models, systematic effects of translation strategies on behavior, variation in difficulty by type of culture-specific item, and a persistent gap between models' recognition of culture-specific knowledge and their ability to operationalize it correctly in output. The work also finds that providing reference translations substantially improves the reliability of LLM-as-a-judge assessments.
Significance. If the dataset construction and scoring prove robust, this provides a timely, open benchmark and framework for culture-aware MT evaluation at a time when LLMs are increasingly used in cross-cultural settings. The systematic comparison of strategies, the item-type difficulty analysis, and the recognition-versus-operationalization distinction offer concrete, actionable insights. The public release of the corpus and code is a clear strength that supports reproducibility and follow-on work.
major comments (2)
- CanMT Dataset Construction: The central claims (performance disparities, strategy effects, difficulty variation, and recognition-operationalization gap) all depend on culture-specific items being identified and scored in a reproducible, unbiased manner. The manuscript does not report inter-annotator agreement disaggregated by annotators' cultural backgrounds or a sensitivity analysis that removes or re-labels borderline items. Without these, it remains possible that annotator-specific priors drive the observed gaps rather than genuine model limitations.
- Evaluation Framework and LLM-as-a-Judge: The multi-dimensional quality scoring and the claim that reference translations improve evaluation reliability rest on details of how 'correct operationalization' is defined and how subjective judgments are aggregated. The provided text does not include statistical controls, exact scoring rubrics, or agreement metrics for the human or LLM judgments, making it difficult to assess whether post-hoc choices affect the headline findings.
minor comments (1)
- The abstract and introduction would benefit from a concise table summarizing the CanMT dataset statistics (number of items, languages, item-type breakdown) to orient readers before the experimental results.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and outline the revisions we will make to strengthen the manuscript's reproducibility and clarity.
read point-by-point responses
-
Referee: CanMT Dataset Construction: The central claims (performance disparities, strategy effects, difficulty variation, and recognition-operationalization gap) all depend on culture-specific items being identified and scored in a reproducible, unbiased manner. The manuscript does not report inter-annotator agreement disaggregated by annotators' cultural backgrounds or a sensitivity analysis that removes or re-labels borderline items. Without these, it remains possible that annotator-specific priors drive the observed gaps rather than genuine model limitations.
Authors: We appreciate the referee's emphasis on ensuring that dataset construction does not introduce annotator bias. The original manuscript reports overall inter-annotator agreement for culture-specific item identification. We agree that disaggregation by cultural background and a sensitivity analysis are valuable additions. In the revised version, we will report agreement metrics broken down by annotators' self-reported cultural backgrounds and include a sensitivity analysis that excludes or re-labels borderline items. These additions will demonstrate that the reported performance gaps and other findings remain consistent, supporting that they reflect model behavior rather than annotator-specific factors. revision: yes
-
Referee: Evaluation Framework and LLM-as-a-Judge: The multi-dimensional quality scoring and the claim that reference translations improve evaluation reliability rest on details of how 'correct operationalization' is defined and how subjective judgments are aggregated. The provided text does not include statistical controls, exact scoring rubrics, or agreement metrics for the human or LLM judgments, making it difficult to assess whether post-hoc choices affect the headline findings.
Authors: We acknowledge that greater explicitness on the evaluation details would aid assessment of robustness. In the revised manuscript, we will expand the description of the multi-dimensional scoring framework by providing the complete rubrics used to define 'correct operationalization' of cultural elements. We will also report agreement metrics (e.g., Fleiss' kappa) for human judgments, correlation measures between human and LLM judges, and statistical controls such as significance testing and confidence intervals for the observed improvements when reference translations are provided to the LLM-as-a-judge. These additions will clarify that the reliability gains are not sensitive to aggregation choices. revision: yes
Circularity Check
Empirical benchmarking and dataset creation with no closed derivation chain
full rationale
The paper introduces the CanMT dataset and a multi-dimensional evaluation framework, then reports measured performance disparities, strategy effects, and recognition-vs-operationalization gaps across LLMs. These are direct empirical outcomes from running models on the constructed test items; no equations, fitted parameters, or self-citation chains reduce the reported numbers to quantities defined by the paper's own inputs. The central claims rest on external model behavior rather than internal redefinition or tautological prediction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 2024 Conference on Empir- ical Methods in Natural Language Processing, pages 1068–1080, Miami, Florida, USA
Bridging cultures in the kitchen: A framework and benchmark for cross-cultural recipe retrieval. InProceedings of the 2024 Conference on Empir- ical Methods in Natural Language Processing, pages 1068–1080, Miami, Florida, USA. Association for Computational Linguistics. Yichong Huang, Baohang Li, Xiaocheng Feng, Wen- shuai Huo, Chengpeng Fu, Ting Liu, and Bing Qin
2024
-
[2]
Aligning translation-specific understanding to general understanding in large language models. InProceedings of the 2024 Conference on Empiri- cal Methods in Natural Language Processing, pages 5028–5041, Miami, Florida, USA. Association for Computational Linguistics. Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chr...
work page internal anchor Pith review arXiv 2024
-
[3]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437. Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingx- uan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, and 1 others. 2025. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556. Yinquan Lu, Wenhao Zhu, Lei Li, Yu Qiao, and Fei Yu...
work page internal anchor Pith review arXiv 2025
-
[4]
Qwen2.5 Technical Report.arXiv preprint. ArXiv:2412.15115 [cs]. Pushpdeep Singh, Mayur Patidar, and Lovekesh Vig
work page internal anchor Pith review arXiv
-
[5]
Gemini: A Family of Highly Capable Multimodal Models
Translating across cultures: LLMs for in- tralingual cultural adaptation. InProceedings of the 28th Conference on Computational Natural Lan- guage Learning, pages 400–418, Miami, FL, USA. Association for Computational Linguistics. Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, A...
work page internal anchor Pith review arXiv 2023
-
[6]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Binwei Yao, Ming Jiang, Tara Bobinac, Diyi Yang, and Junjie Hu. 2024. Benchmarking machine translation with cultural awareness. InFindings of the Associ- ation for Computational Linguistics: EMNLP 2024, pages 13078–13096, Miami, Florida, USA. Associa- tion for Computational Linguistics. Yangfan Ye, X...
work page internal anchor Pith review arXiv 2024
-
[7]
The meeting was canceled due to rain
Completely Unmatched Content: Sentence A and B describe entirely different topics or situations. Example: A: “The meeting was canceled due to rain.” B: “天气很好,适合散步。” (Completely inconsistent in meaning — should be deleted.)
-
[8]
She smiled. Then she walked away
Obvious Non-Translation Concatenation: One side contains multiple sentences while the other includes only part of the content. Example: A: “She smiled. Then she walked away.” B: “她笑了。” (The latter half is missing — not a complete parallel pair.) 2.2 Mismatched Information Volume (To Be Modified)
-
[9]
Finn loves cats
Contextual Misinterpretation: Translation omits or generalizes specific details (e.g., person names, times, places) and should restore the original meaning. Example: A: “Finn loves cats.” B: “他喜欢猫。” → Modify to: “费恩喜欢猫。” (Add explicit subject to restore contextual information.)
-
[10]
Finn loves cats
Partial Alignment: The source covers only part of the target or multiple sentences are incorrectly merged. Example: A: “Finn loves cats.” B: “费恩喜欢猫。我喜欢狗。” → Modify to: “费恩喜欢猫。”
-
[11]
It started to rain
Redundant Information: If the translation adds subjective comments or extra information not in the source, the redundant part should be removed. Example: A: “It started to rain.” B: “天开始下雨,真是糟糕。” → Modify to: “天开始下雨。” =============================================================================== Figure 7: Instruction for human data filtering. items, inco...
1988
-
[12]
{csi_text}
The question must explicitly ask how to translate "{csi_text}" into {tgt_lang} in this context. The question text must be written in English
-
[13]
All options must be written in {tgt_lang} and be grammatically well-formed
-
[14]
Exactly ONE option must preserve both the semantic meaning and cultural function of the CSI
-
[15]
All distractor options must be lexically or structurally close to the correct translation, but express a meaning that is semantically incompatible with the CSI in this context, such that choosing them would lead to serious misunderstanding. Distractors MUST contain a clear semantic or cultural error, such as: - incorrect referent or denotation, - wrong cu...
-
[16]
The correct option must be consistent with how the CSI is treated in the reference translation (even if translated implicitly or paraphrased)
-
[17]
question
The analysis MUST: - justify why the correct option preserves the CSI’s meaning and cultural function; - explicitly explain why each distractor fails due to a semantic or cultural mismatch; - NOT suggest that any incorrect option is acceptable in another context. Output strictly in JSON (no markdown):{ "question": "The question stem...", "options": { "A":...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.