Associative-State Universal Transformers: Sparse Retrieval Meets Structured Recurrence
Pith reviewed 2026-05-13 22:03 UTC · model grok-4.3
The pith
UniMatrix-SparsePointer adds sparse slot routing and pointer fusion to a shared recurrent block, reaching 75.6 percent accuracy on triple-token associative recall while using 53.8 percent fewer parameters than a matched Transformer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
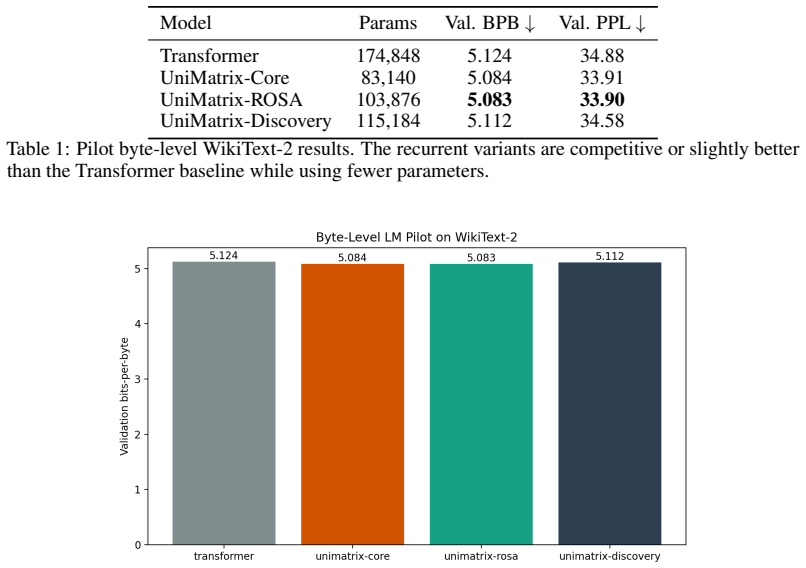
Structured recurrent state alone is not sufficient for exact associative lookup; the UniMatrix family stays near chance on the triple-token recall task while a Transformer reaches 25.4 percent. Adding sparse slot routing and pointer-level output fusion produces UniMatrix-SparsePointer, which attains 75.6 percent on the original pilot and 99.2 percent in a no-dropout setting while using 53.8 percent fewer parameters than the baseline Transformer. On byte-level WikiText-2 the simpler UniMatrix-Core and UniMatrix-ROSA variants reach 5.083–5.084 bits-per-byte versus 5.124 for the parameter-matched Transformer.
What carries the argument
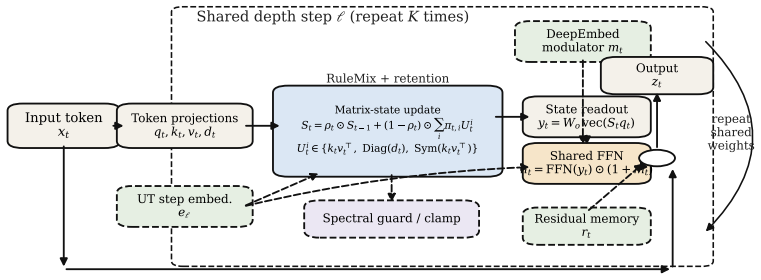
UniMatrix-SparsePointer, which augments a shared recurrent block with sparse slot routing and direct pointer-logit fusion to enable exact retrieval from a compressed state.
If this is right
- Recurrent models can match Transformer language-modeling performance at substantially lower parameter count when the state is updated with hybrid rules and a residual path.
- Exact retrieval from a compressed recurrent state requires both sufficient slot capacity and pointer-level output routing rather than soft attention alone.
- Sparse retrieval can be fused directly into the recurrent output without restoring quadratic attention cost.
- Ablations indicate that slot capacity and exact pointer fusion are the dominant sources of the recall gain.
Where Pith is reading between the lines
- If the sparse-pointer mechanism scales, hybrid recurrent-retrieval models could replace attention for context lengths where quadratic cost becomes prohibitive.
- The gap between synthetic recall and real-language long-range performance suggests the need for new benchmarks that combine associative lookup with natural text distributions.
- Parameter savings of roughly half could enable larger effective state sizes on fixed hardware budgets for streaming or on-device language models.
Load-bearing premise
Success on the synthetic triple-token associative-recall benchmark will carry over to the long-range dependencies that matter in real language modeling.
What would settle it
UniMatrix-SparsePointer fails to improve perplexity or downstream accuracy on any long-context language-modeling benchmark relative to a standard Transformer of equal compute budget.
Figures
read the original abstract
We study whether a structured recurrent state can serve as a compact associative backbone for language modeling while still supporting exact retrieval. We introduce UniMatrix, a Universal Transformer style family that reuses a shared recurrent block across depth and augments it with hybrid state updates, a ROSA-style residual path, and token-conditioned embedding modulation. We evaluate these models on byte-level WikiText-2, synthetic associative recall, throughput profiling on Apple MPS, and a corrected benchmark for triple-token interactions. At small scale, UniMatrix-Core and UniMatrix-ROSA slightly outperform a parameter-matched Transformer on WikiText-2 while using many fewer parameters, reaching 5.084 and 5.083 bits-per-byte versus 5.124. The main negative result is equally important: on associative recall, the original UniMatrix family remains near chance while the Transformer reaches 25.4 percent, showing that compressed recurrent state alone is not enough for exact lookup. A retrieval-oriented follow-up, UniMatrix-Assoc, helps only marginally. By contrast, UniMatrix-SparsePointer, which adds sparse slot routing and direct pointer-logit fusion, reaches 75.6 percent on the original pilot recipe and 99.2 percent on a no-dropout follow-up while using 53.8 percent fewer parameters than the Transformer baseline. Ablations show that the gain comes from sufficient slot capacity and exact pointer-level output routing. Overall, structured recurrent state is promising and parameter-efficient, but strong long-range behavior still requires explicit sparse retrieval and better kernels.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the UniMatrix family of Universal Transformer variants that reuse a shared recurrent block across depth, augmented with hybrid state updates, ROSA-style residuals, token-conditioned modulation, and (in the SparsePointer variant) sparse slot routing with direct pointer-logit fusion. It reports that UniMatrix-Core/ROSA slightly outperform a parameter-matched Transformer on byte-level WikiText-2 (5.083–5.084 bpb vs. 5.124) while using substantially fewer parameters, that the base recurrent models perform near chance on a synthetic triple-token associative-recall pilot (Transformer at 25.4 %), and that UniMatrix-SparsePointer reaches 75.6 % (99.2 % without dropout) on the same pilot with 53.8 % fewer parameters; ablations attribute the gain to slot capacity and exact pointer routing.
Significance. If the efficiency and retrieval results hold under broader evaluation, the work would demonstrate a viable route to compact associative memory in recurrent architectures, offering a parameter-efficient alternative to attention for exact lookup tasks and potentially informing hybrid recurrence-retrieval designs for long-context modeling.
major comments (2)
- [Abstract and §4 (associative-recall and WikiText-2 results)] The central claim that structured recurrent state plus sparse retrieval supplies a compact associative backbone for language modeling rests on only marginal WikiText-2 gains on short sequences; no long-context LM benchmark (e.g., PG-19, arXiv, or long-document QA) is reported that would test whether the SparsePointer mechanism still confers advantage once dependencies become multi-hop, noisy, and interleaved with next-token prediction.
- [§4 (ablations and main results)] The 75.6 % / 99.2 % associative-recall figures and the 53.8 % parameter reduction are presented without error bars, multiple random seeds, or statistical tests, and the ablation table does not report variance; this makes it impossible to assess whether the reported superiority over the Transformer baseline is robust.
minor comments (2)
- [§3 (model and training details)] Training hyperparameters, optimizer settings, and exact model dimensions for the parameter-matched Transformer baseline are not fully specified, hindering reproducibility.
- [§2.3 and §4] The manuscript refers to “corrected benchmark for triple-token interactions” without providing the exact task definition or data-generation code in the main text or appendix.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4 (associative-recall and WikiText-2 results)] The central claim that structured recurrent state plus sparse retrieval supplies a compact associative backbone for language modeling rests on only marginal WikiText-2 gains on short sequences; no long-context LM benchmark (e.g., PG-19, arXiv, or long-document QA) is reported that would test whether the SparsePointer mechanism still confers advantage once dependencies become multi-hop, noisy, and interleaved with next-token prediction.
Authors: We agree that WikiText-2 uses short sequences and does not constitute a long-context benchmark. Our primary evidence for the associative mechanism is the controlled synthetic triple-token recall task, where the base recurrent models perform near chance while SparsePointer reaches 75.6 % (99.2 % without dropout). This isolates the exact-lookup capability that is difficult to measure cleanly in natural long-document data. We nevertheless accept the referee's point that broader evaluation would strengthen the claim and will add an expanded limitations paragraph discussing expected behavior under multi-hop, noisy, and interleaved dependencies, together with a brief outline of how the SparsePointer routing could be scaled to longer contexts. revision: partial
-
Referee: [§4 (ablations and main results)] The 75.6 % / 99.2 % associative-recall figures and the 53.8 % parameter reduction are presented without error bars, multiple random seeds, or statistical tests, and the ablation table does not report variance; this makes it impossible to assess whether the reported superiority over the Transformer baseline is robust.
Authors: We thank the referee for highlighting this omission. The reported numbers were obtained from single runs at small scale during initial exploration. In the revised manuscript we will rerun the associative-recall experiments and the key ablations with at least three independent random seeds, report means and standard deviations, and update both the main results and the ablation table to include variance estimates. revision: yes
Circularity Check
No circularity: empirical comparisons to baselines with no self-referential derivations
full rationale
The paper introduces UniMatrix variants as architectural proposals and reports empirical results on WikiText-2 and synthetic associative-recall benchmarks. All key claims (e.g., 75.6% recall accuracy with 53.8% fewer parameters, 5.083 bpb on WikiText-2) are obtained via direct parameter-matched comparisons to Transformer baselines. No equations, uniqueness theorems, or fitted parameters are presented that reduce by construction to the inputs; the architecture descriptions and ablations remain independent of the reported metrics.
Axiom & Free-Parameter Ledger
free parameters (2)
- slot capacity
- recurrent block size
axioms (1)
- domain assumption A compact recurrent state can serve as an associative backbone for language modeling
invented entities (1)
-
UniMatrix-Core / ROSA / SparsePointer variants
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
UniMatrix reads from the state through yt = Wo vec(St qt). ... St = ρt ⊙ St−1 + (1−ρt) ⊙ Σ πt,i Ui t
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SparsePointer ... βt,s = q⊤t Ks / √dk + log λs ... ℓptr t(v) = Σ softmax(βt)s 1[ys = v]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Longbench: A bilingual, multitask benchmark for long context understanding, 2023
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. Longbench: A bilingual, multitask benchmark for long context understanding, 2023. Ali Behrouz et al. Titans: Learning to memorize at test time, 2025. Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Car...
work page 2023
-
[2]
Jamba: A hybrid transformer-Mamba language model, 2024
Rozen, Erez Shwartz, Mor Zusman, and Yoav Shoham. Jamba: A hybrid transformer-Mamba language model, 2024. Leon Lufkin, Tomás Figliolia, Beren Millidge, and Kamesh Krishnamurthy. Hybrid associative memories, 2026. Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models.International Conference on Learning Represen...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.