Recognition: unknown
AMMA: A Multi-Chiplet Memory-Centric Architecture for Low-Latency 1M Context Attention Serving
Pith reviewed 2026-05-07 14:11 UTC · model grok-4.3
The pith
A memory-centric multi-chiplet architecture replaces GPU dies with HBM-PNM cubes to cut attention latency for million-token contexts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
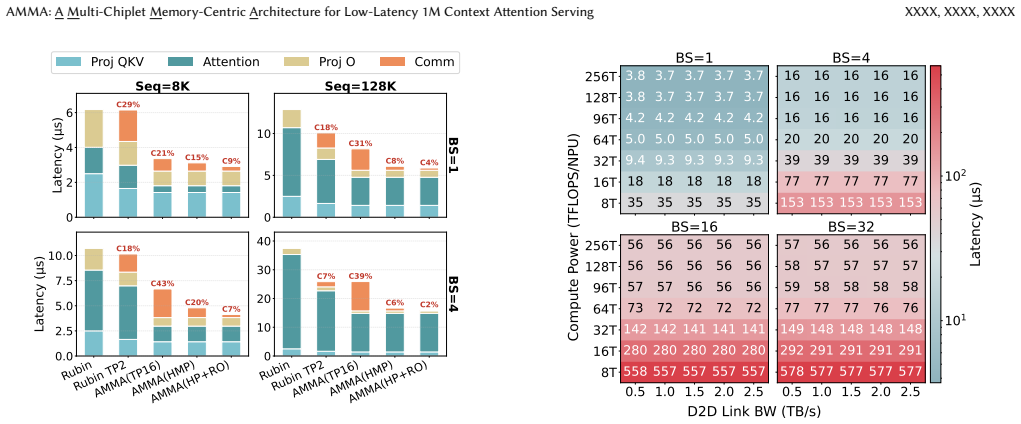
AMMA replaces GPU compute dies with HBM-PNM cubes to roughly double memory bandwidth for decode-phase attention. A logic-die microarchitecture exploits per-cube internal bandwidth under tight power and area limits, while a two-level hybrid parallelism scheme and reordered collective flow cut intra-chip communication costs. Design-space exploration over compute power and die-to-die link bandwidth guides hardware choices. The result is 15.5 times lower attention latency and 6.9 times lower energy use than a standard GPU baseline on long-context workloads.
What carries the argument
HBM-PNM cubes paired with a custom logic-die microarchitecture that routes decode attention directly to internal memory bandwidth, supported by two-level hybrid parallelism and reordered collective flow to minimize die-to-die traffic.
If this is right
- Decode attention for 1M-token contexts becomes feasible at interactive latencies on memory-centric hardware.
- Power and die area currently spent on idle compute units in GPUs can be reallocated to more memory bandwidth.
- Hardware designers gain concrete guidance on per-cube compute power and intra-chip link bandwidth trade-offs.
- Serving systems can shift from GPU-centric to memory-centric designs without losing attention performance.
Where Pith is reading between the lines
- The same memory-centric approach could apply to other memory-bound phases such as KV cache management or retrieval-augmented generation.
- Future chiplet stacks might generalize the two-level parallelism pattern to additional AI primitives beyond attention.
- If the bandwidth-to-performance translation holds, it suggests a broader shift away from compute-rich dies for inference workloads.
Load-bearing premise
The proposed logic-die microarchitecture, hybrid parallelism, and reordered flow can turn the extra per-cube bandwidth into proportional latency and energy reductions without large unmodeled overheads once built in silicon.
What would settle it
Fabricate a prototype of the AMMA chiplet stack, run 1M-token decode attention workloads on it, and compare measured latency and energy directly against an equivalent GPU baseline under identical conditions.
Figures











read the original abstract
All current LLM serving systems place the GPU at the center, from production-level attention-FFN disaggregation to NVIDIA's Rubin GPU-LPU heterogeneous platform. Even academic PIM/PNM proposals still treat the GPU as the central hub for cross-device communication. Yet the GPU's compute-rich architecture is fundamentally mismatched with the memory-bound nature of decode-phase attention, inflating serving latency while wasting power and die area on idle compute units. The problem is compounded as reasoning and agentic workloads push context lengths toward one million tokens, making attention latency the primary user-facing bottleneck. To address these inefficiencies, we present AMMA, a multi-chiplet, memory-centric architecture for low-latency long-context attention. AMMA replaces GPU compute dies with HBM-PNM cubes, roughly doubling the available memory bandwidth to better serve memory-bound attention workloads. To translate this bandwidth into proportional performance gains, we introduce (i) a logic-die microarchitecture that fully exploits per-cube internal bandwidth for decode attention under a minimal power and area budget, (ii) a two-level hybrid parallelism scheme, and (iii) a reordered collective flow that reduces intra-chip die-to-die communication overhead. We further conduct a design-space exploration over per-cube compute power and intra-chip D2D link bandwidth, providing actionable guidance for hardware designers. Evaluations show that AMMA achieves 15.5X lower attention latency and 6.9X lower energy consumption compared with the NVIDIA H100.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AMMA, a multi-chiplet memory-centric architecture for low-latency 1M-context attention serving in LLMs. It replaces GPU compute dies with HBM-PNM cubes to roughly double per-cube memory bandwidth, introduces a logic-die microarchitecture optimized for decode attention under tight power/area budgets, a two-level hybrid parallelism scheme, and a reordered collective flow to minimize intra-chip D2D communication. A design-space exploration over per-cube compute power and D2D link bandwidth is performed, with evaluations claiming 15.5X lower attention latency and 6.9X lower energy consumption versus the NVIDIA H100.
Significance. If the performance claims hold after validation, the work would be significant for computer architecture and LLM systems research by directly targeting the memory-bound nature of long-context decode attention rather than relying on GPU-centric designs. The explicit design-space exploration over compute power and intra-chip D2D bandwidth provides actionable guidance for hardware designers and is a clear strength. The approach of using HBM-PNM cubes with custom logic dies offers a concrete alternative to current disaggregated serving systems.
major comments (1)
- [Evaluation] Evaluation section: The headline claims of 15.5X latency reduction and 6.9X energy reduction versus H100 rest on the logic-die microarchitecture, two-level hybrid parallelism, and reordered collective flow converting doubled HBM bandwidth into proportional gains. However, the design-space exploration does not appear to include stress-testing against measured multi-chiplet D2D link latencies, control logic costs, or utilization losses at scale; without these, the proportional gains remain projections rather than demonstrated outcomes.
minor comments (1)
- [Abstract] Abstract: The quantitative claims are presented without any reference to workloads, baseline configurations, or simulation methodology; adding a single sentence summarizing these would improve clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the significance of targeting memory-bound decode attention with a memory-centric multi-chiplet design. We address the single major comment below with clarifications on our evaluation methodology and modeling choices.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The headline claims of 15.5X latency reduction and 6.9X energy reduction versus H100 rest on the logic-die microarchitecture, two-level hybrid parallelism, and reordered collective flow converting doubled HBM bandwidth into proportional gains. However, the design-space exploration does not appear to include stress-testing against measured multi-chiplet D2D link latencies, control logic costs, or utilization losses at scale; without these, the proportional gains remain projections rather than demonstrated outcomes.
Authors: We thank the referee for this observation. Our design-space exploration (Section 5) systematically varies intra-chip D2D link bandwidth over a wide range of values while holding other parameters fixed; this directly exercises the sensitivity of end-to-end latency and energy to communication performance, serving as a proxy for link-latency stress testing. The logic-die microarchitecture is deliberately minimal, with control logic area and power explicitly budgeted and subtracted from the per-cube envelope so that overheads are not ignored. Utilization is evaluated at full 1 M-token scale under the two-level hybrid parallelism and reordered collective schedule; the reported speedups already reflect the achieved utilization after all communication and synchronization costs. Because AMMA is a forward-looking proposal, we rely on validated cycle-accurate simulation rather than silicon measurements of future D2D links. We will add a short subsection in the revised manuscript that explicitly tabulates the control-logic overhead assumptions and includes an additional sensitivity sweep on utilization under pessimistic D2D latency assumptions. revision: partial
Circularity Check
No circularity: performance claims arise from design-space exploration of the proposed architecture, not from self-referential definitions or fitted inputs.
full rationale
The manuscript presents AMMA as a hardware architecture proposal whose latency and energy improvements versus H100 are obtained via design-space exploration over compute power and D2D bandwidth. No equations, fitted parameters, or self-citations appear as load-bearing steps that reduce the headline claims to their own inputs by construction. The central results are simulation outcomes of the described logic-die microarchitecture, hybrid parallelism, and reordered collectives; they are not tautological renamings or predictions forced by prior self-citations. External comparison to a commercial GPU further keeps the evaluation independent of the paper's own definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. 2023. GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
2023
-
[3]
Anthropic. 2026. Introducing Claude Sonnet 4.6. https://www.anthropic.com/ news/claude-sonnet-4-6 Accessed: 2026-04-05
2026
-
[4]
Kyle Aubrey and Farshad Ghodsian. 2026. Inside NVIDIA Groq 3 LPX: The Low- Latency Inference Accelerator for the NVIDIA Vera Rubin Platform. NVIDIA Technical Blog. https://developer.nvidia.com/blog/inside-nvidia-groq-3-lpx-the- low-latency-inference-accelerator-for-the-nvidia-vera-rubin-platform/
2026
-
[5]
BloombergNEF. 2025. Power for AI: Easier Said Than Built. https://about.bnef. com/insights/commodities/power-for-ai-easier-said-than-built/. Accessed: Apr. 2026
2025
-
[6]
CBRE. 2025. Global Data Center Trends 2025. https://www.cbre.com/insights/ reports/global-data-center-trends-2025. Accessed: Apr. 2026
2025
-
[7]
Liyan Chen, Dongxu Lyu, Zhenyu Li, Jianfei Jiang, Qin Wang, Zhigang Mao, and Naifeng Jing. 2025. AttenPIM: Accelerating LLM Attention with Dual-mode GEMV in Processing-in-Memory. In2025 62nd ACM/IEEE Design Automation Conference (DAC). IEEE, 1–7
2025
-
[8]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review arXiv 2025
-
[9]
Guohao Dai, Ke Hong, Qiuli Mao, Xiuhong Li, Jiaming Xu, Haofeng Huang, Hongtu Xia, Xuefei Ning, Shengen Yan, Yun Liang, et al . 2025. FlashDecod- ing++Next: High Throughput LLM Inference with Latency and Memory Opti- mization.IEEE Trans. Comput.(2025)
2025
-
[10]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. InAdvances in Neural Information Processing Systems
2022
-
[11]
Fabrice Devaux. 2019. The true processing in memory accelerator. In2019 IEEE Hot Chips 31 Symposium (HCS). IEEE, 1–24
2019
-
[12]
Wei Fu, Jiaxuan Gao, Xujie Shen, Chen Zhu, Zhiyu Mei, Chuyi He, Shusheng Xu, Guo Wei, Jun Mei, Jiashu Wang, Tongkai Yang, Binhang Yuan, and Yi Wu. 2025. Areal: A large-scale asynchronous reinforcement learning system for language reasoning.arXiv preprint arXiv:2505.24298(2025)
work page internal anchor Pith review arXiv 2025
-
[13]
Wei Gao, Yuheng Zhao, Dakai An, Tianyuan Wu, Lunxi Cao, Shaopan Xiong, Ju Huang, Weixun Wang, Siran Yang, Wenbo Su, Jiamang Wang, Lin Qu, Bo Zheng, and Wei Wang. 2025. Rollpacker: Mitigating long-tail rollouts for fast, synchronous rl post-training.arXiv preprint arXiv:2509.21009(2025)
-
[14]
Siyuan He, Zhantong Zhu, Yandong He, and Tianyu Jia. 2025. LP-Spec: Leveraging LPDDR PIM for Efficient LLM Mobile Speculative Inference with Architecture- Dataflow Co-Optimization. In2025 IEEE/ACM International Conference On Com- puter Aided Design (ICCAD). IEEE, 1–9
2025
-
[15]
Guseul Heo, Sangyeop Lee, Jaehong Cho, Hyunmin Choi, Sanghyeon Lee, Hyungkyu Ham, Gwangsun Kim, Divya Mahajan, and Jongse Park. 2024. Ne- uPIMs: NPU-PIM Heterogeneous Acceleration for Batched LLM Inferencing. InProceedings of the 29th ACM International Conference on Architectural Sup- port for Programming Languages and Operating Systems, Volume 3. https: ...
-
[16]
Ke Hong, Guohao Dai, Jiaming Xu, Qiuli Mao, Xiuhong Li, Jun Liu, Kangdi Chen, Yuhan Dong, and Yu Wang. 2024. Flashdecoding++: Faster large language model inference with asynchronization, flat gemm optimization, and heuristics. Proceedings of Machine Learning and Systems6 (2024), 148–161
2024
-
[17]
JEDEC Solid State Technology Association. 2024. HBM4 High Bandwidth Memory DRAM Standard. JESD235E
2024
-
[18]
Sunghwan Joo, Jinyeon Kim, Yongsun Lee, Ji-Young Kim, Youngsik Lee, Yong-Min Kim, ChiSung Oh, Kyu-Ha Shim, Haesuk Lee, Young-Yong Byun, et al. 2026. 15.6 A 36GB 3.3 TB/S HBM4 DRAM with Per-Channel TSV RDQS Auto Calibration and Fully-Programmable MBIST. In2026 IEEE International Solid-State Circuits Conference (ISSCC), Vol. 69. IEEE, 264–266
2026
-
[19]
Hongju Kal, Seokmin Lee, Gun Ko, and Won Woo Ro. 2021. Space: locality-aware processing in heterogeneous memory for personalized recommendations. In2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA). IEEE, 679–691
2021
-
[20]
Liu Ke, Udit Gupta, Benjamin Youngjae Cho, David Brooks, Vikas Chandra, Utku Diril, Amin Firoozshahian, Kim Hazelwood, Bill Jia, Hsien-Hsin S Lee, et al
-
[21]
In2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA)
Recnmp: Accelerating personalized recommendation with near-memory processing. In2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA). IEEE, 790–803
-
[22]
Heewoo Kim, Sanjay Sri Vallabh Singapuram, Haojie Ye, Joseph Izraelevitz, Trevor Mudge, Ronald Dreslinski, and Nishil Talati. 2025. NMP-PaK: Near-memory processing acceleration of scalable de Novo genome assembly. InProceedings of the 52nd Annual International Symposium on Computer Architecture. 1834–1847
2025
-
[23]
Jin Hyun Kim, Shin-haeng Kang, Sukhan Lee, Hyeonsu Kim, Woongjae Song, Yuhwan Ro, Seungwon Lee, David Wang, Hyunsung Shin, Bengseng Phuah, et al
-
[24]
In2021 IEEE Hot Chips 33 Symposium (HCS)
Aquabolt-XL: Samsung HBM2-PIM with in-memory processing for ML accelerators and beyond. In2021 IEEE Hot Chips 33 Symposium (HCS). IEEE, 1–26
-
[25]
Hyucksung Kwon, Kyungmo Koo, Janghyeon Kim, Woongkyu Lee, Minjae Lee, Hyungdeok Lee, Yousub Jung, Jaehan Park, Yosub Song, Byeongsu Yang, et al
-
[26]
Lol-pim: Long-context llm decoding with scalable dram-pim system.arXiv e-prints(2024), arXiv–2412
2024
-
[27]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th symposium on operating systems principles. 611–626
2023
-
[28]
Youngeun Kwon, Yunjae Lee, and Minsoo Rhu. 2019. Tensordimm: A practical near-memory processing architecture for embeddings and tensor operations in deep learning. InProceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture. 740–753
2019
-
[29]
Yongkee Kwon, Kornijcuk Vladimir, Nahsung Kim, Woojae Shin, Jongsoon Won, Minkyu Lee, Hyunha Joo, Haerang Choi, Guhyun Kim, Byeongju An, et al. 2022. 12 AMMA: A Multi-Chiplet Memory-Centric Architecture for Low-Latency 1M Context Attention Serving XXXX, XXXX, XXXX System architecture and software stack for GDDR6-AiM. In2022 IEEE Hot Chips 34 Symposium (HC...
2022
-
[30]
Sukhan Lee, Shin-haeng Kang, Jaehoon Lee, Hyeonsu Kim, Eojin Lee, Seungwoo Seo, Hosang Yoon, Seungwon Lee, Kyounghwan Lim, Hyunsung Shin, et al. 2021. Hardware architecture and software stack for PIM based on commercial DRAM technology: Industrial product. In2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA). IEEE, 43–56
2021
-
[31]
Cong Li, Yihan Yin, Xintong Wu, Jingchen Zhu, Zhutianya Gao, Dimin Niu, Qiang Wu, Xin Si, Yuan Xie, Chen Zhang, et al. 2025. H2-llm: Hardware-dataflow co- exploration for heterogeneous hybrid-bonding-based low-batch llm inference. In Proceedings of the 52nd Annual International Symposium on Computer Architecture. 194–210
2025
-
[32]
Sixu Li, Yuzhou Chen, Chaojian Li, Yonggan Fu, Zheng Wang, Zhongzhi Yu, Hao- ran You, Zhifan Ye, Wei Zhou, Yongan Zhang, et al. 2025. ORCHES: Orchestrated Test-Time-Compute-based LLM Reasoning on Collaborative GPU-PIM HEteroge- neous System. InProceedings of the 58th IEEE/ACM International Symposium on Microarchitecture. 476–489
2025
- [33]
-
[34]
Hao Liu, Matei Zaharia, and Pieter Abbeel. 2024. Ring Attention with Blockwise Transformers for Near-Infinite Context. InInternational Conference on Learning Representations
2024
- [35]
-
[36]
Meta AI. 2025. The Llama 4 Herd: The Beginning of a New Era of Natively Multi- modal AI Innovation. https://ai.meta.com/blog/llama-4-multimodal-intelligence/ Accessed: 2026-04-05
2025
-
[37]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori B Hashimoto. 2025. s1: Simple test-time scaling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
2025
-
[38]
Naveen Muralimanohar, Rajeev Balasubramonian, Norman P Jouppi, et al. 2009. CACTI 6.0: A tool to model large caches.HP laboratories27 (2009), 28
2009
-
[39]
Dimin Niu, Shuangchen Li, Yuhao Wang, Wei Han, Zhe Zhang, Yijin Guan, Tianchan Guan, Fei Sun, Fei Xue, Lide Duan, et al. 2022. 184QPS/W 64Mb/mm 2 3D logic-to-DRAM hybrid bonding with process-near-memory engine for recommendation system. In2022 IEEE International Solid-State Circuits Conference (ISSCC), Vol. 65. IEEE, 1–3
2022
-
[40]
NVIDIA. 2023. NVIDIA H100 Tensor Core GPU Archtiecture. https://resources.nvidia.com/en-us-tensor-core
2023
-
[41]
NVIDIA. 2025. NVIDIA Blackwell Architecture Overview. https://resources. nvidia.com/en-us-blackwell-architecture
2025
-
[42]
NVIDIA. 2025. NVIDIA Management Library (NVML). https://developer.nvidia. com/management-library-nvml. Accessed: Apr. 2026
2025
-
[43]
NVIDIA. 2025. NVIDIA Rubin HGX Platform. https://www.nvidia.com/en- us/data-center/hgx/. Accessed: Apr. 2026
2025
- [44]
-
[45]
Jaehyun Park, Jaewan Choi, Kwanhee Kyung, Michael Jaemin Kim, Yongsuk Kwon, Nam Sung Kim, and Jung Ho Ahn. 2024. AttAcc! Unleashing the Power of PIM for Batched Transformer-based Generative Model Inference. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. https://doi...
-
[46]
Matthew Poremba, Itir Akgun, Jieming Yin, Onur Kayiran, Yuan Xie, and Gabriel H Loh. 2017. There and back again: Optimizing the interconnect in networks of memory cubes.ACM SIGARCH Computer Architecture News45, 2 (2017), 678–690
2017
-
[47]
Derrick Quinn, E Ezgi Yücel, Jinkwon Kim, José F Martínez, and Mohammad Alian. 2025. LongSight: Compute-Enabled Memory to Accelerate Large-Context LLMs via Sparse Attention. InProceedings of the 58th IEEE/ACM International Symposium on Microarchitecture. 34–48
2025
-
[48]
Ezgi Yücel, Martin Prammer, Zhenxing Fan, Kevin Skadron, Jignesh M
Derrick Quinn, E. Ezgi Yücel, Martin Prammer, Zhenxing Fan, Kevin Skadron, Jignesh M. Patel, José F. Martínez, and Mohammad Alian. 2025. DReX: Accurate and Scalable Dense Retrieval Acceleration via Algorithmic-Hardware Codesign. InProceedings of the 52nd Annual International Symposium on Computer Archi- tecture (ISCA ’25). Association for Computing Machin...
-
[49]
Saeed Rashidi, Srinivas Sridharan, Sudarshan Srinivasan, and Tushar Krishna
-
[50]
In2020 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS)
Astra-sim: Enabling sw/hw co-design exploration for distributed dl training platforms. In2020 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). IEEE, 81–92
-
[51]
Ananda Samajdar, Yuhao Zhu, Paul Whatmough, Matthew Mattina, and Tushar Krishna. 2018. Scale-sim: Systolic cnn accelerator simulator.arXiv preprint arXiv:1811.02883(2018)
work page Pith review arXiv 2018
-
[52]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2019. Megatron-lm: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053(2019)
work page internal anchor Pith review arXiv 2019
-
[53]
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. 2024. Scaling llm test- time compute optimally can be more effective than scaling model parameters. arXiv preprint arXiv:2408.03314(2024)
work page internal anchor Pith review arXiv 2024
-
[54]
GLM-4.5 Team, Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, Kedong Wang, Lucen Zhong, Mingdao Liu, Rui Lu, Shulin Cao, Xiaohan Zhang, Xuancheng Huang, Yao Wei, Yean Cheng, Yifan An, Yilin Niu, Yuanhao Wen, Yushi Bai, Zhengxiao Du, Zihan Wang, Zilin Zhu, Bohan Zhang, Bosi Wen, Bowen Wu...
work page internal anchor Pith review arXiv 2025
-
[55]
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. 2024. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530(2024)
work page internal anchor Pith review arXiv 2024
-
[56]
Kimi Team, Yifan Bai, Yiping Bao, Y. Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, Zhuofu Chen, Jialei Cui, Hao Ding, Mengnan Dong, Angang Du, Chenzhuang Du, Dikang Du, Yulun Du, Yu Fan, Yichen Feng, Kelin Fu, Bofei Gao, Chenxiao Gao, Hongcheng Gao, Peizhong Ga...
work page internal anchor Pith review arXiv 2025
-
[57]
Boyu Tian, Yiwei Li, Li Jiang, Shuangyu Cai, and Mingyu Gao. 2024. Ndpbridge: Enabling cross-bank coordination in near-dram-bank processing architectures. 13 XXXX, XXXX, XXXX Zhongkai Yu, Haotian Ye, Chenyang Zhou, Ohm Rishabh Venkatachalam, Zaifeng Pan, Zhengding Hu, Junsung Kim, Won Woo Ro, Po-An Tsai, Shuyi Pei, Yangwook Kang, and Yufei Ding In2024 ACM...
2024
-
[58]
Universal Chiplet Interconnect Express, Inc. 2025. UCIe (Universal Chiplet Interconnect Express) Specification 3.0. https://www.uciexpress.org/3-0-spec- download. Accessed: Apr. 2026
2025
-
[59]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. InAdvances in Neural Information Processing Systems
2017
- [60]
-
[61]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
2022
-
[62]
William Won, Taekyung Heo, Saeed Rashidi, Srinivas Sridharan, Sudarshan Srinivasan, and Tushar Krishna. 2023. Astra-sim2. 0: Modeling hierarchical networks and disaggregated systems for large-model training at scale. In2023 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). IEEE, 283–294
2023
-
[63]
Bingyang Wu, Shengyu Liu, Yinmin Zhong, Peng Sun, Xuanzhe Liu, and Xin Jin
-
[64]
InProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles
Loongserve: Efficiently serving long-context large language models with elastic sequence parallelism. InProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles. 640–654
- [65]
-
[66]
An Yang, Anfeng Li, Baosong Yang, et al. 2025. Qwen3 Technical Report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review arXiv 2025
-
[67]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems37 (2024), 50528–50652
2024
-
[68]
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. 2022. Webshop: Towards scalable real-world web interaction with grounded language agents. Advances in Neural Information Processing Systems35 (2022), 20744–20757
2022
-
[69]
Sungmin Yun, Byeongho Kim, Jaehyun Park, Hwayong Nam, Jung Ho Ahn, and Eojin Lee. 2022. GraNDe: Near-data processing architecture with adaptive matrix mapping for graph convolutional networks.IEEE Computer Architecture Letters 21, 2 (2022), 45–48
2022
-
[70]
Sungmin Yun, Kwanhee Kyung, Juhwan Cho, Jaewan Choi, Jongmin Kim, Byeongho Kim, Sukhan Lee, Kyomin Sohn, and Jung Ho Ahn. 2024. Duplex: A device for large language models with mixture of experts, grouped query atten- tion, and continuous batching. In2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 1429–1443
2024
-
[71]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. 2024. {DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 193–210
2024
-
[72]
Minxuan Zhou, Weihong Xu, Jaeyoung Kang, and Tajana Rosing. 2022. TransPIM: A memory-based acceleration via software-hardware co-design for transformer. In2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 1071–1085
2022
- [73]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.