HealthNLP_Retrievers at ArchEHR-QA 2026: Cascaded LLM Pipeline for Grounded Clinical Question Answering
Pith reviewed 2026-05-07 10:33 UTC · model grok-4.3
The pith
A cascaded pipeline using Gemini 2.5 Pro produces grounded answers to patient questions about electronic health records through query reformulation, evidence scoring, restricted generation, and alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
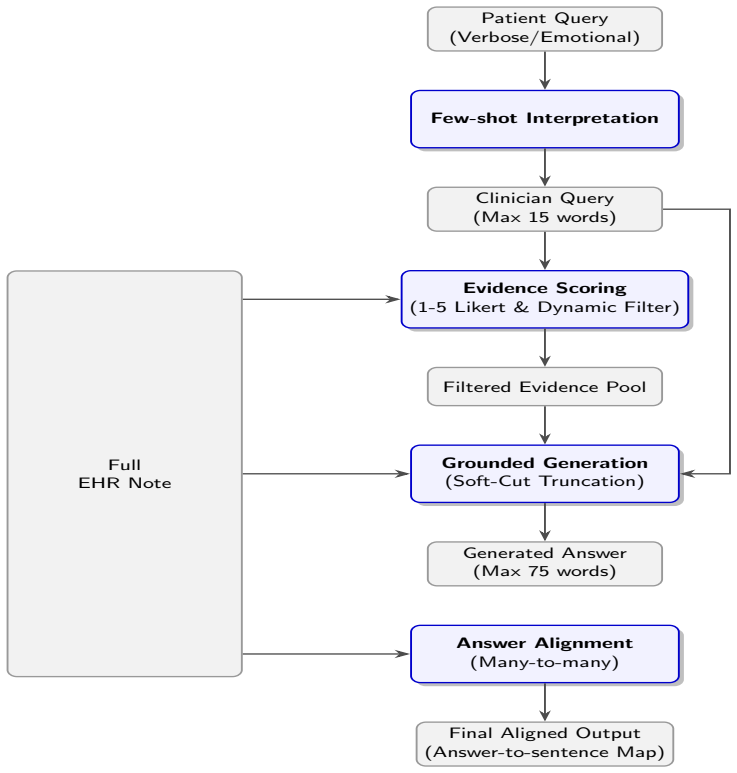
The authors establish that their multi-stage cascaded pipeline powered by Gemini 2.5 Pro, comprising few-shot query reformulation, heuristic-based evidence scoring, grounded response generation restricted to identified evidence, and high-precision many-to-many alignment, delivers competitive performance across all tracks of the ArchEHR-QA 2026 task.
What carries the argument
The four-module cascaded pipeline that reformulates patient queries, scores and retrieves clinical sentences, generates evidence-restricted answers, and creates many-to-many alignments between answers and sources.
If this is right
- Query reformulation condenses patient questions to improve evidence retrieval from lengthy notes.
- Heuristic scoring raises recall when selecting relevant clinical sentences.
- Restricting generation to retrieved evidence produces better-grounded responses.
- Many-to-many alignment creates transparent links that support verification of answers.
- The pipeline yields professional-quality patient communication while maintaining grounding.
Where Pith is reading between the lines
- The same staged structure could be applied to question answering over other types of medical documents such as discharge summaries or lab reports.
- Substituting open-weight models for Gemini 2.5 Pro would allow direct measurement of trade-offs in cost, latency, and precision.
- Adding learned components to the evidence scorer might further reduce missed key information without sacrificing the current heuristic simplicity.
Load-bearing premise
The Gemini 2.5 Pro model together with the heuristic evidence scorer will consistently retrieve only relevant clinical sentences and keep generated answers free of unsupported content.
What would settle it
An evaluation set where any generated answer contains clinical facts absent from the retrieved evidence sentences or omits critical details present in the original notes.
Figures
read the original abstract
Patient portals now give individuals direct access to their electronic health records (EHRs), yet access alone does not ensure patients understand or act on the complex clinical information contained in these records. The ArchEHR-QA 2026 shared task addresses this challenge by focusing on grounded question answering over EHRs, and this paper presents the system developed by the HealthNLP_Retrievers team for this task. The proposed approach uses a multi-stage cascaded pipeline powered by the Gemini 2.5 Pro large language model to interpret patient-authored questions and retrieve relevant evidence from lengthy clinical notes. Our architecture comprises four integrated modules: (1) a few-shot query reformulation unit which summarizes verbose patient queries; (2) a heuristic-based evidence scorer which ranks clinical sentences to prioritize recall; (3) a grounded response generator which synthesizes professional-caliber answers restricted strictly to identified evidence; and (4) a high-precision many-to-many alignment framework which links generated answers to supporting clinical sentences. This cascaded approach achieved competitive results. Across the individual tracks, the system ranked 1st in question interpretation, 5th in answer generation, 7th in evidence identification, and 9th in answer-evidence alignment. These results show that integrating large language models within a structured multi-stage pipeline improves grounding, precision, and the professional quality of patient-oriented health communication. To support reproducibility, our source code is publicly available in our GitHub repository
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper describes the HealthNLP_Retrievers system for the ArchEHR-QA 2026 shared task on grounded clinical question answering over EHRs. It proposes a four-module cascaded pipeline powered by Gemini 2.5 Pro: (1) few-shot query reformulation to summarize patient queries, (2) heuristic-based evidence scorer to rank clinical sentences prioritizing recall, (3) grounded response generator to produce answers strictly from identified evidence, and (4) high-precision many-to-many alignment to link answers to supporting sentences. The system achieved 1st place in question interpretation, 5th in answer generation, 7th in evidence identification, and 9th in answer-evidence alignment. The authors conclude that integrating LLMs in a structured multi-stage pipeline improves grounding, precision, and professional quality of patient-oriented health communication, with source code released publicly on GitHub.
Significance. If the pipeline structure is shown to drive the gains, the work offers a practical example of how cascaded LLM modules can enhance evidence grounding in clinical QA for patient portals, with external validation from shared-task rankings. The public code release is a clear strength that aids reproducibility in health NLP. However, the moderate support noted in the absence of ablations or baselines limits the strength of the significance claim regarding the pipeline's specific contributions over the base model.
major comments (2)
- [Abstract and Results] Abstract and Results section: The central claim that the cascaded pipeline improves grounding, precision, and professional quality is not load-bearing supported by the evidence, as no ablation studies removing individual modules (e.g., the heuristic evidence scorer or many-to-many alignment) or direct baseline comparison to single-stage Gemini 2.5 Pro are reported. The 7th and 9th place rankings in evidence identification and alignment leave open whether gains derive from the pipeline or the underlying LLM.
- [Methods] Methods section (module descriptions): The heuristic-based evidence scorer and grounded response generator lack sufficient detail on mechanisms to ensure no key information is missed or unsupported content added, which directly underpins the grounding claim; without error analysis or quantitative validation of these restrictions, the assumption remains untested.
minor comments (2)
- [Abstract] Abstract: The term 'professional-caliber answers' is used without defining the specific criteria or metrics for professional quality, which could be clarified for precision.
- [Methods] The paper would benefit from a table summarizing the four modules with their inputs, outputs, and key design choices to improve readability of the architecture.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our system description paper for the ArchEHR-QA 2026 shared task. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results section: The central claim that the cascaded pipeline improves grounding, precision, and professional quality is not load-bearing supported by the evidence, as no ablation studies removing individual modules (e.g., the heuristic evidence scorer or many-to-many alignment) or direct baseline comparison to single-stage Gemini 2.5 Pro are reported. The 7th and 9th place rankings in evidence identification and alignment leave open whether gains derive from the pipeline or the underlying LLM.
Authors: We acknowledge that the manuscript lacks ablation studies and direct single-stage baselines, which limits causal attribution of gains to the pipeline structure versus the base LLM. The shared-task rankings (1st in question interpretation, 5th in answer generation) provide external validation of competitiveness, but we agree this does not isolate module contributions. In revision, we will moderate the central claim in the Abstract and Results to focus on observed performance rather than asserting pipeline-driven improvements. We will add a Limitations subsection discussing this gap and outlining plans for future ablations, though full new experiments are constrained by post-task timing. revision: partial
-
Referee: [Methods] Methods section (module descriptions): The heuristic-based evidence scorer and grounded response generator lack sufficient detail on mechanisms to ensure no key information is missed or unsupported content added, which directly underpins the grounding claim; without error analysis or quantitative validation of these restrictions, the assumption remains untested.
Authors: We appreciate this point, as greater transparency on the heuristic rules and grounding constraints is needed. We will expand the Methods section with explicit details on the evidence scorer's heuristics (including keyword overlap, recency weighting, and recall-prioritizing thresholds) and the response generator's prompt constraints that prohibit unsupported content. We will also add a dedicated error analysis subsection using development-set samples to report quantitative metrics on missed evidence and unsupported additions, directly testing the grounding mechanisms. revision: yes
Circularity Check
No circularity; empirical rankings on external shared-task benchmark
full rationale
The paper describes a four-module cascaded LLM pipeline (query reformulation, heuristic evidence scorer, grounded generator, many-to-many alignment) and reports its performance via rankings on the independent ArchEHR-QA 2026 shared task (1st interpretation, 5th generation, 7th evidence ID, 9th alignment). No equations, derivations, fitted parameters, or self-citations appear in the provided text. The central claim that the pipeline improves grounding is tied directly to these external benchmark results rather than any quantity defined or fitted by the authors themselves. This is a standard system-description submission with no load-bearing steps that reduce to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models such as Gemini 2.5 Pro can be reliably instructed to generate answers using only provided clinical evidence.
Reference graph
Works this paper leans on
-
[1]
Introduction Large language models (LLMs) have significantly advanced consumer health question answering. SystemssuchasMed-PaLM2achieveexpert-level performance on medical licensing benchmarks (Singhal et al., 2025). Despite these advances, general-purpose LLMs often struggle to provide grounded answers. Grounding refers to the ability to anchor responses ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Related Work 2.1. Clinical Question Answering Automated clinical QA has evolved from structured knowledge-base lookups to open-domain systems capable of reasoning over unstructured text. Early work on consumer health QA focused on summa- rizing patient questions to bridge the vocabulary gap between nonexpert users and medical profes- sionals (Abacha and D...
work page 2019
-
[3]
revealed several effective design patterns among the 29 participating teams. LAMAR (Yoad- sanit et al., 2025) employed clinically aligned few- shotlearningtogenerategroundedresponsesfrom EHRs, while CUNI (Lanz and Pecina, 2025) in- vestigated whether smaller, more efficient LLMs matchedtheperformanceoffrontiermodelsonclin- ical QA. These studies collectiv...
work page 2025
-
[4]
Methodology The proposed HealthNLP_Retrievers system is a four-stage cascaded pipeline designed to bridge the semantic gap between subjective patient nar- ratives and objective clinical documentation. The system is built using the Gemini 2.5 Pro model to utilize its extended context window to process significantly larger clinical notes. Our approach em- p...
work page 2017
-
[5]
Result Analysis In this section, we analyze the performance of the HealthNLP_Retrievers pipeline on the ArchEHR- QA 2026 dataset. Our evaluation follows the dual- metric framework of the challenge, focusing on factuality (alignment and evidence identification) and relevance (textual quality) (Soni and Demner- Fushman, 2026b). As shown in Table 1, our cas-...
work page 2026
-
[6]
Conclusion We presented the HealthNLP_Retrievers system, a cascaded pipeline for the ArchEHR-QA 2026 sharedtask. BydecomposingclinicalQAintoquery interpretation, heuristic scoring, and precise align- ment, our system effectively bridged the gap be- tween patient narratives and clinical notes. This modular design, driven by our few-shot query re- formulati...
work page 2026
-
[7]
Limitations This work has several limitations. First, the sys- tem relies exclusively on the Gemini 2.5 Pro API, introducing a dependency on a proprietary, closed- weight model. This limits reproducibility and adapt- ability in privacy-sensitive environments, as all clin- ical text is transmitted to an external server. Sec- ond, our evaluation is confined...
work page 2026
-
[8]
Ethics Statement This work utilizes the ArchEHR-QA dataset (Soni and Demner-Fushman, 2026a), which is derived from the de-identified MIMIC-III database (Johnson et al., 2016) and accessed through PhysioNet un- der appropriate data use agreements. To mitigate privacy risks, the patient questions in the dataset are inspired by, rather than directly sourced ...
work page 2016
-
[9]
Bibliographical References Asma Ben Abacha and Dina Demner-Fushman. 2019a. Bridging the gap between consumers’ medication questions and trusted answers. In MEDINFO 2019: Health and Wellbeing e- Networks for All, pages 25–29. IOS Press. Asma Ben Abacha and Dina Demner-Fushman. 2019b. On the role of question summarization and information source restriction ...
work page internal anchor Pith review arXiv 2019
-
[10]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini 1.5: Unlocking multimodal un- derstanding across millions of tokens of context. arXiv preprint arXiv:2403.05530. Wenxuan Wang, Zizhan Ma, Meidan Ding, Shiyi Zheng, Shengyuan Liu, Jie Liu, Jiaming Ji, Went- ing Chen, Xiang Li, Linlin Shen, et al. 2025. Med- ical reasoning in the era of llms: a systematic review of enhancement techniques and applica-...
work page internal anchor Pith review arXiv 2025
-
[11]
BERTScore: Evaluating Text Generation with BERT
LAMAR at ArchEHR-QA 2025: Clini- cally aligned LLM-generated few-shot learning for EHR-grounded patient question answering. InProceedingsofthe24thWorkshoponBiomed- ical Language Processing. Yuheng Zha, Yichi Yang, Ruichen Li, and Zhiting Hu. 2023. Alignscore: Evaluating factual con- sistency with a unified alignment function. In Proceedings of the 61st An...
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.