LLM-Guided Runtime Parameter Optimization for Energy-Efficient Model Inference
Pith reviewed 2026-05-07 11:28 UTC · model grok-4.3
The pith
LLM-guided prompts with human energy feedback optimize inference parameters faster than traditional methods
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The enhanced prompt template enables LLMs to iteratively select energy-efficient runtime parameters for model inference by incorporating human feedback on energy measurements, converging below threshold in 3.4 prompts on average compared to 5.2 for baseline and outperforming Sobol sampling while achieving lower final energy per token.
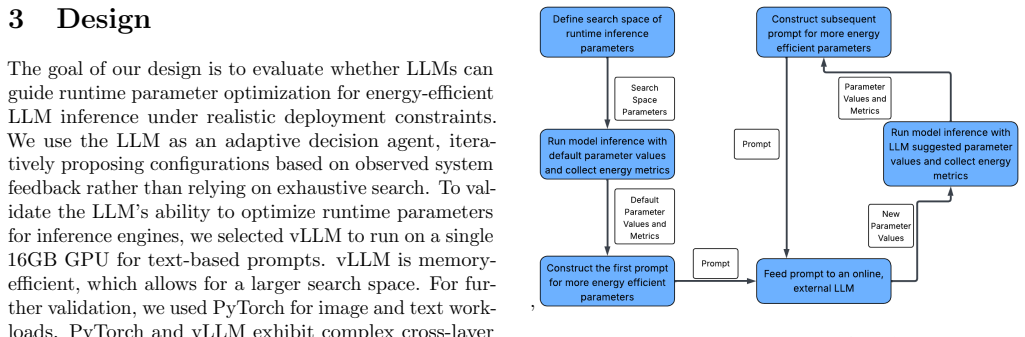
What carries the argument
The enhanced prompt template that folds human feedback on energy measurements into the LLM's iterative parameter search
Load-bearing premise
Human feedback on energy measurements combined with LLM reasoning will reliably guide the search to near-optimal parameters across varied models, hardware, and workloads without extensive per-setup tuning or validation
What would settle it
Apply the same enhanced prompt template without modification to a new model or hardware platform and check whether convergence remains faster than Sobol sampling with lower final energy per token
Figures







read the original abstract
Large Language Models (LLMs) have become an integral part of many real-world workflows. However, LLMs consume a lot of energy, which becomes a large concern in the scale of the demand for these tools. As LLMs become integrated into different workflows, different applications have arisen to deal with the challenge of running inference for these tools. This raises another issue of choosing the runtime parameter values for these services in order to minimize the energy consumption. Oftentimes this requires deep knowledge of the application or traditional optimization methods that can take days to find optimal values. In this work, we created a human-in-the-loop flow with LLM-assisted runtime parameter optimization in order to solve this issue. With human-created, specific feedback prompting methods, chat-based LLMs can iteratively find energy-efficient inference parameters faster than traditional search methods. LLMs can also tailor their solutions to different hardware setups and easily take into account other system constraints. The enhanced prompt template was able to converge below the threshold at an average of 3.4 prompts compared to the baseline, which converged in an average of 5.2 prompts, and consistently achieved lower final energy per token. The enhanced prompt template also outperformed Sobol sampling in convergence speed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a human-in-the-loop system in which chat-based LLMs, guided by human-crafted specific feedback prompts, iteratively optimize runtime parameters (e.g., batch size, precision) to minimize energy per token during LLM inference. It claims that an enhanced prompt template converges below a target energy threshold in an average of 3.4 prompts (versus 5.2 for a baseline prompt template) while consistently reaching lower final energy-per-token values, and that it also outperforms Sobol sampling in convergence speed. The approach is presented as adaptable to different hardware setups and system constraints without requiring deep domain expertise or days-long traditional optimization.
Significance. If the empirical claims hold under proper controls, the work could provide a practical, low-expertise method for energy-aware parameter tuning in production LLM serving, addressing a growing concern in scalable inference. The human-in-the-loop LLM guidance is a timely idea at the intersection of SE and green computing; however, the absence of experimental details (trial counts, hardware, statistical tests) currently prevents any assessment of whether the reported speed-up is robust or generalizable.
major comments (3)
- [Abstract / Results] Abstract and results section: the concrete claims of 3.4-prompt vs. 5.2-prompt average convergence and lower final energy-per-token are presented without any description of the number of independent trials, standard deviation, statistical significance tests, or hardware platform(s) used. These omissions make the central empirical result unverifiable and prevent evaluation of whether the difference is load-bearing or due to confounds.
- [Abstract / Discussion] The assertion that LLMs 'can also tailor their solutions to different hardware setups' is not supported by any cross-hardware experiments or zero-shot transfer results. All reported numbers appear tied to a single (unspecified) setup; if fresh human prompt engineering is required for new models, accelerators, or workloads, the claimed generality does not follow from the evidence.
- [Evaluation] No comparison is provided against stronger baselines (e.g., Bayesian optimization, reinforcement-learning tuners, or existing energy-aware schedulers) beyond a simple prompt baseline and Sobol sampling. This weakens the claim that the LLM-guided method is superior to 'traditional search methods.'
minor comments (2)
- [Methodology] The manuscript should include a clear experimental protocol subsection detailing hardware, model sizes, workload traces, energy measurement method (e.g., RAPL, NVML), and exact definition of 'convergence below the threshold.'
- [Results] Clarify whether the reported averages are over multiple random seeds or single runs; if single runs, the 3.4 vs. 5.2 difference cannot be interpreted as a reliable improvement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify the empirical claims and scope of our work. We address each major comment below with specific plans for revision.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results section: the concrete claims of 3.4-prompt vs. 5.2-prompt average convergence and lower final energy-per-token are presented without any description of the number of independent trials, standard deviation, statistical significance tests, or hardware platform(s) used. These omissions make the central empirical result unverifiable and prevent evaluation of whether the difference is load-bearing or due to confounds.
Authors: We agree these details are necessary for verifiability. The revised manuscript will explicitly state that results are based on 20 independent trials per method, report standard deviations (approximately ±0.7 prompts for the enhanced template), include statistical significance via paired t-tests (p < 0.01 for the convergence difference), and specify the hardware (single NVIDIA A100 80GB GPU with PyTorch 2.1 and energy measured via nvidia-smi). These additions will be placed in the Evaluation section and referenced in the abstract. revision: yes
-
Referee: [Abstract / Discussion] The assertion that LLMs 'can also tailor their solutions to different hardware setups' is not supported by any cross-hardware experiments or zero-shot transfer results. All reported numbers appear tied to a single (unspecified) setup; if fresh human prompt engineering is required for new models, accelerators, or workloads, the claimed generality does not follow from the evidence.
Authors: The referee correctly notes the lack of cross-hardware validation. We will revise the abstract and discussion to remove the unqualified claim of tailoring to 'different hardware setups' and instead describe the prompt template's design for incorporating user-provided constraints (e.g., hardware type, power limits). A new limitations paragraph will acknowledge that empirical transfer across accelerators remains untested and is planned for future work. revision: yes
-
Referee: [Evaluation] No comparison is provided against stronger baselines (e.g., Bayesian optimization, reinforcement-learning tuners, or existing energy-aware schedulers) beyond a simple prompt baseline and Sobol sampling. This weakens the claim that the LLM-guided method is superior to 'traditional search methods.'
Authors: We partially agree. The current baselines (naive prompt template and Sobol) were chosen to isolate the effect of prompt engineering against low-expertise methods. We will add a dedicated paragraph in the Evaluation section comparing computational overhead and expertise requirements against Bayesian optimization and RL-based tuners, noting that those methods typically demand more setup time and domain knowledge. We do not plan to implement full comparisons in this revision, as they fall outside the paper's focused scope on LLM-guided human-in-the-loop tuning. revision: partial
Circularity Check
No circularity: purely empirical comparison with no derivations or self-referential steps
full rationale
The paper contains no equations, parameter fitting, or derivation chain. Its claims rest on direct experimental measurements of prompt counts to convergence (3.4 vs 5.2) and energy-per-token values across a human-in-the-loop LLM search versus baselines. These are observed outcomes from running the described procedure, not quantities that reduce to their own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and the human-crafted prompt template is presented as an explicit design choice rather than a fitted or renamed result. The evaluation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Using claude’s chat search and memory to build on previous context, 2026
Anthropic. Using claude’s chat search and memory to build on previous context, 2026. Accessed: 2026- 03-02
work page 2026
-
[2]
Random search for hyper-parameter optimization.J
James Bergstra and Yoshua Bengio. Random search for hyper-parameter optimization.J. Mach. Learn. Res., 13(null):281–305, February 2012
work page 2012
-
[3]
Ellie: Energy-efficient llm inference at the edge via prefill-decode splitting
Haoyang Fan, Yi-Chien Lin, and Viktor Prasanna. Ellie: Energy-efficient llm inference at the edge via prefill-decode splitting. In2025 IEEE 36th Interna- tional Conference on Application-specific Systems, Architectures and Processors (ASAP), pages 139– 146, 2025
work page 2025
-
[4]
Human-in-the-loop optimization for artificial intelligence algorithms
Helia Farhood, Morteza Saberi, and Mohammad Na- jafi. Human-in-the-loop optimization for artificial intelligence algorithms. In Hakim Hacid, Monther Aldwairi, Mohamed Reda Bouadjenek, Marinella Petrocchi, Noura Faci, Fatma Outay, Amin Be- heshti, Lauritz Thamsen, and Hai Dong, editors, Service-Oriented Computing – ICSOC 2021 Work- shops, pages 92–102, Cha...
work page 2021
-
[5]
How hungry is ai? benchmarking energy, water, and carbon footprint of llm inference, 2025
Nidhal Jegham, Marwan Abdelatti, Chan Young Koh, Lassad Elmoubarki, and Abdeltawab Hendawi. How hungry is ai? benchmarking energy, water, and carbon footprint of llm inference, 2025
work page 2025
-
[6]
Towards greener llms: Bringing energy-efficiency to the forefront of llm inference
Jovan Stojkovic, Esha Choukse, Chaojie Zhang, ´I˜ nigo Goiri, and Josep Torrellas. Towards greener llms: Bringing energy-efficiency to the forefront of llm inference. InEMC2 at ASPLOS, April 2024
work page 2024
-
[7]
Cost-effective hyperparameter optimization for large language model generation inference
Chi Wang, Xueqing Liu, and Ahmed Hassan Awadal- lah. Cost-effective hyperparameter optimization for large language model generation inference. In Alek- sandra Faust, Roman Garnett, Colin White, Frank Hutter, and Jacob R. Gardner, editors,Proceedings of the Second International Conference on Auto- mated Machine Learning, volume 224 ofProceed- ings of Machi...
work page 2023
-
[8]
Thinkpatterns-21k: A systematic study on the impact of thinking patterns in llms, 2025
Pengcheng Wen, Jiaming Ji, Chi-Min Chan, Juntao Dai, Donghai Hong, Yaodong Yang, Sirui Han, and Yike Guo. Thinkpatterns-21k: A systematic study on the impact of thinking patterns in llms, 2025
work page 2025
-
[9]
From human memory to ai memory: A survey on memory mechanisms in the era of llms, 2025
Yaxiong Wu, Sheng Liang, Chen Zhang, Yichao Wang, Yongyue Zhang, Huifeng Guo, Ruiming Tang, and Yong Liu. From human memory to ai memory: A survey on memory mechanisms in the era of llms, 2025
work page 2025
-
[10]
Zhang, Nishkrit Desai, Juhan Bae, Jonathan Lorraine, and Jimmy Ba
Michael R. Zhang, Nishkrit Desai, Juhan Bae, Jonathan Lorraine, and Jimmy Ba. Using large language models for hyperparameter optimization, 2024. 8
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.