Global Optimality for Constrained Exploration via Penalty Regularization
Pith reviewed 2026-05-07 05:19 UTC · model grok-4.3
The pith
A quadratic-penalty policy gradient method achieves global last-iterate convergence for constrained maximum-entropy exploration in reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Policy Gradient Penalty (PGP) method enforces general convex occupancy-measure constraints through quadratic-penalty regularization in a single-loop policy-space optimization. It constructs pseudo-rewards that yield gradient estimates of the penalized objective via the classical Policy Gradient Theorem. The penalized objective is shown to be regular and smooth. Leveraging hidden convexity and strong duality, PGP attains global last-iterate convergence to an ε-optimal constrained entropy value with ε-bounded constraint violation, despite the non-convexity induced by policy parameterization.
What carries the argument
Quadratic-penalty regularization applied to convex occupancy-measure constraints, which produces an unconstrained penalized objective whose gradients are obtained via pseudo-rewards and the Policy Gradient Theorem, with global last-iterate optimality recovered through hidden convexity and strong duality.
If this is right
- A single trained policy can be deployed directly rather than requiring ergodic averaging of multiple policies.
- The same convergence guarantees cover arbitrary convex occupancy constraints including safety, resource, and imitation requirements.
- The approach remains applicable under general differentiable policy parameterizations that would otherwise render the problem non-convex.
- Scalable implementations become feasible for continuous-control tasks once the pseudo-reward construction is in place.
Where Pith is reading between the lines
- The same penalty-plus-duality route may extend to other non-convex RL objectives whose occupancy-measure formulations regain hidden convexity after regularization.
- Practitioners could adapt the penalty schedule dynamically during training to tighten feasibility without sacrificing the last-iterate guarantee.
- The framework indicates that many constrained RL problems become globally tractable once they are lifted to the occupancy-measure space and then penalized.
Load-bearing premise
The occupancy-measure constraints are convex and the resulting penalized objective admits the smoothness and hidden-convexity properties required for the policy-gradient updates and the duality-based optimality transfer to be valid.
What would settle it
A grid-world or continuous-control run in which the final iterate of PGP produces a constrained entropy value more than ε worse than the known optimum or a constraint violation larger than ε, even after the penalty parameter is driven to the regime where theory predicts convergence.
Figures














read the original abstract
Efficient exploration is a central problem in reinforcement learning and is often formalized as maximizing the entropy of the state-action occupancy measure. While unconstrained maximum-entropy exploration is relatively well understood, real-world exploration is often constrained by safety, resource, or imitation requirements. This constrained setting is particularly challenging because entropy maximization lacks additive structure, rendering Bellman-equation-based methods inapplicable. Moreover, scalable approaches require policy parameterization, inducing non-convexity in both the objective and the constraints. To our knowledge, the only prior model-free policy-gradient approach for this setting under general policy parameterization is due to Ying et al. (2025). Unfortunately, their guarantees are limited to weak regret and ergodic averages, which do not imply that the final output is a single deployable policy that is near-optimal and nearly feasible. In this work we take a different approach to this problem, and propose Policy Gradient Penalty (PGP) method, a single-loop policy-space method that enforces general convex occupancy-measure constraints via quadratic-penalty regularization. PGP constructs pseudo-rewards that yield gradient estimates of the penalized objective, subsequently exploiting the classical Policy Gradient Theorem. We further establish the regularity of the penalized objective, providing the smoothness properties needed to justify the convergence of PGP. Leveraging hidden convexity and strong duality, we then establish global last-iterate convergence guarantees, attaining an $\epsilon$-optimal constrained entropy value with $\epsilon$ bounded constraint violation despite policy-induced non-convexity. We validate PGP through ablations on a grid-world benchmark and further demonstrate scalability on two challenging continuous-control tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Policy Gradient Penalty (PGP) method for constrained maximum-entropy exploration in RL. It enforces general convex occupancy-measure constraints through quadratic-penalty regularization, derives pseudo-rewards to enable classical policy-gradient updates on the penalized objective, establishes smoothness and regularity of that objective, and invokes hidden convexity together with strong duality to prove global last-iterate convergence to an ε-optimal constrained entropy value with bounded constraint violation, even under non-convex policy parameterization. Empirical support is given via grid-world ablations and two continuous-control tasks.
Significance. If the hidden-convexity and strong-duality arguments are correct, the work supplies the first last-iterate global-optimality guarantee for this constrained setting under general policy parameterization, a clear improvement over the weak-regret/ergodic-average results of Ying et al. (2025). The single-loop penalty approach is practically attractive for safe or resource-constrained exploration. The technical device of transferring optimality via hidden convexity may have wider applicability to other non-convex occupancy-measure problems in RL.
major comments (1)
- Abstract and convergence analysis: the central claim that strong duality transfers optimality from the convex occupancy-measure problem to the non-convex policy parameterization rests on the penalized objective admitting hidden convexity and satisfying a constraint qualification. The manuscript must explicitly state the qualification used (e.g., Slater’s condition or an interior-point assumption on the occupancy constraints) and verify that it remains valid after the quadratic penalty is introduced and the policy parameterization is applied.
minor comments (3)
- Abstract: the citation “Ying et al. (2025)” should be expanded to a full bibliographic entry in the reference list and cross-checked for consistency with the in-text citation.
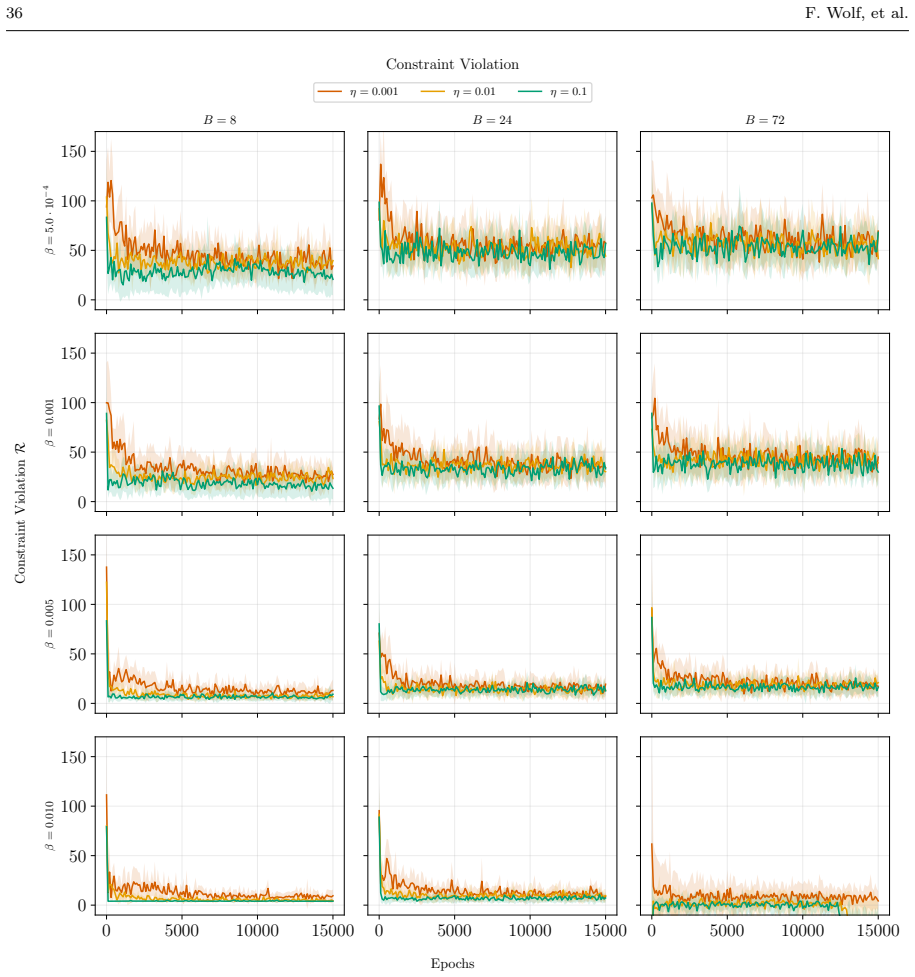
- Experiments section: the precise convex occupancy-measure constraints used in the grid-world ablations and the two continuous-control tasks, together with the numerical values of the penalty coefficient, should be stated explicitly to support reproducibility.
- Notation and algorithm description: the construction of the pseudo-rewards from the quadratic penalty term would benefit from an explicit equation label so that subsequent convergence arguments can refer to it directly.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and for identifying this important clarification point regarding the constraint qualification. We address the comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract and convergence analysis: the central claim that strong duality transfers optimality from the convex occupancy-measure problem to the non-convex policy parameterization rests on the penalized objective admitting hidden convexity and satisfying a constraint qualification. The manuscript must explicitly state the qualification used (e.g., Slater’s condition or an interior-point assumption on the occupancy constraints) and verify that it remains valid after the quadratic penalty is introduced and the policy parameterization is applied.
Authors: We agree that the constraint qualification should be stated explicitly rather than left implicit. In the revised manuscript we will add a dedicated paragraph in the convergence analysis (Section 4) stating that we invoke Slater’s condition on the original convex occupancy-measure problem: there exists an occupancy measure μ* satisfying g(μ*) < 0 for all inequality constraints (with a positive margin). We will then verify that this condition is preserved after quadratic-penalty regularization: the penalty term is identically zero on the feasible set and strictly positive outside it, so any strictly feasible μ* remains strictly feasible for the penalized objective; moreover, because the penalty is convex in the occupancy measure, the hidden-convexity property of the penalized problem is unchanged. For the non-convex policy parameterization, hidden convexity already guarantees that the policy-induced occupancy measures can attain the same optimum as the convex relaxation; the Slater condition is a property of the occupancy-measure feasible set and does not need to be re-verified for each parameterization (provided the policy class is sufficiently expressive, which is assumed throughout and validated empirically). We will also insert a brief reference to this assumption in the abstract. These changes will be made without altering any theorems or proofs. revision: yes
Circularity Check
No significant circularity; derivation relies on classical theorems
full rationale
The paper's derivation chain begins from the standard Policy Gradient Theorem applied to a quadratic-penalty regularized objective, then invokes established smoothness properties, hidden convexity of the penalized entropy, and strong duality to transfer global optimality from the convex occupancy-measure space back to the non-convex policy parameterization. These steps cite the classical Policy Gradient Theorem and standard convex-optimization duality results rather than any self-defined quantity, fitted parameter, or prior result by the same authors. The single external citation to Ying et al. (2025) is to independent prior work on the same problem and is not used to justify uniqueness or to close the main argument. No equation reduces to its own input by construction, and the central last-iterate guarantee remains independently supported by the cited external theorems.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The penalized objective is smooth and possesses hidden convexity
- domain assumption Strong duality holds for the constrained entropy problem after penalty regularization
Reference graph
Works this paper leans on
-
[1]
PMLR, July 2023. A. Barakat, S. Chakraborty, P. Yu, P. Tokekar, and A. S. Bedi. Towards Scalable General Utility Reinforcement Learning: Occupancy Approximation, Sample Complexity and Global Optimality, Feb. 2025. D. P. Bertsekas.Nonlinear Programming. Athena Scientific, 2 edition, Sept. 1999. ISBN 978-1-886529-00-7. D. P. Bertsekas, editor.Convex Optimiz...
-
[2]
PMLR, Nov. 2020. B. Marin Moreno, M. Brégère, P. Gaillard, and N. Oudjane. MetaCURL: Non-stationary Concave Utility Rein- forcement Learning.Advances in Neural Information Processing Systems, 37:123091–123126, Dec. 2024. doi: 10.52202/079017-3912. B. Martinet. Brève communication. Régularisation d’inéquations variationnelles par approximations successives...
-
[3]
ISSN 0037-9484. B. M. Moreno, M. Brégère, P. Gaillard, and N. Oudjane. Efficient Model-Based Concave Utility Reinforcement Learning through Greedy Mirror Descent. In S. Dasgupta, S. Mandt, and Y. Li, editors,International Conference on Artificial Intelligence and Statistics, 2-4 May 2024, Palau de Congressos, Valencia, Spain, volume 238 ofProceedings of M...
-
[4]
PMLR, 2025. A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmai- son, A. Köpf, E. Z. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In H. M. Wallach, H. Larochelle...
-
[5]
ISSN 0364-765X, 1526-5471. doi: 10.1287/moor.8.2.231. A. Wachi, W. Hashimoto, X. Shen, and K. Hashimoto. Safe Exploration in Reinforcement Learning: A Generalized Formulation and Algorithms. InThirty-Seventh Conference on Neural Information Processing Systems, Nov. 2023. I.-J. Wang and J. C. Spall. Stochastic optimisation with inequality constraints using...
-
[6]
The domainΛ=c(Θ)is convex, the functionsH 1, H2 :Λ→Rare convex, i.e. satisfy fori= 1,2and for allu, v∈Λ and anyα∈[0,1] Hi((1−α)u+αv)≤(1−α)H i(u) +αH i(v)− (1−α)αµ H 2 ∥u−v∥ 2.(HC-1) Additionally, we assume (HC) admits a solutionu ∗ ∈Λwith its corresponding objective function valueF ∗ := H1(u∗) =F 1(c−1(u∗)). Throughout this appendix,F∗ denotes the minimum...
-
[7]
IPPPM” refers to the inexact proximal point penalty framework, “GD
The mapc:Θ→Λis invertible and there exists aµ c >0such that for allθ, ˜θ∈Θit holds ∥c(θ)−c( ˜θ)∥ ≥µ c∥θ− ˜θ∥.(HC-2) Ifµ H >0, we refer to (HC) as(µ c, µH )-strongly convex. Note that in this more generic setting, we haveµc =µ λ of Assumption 2. We can map (CME) to (HC) viaH1 =−HandH 2 =R. Note that the condition (HC-2) along with Assumption 8 imply that t...
work page 2020
-
[8]
VF” refers to the value function, i.e. the critic we use in the REINFORCE estimate, “Lr
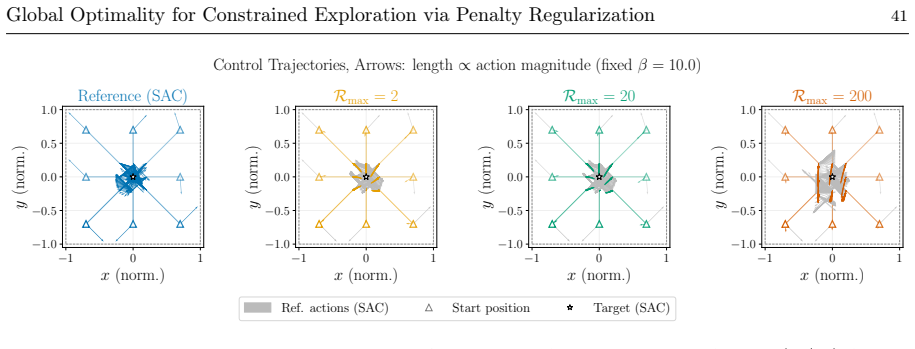
which is an extension of the Google DeepMind Con- trol suite (Todorov et al. 2012, Tassa et al. 2018). The pen- dulum starts in the resting downwards position and the goal is to safely explore the dynamics of the system with- out exceeding an imposed slider safety limits on the left and right. Fig. 5: Overview of the grid-world with discrete state-action ...
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.