RunAgent: Interpreting Natural-Language Plans with Constraint-Guided Execution
Pith reviewed 2026-05-09 19:51 UTC · model grok-4.3
The pith
RunAgent improves plan execution by autonomously deriving constraints from natural-language task descriptions and enforcing them step by step.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
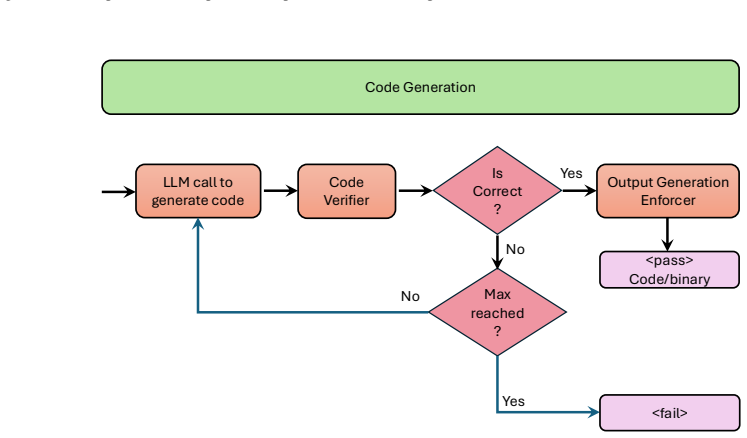
RunAgent interprets natural-language plans through an agentic language with control constructs and enforces stepwise execution via autonomously derived and validated constraints and rubrics, while dynamically selecting LLM reasoning, tool use, or code generation plus error correction.
What carries the argument
Constraint-guided execution mechanism that autonomously derives and validates constraints and rubrics from each task description to direct the choice of reasoning method and verify outputs.
If this is right
- RunAgent outperforms baseline LLMs and PlanGEN methods on Natural-plan and SciBench datasets.
- Stepwise constraint enforcement combined with error correction increases correctness in long workflows.
- Dynamic selection of reasoning methods and context filtering maintain focus without losing necessary information.
- The agentic language with IF, GOTO, and FORALL enables structured control inside natural-language plans.
Where Pith is reading between the lines
- The same constraint derivation process could support automated scientific experiment pipelines described in plain language.
- Extending the method to plans that require coordination across multiple external tools might reveal new error patterns.
- If constraint quality varies by domain, hybrid human-AI review of derived rubrics could be tested as a lightweight addition.
Load-bearing premise
That the autonomous derivation and validation of constraints from task descriptions will reliably produce useful rubrics that improve execution correctness across diverse plans.
What would settle it
A new benchmark dataset of plans with ambiguous constraints where RunAgent's derived rubrics produce lower accuracy than unconstrained LLM execution.
Figures








read the original abstract
Humans solve problems by executing targeted plans, yet large language models (LLMs) remain unreliable for structured workflow execution. We propose RunAgent, a multi-agent plan execution platform that interprets natural-language plans while enforcing stepwise execution through constraints and rubrics. RunAgent bridges the expressiveness of natural language with the determinism of programming via an agentic language with explicit control constructs (e.g., \texttt{IF}, \texttt{GOTO}, \texttt{FORALL}). Beyond verifying syntactic and semantic verification of the step output, which is performed based on the specific instruction of each step, RunAgent autonomously derives and validates constraints based on the description of the task and its instance at each step. RunAgent also dynamically selects among LLM-based reasoning, tool usage, and code generation and execution (e.g., in Python), and incorporates error correction mechanisms to ensure correctness. Finally, RunAgent filters the context history by retaining only relevant information during the execution of each step. Evaluations on Natural-plan and SciBench Datasets demonstrate that RunAgent outperforms baseline LLMs and state-of-the-art PlanGEN methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RunAgent, a multi-agent platform for executing natural-language plans. It interprets plans via an agentic language with control constructs (IF, GOTO, FORALL), autonomously derives and validates constraints/rubrics from task descriptions at each step, dynamically selects among LLM reasoning, tools, and code execution, applies error correction, and filters context history. The central claim is that this constraint-guided approach yields outperformance over baseline LLMs and PlanGEN methods on the Natural-plan and SciBench datasets.
Significance. If the performance gains are shown to be robust and attributable to the autonomous constraint mechanism, the work could meaningfully advance reliable structured execution in LLM agents by combining natural-language expressiveness with deterministic verification. The idea of deriving rubrics on-the-fly from task instances, rather than relying solely on manual engineering, is a potentially useful direction for agentic systems.
major comments (2)
- [§4] §4 (Experiments): The outperformance claim on Natural-plan and SciBench is stated without any reported metrics, baseline implementations, statistical significance tests, or error analysis. This prevents verification of the headline result and makes it impossible to assess whether gains are meaningful or consistent.
- [§3.2] §3.2 (Constraint Derivation): No quantitative breakdown is given of the success rate, failure modes, or coverage of the autonomously derived constraints/rubrics. Because the paper attributes its advantage to constraint-guided execution, the absence of an ablation that disables only this module (while retaining dynamic selection, error correction, and context filtering) leaves the central causal claim unsupported.
minor comments (2)
- [§3.1] The agentic language constructs are described at a high level; a small formal syntax or illustrative code example would improve reproducibility.
- [§4] Dataset statistics (task counts, plan lengths, domains) and exact baseline versions are not summarized in the evaluation section.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The two major comments highlight important gaps in experimental reporting and causal analysis. We address each point below and commit to a major revision that incorporates the requested details, metrics, and ablations without altering the core claims of the work.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The outperformance claim on Natural-plan and SciBench is stated without any reported metrics, baseline implementations, statistical significance tests, or error analysis. This prevents verification of the headline result and makes it impossible to assess whether gains are meaningful or consistent.
Authors: We agree that the current presentation of results in §4 is insufficiently detailed for independent verification. The manuscript does contain comparative tables, but they lack the full numerical values, baseline code references, significance testing, and error breakdowns the referee correctly identifies as necessary. In the revised version we will expand §4 with complete accuracy and success-rate tables for both datasets, explicit descriptions of baseline implementations (including prompts and hyperparameters for GPT-4, Claude, and PlanGEN), paired t-test p-values, and a categorized error analysis (e.g., constraint violation, execution failure, reasoning error). These additions will directly support the outperformance claim. revision: yes
-
Referee: [§3.2] §3.2 (Constraint Derivation): No quantitative breakdown is given of the success rate, failure modes, or coverage of the autonomously derived constraints/rubrics. Because the paper attributes its advantage to constraint-guided execution, the absence of an ablation that disables only this module (while retaining dynamic selection, error correction, and context filtering) leaves the central causal claim unsupported.
Authors: We accept that the causal contribution of autonomous constraint derivation requires stronger empirical support. The revised manuscript will add a dedicated subsection under §3.2 (or a new §4.3) reporting quantitative metrics on constraint derivation: success rate of rubric generation, coverage of task constraints, and observed failure modes across Natural-plan and SciBench instances. We will also include a controlled ablation that removes only the constraint-derivation module while preserving dynamic reasoning-mode selection, error correction, and context filtering. The resulting performance delta will be reported with the same metrics and significance tests used in the main experiments, directly addressing the referee’s concern about attribution. revision: yes
Circularity Check
No circularity: descriptive systems paper with no derivations or self-referential reductions
full rationale
The manuscript describes RunAgent as an agentic platform using natural-language plans, explicit control constructs, autonomous constraint/rubric derivation, dynamic LLM/tool/code selection, error correction, and context filtering. The sole load-bearing claim is empirical outperformance on Natural-plan and SciBench. No equations, fitted parameters, first-principles derivations, or predictions appear. No self-citations are invoked to justify uniqueness or ansatzes. The method is presented as a procedural composition of standard agentic techniques; the evaluation result does not reduce to any input by construction. This matches the reader's 0.0 assessment and satisfies the default expectation for non-circularity in systems papers lacking mathematical chains.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
H. Wei, Z. Zhang, S. He, T. Xia, S. Pan, and F. Liu. Plangenllms: A modern survey of llm planning capabilities.Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics, 2025
work page 2025
-
[4]
L.P. Kaelbling, M.L. Littman, and A.R. Cassandra. Planning and acting in partially observable stochastic domains.Artificial Intelligence, 101(1–2):99–134, 1998
work page 1998
-
[5]
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversations. InFirst Conference on Language Modeling, 2024
work page 2024
-
[6]
G. Wang, Y . Xie, Y . Jiang, A. Mandlekar, C. Xiao, Y . Zhu, L. Fan, and A. Anandkumar. V oyager: An open-ended embodied agent with large language models.Transactions on Machine Learning Research, 2023
work page 2023
-
[7]
A.B. Corr ˆea, A.G. Pereira, and J. Seipp. Classical planning with llm- generated heuristics: Challenging the state of the art with python code. arXiv preprint arXiv:2503.18809, 2025
-
[8]
H. Mozannar, G. Bansal, C. Tan, A. Fourney, V . Dibia, J. Chen, J. Gerrits, T. Payne, M.K. Maldaner, M. Grunde-McLaughlin, et al. Magentic-ui: Towards human-in-the-loop agentic systems.arXiv preprint arXiv:2507.22358, 2025
-
[9]
K. Rao, G. Coviello, G. Mellone, C.G. De Vita, and S. Chakradhar. XPF: Agentic ai system for business workflow automation. InPro- ceedings of the 34th International Symposium on High-Performance Parallel and Distributed Computing, HPDC ’25. Association for Computing Machinery, 2025
work page 2025
-
[10]
G. Coviello and S. Chakradhar. V ¨ol: A human-centric instruction language for AI-native automation. Technical Report 2026-TR011, NEC Laboratories America, Inc., 2026
work page 2026
- [11]
- [12]
-
[13]
X. Wang, Z. Hu, P. Lu, Y . Zhu, J. Zhang, S. Subramaniam, A.R. Loomba, S. Zhang, Y . Sun, and W. Wang. Scibench: evaluating college-level scientific problem-solving abilities of large language models. InProceedings of the 41st International Conference on Machine Learning, pages 50622–50649, 2024
work page 2024
-
[14]
A. Hurst, A. Lerer, A.P. Goucher, A. Perelman, A. Ramesh, A. Clark, AJ Ostrow, A. Welihinda, A. Hayes, A. Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024. APPENDIX A. Prompts
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Initialization Prompts: Constraint Generation Prompt messages=[{”role”: ”system”, ”content”: ”””You are an expert at extracting constraints that MUST NOT be violated when solving a task instance. You will be given: - A task description - A specific instance of the task Your job: - Output a comprehensive list of constraints that should not be violated whil...
-
[16]
You are given a Python code{code generated}
Python Code Execution Prompts: Python Code Add Print System Prompt You are an expert at recognizing and adding print statements to Python code. You are given a Python code{code generated}. If the code prints an output, output ”No” without any other text. If the code does not print an output, add an appropriate print statement to the code to print an outpu...
-
[17]
The Python code to implement the last step is also given
Constraint Validation Prompts: Python Code Execution System Prompt You are given a conversation, where at the end of the conversation a step is supposed to be carried out. The Python code to implement the last step is also given. Execute the Python code. If you reply with a Function Call, you must carefully provide the arguments required to run the Python...
-
[18]
Task:{task} Instance:{instance}
Executor Prompts: Executor System Prompt You will execute a series of steps on a given input. Task:{task} Instance:{instance}. You may be provided a preamble before the steps. Each step may have constraints. Every time I ask you to execute a step, you will generate just the exact output for the step without any further explanation. The message with the st...
-
[19]
Compiler Prompts: Python Judge System Prompt You are asked to judge whether a step at the end of a conversation can be implemented better as a Python code or by LLM API call. You know that LLMs are good at problems where natural language processing and creativity are required. You know that LLMs are not good at problems where algorithmic thinking and math...
-
[20]
Below you are given the associated task, an instance and a chat history
Keyword Prompts: FORALL Prompt messages = [{”role”: ”system”, ”content”: ”””You are given a FORALL statement from the user. Below you are given the associated task, an instance and a chat history. The task is:{task}. The instance is:{instance}. The chat history is:{chat history}. Your job is to use the task, instance and chat history to find all items tha...
-
[21]
Execute the numbered plan exactly
Example for FORALL: a) Task:Write short creative stories about New York monuments. Execute the numbered plan exactly. Every story should be about 100 words and focused on the monument named in the iteration. b) Input: New York monuments and landmarks to feature: Statue of Liberty, Brooklyn Bridge, Empire State Building. c) Plan and Observed Output: Plan:1...
-
[22]
Math branch activated because 12>7
Example for IF (True): a) Task:Demonstrate conditional execution with sim- ple mathematical statements. Execute the numbered plan exactly, and when a step asks for exact text, reproduce it verbatim with no extra words. b) Input: Math note: 12 is greater than 7, 3 is less than 10, and no arithmetic errors are present. c) Plan and Observed Output: Step 1 IF...
-
[23]
Example for IF (False): a) Task:Demonstrate conditional execution with sim- ple mathematical statements. Execute the numbered plan exactly, and when a step asks for exact text, reproduce it verbatim with no extra words. b) Input: Math note: 5 is less than 9, 2 plus 2 equals 4, and 10 is not less than 3. c) Plan and Observed Output: Step 1 IF 10 is less th...
-
[24]
Example for GOTO: a) Task:Demonstrate direct control-flow jumps. Exe- cute the numbered plan exactly, and when a step asks for exact text, reproduce it verbatim with no extra words. b) Input: Routing note: jump directly to the emergency branch and skip the descriptive intermediate steps. c) Plan and Observed Output: Step 1 goto step 4 Observed output:no s...
-
[25]
Example for Natural Plan Calendar Scheduling: Executor System Prompt Task: Your task is to find a feasible schedule for calendar events, taking into account time slots, durations, constraints, and conflicts. You will analyze the calendar requirements and available time slots to determine the optimal event schedule. Output the final calendar schedule outli...
-
[26]
Output the final answer in the required format, without any other text
Example for Scibench Stat: Task: Your task is to solve statistics and probability problems by analyzing the problem statement, applying appropriate statistical methods, and calculating the required values. Output the final answer in the required format, without any other text. Instance: If the distribution ofYisb(n,0.25), give a lower bound forP(|Y /n−0.2...
-
[27]
Example for Natural Plan Calendar Scheduling: a) If a busy slot ends at time t, then the person is considered free at time t. For example, if the person is busy from 10:00 AM to 12:00 PM, then the person is considered free at 12:00 PM, and a meeting can be scheduled at 12:00 PM for this person. b) There is no need to have breaks between work for any perso...
-
[28]
b) If you spend a day in two cities, count the day for both cities
Example for Natural Plan Trip Planning: a) If you spend any time of the day in a city, count it as a full day spent in that city. b) If you spend a day in two cities, count the day for both cities. c) The day you arrive in a city is counted as a full day spent in the city, and the trip starts on the day you arrive. d) The day you leave a city is counted a...
-
[29]
Example for Scibench Stat: a) Chebyshev’s inequality should be used when applica- ble
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.