Recognition: unknown
Graph Query Generation with Constraint-guided Large Language Agents
Pith reviewed 2026-05-10 16:51 UTC · model grok-4.3
The pith
UniQGen uses constraint-guided LLM agents to generate executable graph queries across languages without schema-specific fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
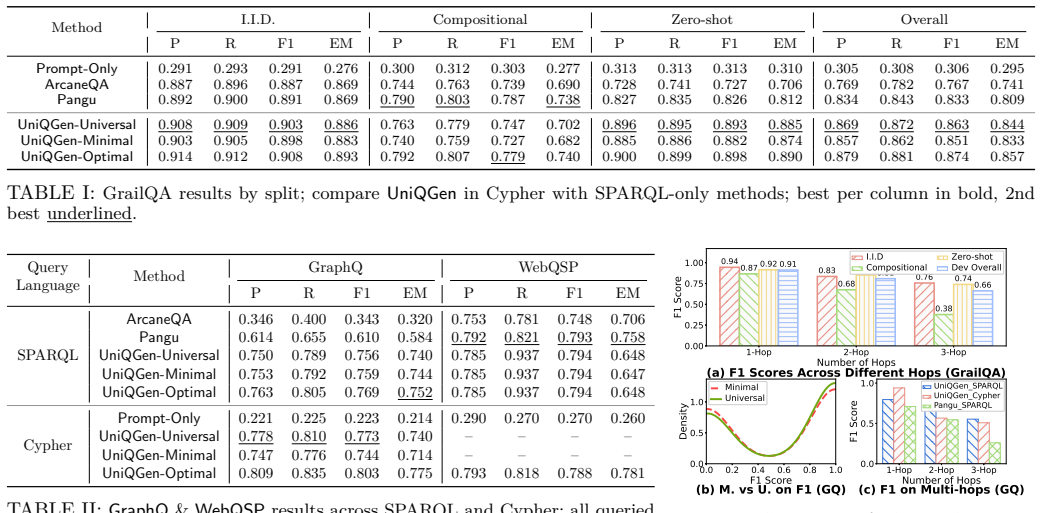
UniQGen shows that a Chase & Backchase variant augmented with dynamic constraint reasoning and LLM-based quality estimation can extract representative clauses and produce executable, intent-aligned graph queries in multiple languages, achieving F1 gains of 31.6 percent on GraphQ and 4.9 percent on GrailQA over prior techniques while requiring no fine-tuning for schema matching.
What carries the argument
A variant of Chase & Backchase extended with dynamic reasoning over query constraints that interacts with LLMs for query quality estimation, used to extract and refine representative graph query clauses into executable queries.
If this is right
- The framework delivers higher accuracy and efficiency than prior graph query generators on GraphQ, GrailQA, and WebQSP.
- UniQGen works on schema-less or varying graphs because it avoids any fine-tuning step for schema matching.
- The same pipeline supports cross-language KGQA by producing executable queries in Cypher for property graphs deployed on systems such as Neptune.
- Releasing Cypher outputs and a Neptune-ready Freebase snapshot enables reproducible experiments across query languages.
Where Pith is reading between the lines
- The constraint-guided pattern could be ported to additional query languages or graph stores without redesigning the core loop.
- Enterprise settings with frequent schema evolution might adopt the method to maintain query generation quality over time.
- Scaling the LLM interaction step to larger graphs could reveal limits on reasoning depth that require further constraint pruning.
Load-bearing premise
The dynamic reasoning process over query constraints interacts effectively with LLMs to estimate quality and produce intent-aligned queries without post-hoc tuning.
What would settle it
Apply UniQGen to a fresh KGQA benchmark with unseen schema structure and measure whether F1 scores fall below or match those of fine-tuned baselines on the same data.
Figures



read the original abstract
Knowledge Graph Question Answering (KGQA) has advanced through structured query generation, yet most efforts target RDF/SPARQL, leaving Cypher and property graphs underexplored, despite increasing demand for unified KGQA in industry settings. We propose UniQGen, a novel constraint-based framework that employs LLM agents to dynamically extract and refine representative graph query clauses into executable, intent-aligned graph queries across query languages. The foundation of our method is a variant of Chase & Backchase, a family of algorithms for query optimization and reformulation. We extend Chase & Backchase with a dynamic reasoning process over query constraints that also interact with LLMs for query quality estimation. With a Cypher-supported Freebase graph deployed on Amazon Neptune, we extensively evaluate our approach on popular KGQA benchmarks (GraphQ, GrailQA, and WebQSP). We demonstrate that UniQGen outperforms state-of-the-art graph query generation techniques in both accuracy and efficiency, with F1 gains of 31.6% on GraphQ and 4.9% on GrailQA. Unlike prior methods, our framework does not require fine-tuning for schema matching, making it more extensible to schema-less graphs and semantics in query workloads, and is more suitable for enterprise-grade KGQA. We release Cypher outputs and a Neptune-ready Freebase snapshot to support reproducible, cross-language KGQA research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UniQGen, a constraint-guided framework that extends the Chase & Backchase algorithm with LLM agents for dynamic reasoning over query constraints and quality estimation. It generates executable, intent-aligned graph queries (primarily Cypher on a Neptune-hosted Freebase graph) from natural language questions without requiring fine-tuning for schema matching. The central empirical claim is that UniQGen outperforms prior graph query generation methods, achieving F1 gains of 31.6% on GraphQ and 4.9% on GrailQA, with additional claims of improved efficiency and extensibility to schema-less graphs; the authors release Cypher outputs and a Neptune-ready Freebase snapshot.
Significance. If the reported F1 gains are reproducible and attributable to the proposed LLM-augmented Chase & Backchase extension rather than base prompting or experimental setup, the work would meaningfully advance unified KGQA across RDF and property-graph query languages. The absence of fine-tuning requirements and the release of artifacts for cross-language reproducibility are clear strengths that could support follow-on research in enterprise KGQA settings.
major comments (2)
- [Evaluation] Evaluation section: the central claim attributes the 31.6% F1 gain on GraphQ (and 4.9% on GrailQA) to the dynamic reasoning process over query constraints that interacts with LLMs for quality estimation. No ablation is described that disables or replaces the LLM quality-estimation step while keeping the rest of the agent framework fixed; therefore the gains could arise from base LLM prompting, schema exposure in the prompt, or the Neptune/Freebase setup rather than the claimed interaction. This assumption is load-bearing because the paper positions the extension as the key differentiator from prior methods.
- [Method] Method section (Chase & Backchase variant): the description of how the dynamic reasoning process interacts with LLMs for query quality estimation lacks concrete pseudocode, worked examples, or formalization showing the precise interface between constraint chasing and LLM calls. Without this, it is impossible to assess whether the extension is a genuine algorithmic advance or primarily prompt engineering.
minor comments (2)
- [Abstract] The abstract states specific F1 gains and artifact releases but provides no baseline names, error bars, statistical significance tests, or ablation results, which is atypical for an empirical DB paper and hinders immediate assessment.
- Table or figure captions for the main results should explicitly list all baselines, their fine-tuning status, and the exact query language used, to make the cross-language claim easier to verify.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that both the evaluation and method sections can be strengthened to better substantiate our claims regarding the contribution of the dynamic reasoning process. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the central claim attributes the 31.6% F1 gain on GraphQ (and 4.9% on GrailQA) to the dynamic reasoning process over query constraints that interacts with LLMs for quality estimation. No ablation is described that disables or replaces the LLM quality-estimation step while keeping the rest of the agent framework fixed; therefore the gains could arise from base LLM prompting, schema exposure in the prompt, or the Neptune/Freebase setup rather than the claimed interaction. This assumption is load-bearing because the paper positions the extension as the key differentiator from prior methods.
Authors: We acknowledge that the absence of a targeted ablation isolating the LLM quality-estimation step leaves open the possibility that gains stem from base prompting or experimental setup. In the revised manuscript, we will add an ablation study that disables or replaces the LLM-based quality estimation (e.g., with a deterministic heuristic) while retaining the constraint-chasing framework and other agent components. This will provide direct evidence that the reported F1 improvements are attributable to the proposed interaction rather than prompting alone. revision: yes
-
Referee: [Method] Method section (Chase & Backchase variant): the description of how the dynamic reasoning process interacts with LLMs for query quality estimation lacks concrete pseudocode, worked examples, or formalization showing the precise interface between constraint chasing and LLM calls. Without this, it is impossible to assess whether the extension is a genuine algorithmic advance or primarily prompt engineering.
Authors: We agree that the current description would benefit from greater formalization to clarify the algorithmic contribution. In the revision, we will include pseudocode for the full dynamic reasoning loop, a formal description of the interface between constraint chasing steps and LLM calls for quality estimation, and a worked example tracing a sample query through the process. These additions will make explicit how the extension goes beyond standard prompting. revision: yes
Circularity Check
No circularity: empirical gains measured on external public benchmarks
full rationale
The paper describes UniQGen as an LLM-agent framework extending the known Chase & Backchase algorithm family with constraint-guided dynamic reasoning and LLM-based quality estimation. Performance claims consist of measured F1 improvements (31.6% on GraphQ, 4.9% on GrailQA) against prior methods on standard public KGQA benchmarks, with released outputs for reproducibility. No equations, fitted parameters, or self-referential definitions appear that would make the reported gains equivalent to the method's own inputs by construction. The central differentiator (no fine-tuning for schema matching) is presented as an empirical outcome rather than a definitional tautology. Evaluation is against external baselines on fixed datasets, satisfying the criterion for self-contained, non-circular empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A variant of Chase & Backchase can be extended with dynamic LLM reasoning for query generation and quality estimation.
Reference graph
Works this paper leans on
-
[1]
The onegraph vision: Challenges of breaking the graph model lock-in,
O. Lassila, M. Schmidt, O. Hartig, B. Bebee, D. Bechberger, W. Broekema, A. Khandelwal, K. Lawrence, C. M. Lopez En- riquez, R. Sharda et al., “The onegraph vision: Challenges of breaking the graph model lock-in,” Semantic Web, vol. 14, no. 1, pp. 125–134, 2022
work page 2022
-
[2]
Multilayer graphs: a unified data model for graph databases,
R. Angles, A. Hogan, O. Lassila, C. Rojas, D. Schwabe, P. Szekely, and D. Vrgoč, “Multilayer graphs: a unified data model for graph databases,” in Proceedings of the 5th ACM SIGMOD Joint International Workshop on Graph Data Man- agement Experiences & Systems (GRADES) and Network Data Analytics (NDA), 2022
work page 2022
-
[3]
Bridging graph data models: Rdf, rdf-star, and property graphs as directed acyclic graphs,
E. Gelling, G. Fletcher, and M. Schmidt, “Bridging graph data models: Rdf, rdf-star, and property graphs as directed acyclic graphs,” arXiv preprint arXiv:2304.13097, 2023
-
[4]
opencypher over rdf: Connecting two worlds,
M. Schmidt, B. Bebee, W. Broekema, M. Elzarei, C. M. L. En- riquez, M. Neyman, F. Schmedding, A. Steigmiller, B. Thomp- son, G. Varkey et al., “opencypher over rdf: Connecting two worlds,” 2024
work page 2024
-
[5]
Beyond iid: three levels of generalization for question answering on knowledge bases,
Y. Gu, S. Kase, M. Vanni, B. Sadler, P. Liang, X. Yan, and Y. Su, “Beyond iid: three levels of generalization for question answering on knowledge bases,” in Proceedings of the Web Conference, 2011
work page 2011
-
[6]
The value of semantic parse labeling for knowledge base question answering,
W.-t. Yih, M. Richardson, C. Meek, M.-W. Chang, and J. Suh, “The value of semantic parse labeling for knowledge base question answering,” in ACL, 2016
work page 2016
-
[7]
Graph databases: Neo4j analysis
J. Guia, V. G. Soares, and J. Bernardino, “Graph databases: Neo4j analysis. ” in ICEIS (1), 2017, pp. 351–356
work page 2017
-
[8]
Compositional semantic parsing with large language models,
A. Drozdov, N. Schärli, E. Akyürek, N. Scales, X. Song, X. Chen, O. Bousquet, and D. Zhou, “Compositional semantic parsing with large language models,” in ICLR, 2022
work page 2022
-
[9]
Flexkbqa: A flexible llm-powered framework for few-shot knowledge base question answering,
Z. Li, S. Fan, Y. Gu, X. Li, Z. Duan, B. Dong, N. Liu, and J. Wang, “Flexkbqa: A flexible llm-powered framework for few-shot knowledge base question answering,” 2024. [Online]. A vailable:https://arxiv.org/abs/2308.12060
-
[10]
arXiv preprint arXiv:2109.08678 , year=
X. Ye, S. Yavuz, K. Hashimoto, Y. Zhou, and C. Xiong, “Rng- kbqa: Generation augmented iterative ranking for knowledge base question answering,” arXiv preprint arXiv:2109.08678, 2021
-
[11]
Bring your own kg: Self-supervised program synthesis for zero-shot kgqa,
D. Agarwal, R. Das, S. Khosla, and R. Gangadharaiah, “Bring your own kg: Self-supervised program synthesis for zero-shot kgqa,” in NAACL, 2024
work page 2024
-
[12]
Don’t generate, discriminate: A proposal for grounding language models to real-world environ- ments,
Y. Gu, X. Deng, and Y. Su, “Don’t generate, discriminate: A proposal for grounding language models to real-world environ- ments,” in ACL, 2023
work page 2023
-
[13]
TIARA: multi-grained retrieval for robust question answering over large knowledge bases,
Y. Shu, Z. Yu, Y. Li, B. F. Karlsson, T. Ma, Y. Qu, and C.-Y. Lin, “Tiara: Multi-grained retrieval for robust question answering over large knowledge bases,” 2022. [Online]. A vailable:https://arxiv.org/abs/2210.12925
-
[14]
N. Shirvani-Mahdavi, F. Akrami, M. S. Saeef, X. Shi, and C. Li, “Comprehensive analysis of freebase and dataset creation for robust evaluation of knowledge graph link prediction models,” in International Semantic Web Conference. Springer, 2023, pp. 113–133
work page 2023
-
[15]
Sgpt: a generative approach for sparql query generation from natural language questions,
M. R. A. H. Rony, U. Kumar, R. Teucher, L. Kovriguina, and J. Lehmann, “Sgpt: a generative approach for sparql query generation from natural language questions,” IEEE Access, vol. 10, pp. 70 712–70 723, 2022
work page 2022
-
[16]
Code-style in- context learning for knowledge-based question answering,
Z. Nie, R. Zhang, Z. Wang, and X. Liu, “Code-style in- context learning for knowledge-based question answering,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 17, 2024, pp. 18 833–18 841
work page 2024
-
[17]
A comprehensive evaluation of neural sparql query generation from natural language questions,
P. A. K. K. Diallo, S. Reyd, and A. Zouaq, “A comprehensive evaluation of neural sparql query generation from natural language questions,” IEEE Access, 2024
work page 2024
-
[18]
L. Nie, S. Cao, J. Shi, J. Sun, Q. Tian, L. Hou, J. Li, and J. Zhai, “Graphq ir: Unifying the semantic parsing of graph query languages with one intermediate representation,” in EMNLP, 2022
work page 2022
-
[19]
Query reformulation with constraints,
A. Deutsch, L. Popa, and V. Tannen, “Query reformulation with constraints,” ACM SIGMOD Record, vol. 35, no. 1, pp. 65–73, 2006
work page 2006
-
[20]
Knowledge graph- augmented language models for complex question answering,
P. Sen, S. Mavadia, and A. Saffari, “Knowledge graph- augmented language models for complex question answering,” in Proceedings of the 1st Workshop on Natural Language Reasoning and Structured Explanations (NLRSE), 2023, pp. 1–8
work page 2023
-
[21]
D. Le, K. Zhao, M. Wang, and Y. Wu, “Graphlingo: Domain knowledge exploration by synchronizing knowledge graphs and large language models,” in ICDE, 2024
work page 2024
-
[22]
Graph chain-of-thought: Augmenting large language models by reasoning on graphs,
B. Jin, C. Xie, J. Zhang, K. K. Roy, Y. Zhang, Z. Li, R. Li, X. Tang, S. Wang, Y. Meng et al., “Graph chain-of-thought: Augmenting large language models by reasoning on graphs,” in ACL, 2024
work page 2024
-
[23]
Cypherbench: Towards precise retrieval over full-scale modern knowledge graphs in the llm era,
Y. Feng, S. Papicchio, and S. Rahman, “Cypherbench: Towards precise retrieval over full-scale modern knowledge graphs in the llm era,” arXiv preprint arXiv:2412.18702, 2024
-
[24]
Towards holistic entity linking: Survey and directions,
I. L. Oliveira, R. Fileto, R. Speck, L. P. Garcia, D. Moussallem, and J. Lehmann, “Towards holistic entity linking: Survey and directions,” Information Systems, vol. 95, p. 101624, 2021
work page 2021
-
[25]
A review on fact extraction and verification,
G. Bekoulis, C. Papagiannopoulou, and N. Deligiannis, “A review on fact extraction and verification,” CSUR, vol. 55, no. 1, pp. 1–35, 2021
work page 2021
-
[26]
Graph query generation with constraint- guided large language agents,
M. Wang, N. Jedema, R. Pandey, R. Krishnan, J. Lehmann, and Y. Wu, “Graph query generation with constraint- guided large language agents,” 2025. [Online]. A vailable: https://wangmengying.me/papers/uniqgen.pdf
work page 2025
-
[27]
Question answering over knowledge graphs: question understanding via template decomposition,
W. Zheng, J. X. Yu, L. Zou, and H. Cheng, “Question answering over knowledge graphs: question understanding via template decomposition,” Proceedings of the VLDB Endowment, vol. 11, no. 11, pp. 1373–1386, 2018
work page 2018
-
[28]
On generating characteristic-rich question sets for QA evaluation,
Y. Su, H. Sun, B. Sadler, M. Srivatsa, I. Gür, Z. Yan, and X. Yan, “On generating characteristic-rich question sets for QA evaluation,” in EMNLP, 2016
work page 2016
-
[29]
Y. Gu and Y. Su, “Arcaneqa: Dynamic program induction and contextualized encoding for knowledge base question answer- ing,” in Proceedings of the 29th International Conference on Computational Linguistics, 2022, pp. 1718–1731
work page 2022
-
[30]
Pangu github issue: Compute resources
Pangu, “Pangu github issue: Compute resources. ” 2025. [Online]. A vailable:https://github.com/dki-lab/Pangu/issues/6
work page 2025
-
[31]
Case-based reasoning for natural language queries over knowledge bases,
R. Das, M. Zaheer, D. Thai, A. Godbole, E. Perez, J.-Y. Lee, L. Tan, L. Polymenakos, and A. Mccallum, “Case-based reasoning for natural language queries over knowledge bases,” in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021, pp. 9594–9611
work page 2021
-
[32]
Query graph generation for answering multi-hop complex questions from knowledge bases
Y. Lan and J. Jiang, “Query graph generation for answering multi-hop complex questions from knowledge bases. ” Associa- tion for Computational Linguistics, 2020
work page 2020
-
[33]
Rng- kbqa: Generation augmented iterative ranking for knowledge base question answering,
X. Ye, S. Yavuz, K. Hashimoto, Y. Zhou, and C. Xiong, “Rng- kbqa: Generation augmented iterative ranking for knowledge base question answering,” in Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: Long papers), 2022, pp. 6032–6043
work page 2022
-
[34]
G. He, Y. Lan, J. Jiang, W. X. Zhao, and J.-R. Wen, “Improv- ing multi-hop knowledge base question answering by learning intermediate supervision signals,” in Proceedings of the 14th ACM international conference on web search and data mining, 2021, pp. 553–561
work page 2021
-
[35]
J. Jiang, K. Zhou, X. Zhao, and J.-R. Wen, “Unikgqa: Unified retrieval and reasoning for solving multi-hop question answering over knowledge graph,” in The Eleventh International Confer- ence on Learning Representations
-
[36]
Structgpt: A general framework for large language model to reason over structured data,
J. Jiang, K. Zhou, Z. Dong, K. Ye, W. X. Zhao, and J.- R. Wen, “Structgpt: A general framework for large language model to reason over structured data,” in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 9237–9251
work page 2023
-
[37]
Reasoning on graphs: Faithful and interpretable large language model reasoning,
L. LUO, Y.-F. Li, G. Haffari, and S. Pan, “Reasoning on graphs: Faithful and interpretable large language model reasoning,” in The Twelfth International Conference on Learning Representa- tions
-
[38]
X. He, Y. Tian, Y. Sun, N. Chawla, T. Laurent, Y. LeCun, X. Bresson, and B. Hooi, “G-retriever: Retrieval-augmented generation for textual graph understanding and question an- swering,” Advances in Neural Information Processing Systems, vol. 37, pp. 132 876–132 907, 2024. Appendix I: Glossary of Key Notations * The examples related to the Olympic Games ar...
work page 2024
-
[39]
Please only output the table in markdown format, no other context
-
[40]
Double-check that all essential properties for connecting entities are included; don’t omit them. ... Input: {NL Query}, {Extracted Entities}, {Factual Constraints} Output: {constraint table} B. Query Generator Given a natural language query, extracted entities, and a list of constraints, generate a Cypher query that uses all provided constraints without ...
-
[41]
For node IDs, use the format: (‘ id‘: ”<url>”)
-
[42]
For properties/at- tributes, use the format m
For constrains/relationships(predicates that connect two nodes) use the format: [:‘<url>‘] 3. For properties/at- tributes, use the format m. ‘<url>‘ ... Requirements:
-
[43]
Incorporates all given constraints exactly as provided
-
[44]
Uses the known entities appropriately
-
[45]
Does not introduce any additional constraints
-
[46]
Input: {NL Query}, {Extracted Entities}, {Constraints} Output: {Cypher query} C
Includes necessary operators or query modifiers to answer the NL query ... Input: {NL Query}, {Extracted Entities}, {Constraints} Output: {Cypher query} C. Evaluator You are an expert system for evaluating answers to knowledge graph queries. Your task is to score a list of potential answers to a given natural language query. Also, output a reference answe...
-
[47]
Consider the relevance and accuracy of each answer in relation to the query
-
[48]
Assign a score from 0 to 20 for each answer, where: * 0 means completely irrelevant or incorrect * 20 means highly relevant and likely correct * Use the full range of scores to differentiate between answers
-
[49]
For empty or null answers, assign a score of 0
-
[50]
If multiple answers are identical, give them the same score
-
[51]
Consider both the content and the format of the answer. ... Input format: {Natural language query} {List of answers} Output: {Reference Answer Set} {List of scores} D. Prompt variance of the oracle reference set A UniQGen uses an LLM oracle to obtain a reference answer set A for an NL query, which guides the Chase/Backchase loop. P0: Minimal answer-only p...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.