GraphSculptor: Sculpting Pre-training Coreset for Graph Self-supervised Learning
Pith reviewed 2026-05-09 14:32 UTC · model grok-4.3
The pith
A 10% coreset of graphs retains 99.6% of full pre-training performance for graph self-supervised learning while cutting training time by nearly 90%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
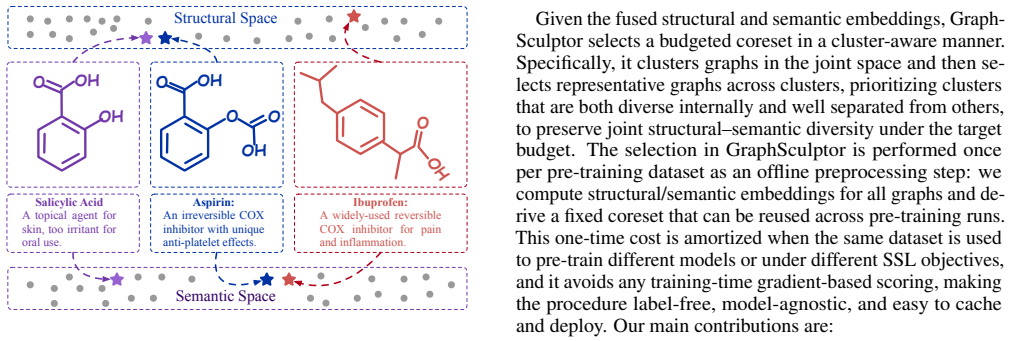
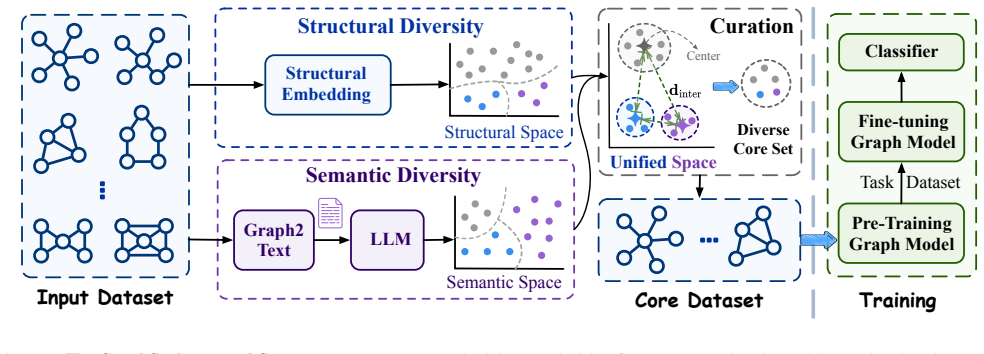
GraphSculptor constructs pre-training coresets by quantifying structural diversity with intrinsic graph statistics to form feature vectors and semantic diversity by encoding graph-to-text descriptions with a pre-trained language model. These signals are fused into a unified metric space where cluster-aware selection preserves joint structural-semantic diversity. The method supplies a label-free solution and derives a theoretical bound on the loss gap to full-data pre-training, with experiments showing that a 10% coreset reaches 99.6% of full performance and reduces pre-training time by nearly 90%.
What carries the argument
GraphSculptor, a label-free coreset builder that fuses structural feature vectors from graph statistics with semantic encodings from language models on graph-to-text descriptions, then applies cluster-aware selection in the combined space.
Load-bearing premise
That preserving joint structural-semantic diversity via cluster-aware selection on graph statistics and language-model graph-to-text encodings is sufficient to maintain pre-training effectiveness for downstream tasks without labels.
What would settle it
Selecting a 10% coreset with GraphSculptor on a fresh large graph dataset and measuring downstream performance below 95% of the full-data baseline after identical pre-training would falsify the effectiveness claim.
Figures

read the original abstract
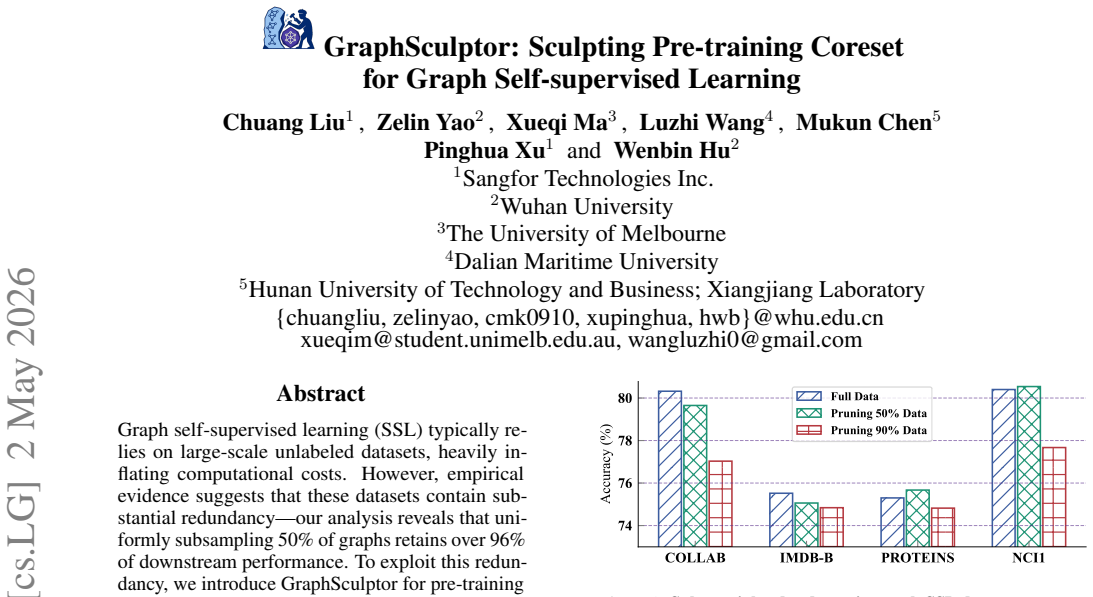
Graph self-supervised learning typically relies on large-scale unlabeled datasets, heavily inflating computational costs. However, empirical evidence suggests that these datasets contain substantial redundancy-our analysis reveals that uniformly subsampling 50% of graphs retains over 96% of downstream performance. To exploit this redundancy, we introduce GraphSculptor for pre-training coreset construction. Unlike methods dependent on additional training-time signals or limited solely to topological statistics, GraphSculptor provides a label-free solution that constructs coresets via two complementary perspectives: intrinsic structure and contextual semantics. Concretely, structural diversity is quantified using intrinsic graph statistics, yielding a structural feature vector for each graph, while semantic diversity is captured by utilizing a pre-trained language model to encode descriptions generated via graph-to-text. GraphSculptor integrates these signals into a unified metric space and performs cluster-aware selection to preserve joint structural-semantic diversity. We further derive a theoretical bound on the loss gap between coreset and full-data pre-training, offering theoretical motivation for our selection formulation. Extensive experiments demonstrate that GraphSculptor effectively sculpts the dataset: a 10% coreset achieves 99.6% of full-data performance while reducing pre-training time by nearly 90%, offering a scalable solution for data-efficient graph pre-training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce GraphSculptor, a label-free method for pre-training coreset construction in graph self-supervised learning. It quantifies structural diversity using intrinsic graph statistics and semantic diversity using pre-trained language models on graph-to-text descriptions, then performs cluster-aware selection in a unified metric space. A theoretical bound on the loss gap is derived, and experiments show that a 10% coreset retains 99.6% of full-data downstream performance while cutting pre-training time by nearly 90%.
Significance. If the results hold, this work is significant for providing a scalable solution to the high computational costs of graph SSL by exploiting redundancy in unlabeled data. The combination of empirical performance gains and a theoretical loss-gap bound offers both practical utility and theoretical insight into data-efficient pre-training.
major comments (3)
- [§4 (Theoretical Analysis)] §4 (Theoretical Analysis): the derived bound on the loss gap between coreset and full-data pre-training relies on the assumption that the unified structural-semantic metric space correlates with the SSL objective (contrastive/generative losses on augmentations); no analysis or empirical correlation is shown between the chosen graph statistics/LM encodings and augmentation-sensitive substructures that dominate the loss, which is load-bearing for the bound to support the downstream fidelity claim.
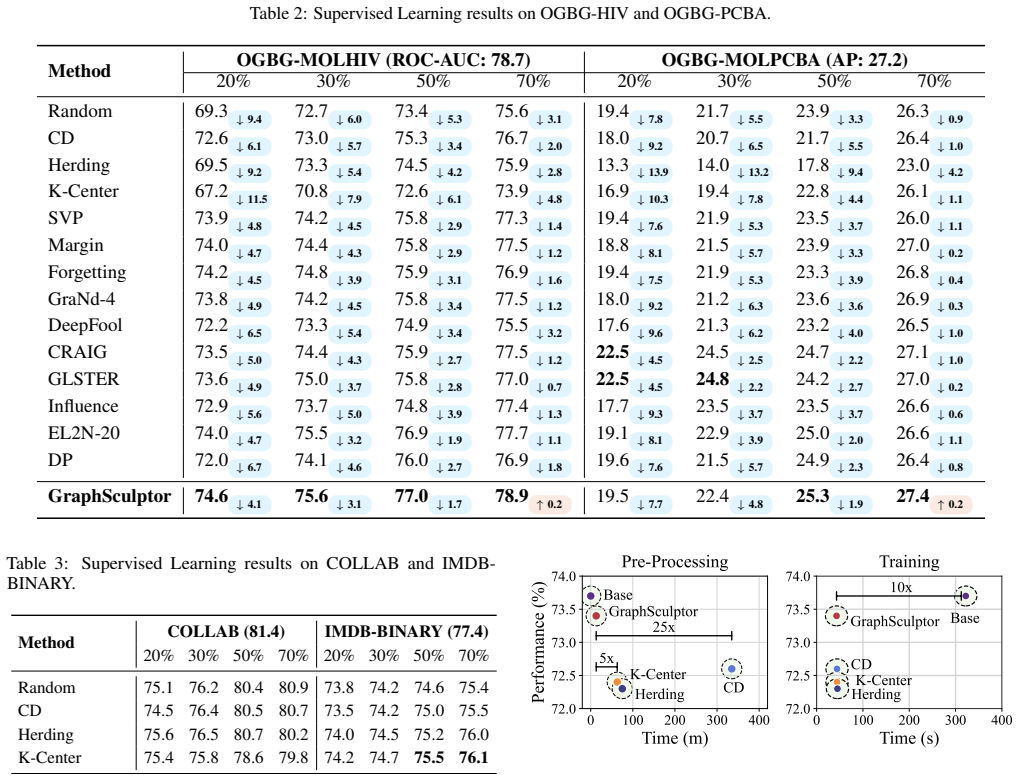
- [§5 (Experiments)] §5 (Experiments): the 10% coreset achieving 99.6% performance is the central empirical claim, but the setup reports only aggregate results without ablations isolating structural vs. semantic contributions or direct comparison to 10% uniform random sampling (beyond the 50% uniform result of 96%); this leaves open whether the cluster-aware selection on the specific features is necessary or if the bound holds only for the chosen metric.
- [§3.3 (Cluster-aware Selection)] §3.3 (Cluster-aware Selection): the integration into a unified metric space for preserving joint diversity is presented as sufficient for maintaining pre-training effectiveness, but without validation that these features capture motifs relevant to the SSL loss landscape (as opposed to general diversity), the selection may not guarantee the observed performance even if the bound is mathematically correct.
minor comments (2)
- [Abstract] Abstract: the time reduction is stated as 'nearly 90%'; report the precise measured reduction (with standard deviation if applicable) in the main experimental table for reproducibility.
- [Notation] Notation throughout: ensure the structural feature vector and semantic embedding are denoted consistently when combined into the unified metric (e.g., avoid switching between f_s and e_sem without explicit definition).
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important aspects of the theoretical motivation, experimental validation, and feature relevance that we will address in the revision to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4 (Theoretical Analysis)] the derived bound on the loss gap between coreset and full-data pre-training relies on the assumption that the unified structural-semantic metric space correlates with the SSL objective (contrastive/generative losses on augmentations); no analysis or empirical correlation is shown between the chosen graph statistics/LM encodings and augmentation-sensitive substructures that dominate the loss, which is load-bearing for the bound to support the downstream fidelity claim.
Authors: We agree that the bound in §4 is derived under the assumption that the unified metric serves as a proxy for the SSL objective. The mathematical derivation holds under this premise to motivate the selection. To strengthen the connection to empirical results, we will add an empirical analysis in the revised manuscript that computes correlations between the structural-semantic features and the actual contrastive/generative losses on augmentations for selected graphs versus the full set. This will provide direct support for the assumption without changing the bound itself. revision: yes
-
Referee: [§5 (Experiments)] the 10% coreset achieving 99.6% performance is the central empirical claim, but the setup reports only aggregate results without ablations isolating structural vs. semantic contributions or direct comparison to 10% uniform random sampling (beyond the 50% uniform result of 96%); this leaves open whether the cluster-aware selection on the specific features is necessary or if the bound holds only for the chosen metric.
Authors: We thank the referee for this suggestion. The 50% uniform result was included to illustrate data redundancy, but we acknowledge that a 10% random baseline and component-wise ablations are needed for completeness. In the revised version, we will add (i) direct comparison of GraphSculptor at 10% against 10% uniform random sampling across all datasets and (ii) ablations that separately evaluate structural-only, semantic-only, and combined selection. These will clarify the contribution of the unified metric and cluster-aware approach. revision: yes
-
Referee: [§3.3 (Cluster-aware Selection)] the integration into a unified metric space for preserving joint diversity is presented as sufficient for maintaining pre-training effectiveness, but without validation that these features capture motifs relevant to the SSL loss landscape (as opposed to general diversity), the selection may not guarantee the observed performance even if the bound is mathematically correct.
Authors: The structural statistics (e.g., degree, clustering) and LM-encoded semantics were selected because they capture properties preserved under typical graph augmentations used in SSL. We recognize that explicit validation linking them to loss-relevant motifs would be beneficial. We will revise §3.3 to include a discussion of this alignment and add a targeted analysis (e.g., motif preservation statistics on selected coresets) to demonstrate relevance to the SSL objective, thereby supporting the effectiveness of the selection. revision: partial
Circularity Check
No circularity: independent features and externally motivated bound
full rationale
The coreset construction relies on intrinsic graph statistics and pre-trained LM encodings of graph-to-text descriptions, both computed without reference to the SSL pre-training loss or downstream labels. The derived theoretical bound on the loss gap is presented as external motivation for the cluster-aware selection rule rather than being tautological with the selection itself. No self-citations appear load-bearing, no parameters are fitted to target performance and then renamed as predictions, and the 50% uniform subsample observation is used only as empirical motivation for redundancy, not as a fitted input. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption Intrinsic graph statistics sufficiently quantify structural diversity relevant for self-supervised learning
- domain assumption Graph-to-text conversion followed by language model encoding captures semantic diversity
- domain assumption Cluster-aware selection in the unified metric space preserves the necessary diversity for effective pre-training
Reference graph
Works this paper leans on
-
[1]
SciBERT: A pretrained language model for scientific text
[Beltagyet al., 2019 ] Iz Beltagy, Kyle Lo, and Arman Cohan. SciBERT: A pretrained language model for scientific text. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors,Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th Inter- national Joint Conference on Natural Language Processing (EMNLP-IJCNLP),
work page 2019
-
[2]
Beyond efficiency: Molecular data pruning for enhanced generalization
[Chenet al., 2024 ] Dingshuo Chen, Zhixun Li, Yuyan Ni, Guibin Zhang, Ding Wang, Qiang Liu, Shu Wu, Jeffrey Xu Yu, and Liang Wang. Beyond efficiency: Molecular data pruning for enhanced generalization. InThe Thirty-eighth Annual Conference on Neural Information Processing Sys- tems,
work page 2024
-
[3]
Bert: Pre-training of deep bidirectional transformers for language understanding
[Devlinet al., 2019 ] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In Assoc. Comput. Linguistics,
work page 2019
-
[4]
Mirage: Model-agnostic graph distillation for graph classification
[Guptaet al., 2024 ] Mridul Gupta, Sahil Manchanda, HARIPRASAD KODAMANA, and Sayan Ranu. Mirage: Model-agnostic graph distillation for graph classification. InThe Twelfth International Conference on Learning Representations,
work page 2024
-
[5]
Graphmae: Self-supervised masked graph autoencoders
[Houet al., 2022 ] Zhenyu Hou, Xiao Liu, Yukuo Cen, Yux- iao Dong, Hongxia Yang, Chunjie Wang, and Jie Tang. Graphmae: Self-supervised masked graph autoencoders. In Proc. 28th ACM SIGKDD Conf. Knowl. Discovery Data Mining,
work page 2022
-
[6]
Graphmae2: A decoding-enhanced masked self-supervised graph learner
[Houet al., 2023 ] Zhenyu Hou, Yufei He, Yukuo Cen, Xiao Liu, Yuxiao Dong, Evgeny Kharlamov, and Jie Tang. Graphmae2: A decoding-enhanced masked self-supervised graph learner. InProc. ACM Web Conf. 2023,
work page 2023
-
[7]
arXiv preprint arXiv:2005.00687 , year=
[Huet al., 2020 ] Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs.arXiv:2005.00687,
-
[8]
What’s behind the mask: Understanding masked graph modeling for graph autoen- coders
[Liet al., 2023 ] Jintang Li, Ruofan Wu, Wangbin Sun, Liang Chen, Sheng Tian, Liang Zhu, Changhua Meng, Zibin Zheng, and Weiqiang Wang. What’s behind the mask: Understanding masked graph modeling for graph autoen- coders. InProc. 29th ACM SIGKDD Conf. Knowl. Discov- ery Data Mining,
work page 2023
-
[9]
Model-free graph data selection under distribution shift,
[Liet al., 2025 ] Ting-Wei Li, Ruizhong Qiu, and Hanghang Tong. Model-free graph data selection under distribution shift,
work page 2025
-
[10]
Rethinking tokenizer and decoder in masked graph mod- eling for molecules
[Liuet al., 2023 ] Zhiyuan Liu, Yaorui Shi, An Zhang, Enzhi Zhang, Kenji Kawaguchi, Xiang Wang, and Tat-Seng Chua. Rethinking tokenizer and decoder in masked graph mod- eling for molecules. InThirty-seventh Conf. Neural Inf. Process. Syst.,
work page 2023
-
[11]
Where to mask: Structure-guided masking for graph masked autoen- coders
[Liuet al., 2024 ] Chuang Liu, Yuyao Wang, Yibing Zhan, Xueqi Ma, Dapeng Tao, Jia Wu, and Wenbin Hu. Where to mask: Structure-guided masking for graph masked autoen- coders. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24, pages 2180–2188. International Joint Conferences on Artificial Intelligence Orga...
work page 2024
-
[12]
Graph positional autoen- coders as self-supervised learners
[Liuet al., 2025 ] Yang Liu, Deyu Bo, Wenxuan Cao, Yuan Fang, Yawen Li, and Chuan Shi. Graph positional autoen- coders as self-supervised learners. InSIGKDD,
work page 2025
-
[13]
Hi-gmae: Hierarchical graph masked autoencoders
[Liuet al., 2026 ] Chuang Liu, Zelin Yao, Xueqi Ma, Mukun Chen, Luzhi Wang, Jia Wu, and Wenbin Hu. Hi-gmae: Hierarchical graph masked autoencoders. InProceedings of the ACM Web Conference 2026, page 1250–1261,
work page 2026
-
[14]
Kriege, Franka Bause, Kristian Kersting, Petra Mutzel, and Marion Neumann
[Morriset al., 2020 ] Christopher Morris, Nils M. Kriege, Franka Bause, Kristian Kersting, Petra Mutzel, and Marion Neumann. Tudataset: A collection of benchmark datasets for learning with graphs. InICML 2020 Workshop Graph Representation Learn. Beyond (GRL+ 2020),
work page 2020
-
[15]
[Peiet al., 2023 ] Qizhi Pei, Wei Zhang, Jinhua Zhu, Kehan Wu, Kaiyuan Gao, Lijun Wu, Yingce Xia, and Rui Yan. Biot5: Enriching cross-modal integration in biology with chemical knowledge and natural language associations. In Proceedings of the 2023 Conference on Empirical Meth- ods in Natural Language Processing, pages 1102–1123, December
work page 2023
-
[16]
Recipe for a general, powerful, scalable graph transformer
[Rampaseket al., 2022 ] Ladislav Rampasek, Mikhail Galkin, Vijay Prakash Dwivedi, Anh Tuan Luu, Guy Wolf, and Dominique Beaini. Recipe for a general, powerful, scalable graph transformer. InConf. Workshop Neural Inf. Process. Syst.,
work page 2022
-
[17]
[Shenet al., 2025 ] Weixuan Shen, Xiaobo Shen, and Shirui Pan. Adversarial contrastive graph masked autoencoder against graph structure and feature dual attacks.Proceed- ings of the AAAI Conference on Artificial Intelligence,
work page 2025
-
[18]
Gigamae: Generalizable graph masked autoencoder via collaborative latent space reconstruction
[Shiet al., 2023 ] Yucheng Shi, Yushun Dong, Qiaoyu Tan, Jundong Li, and Ninghao Liu. Gigamae: Generalizable graph masked autoencoder via collaborative latent space reconstruction. InProc. 32nd ACM Int. Conf. Inf. Knowl. Manage.,
work page 2023
-
[19]
Zinc 15–ligand discovery for everyone.J
[Sterling and Irwin, 2015] Teague Sterling and John J Irwin. Zinc 15–ligand discovery for everyone.J. Chem. Inf. Model.,
work page 2015
-
[20]
S2gae: Self-supervised graph autoencoders are generalizable learn- ers with graph masking
[Tanet al., 2023 ] Qiaoyu Tan, Ninghao Liu, Xiao Huang, Soo-Hyun Choi, Li Li, Rui Chen, and Xia Hu. S2gae: Self-supervised graph autoencoders are generalizable learn- ers with graph masking. InProc. Sixteenth ACM Int. Conf. Web Search Data Mining,
work page 2023
-
[21]
Rethinking graph masked autoencoders through alignment and uniformity
[Wanget al., 2024 ] Liang Wang, Xiang Tao, Qiang Liu, and Shu Wu. Rethinking graph masked autoencoders through alignment and uniformity. InProc. AAAI Conf. Artif. Intell.,
work page 2024
-
[22]
Feinberg, Joseph Gomes, Caleb Geniesse, Aneesh S
[Wuet al., 2018 ] Zhenqin Wu, Bharath Ramsundar, Evan N. Feinberg, Joseph Gomes, Caleb Geniesse, Aneesh S. Pappu, Karl Leswing, and Vijay Pande. Moleculenet: a benchmark for molecular machine learning.Chem. Sci.,
work page 2018
-
[23]
[Xiaet al., 2022a ] Jun Xia, Lirong Wu, Jintao Chen, Bozhen Hu, and Stan Z. Li. Simgrace: A simple framework for graph contrastive learning without data augmentation. In Proc. ACM Web Conf. 2022,
work page 2022
-
[24]
A survey of pretraining on graphs: Taxonomy, methods, and applications.arXiv:2202.07893,
[Xiaet al., 2022b ] Jun Xia, Yanqiao Zhu, Yuanqi Du, and Stan Z Li. A survey of pretraining on graphs: Taxonomy, methods, and applications.arXiv:2202.07893,
-
[25]
[Yanget al., 2023 ] Beining Yang, Kai Wang, Qingyun Sun, Cheng Ji, Xingcheng Fu, Hao Tang, Yang You, and Jianxin Li. Does graph distillation see like vision dataset counter- part? InThirty-seventh Conference on Neural Information Processing Systems,
work page 2023
-
[26]
Do transformers really perform badly for graph representation? InConf
[Yinget al., 2021 ] Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, and Tie-Yan Liu. Do transformers really perform badly for graph representation? InConf. Workshop Neural Inf. Process. Syst.,
work page 2021
-
[27]
Graph con- trastive learning with augmentations
[Youet al., 2020 ] Yuning You, Tianlong Chen, Yongduo Sui, Ting Chen, Zhangyang Wang, and Yang Shen. Graph con- trastive learning with augmentations. InAdvances Neural Inf. Process. Syst., volume 33, pages 5812–5823,
work page 2020
-
[28]
GDer: Safeguarding efficiency, balancing, and robustness via pro- totypical graph pruning
[Zhanget al., 2024 ] Guibin Zhang, Haonan Dong, Yuchen Zhang, Zhixun Li, Dingshuo Chen, Kai Wang, Tianlong Chen, Yuxuan Liang, Dawei Cheng, and Kun Wang. GDer: Safeguarding efficiency, balancing, and robustness via pro- totypical graph pruning. InThe Thirty-eighth Annual Con- ference on Neural Information Processing Systems,
work page 2024
-
[29]
Protom- gae: Prototype-aware masked graph auto-encoder for graph representation learning.ACM Trans
[Zheng and Jia, 2024] Yimei Zheng and Caiyan Jia. Protom- gae: Prototype-aware masked graph auto-encoder for graph representation learning.ACM Trans. Knowl. Discovery Data, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.