Research on Vision-Language Question Answering Models for Industrial Robots
Pith reviewed 2026-05-09 14:32 UTC · model grok-4.3
The pith
A hierarchical cross-modal fusion model improves vision-language question answering for industrial robots by uniting visual features and language parsing in a shared reasoning space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By combining region-based deep networks for visual features, weighted embeddings, recurrent neural parsing of sentence structure, and adaptive fusion with cross-attention, the hierarchical model creates a joint reasoning space that processes operational queries, step-by-step instructions, and anomaly detection more dependably than prior VLQA approaches.
What carries the argument
Hierarchical cross-modal fusion via adaptive fusion and cross-attention mechanisms that align multi-scale visual regions with parsed language structures into one reasoning space.
If this is right
- Higher Top-1 accuracy and semantic alignment when robots answer questions about their immediate surroundings.
- Improved robustness when queries involve multiple steps or vague phrasing typical in manufacturing.
- Each architectural module contributes measurably, as shown by ablation results that isolate the effect of multi-level integration.
- Greater operational effectiveness and interpretability for human-robot tasks in diverse industrial settings.
Where Pith is reading between the lines
- The design could support more natural language interfaces on factory floors, cutting down on the need for rigidly scripted commands.
- Similar fusion patterns might transfer to logistics or assembly robots facing changing environments.
- Real-time deployment would require checking whether the added modules keep latency low enough for live robot control.
Load-bearing premise
Combining object detection, multi-scale visual encoding, syntactic parsing, and task-aware semantic attention will deliver consistent gains in real industrial environments without overfitting to the test benchmarks.
What would settle it
Running the model on fresh factory robot interaction data containing previously unseen ambiguous or procedural queries would produce no measurable lift in semantic alignment or accuracy over existing vision-language baselines.
Figures

read the original abstract
A hierarchical cross-modal fusion model is proposed for vision-language question answering (VLQA) in industrial robotics, targeting the challenges of semantic ambiguity, complex environmental layouts, and domain-specific terminology common in modern manufacturing. The framework integrates advanced object detection, multi-scale visual encoding, syntactic parsing, and task-aware semantic attention to unite vision and language signals into a joint reasoning space. Region-based deep networks extract visual features, weighted embeddings aggregate, and recurrent neural parsing encodes sentence structures. Through fine-grained semantic alignment driven by adaptive fusion and cross-attention mechanisms, the system can handle operational queries, instruction steps, and anomaly detection with higher reliability. Compared to the existing VLQA benchmarks, validation experiments conducted on the IVQA and RIF benchmarks indicate improvements in semantic alignment, Top-1 accuracy, and robustness to ambiguous or procedural task queries. Ablation studies further quantify the impact of each architectural module, confirming the necessity of multi-level feature integration and context-driven gating for dependable industrial deployment. The technical advancements reported here provide core methodologies to improve the interpretability and operational effectiveness of industrial robots faced with diverse human-robot interaction tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hierarchical cross-modal fusion model for vision-language question answering in industrial robotics. It integrates object detection, multi-scale visual encoding, syntactic parsing, and task-aware semantic attention to address semantic ambiguity, complex layouts, and domain-specific terminology. The model uses region-based networks for visual features, weighted embeddings, recurrent parsing for sentences, and adaptive fusion with cross-attention for joint reasoning. Validation on the IVQA and RIF benchmarks is reported to show gains in semantic alignment, Top-1 accuracy, and robustness to ambiguous or procedural queries, with ablation studies confirming the value of multi-level integration.
Significance. If the empirical claims hold under rigorous scrutiny, the work could offer practical advances in VLQA for manufacturing robots by improving reliability in human-robot interaction tasks. The modular architecture targeting industrial challenges is a plausible direction, and explicit ablation analysis is a positive step toward interpretability. However, the absence of detailed quantitative results, baselines, and statistical validation substantially reduces the assessed significance at present.
major comments (3)
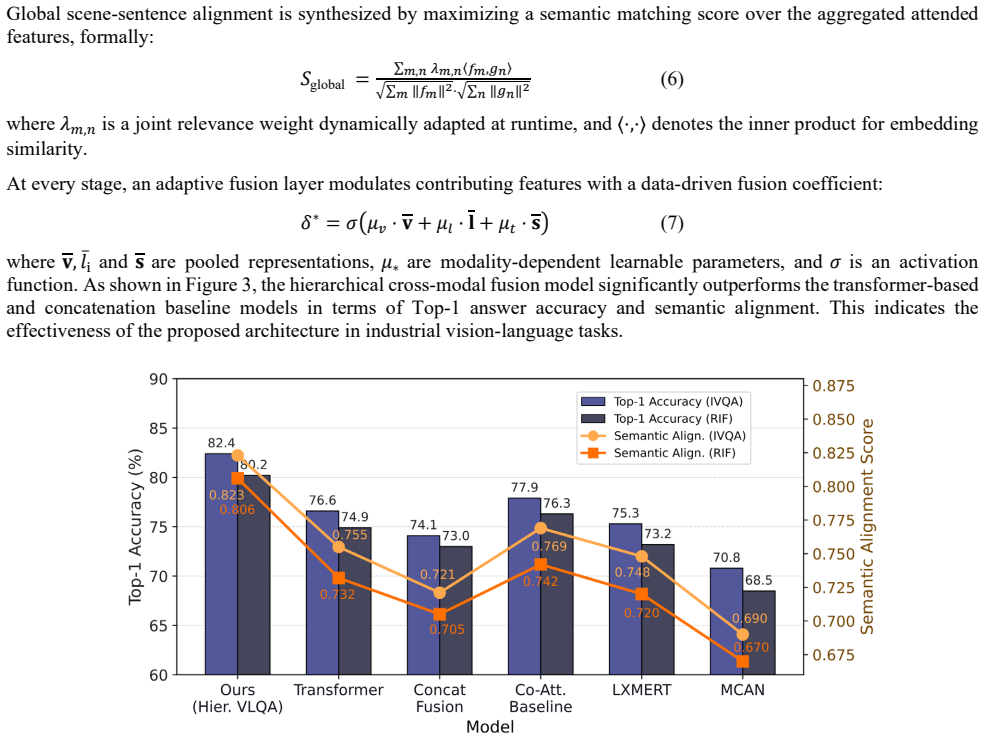
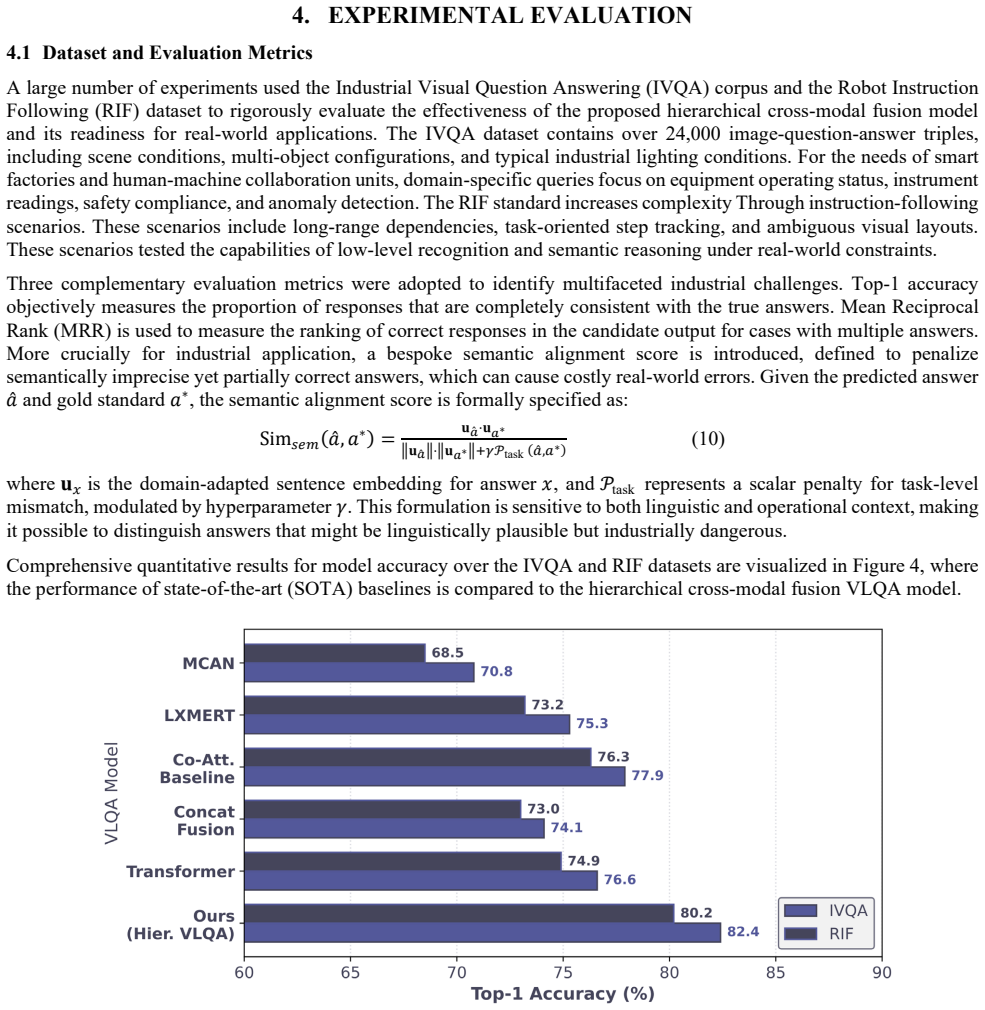
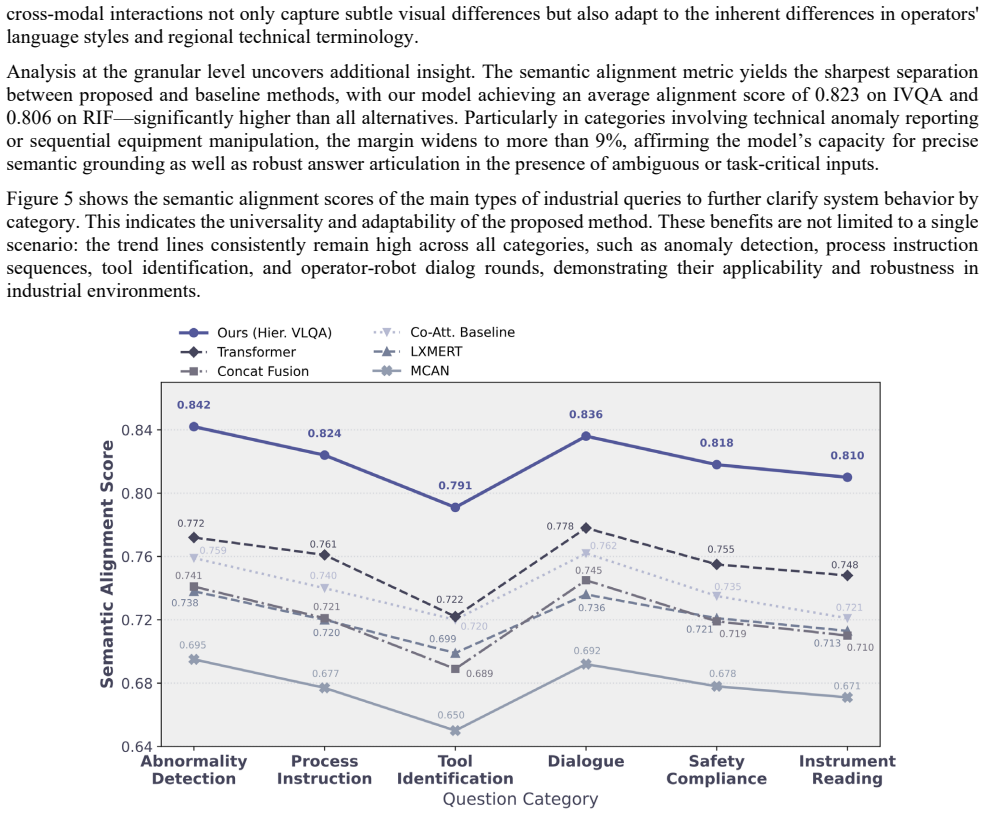
- [Experimental Validation] Experimental section: The manuscript asserts improvements in semantic alignment, Top-1 accuracy, and robustness on IVQA and RIF benchmarks but supplies no numerical deltas, baseline models, error bars, statistical tests, or data exclusion criteria. This directly undermines verification of the central claim that the full hierarchical fusion architecture is necessary and superior.
- [Ablation Studies] Ablation studies: The text states that ablations quantify the impact of each module (object detection, multi-scale encoding, syntactic parsing, task-aware attention) and confirm necessity of multi-level integration, yet no performance tables, drop magnitudes, or controls for hidden adaptations are provided. Without these, the load-bearing assertion that context-driven gating is required for industrial deployment cannot be evaluated.
- [Validation Experiments] Benchmark suitability: Claims of robustness to ambiguous or procedural task queries rest on IVQA and RIF, but no analysis of domain shift (novel layouts, terminology, or out-of-distribution procedural queries) or comparison to real industrial variability is given. This leaves open whether gains generalize beyond the chosen benchmarks.
minor comments (2)
- [Abstract] The abstract and introduction use vague phrasing such as 'higher reliability' and 'improvements' without anchoring to specific metrics or prior work; adding concrete references to existing VLQA models would improve clarity.
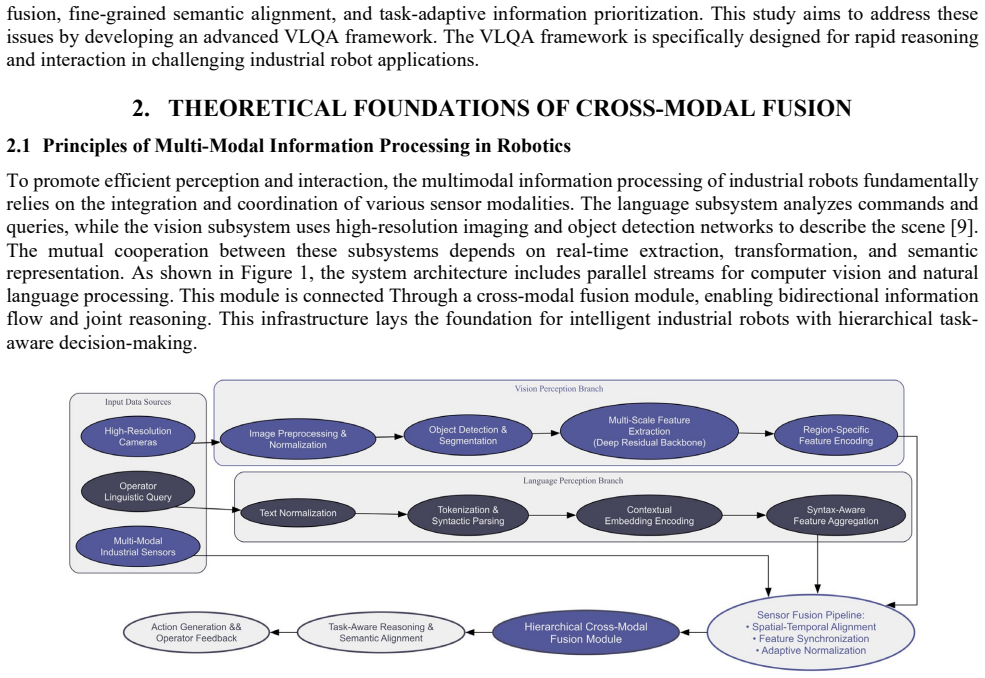
- [Model Description] Notation for components (e.g., region-based deep networks, weighted embeddings, recurrent neural parsing) is introduced without equations or diagrams in the provided text, making the fusion mechanism hard to follow precisely.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. We agree that the experimental section requires substantial strengthening with quantitative details, and we will revise the manuscript to address all points raised.
read point-by-point responses
-
Referee: Experimental section: The manuscript asserts improvements in semantic alignment, Top-1 accuracy, and robustness on IVQA and RIF benchmarks but supplies no numerical deltas, baseline models, error bars, statistical tests, or data exclusion criteria. This directly undermines verification of the central claim that the full hierarchical fusion architecture is necessary and superior.
Authors: We acknowledge that the current version lacks the specific numerical evidence needed for rigorous verification. In the revised manuscript, we will expand the experimental section with detailed performance tables reporting exact Top-1 accuracy, semantic alignment scores, and robustness metrics on IVQA and RIF, including deltas relative to standard baselines (e.g., vanilla VQA models and prior cross-modal fusion approaches). Multiple-run error bars, statistical significance tests (paired t-tests with p-values), and explicit data exclusion criteria will be added to support the claims. revision: yes
-
Referee: Ablation studies: The text states that ablations quantify the impact of each module (object detection, multi-scale encoding, syntactic parsing, task-aware attention) and confirm necessity of multi-level integration, yet no performance tables, drop magnitudes, or controls for hidden adaptations are provided. Without these, the load-bearing assertion that context-driven gating is required for industrial deployment cannot be evaluated.
Authors: We agree that explicit ablation results are essential. The revision will include comprehensive ablation tables showing accuracy drops when ablating each module individually and in combination, with precise drop magnitudes. We will also describe experimental controls (e.g., fixed hyperparameters and no compensatory retraining) to rule out hidden adaptations, thereby substantiating the necessity of multi-level integration and context-driven gating. revision: yes
-
Referee: Benchmark suitability: Claims of robustness to ambiguous or procedural task queries rest on IVQA and RIF, but no analysis of domain shift (novel layouts, terminology, or out-of-distribution procedural queries) or comparison to real industrial variability is given. This leaves open whether gains generalize beyond the chosen benchmarks.
Authors: We will add a dedicated analysis subsection on generalization. This will include targeted evaluations on benchmark subsets with introduced novel layouts, domain-specific terminology variations, and out-of-distribution procedural queries to quantify domain shift effects. A discussion of limitations regarding real-world industrial variability (e.g., sensor noise, dynamic environments) will be included, while noting that IVQA and RIF remain the most appropriate public benchmarks for this domain. revision: yes
Circularity Check
No circularity; empirical claims rest on benchmark validation without derivations or self-referential reductions
full rationale
The manuscript describes a hierarchical cross-modal fusion architecture for VLQA in industrial robotics, combining object detection, multi-scale visual encoding, syntactic parsing, and task-aware semantic attention. All performance claims (improvements in semantic alignment, Top-1 accuracy, robustness) are presented as outcomes of validation experiments on the IVQA and RIF benchmarks plus ablation studies. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described content. The derivation chain is therefore self-contained as standard empirical ML reporting rather than any tautological reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cross-attention and multi-scale encoding reliably align vision and language modalities in domain-specific settings.
Reference graph
Works this paper leans on
- [2]
-
[3]
Wang, T., Zheng, P., Li, S., & Wang, L. (2024). Multimodal human –robot interaction for human‐centric smart manufacturing: a survey. Advanced Intelligent Systems, 6(3), 2300359
work page 2024
-
[4]
Qian, X., Wang, Z., Wang, J., Guan, G., & Li, H. (2022). Audio-visual cross-attention network for robotic speaker tracking. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31, 550-562
work page 2022
-
[5]
Picard, C., Edwards, K. M., Doris, A. C., Man, B., Giannone, G., Alam, M. F., & Ahmed, F. (2025). From concept to manufacturing: Evaluating vision- language models for engineering design. Artificial Intelligence Review, 58(9), 288
work page 2025
-
[6]
Asiel, M. (2025). Vision language Models of General Purpose Robot Control. ComputeX-Journal of Emerging Technology & Applied Science, 1(2), 01-08
work page 2025
-
[7]
Miao, R., Jia, Q., Sun, F., Chen, G., & Huang, H. (2024, January). Hierarchical understanding in robotic manipulation: A knowledge-based framework. In Actuators (Vol. 13, No. 1, p. 28). MDPI
work page 2024
-
[8]
Wang, T., Li, J., Kong, Z., Liu, X., Snoussi, H., & Lv, H. (2021). Digital twin improved via visual question answering for vision -language interactive mode in human –machine collaboration. Journal of Manufacturing Systems, 58, 261-269
work page 2021
-
[9]
Dong, M., Bai, Y., & Yu, X. (2025). A single multi -task deep neural network with a multi -scale feature aggregation mechanism for manipulation relationship reasoning in robotic grasping: M. Dong, Y. Bai, X. Yu. The Journal of Supercomputing, 81(10), 1126
work page 2025
-
[10]
Cong, Y., & Mo, H. (2025). An overview of robot embodied intelligence based on multimodal models: Tasks, models, and system schemes. International Journal of Intelligent Systems, 2025(1), 5124400
work page 2025
-
[11]
Wang, H., Li, C., & Li, Y. F. (2024). Large -scale visual language model boosted by contrast domain adaptation for intelligent industrial visual monitoring. IEEE Transactions on Industrial Informatics, 20(12), 14114-14123
work page 2024
-
[12]
Costanzo, M., De Maria, G., Lettera, G., & Natale, C. (2021). A multimodal approach to human safety in collaborative robotic workcells. IEEE Transactions on Automation Science and Engineering, 19(2), 1202-1216
work page 2021
-
[13]
Yu, T., Fu, K., Zhang, J., Huang, Q., & Yu, J. (2024). Multi -granularity contrastive cross -modal collaborative generation for end -to-end long -term video question answering. IEEE Transactions on Image Processing, 33, 3115-3129
work page 2024
-
[14]
Brzozka, B. (2025). Machine Learning Algorithms in Predicting College Students’ Grades: A Review. Journal of Applied Automation Technologies, 3, 1–12. https://doi.org/10.64972/jaat.2025v3.1
-
[15]
Aderoba, O. A., & Mpofu¹, K. (2025). Assembly Industrial Robots. Flexible Automation and Intelligent Manufacturing: The Future of Automation and Manufacturing: Intelligence, Agility, and Sustainability: Proceedings of FAIM 2025, June 21–24, 2025, New York City, NY, USA, Volume 1, 1, 38
work page 2025
-
[16]
Garg, S., Sünderhauf, N., Dayoub, F., Morrison, D., Cosgun, A., Carneiro, G., ... & Milford, M. (2020). Semantics for robotic mapping, perception and interaction: A survey. Foundations and Trends® in Robotics, 8(1-2), 1-224
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.