Imbalanced Classification under Capacity Constraints
Pith reviewed 2026-05-07 13:18 UTC · model grok-4.3
The pith
A classification framework enforces a user-set limit on positive predictions while maximizing detection of the minority class under capacity constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By adding an explicit constraint on the proportion of instances predicted positive, the framework produces classifiers that respect a pre-specified capacity bound while achieving higher detection performance on the minority class than either unconstrained models or resampling methods such as SMOTE. The same construction extends without change to streaming data where each decision must be made in real time.
What carries the argument
A capacity-constrained classifier that adjusts the decision rule to enforce a user-defined upper bound on the positive prediction rate while optimizing a detection metric such as recall.
If this is right
- Detection performance improves substantially compared with resampling techniques that leave the positive rate uncontrolled.
- The method extends directly to online settings where decisions occur in real time.
- Implementation uses any standard supervised learning algorithm without requiring new optimization routines.
- Explicit rate control prevents both over-selection that wastes capacity and under-selection that misses true cases.
Where Pith is reading between the lines
- Production systems could adopt the rate bound as a direct proxy for total verification cost rather than tuning post hoc.
- The same constraint idea may combine with other limits such as per-group fairness requirements.
- Evaluation protocols for imbalanced problems should routinely report performance at the operating rate the user actually faces.
Load-bearing premise
A classifier exists that can be tuned to meet the exact positive prediction rate bound and still returns meaningfully higher detection rates than methods that do not enforce the bound.
What would settle it
An experiment on a sequential imbalanced dataset in which the proposed method, forced to the same positive prediction rate, shows no higher minority-class recall than a standard classifier whose threshold is simply adjusted to match that same rate.
Figures





read the original abstract
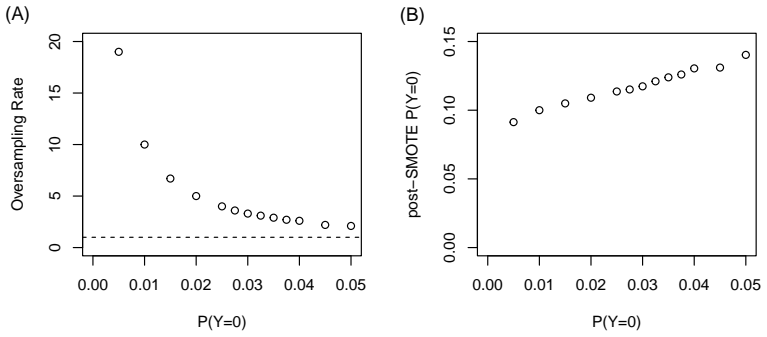
In many classification settings, the class of primary interest is underrepresented, leading to imbalanced data problems that arise in applications such as rare disease detection and fraud identification. In these contexts, identifying a potential positive instance typically triggers costly follow-up actions, such as medical imaging or detailed transaction inspection, which are subject to limited operational capacity. Motivated by this setting, we consider classification problems where data may arrive sequentially and decisions must be made under constraints on the number of instances that can be selected for further analysis. We propose a classification framework that explicitly controls the rate of positive predictions, enforcing a user-defined bound on the proportion of observations classified as belonging to the minority class while maximizing detection performance. The approach can be implemented using standard learning methods and naturally extends to online settings, where decisions are taken in real time. We show that incorporating capacity constraints leads to substantial improvements over classical approaches, including resampling techniques such as SMOTE, which do not directly control the selection rate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a classification framework for imbalanced data problems (e.g., rare disease detection, fraud) where operational capacity limits the number of positive predictions that can be followed up. The framework explicitly enforces a user-defined bound on the proportion of observations classified as positive while maximizing detection performance; it is implementable with standard learners and extends naturally to online/sequential decision settings. The central claim is that incorporating these capacity constraints yields substantial improvements over classical approaches including resampling methods such as SMOTE, which lack direct rate control.
Significance. If the empirical gains hold under fair comparisons, the work addresses a practically important gap: many imbalanced-classification pipelines ignore hard limits on follow-up actions, leading to either wasted capacity or missed detections. The ability to use off-the-shelf learners and the online extension are concrete strengths that could translate to deployable systems in resource-constrained domains. The paper also earns credit for framing the problem as an explicit constrained optimization rather than an implicit side-effect of resampling.
major comments (2)
- [Abstract and experimental sections] The central claim of 'substantial improvements over ... SMOTE' (Abstract) rests on the assumption that reported gains reflect superior detection under the exact capacity bound rather than merely the act of enforcing the bound. Experiments must therefore compare against baselines that are also forced to respect the identical positive-prediction-rate limit (e.g., by post-hoc thresholding of SMOTE scores or by adding a rate-constrained post-processing step). Without such controls, any advantage could be an artifact of capacity violation by the unconstrained baseline.
- [Method and results sections] The weakest assumption (that a classifier exists which meets the user-defined positive-rate bound while still delivering meaningful gains) is load-bearing for the practical utility claim. The manuscript should provide either a theoretical guarantee or explicit empirical verification that the proposed method can achieve the bound without collapsing to trivial performance; otherwise the framework reduces to a post-hoc rate enforcer whose detection benefit is not guaranteed.
minor comments (1)
- [Abstract] The abstract asserts 'substantial improvements' without any quantitative numbers, error bars, or dataset details; moving at least one representative table or figure reference into the abstract would strengthen the claim.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments correctly identify the need for controlled comparisons under identical capacity constraints and for explicit verification that the framework delivers non-trivial performance. We address both points below and will revise the manuscript accordingly to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Abstract and experimental sections] The central claim of 'substantial improvements over ... SMOTE' (Abstract) rests on the assumption that reported gains reflect superior detection under the exact capacity bound rather than merely the act of enforcing the bound. Experiments must therefore compare against baselines that are also forced to respect the identical positive-prediction-rate limit (e.g., by post-hoc thresholding of SMOTE scores or by adding a rate-constrained post-processing step). Without such controls, any advantage could be an artifact of capacity violation by the unconstrained baseline.
Authors: We agree that the original comparisons did not enforce the capacity bound on the SMOTE baseline, which limits the fairness of the evaluation under the operational constraint. In the revised manuscript we will add post-hoc thresholding experiments on SMOTE scores (and other baselines) to enforce exactly the same positive-prediction-rate limit used by our method. Detection metrics (recall at the fixed rate, precision-recall AUC under constraint) will be reported side-by-side. This revision will isolate the benefit of the integrated constrained optimization from the mere act of rate control. revision: yes
-
Referee: [Method and results sections] The weakest assumption (that a classifier exists which meets the user-defined positive-rate bound while still delivering meaningful gains) is load-bearing for the practical utility claim. The manuscript should provide either a theoretical guarantee or explicit empirical verification that the proposed method can achieve the bound without collapsing to trivial performance; otherwise the framework reduces to a post-hoc rate enforcer whose detection benefit is not guaranteed.
Authors: The framework is formulated as a constrained optimization that meets the bound by construction when solved with standard learners. To address the concern we will add, in the results section, explicit tables confirming that the realized positive-prediction rate matches the target bound (within solver tolerance) on every dataset and setting. We will also include a random-selection baseline that respects the identical capacity limit and show that our method consistently outperforms it, establishing non-trivial gains. While a general non-collapse theorem would require additional assumptions on the data distribution, the added empirical verification will demonstrate that meaningful detection performance is attained in practice. revision: yes
Circularity Check
No circularity: framework proposal is self-contained without derivations
full rationale
The manuscript proposes a new classification framework that enforces user-specified positive prediction rate bounds under capacity constraints, implemented via standard learners and extendable to online settings. No equations, derivations, or parameter-fitting steps appear in the provided text that would reduce a claimed result to its own inputs by construction. Claims of improvement over SMOTE and resampling methods rest on the explicit design of rate control rather than any fitted or self-cited uniqueness theorem. The central premise is a methodological choice (enforce bound while maximizing detection) whose validity is presented as empirical and implementational, not as a mathematical reduction. This satisfies the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A feasible classifier exists that meets the user-defined positive prediction bound while maximizing detection performance
Reference graph
Works this paper leans on
-
[1]
Baum, E., Haussler, D. (1988). What size net gives valid generalization?. Advances in neural information processing systems, 1. 33 0.00 0.01 0.02 0.03 0.04 0.05 0 5 10 15 20 Gain [%] b=3 b=2 b=1 P(Y = 0) Figure 6: Percentage gain over the capacity constrain method as a function of the minority-class probability P(Y = 0), for different values of the capaci...
work page 1988
-
[2]
Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. (2002). SMOTE: synthetic minority over-sampling technique.Journal of artificial intelligence research,16, 321-357
work page 2002
-
[3]
Devroye, L., Gy¨ orfi, L., Lugosi, G. (2013). A probabilistic theory of pattern recognition (Vol. 31). Springer Science & Business Media
work page 2013
-
[4]
PhD thesis “The weighted nearest neighbor rules by Royall (1966), Stanford University
work page 1966
-
[5]
Fernandez, A., Barrenechea, E., Bustince, H., & Herrera, F. (2011). A review on ensembles for the class imbalance problem: bagging-, boosting-, and hybrid-based approaches.IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews),42(4), 463-484
work page 2011
-
[6]
Galar, M., Fernandez, A., Boaches.IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews),42(4), 463-484
-
[7]
He, H. and Garcia, E. A. (2009). Learning from imbalanced data. IEEE Transactions on knowledge and data engineering, 21(9), 1263-1284
work page 2009
-
[8]
Turning the tables: Biased, imbalanced, dynamic tabular datasets for ml evaluation
Jesus, S´ ergio, et al. (2022) “Turning the tables: Biased, imbalanced, dynamic tabular datasets for ml evaluation.”Advances in Neural Infor- mation Processing Systems35: 33563-33575
work page 2022
-
[9]
(2013).Applied predictive modeling(Vol
Kuhn, M., & Johnson, K. (2013).Applied predictive modeling(Vol. 26). New York: Springer
work page 2013
-
[10]
Kaur, H., Pannu, H. S., & Malhi, A. K. (2019). A systematic review on imbalanced data challenges in machine learning: Applications and solutions.ACM computing surveys (CSUR),52(4), 1-36
work page 2019
-
[11]
Menon, A., Narasimhan, H., Agarwal, S., Chawla, S. (2013, May). On the statistical consistency of algorithms for binary classification under class imbalance. In International Conference on Machine Learning (pp. 603-611). PMLR
work page 2013
-
[12]
Consistent multiclass algorithms for complex metrics and constraints
Narasimhan, H., Ramaswamy, H. G., Tavker, S. K., Khurana, D., Ne- trapalli, P., Agarwal, S. (2024). “Consistent multiclass algorithms for complex metrics and constraints.”Journal of Machine Learning Research, 25(367), 1-81. 35
work page 2024
-
[13]
W. Pei, B. Xue, M. Zhang, L. Shang, X. Yao and Q. Zhang, ”A Survey on Unbalanced Classification: How Can Evolutionary Computation Help?,” inIEEE Transactions on Evolutionary Computation, vol. 28, no. 2, pp. 353-373, April 2024
work page 2024
-
[14]
Steinwart, I. (2005). ”Consistency of support vector machines and other regularized kernel classifiers”. IEEE Transactions on Information Theory Vol. 51, no.1, pp. 128–142 (2005)
work page 2005
-
[15]
Yeh, I-Cheng, and Che-hui Lien. (2009) “The comparisons of data mining techniques for the predictive accuracy of probability of default of credit card clients.”Expert systems with applications, 36.2, 2473-2480
work page 2009
-
[16]
Differential Privacy Under Class Imbalance: Methods and Empirical Insights
L. Rosenblatt, J Lut, E. Turok, M. Avella Medina, R. Cumming (2025) “Differential Privacy Under Class Imbalance: Methods and Empirical Insights”,Forty-second International Conference on Machine Learning
work page 2025
-
[17]
Finding the best classification threshold in imbalanced classifications
Zou, Q., Xie, S., Lin, Z., Wu, M., Ju, Y. (2016). “Finding the best classification threshold in imbalanced classifications”,Big Data Research, 5, 2-8. 36
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.