Transformers Provably Implement In-Context Reinforcement Learning with Policy Improvement
Pith reviewed 2026-05-08 05:33 UTC · model grok-4.3
The pith
A linear self-attention transformer block can execute policy-improvement steps from reinforcement learning algorithms when supplied with trajectory data in context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A linear self-attention transformer block can provably implement policy-improvement methods, including semi-gradient SARSA and actor-critic, via explicit parameter constructions. Beyond existence, the paper analyzes a teacher-mimicking training procedure and establishes that, under suitable richness conditions on the training MDP distribution, gradient flow converges locally and exponentially to an optimal parameter manifold corresponding to the desired RL update. Empirically, models trained on randomly generated tabular MDPs recover the predicted parameter structure and achieve strong control performance on unseen MDPs.
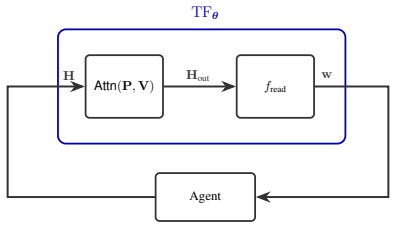
What carries the argument
linear self-attention transformer block, which the paper shows can be parameterized to compute the policy-improvement update by combining action-value estimates drawn from the input context.
If this is right
- The transformer applies semi-gradient SARSA updates to new trajectories presented in its context without any parameter changes.
- The same block can implement actor-critic style policy improvements when the appropriate parameters are used.
- Gradient flow during teacher-mimicking training reaches the parameter manifold that realizes these RL updates.
- Once trained, the model delivers strong in-context control performance on MDPs never seen during training.
Where Pith is reading between the lines
- The same construction may extend to show how transformers can internalize variants of Q-learning or other value-based methods.
- The convergence guarantee suggests that dataset design for in-context RL should prioritize diversity across MDPs rather than depth within a single environment.
- Observed strong few-shot behavior in large language models on sequential decision tasks could partly arise from similar internalized policy-improvement mechanisms.
Load-bearing premise
The distribution of MDPs used during training must be rich enough for gradient flow to converge locally and exponentially to the target parameter manifold.
What would settle it
Train the transformer on a narrow distribution of similar MDPs and observe whether the resulting weights fail to match the explicit constructions or produce weak performance on new MDPs.
Figures



read the original abstract
We investigate the ability of transformers to perform in-context reinforcement learning (ICRL), where a model must infer and execute learning algorithms from trajectory data without parameter updates. We show that a linear self-attention transformer block can provably implement policy-improvement methods, including semi-gradient SARSA and actor-critic, via explicit parameter constructions. Beyond existence, we design a teacher-mimicking training procedure, analyze its gradient-flow dynamics, and establish the first convergence guarantee in the ICRL literature: under suitable richness conditions on the training MDP distribution, gradient flow converges locally and exponentially to an optimal parameter manifold corresponding to the desired RL update. Empirically, training transformers on randomly generated tabular MDPs confirms these predictions: the learned models recover the parameter structure of our explicit constructions and, when deployed on unseen MDPs, deliver strong in-context control performance. Together, these results illuminate how transformer architectures internalize and execute classical reinforcement learning algorithms in context, bridging mechanistic understanding and training dynamics in ICRL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a linear self-attention transformer block can provably implement in-context policy-improvement algorithms (semi-gradient SARSA and actor-critic) via explicit parameter constructions. It further shows that a teacher-mimicking training loss, when optimized by gradient flow, converges locally and exponentially to the target parameter manifold under suitable richness conditions on the distribution of training MDPs. Experiments on randomly generated tabular MDPs confirm that trained models recover the constructed parameter structure and achieve strong in-context control on unseen MDPs.
Significance. If the constructions and convergence result hold, the work supplies the first explicit mechanistic account of how transformers can internalize classical RL updates in context, together with the first convergence guarantee in the ICRL literature. The explicit constructions and the gradient-flow analysis are concrete strengths that could guide both architecture design and training procedures for in-context learners.
major comments (3)
- [Theorem 4.3] Theorem 4.3 (gradient-flow convergence): the local exponential convergence guarantee is conditioned on 'suitable richness conditions' on the MDP distribution, yet the paper does not provide an explicit, checkable statement of these conditions nor verify that they hold for the randomly generated tabular MDPs used in §6. Without this verification the exponential rate does not necessarily apply to the reported experiments.
- [§5.2] §5.2 (basin of attraction): the analysis establishes local convergence to the target manifold but does not characterize the size of the basin or show that typical random initializations lie inside it. This leaves open whether the training procedure reliably reaches the desired RL update in practice.
- [§6.1] §6.1 (empirical validation): the experiments are restricted to tabular MDPs with no error bars, no ablation of the richness assumption, and no comparison against non-transformer baselines that could isolate the effect of the attention mechanism.
minor comments (2)
- [Eq. (3)] Notation for the linear self-attention block (Eq. (3)) should explicitly distinguish the query/key/value projections from the subsequent value mixing that realizes the SARSA update.
- [Figure 3] Figure 3 caption should state the exact number of random seeds and MDPs used to generate the reported curves.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and presentation of our theoretical and empirical results. We address each major point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Theorem 4.3] Theorem 4.3 (gradient-flow convergence): the local exponential convergence guarantee is conditioned on 'suitable richness conditions' on the MDP distribution, yet the paper does not provide an explicit, checkable statement of these conditions nor verify that they hold for the randomly generated tabular MDPs used in §6. Without this verification the exponential rate does not necessarily apply to the reported experiments.
Authors: We agree that the richness conditions should be stated explicitly to allow verification. In the revised manuscript, we will provide a precise, checkable formulation: the training distribution must ensure that the Gram matrix of the concatenated state-action-next-state features across sampled trajectories has full rank equal to the dimension of the target parameter space. We will also add a short appendix verifying that the random tabular MDP generator (with uniform sampling over states, actions, and transitions) satisfies this condition with high probability for the dimensions used in §6, thereby confirming applicability of the exponential rate to the experiments. revision: yes
-
Referee: [§5.2] §5.2 (basin of attraction): the analysis establishes local convergence to the target manifold but does not characterize the size of the basin or show that typical random initializations lie inside it. This leaves open whether the training procedure reliably reaches the desired RL update in practice.
Authors: The result in §5.2 is deliberately local, as is standard for gradient-flow analyses of non-convex losses; a full global characterization of the basin would require substantially stronger assumptions on the loss landscape that lie outside the paper's scope. To address practical reliability, we will expand §5.2 with a brief discussion of sufficient conditions for a large basin (e.g., when the teacher loss is strongly convex near the manifold) and will report, in the experiments, the fraction of random initializations that successfully converge to the target structure, providing empirical evidence that typical initializations lie inside the basin for the considered settings. revision: partial
-
Referee: [§6.1] §6.1 (empirical validation): the experiments are restricted to tabular MDPs with no error bars, no ablation of the richness assumption, and no comparison against non-transformer baselines that could isolate the effect of the attention mechanism.
Authors: We acknowledge these limitations in the current experimental section. In the revision we will (i) add error bars by repeating all runs over at least 10 random seeds, (ii) include an ablation that varies MDP richness (e.g., by restricting transition diversity) and reports the resulting convergence behavior, and (iii) add comparisons against non-transformer baselines (MLPs and LSTMs) trained with the identical teacher-mimicking objective, thereby isolating the contribution of the linear self-attention mechanism to in-context policy improvement. revision: yes
Circularity Check
No significant circularity; explicit constructions and convergence analysis remain independent of self-referential inputs.
full rationale
The paper derives explicit parameter constructions in a linear self-attention block that realize semi-gradient SARSA and actor-critic updates by direct mapping from the external RL algorithms. The subsequent teacher-mimicking loss is defined against an independent teacher that already executes those same external updates, so the target manifold is fixed by the RL methods rather than by the training procedure itself. Gradient-flow analysis then proves local exponential convergence to that manifold under stated richness conditions on the MDP distribution. This chain relies on external benchmarks (classical RL algorithms) and does not reduce any central claim to a fitted parameter renamed as prediction, a self-citation chain, or a self-definitional loop. The empirical confirmation on randomly generated MDPs further tests recovery of the externally defined structure rather than tautological self-matching.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Suitable richness conditions on the training MDP distribution
Reference graph
Works this paper leans on
- [1]
-
[2]
Language Models are Few-Shot Learners , year =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[3]
Proceedings of Neural Information Processing Systems , year=
What can transformers learn in-context? a case study of simple function classes , author=. Proceedings of Neural Information Processing Systems , year=
-
[4]
The Thirteenth International Conference on Learning Representations , year=
Transformers Can Learn Temporal Difference Methods for In-Context Reinforcement Learning , author=. The Thirteenth International Conference on Learning Representations , year=
-
[5]
Reinforcement Learning: An Introduction , author =. 2018 , edition =
work page 2018
-
[6]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, Lukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =. 2017 , month =
work page 2017
-
[7]
The Eleventh International Conference on Learning Representations , year=
In-context Reinforcement Learning with Algorithm Distillation , author=. The Eleventh International Conference on Learning Representations , year=
-
[8]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Supervised Pretraining Can Learn In-Context Reinforcement Learning , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[9]
Chowdhery, Aakanksha and Narang, Sharan and Devlin, Jacob and Bosma, Maarten and Mishra, Gaurav and Roberts, Adam and Barham, Paul and Chung, Hyung Won and Sutton, Charles and Gehrmann, Sebastian and others , journal =
-
[10]
OpenAI and Josh Achiam and Steven Adler and Sandhini Agarwal and Lama Ahmad and Ilge Akkaya and Florencia Leoni Aleman and Diogo Almeida and Janko Altenschmidt and Sam Altman and Shyamal Anadkat and others , journal =. 2024 , eprint=
work page 2024
-
[11]
Proceedings of the 40th International Conference on Machine Learning , year =
Transformers Learn In-Context by Gradient Descent , author =. Proceedings of the 40th International Conference on Machine Learning , year =
-
[12]
What learning algorithm is in-context learning?
Aky. What learning algorithm is in-context learning?. The Eleventh International Conference on Learning Representations , year =
-
[13]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Transformers learn to implement preconditioned gradient descent for in-context learning , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[14]
A Survey of In-Context Reinforcement Learning , author=. 2025 , eprint=
work page 2025
-
[15]
Kingma, Diederik P. and Ba, Jimmy , title =. International Conference on Learning Representations (ICLR) , year =
-
[16]
The Twelfth International Conference on Learning Representations , year =
One Step of Gradient Descent is Provably the Optimal In-Context Learner with One Layer of Linear Self-Attention , author =. The Twelfth International Conference on Learning Representations , year =
-
[17]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Transformers as Statisticians: Provable In-Context Learning with In-Context Algorithm Selection , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[18]
Journal of Machine Learning Research , year =
Trained Transformers Learn Linear Models In-Context , author =. Journal of Machine Learning Research , year =
-
[19]
Thirty-seventh Conference on Neural Information Processing Systems , year =
Large Language Models can Implement Policy Iteration , author =. Thirty-seventh Conference on Neural Information Processing Systems , year =
-
[20]
The Thirteenth International Conference on Learning Representations , year=
Transformers Handle Endogeneity in In-Context Linear Regression , author=. The Thirteenth International Conference on Learning Representations , year=
-
[21]
NeurIPS 2023 Foundation Models for Decision Making Workshop , year=
Learning to Solve New sequential decision-making Tasks with In-Context Learning , author=. NeurIPS 2023 Foundation Models for Decision Making Workshop , year=
work page 2023
-
[22]
The Twelfth International Conference on Learning Representations , year =
Transformers as Decision Makers: Provable In-Context Reinforcement Learning via Supervised Pretraining , author =. The Twelfth International Conference on Learning Representations , year =
- [23]
-
[24]
Training Dynamics of Multi-Head Softmax Attention for In-Context Learning: Emergence, Convergence, and Optimality , author=. 2024 , eprint=
work page 2024
-
[25]
Thirty-seventh Conference on Neural Information Processing Systems , year =
Scan and Snap: Understanding Training Dynamics and Token Composition in 1-layer Transformer , author =. Thirty-seventh Conference on Neural Information Processing Systems , year =
-
[26]
Forty-first International Conference on Machine Learning , year=
How Transformers Learn Causal Structure with Gradient Descent , author=. Forty-first International Conference on Machine Learning , year=
-
[27]
Advances in Neural Information Processing Systems , editor=
Decision Transformer: Reinforcement Learning via Sequence Modeling , author=. Advances in Neural Information Processing Systems , editor=. 2021 , url=
work page 2021
-
[28]
Offline Reinforcement Learning as One Big Sequence Modeling Problem , url =
Janner, Michael and Li, Qiyang and Levine, Sergey , booktitle =. Offline Reinforcement Learning as One Big Sequence Modeling Problem , url =
- [29]
-
[30]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Can large language models explore in-context? , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.