Distributionally-Robust Learning to Optimize
Pith reviewed 2026-05-08 12:17 UTC · model grok-4.3
The pith
Minimizing a Wasserstein-robust version of the performance estimation problem produces first-order optimization algorithms with provable out-of-sample guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
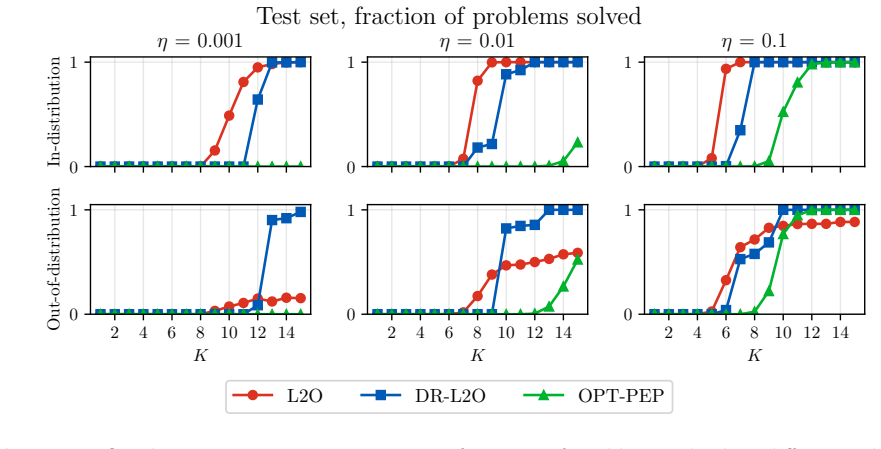
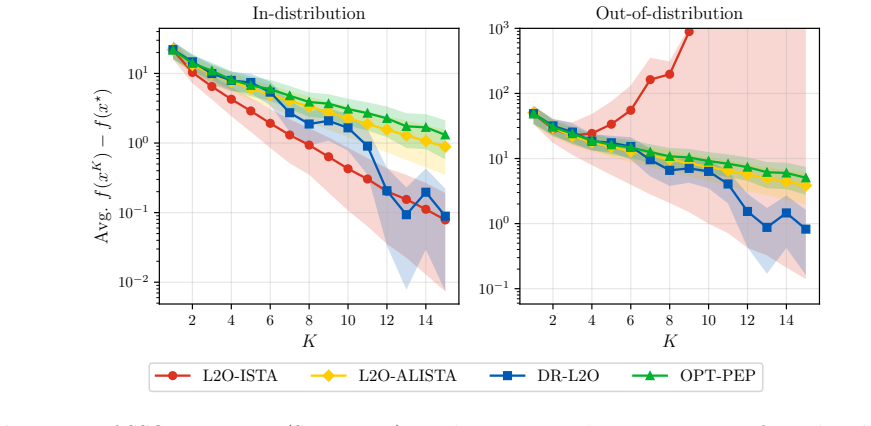
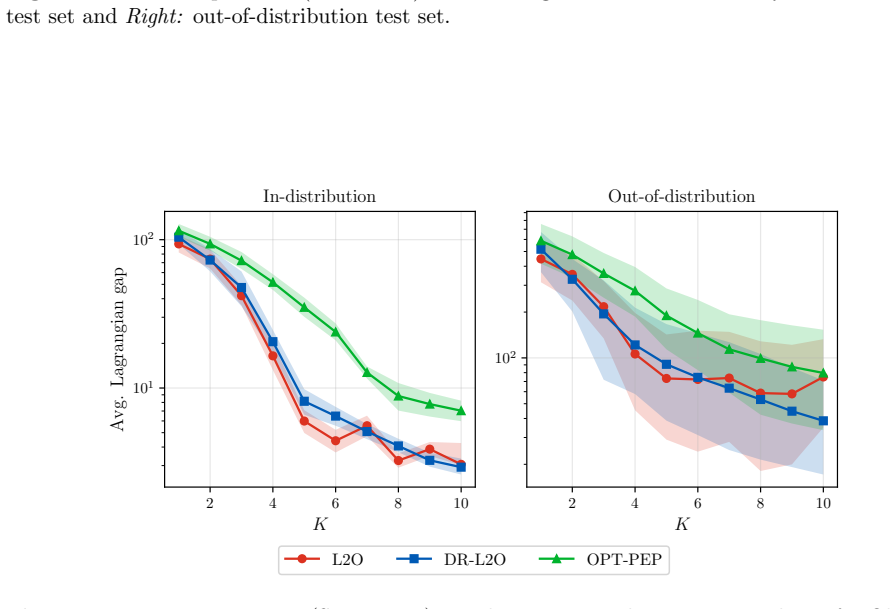
We minimize a Wasserstein distributionally robust performance estimation problem over algorithm hyperparameters. As the robustness radius tends to zero this recovers standard learning to optimize; as the radius grows it recovers worst-case optimal algorithm design. High-probability bounds show that the true risk of the learned algorithm is at most the in-sample optimum plus a term vanishing with sample size and is never worse than the pure PEP worst-case value. Experiments on unconstrained quadratic minimization, LASSO, and linear programming show improved out-of-sample performance relative to both extremes.
What carries the argument
The Wasserstein distributionally robust performance estimation problem (DRO-PEP), which replaces the empirical risk in the PEP with its worst-case value over all distributions within a given Wasserstein distance of the training empirical measure and is minimized by differentiating through the solution of the resulting inner semidefinite program at each SGD step.
If this is right
- The true risk of any algorithm produced by the method is bounded above by the in-sample L2O optimum plus a slack that shrinks with the number of training samples.
- The same risk is guaranteed to be no larger than the worst-case PEP bound obtained by letting the robustness radius become infinite.
- On quadratic, LASSO, and linear-programming benchmarks the learned algorithms simultaneously beat both the vanilla L2O baseline and the worst-case PEP baseline in out-of-sample performance.
- The framework is applicable to any first-order method whose worst-case performance on a fixed problem can be encoded as a semidefinite program.
Where Pith is reading between the lines
- Practitioners could choose the robustness radius by estimating the expected Wasserstein distance between training and deployment problem distributions rather than fixing it in advance.
- If the inner SDP becomes computationally expensive for high-dimensional problems, replacing it with a cheaper relaxation or sampling-based estimator would preserve the outer-loop structure.
- The same DRO-PEP construction could be applied to learn parameters of other iterative algorithms whose convergence can be bounded by a semidefinite program.
Load-bearing premise
The inner semidefinite programs that encode the performance estimation problem can be solved accurately and differentiated through at every step of the outer stochastic gradient descent, and the training dataset of problem instances is sufficiently representative that the Wasserstein ball captures the distribution shifts that actually occur at test time.
What would settle it
Generate a large held-out test set of problem instances drawn from a distribution whose Wasserstein distance from the training set exceeds the chosen robustness radius and check whether the observed performance of the learned algorithm violates the high-probability risk bound or fails to improve on the pure L2O and pure PEP baselines.
Figures







read the original abstract
We propose a distributionally robust approach to learning hyperparameters for first-order methods in convex optimization. Given a dataset of problem instances, we minimize a Wasserstein distributionally robust version of the performance estimation problem (PEP) over algorithm parameters such as step sizes. Our framework unifies two extremes: as the robustness radius vanishes, we recover classical learning to optimize (L2O); as it grows, we recover worst-case optimal algorithm design via PEP. We solve the resulting problem with stochastic gradient descent, differentiating through the solution of an inner semidefinite program at each step. We prove high-probability bounds showing that the true risk of the learned algorithm is at most the in-sample L2O optimum plus a slack that shrinks with the sample size, and is no worse than the worst-case PEP bound. On unconstrained quadratic minimization, LASSO, and linear programming benchmarks, our learned algorithms achieve strong out-of-sample performance with certifiable robustness, outperforming both worst-case optimal and vanilla L2O baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a distributionally robust framework for learning to optimize (L2O) by minimizing a Wasserstein DRO version of the performance estimation problem (PEP) over algorithm parameters such as step sizes. It unifies classical L2O (recovered as the robustness radius vanishes) and worst-case optimal design via PEP (as the radius grows). The resulting nonconvex problem is solved via SGD, with each gradient step requiring solution of an inner SDP for the robust PEP followed by differentiation through its optimal value. High-probability generalization bounds are derived showing that the true risk of the learned algorithm is bounded by the in-sample L2O optimum plus a vanishing slack term, and is no worse than the worst-case PEP bound. On benchmarks including unconstrained quadratic minimization, LASSO, and linear programming, the learned algorithms are reported to achieve strong out-of-sample performance with certifiable robustness, outperforming both worst-case PEP and vanilla L2O baselines.
Significance. If the inner SDP solves and differentiation steps are numerically reliable, the work provides a principled unification of average-case L2O and worst-case PEP design, together with high-probability bounds that certify robustness without sacrificing practical performance. The explicit credit for the parameter-free limiting cases and the reproducible benchmark comparisons on standard convex problems are strengths. The approach could influence both the L2O and robust optimization literatures by offering a tunable robustness knob backed by concentration inequalities.
major comments (2)
- [§4.2] §4.2 (Differentiable PEP layer): The central training procedure relies on solving the inner distributionally robust PEP SDP to sufficient accuracy and obtaining a usable gradient (via implicit differentiation or KKT system) at every SGD iterate. No numerical validation, tolerance analysis, or handling of non-unique dual multipliers is provided for cases where the quadratic forms become degenerate (e.g., LASSO instances with active constraints). This assumption is load-bearing for both the learned parameters and the claimed certifiable out-of-sample robustness in §5.
- [Theorem 3] Theorem 3 (High-probability risk bound): The bound asserts that the true risk is at most the in-sample L2O optimum plus a term that shrinks with sample size. The proof sketch invokes standard concentration around the learned in-sample optimum, but does not address whether the map from algorithm parameters to the worst-case PEP value remains Lipschitz or has bounded sensitivity uniformly over the Wasserstein ball when SDP solutions lie on the boundary of the feasible set.
minor comments (3)
- [§5.1] §5.1 and Table 1: the experimental protocol for selecting the robustness radius (cross-validation, fixed grid, or otherwise) is not stated, making it difficult to assess whether the reported gains are robust to this hyperparameter.
- [Figure 3] Figure 3: axis labels and legend entries for the three methods (DRO-L2O, PEP, vanilla L2O) are difficult to distinguish in black-and-white rendering; add distinct line styles or markers.
- [§2.3] §2.3: the notation for the Wasserstein ball radius ε is introduced without an explicit statement of its units or scaling with problem dimension, which affects interpretability of the limiting cases.
Simulated Author's Rebuttal
We thank the referee for the thorough review and for highlighting the strengths of our unification of L2O and PEP design. We address the two major comments below with concrete revisions to the manuscript.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Differentiable PEP layer): The central training procedure relies on solving the inner distributionally robust PEP SDP to sufficient accuracy and obtaining a usable gradient (via implicit differentiation or KKT system) at every SGD iterate. No numerical validation, tolerance analysis, or handling of non-unique dual multipliers is provided for cases where the quadratic forms become degenerate (e.g., LASSO instances with active constraints). This assumption is load-bearing for both the learned parameters and the claimed certifiable out-of-sample robustness in §5.
Authors: We agree that reliable SDP solves and gradients are essential. In the revision we will add a dedicated numerical appendix subsection that (i) specifies solver tolerances (e.g., MOSEK primal/dual feasibility 1e-8, relative gap 1e-6), (ii) reports empirical gradient accuracy on 50 random LASSO instances with active constraints by comparing implicit differentiation against finite differences, and (iii) handles potential non-uniqueness by adding a small Tikhonov regularization (1e-4) to the dual SDP objective, which preserves the optimal value up to a controllable error while guaranteeing unique multipliers. These changes directly support the robustness claims in §5. revision: yes
-
Referee: [Theorem 3] Theorem 3 (High-probability risk bound): The bound asserts that the true risk is at most the in-sample L2O optimum plus a term that shrinks with sample size. The proof sketch invokes standard concentration around the learned in-sample optimum, but does not address whether the map from algorithm parameters to the worst-case PEP value remains Lipschitz or has bounded sensitivity uniformly over the Wasserstein ball when SDP solutions lie on the boundary of the feasible set.
Authors: We thank the referee for this observation. The optimal value of the distributionally robust PEP is continuous in the algorithm parameters for each fixed instance (by standard SDP perturbation results under Slater’s condition, which holds for the quadratic, LASSO, and LP problems we consider). To obtain a uniform Lipschitz constant over the compact Wasserstein ball, we will revise the proof of Theorem 3 to include an explicit sensitivity bound derived from the dual SDP: the Lipschitz modulus is controlled by the maximum norm of the problem data matrices and the radius of the Wasserstein ball. This argument is added without changing the statement of the bound and ensures the concentration step remains valid even when optimal solutions lie on the boundary. revision: yes
Circularity Check
Derivation chain is self-contained with no circular reductions
full rationale
The paper's high-probability generalization bounds are derived from standard concentration inequalities around the learned in-sample optimum and do not reduce by the paper's own equations to a quantity defined solely in terms of a fitted parameter. The unification of L2O and worst-case PEP as limiting cases of the Wasserstein radius is a definitional observation rather than a circular derivation. No self-citations are load-bearing for the central claims, and the empirical out-of-sample results on benchmarks are independent of the theoretical chain. The inner SDP differentiation is a computational procedure whose stability is an implementation concern, not a logical circularity in the bounds or unification.
Axiom & Free-Parameter Ledger
free parameters (1)
- robustness radius
axioms (1)
- domain assumption The underlying optimization problems are convex.
Reference graph
Works this paper leans on
-
[1]
A. Agrawal, B. Amos, S. Barratt, S. Boyd, S. Diamond, and J. Z. Kolter. Differentiable Convex Optimization Layers. InAdvances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019
work page 2019
-
[2]
A. Agrawal, S. Barratt, S. Boyd, E. Busseti, and W. M. Moursi. Differentiating Through a Cone Program.Journal of Applied & Numerical Optimization, 1(2):107–115, May 2019
work page 2019
-
[3]
J. M. Altschuler and P. A. Parrilo. Acceleration by stepsize hedging: Silver Stepsize Schedule for smooth convex optimization.Mathematical Programming, 213(1):1105– 1118, Sept. 2025
work page 2025
-
[4]
B. Amos. Tutorial on Amortized Optimization.Foundations and Trends in Machine Learning, 16(5):592–732, June 2023
work page 2023
-
[5]
M. Andrychowicz, M. Denil, S. G´ omez, M. W. Hoffman, D. Pfau, T. Schaul, B. Shilling- ford, and N. de Freitas. Learning to learn by gradient descent by gradient descent. In Advances in Neural Information Processing Systems, volume 29. Curran Associates, Inc., 2016
work page 2016
-
[6]
D. Applegate, M. Diaz, O. Hinder, H. Lu, M. Lubin, B. O’ Donoghue, and W. Schudy. Practical Large-Scale Linear Programming using Primal-Dual Hybrid Gradient. InAd- vances in Neural Information Processing Systems, volume 34, pages 20243–20257, New York, 2021. Curran Associates, Inc
work page 2021
-
[7]
D. Applegate, O. Hinder, H. Lu, and M. Lubin. Faster first-order primal-dual meth- ods for linear programming using restarts and sharpness.Mathematical Programming, 201(1):133–184, 2023
work page 2023
-
[8]
H. H. Bauschke and P. L. Combettes.Convex Analysis and Monotone Operator The- ory in Hilbert Spaces. CMS Books in Mathematics. Springer International Publishing, Cham, 2017. 14
work page 2017
-
[9]
Beck.First-Order Methods in Optimization
A. Beck.First-Order Methods in Optimization. Society for Industrial and Applied Mathematics, Philadelphia, PA, 2017
work page 2017
-
[10]
C. Berge.Topological Spaces: Including a Treatment of Multi-valued Functions, Vector Spaces and Convexity. Oliver & Boyd, 1963
work page 1963
-
[11]
N. Blin, S. Gualandi, C. Maes, A. Lodi, and B. Stellato. Batched First-Order Methods for Parallel LP Solving in MIP. InInternational Conference on Machine Learning (ICML), 2026
work page 2026
-
[12]
N. Bousselmi, J. M. Hendrickx, and F. Glineur. Interpolation Conditions for Linear Operators and Applications to Performance Estimation Problems.SIAM Journal on Optimization, 34(3):3033–3063, Sept. 2024
work page 2024
-
[13]
S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein. Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers.Foundations and Trends in Machine Learning, 3:1–122, Jan. 2011
work page 2011
-
[14]
A. L. Cambridge. The Olivetti faces dataset.http://www.cl.cam.ac.uk/research/ dtg/attarchive/facedatabase.html, 1994
work page 1994
-
[15]
A. Chambolle and T. Pock. A First-Order Primal-Dual Algorithm for Convex Problems with Applications to Imaging.Journal of Mathematical Imaging and Vision, 40(1):120– 145, 2011
work page 2011
-
[16]
K. Chen, D. Sun, Y. Yuan, G. Zhang, and X. Zhao. HPR-LP: An implementation of an HPR method for solving linear programming.Mathematical Programming Computation, Oct. 2025
work page 2025
-
[17]
K. Chen, D. Sun, Y. Yuan, G. Zhang, and X. Zhao. HPR-QP: A dual Halpern Peaceman- Rachford method for solving large-scale convex composite quadratic programming, July 2025
work page 2025
-
[18]
T. Chen, X. Chen, W. Chen, H. Heaton, J. Liu, Z. Wang, and W. Yin. Learning to Optimize: A Primer and A Benchmark.Journal of Machine Learning Research, 23(189):1–59, 2022
work page 2022
-
[19]
X. Chen, T. Chen, Y. Cheng, W. Chen, A. Awadallah, and Z. Wang. Scalable Learning to Optimize: A Learned Optimizer Can Train Big Models. InComputer Vision – ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXIII, pages 389–405, Berlin, Heidelberg, Oct. 2022. Springer-Verlag
work page 2022
-
[20]
X. Chen, J. Liu, Z. Wang, and W. Yin. Theoretical Linear Convergence of Unfolded ISTA and its Practical Weights and Thresholds. InAdvances in Neural Information Processing Systems, volume 31, pages 9079–9089, Canada, 2018. Curran Associates, Inc. 15
work page 2018
-
[21]
S. Das Gupta, B. P. G. Van Parys, and E. K. Ryu. Branch-and-bound performance estimation programming: A unified methodology for constructing optimal optimization methods.Mathematical Programming, 204(1-2):567–639, Mar. 2024
work page 2024
-
[22]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. IEEE, 2009
work page 2009
-
[23]
S. Diamond and S. Boyd. Total variation inpainting. CVXPY Examples, 2016. Accessed: 2025-05-01
work page 2016
-
[24]
Y. Drori and M. Teboulle. Performance of first-order methods for smooth convex min- imization: A novel approach.Mathematical Programming, 145(1):451–482, June 2014
work page 2014
-
[25]
G. K. Dziugaite and D. M. Roy. Computing Nonvacuous Generalization Bounds for Deep (Stochastic) Neural Networks with Many More Parameters than Training Data. InProceedings of the 33rd Conference on Uncertainty in Artificial Intelligence. AUAI Press, Aug. 2017
work page 2017
-
[26]
N. Fournier and A. Guillin. On the rate of convergence in Wasserstein distance of the empirical measure.Probability Theory and Related Fields, 162(3-4):707–738, Aug. 2015
work page 2015
-
[27]
M. Frank and P. Wolfe. An algorithm for quadratic programming.Naval Research Logistics Quarterly, 3(1-2):95–110, 1956
work page 1956
-
[28]
M. Garstka, M. Cannon, and P. Goulart. COSMO: A conic operator splitting method for large convex problems. In2019 18th European Control Conference (ECC), pages 1951–1956, Naples, Italy, June 2019. IEEE
work page 1951
- [29]
-
[30]
P. J. Goulart and Y. Chen. Clarabel: An interior-point solver for conic programs with quadratic objectives, May 2024
work page 2024
-
[31]
K. Gregor and Y. LeCun. Learning fast approximations of sparse coding. InProceedings of the 27th International Conference on International Conference on Machine Learning, ICML’10, pages 399–406, Madison, WI, USA, June 2010. Omnipress
work page 2010
- [32]
- [33]
- [34]
- [35]
-
[36]
U. Jang, S. D. Gupta, and E. K. Ryu. Computer-Assisted Design of Accelerated Com- posite Optimization Methods: OptISTA, Sept. 2024
work page 2024
- [37]
-
[38]
D. Kim. Accelerated proximal point method for maximally monotone operators.Math- ematical Programming, 190(1):57–87, Nov. 2021
work page 2021
- [39]
-
[40]
D. P. Kingma and J. Ba. Adam: A Method for Stochastic Optimization. In3rd International Conference on Learning Representations, 2015
work page 2015
-
[41]
D. Kuhn, P. M. Esfahani, V. A. Nguyen, and S. Shafieezadeh-Abadeh. Wasserstein Distributionally Robust Optimization: Theory and Applications in Machine Learning. In S. Netessine, D. Shier, and H. J. Greenberg, editors,Operations Research & Man- agement Science in the Age of Analytics, pages 130–166. INFORMS, Washington, Oct. 2019
work page 2019
-
[42]
D. Kuhn, S. Shafiee, and W. Wiesemann. Distributionally Robust Optimization.Acta Numerica, 34:579–804, 2025
work page 2025
- [43]
-
[44]
L. Lessard, B. Recht, and A. Packard. Analysis and Design of Optimization Algorithms via Integral Quadratic Constraints.SIAM Journal on Optimization, 26(1):57–95, Jan. 2016
work page 2016
- [45]
-
[46]
Z. Lin, Z. Xiong, D. Ge, and Y. Ye. A Practical GPU-Enhanced Matrix-Free Primal- Dual Method for Large-Scale Conic Programs, Apr. 2026
work page 2026
-
[47]
J. Liu, X. Chen, Z. Wang, and W. Yin. ALISTA: Analytic Weights Are As Good As Learned Weights in LISTA. InInternational Conference on Learning Representations, May 2019. 17
work page 2019
-
[48]
J. Liu, X. Chen, Z. Wang, W. Yin, and H. Cai. Towards Constituting Mathematical Structures for Learning to Optimize. InProceedings of the 40th International Conference on Machine Learning, pages 21426–21449. PMLR, July 2023
work page 2023
-
[49]
I. Loshchilov and F. Hutter. SGDR: Stochastic Gradient Descent with Warm Restarts. InInternational Conference on Learning Representations, 2017
work page 2017
-
[50]
I. Loshchilov and F. Hutter. Decoupled Weight Decay Regularization. InInternational Conference on Learning Representations, May 2019
work page 2019
-
[51]
H. Lu, Z. Peng, and J. Yang. cuPDLPx: A Further Enhanced GPU-Based First-Order Solver for Linear Programming, Sept. 2025
work page 2025
- [52]
-
[53]
V. A. Marˇ cenko and L. A. Pastur. Distribution of Eigenvalues for Some Sets of Random Matrices.Mathematics of the USSR-Sbornik, 1(4):457–483, Apr. 1967
work page 1967
-
[54]
A. Martin and G. Belgioioso. Learning to accelerate Krasnosel’skii-Mann fixed-point iterations with guarantees, Jan. 2026
work page 2026
-
[55]
A. Martin and L. Furieri. Learning to Optimize With Convergence Guarantees Using Nonlinear System Theory.IEEE Control Systems Letters, 8:1355–1360, 2024
work page 2024
- [56]
-
[57]
P. Mohajerin Esfahani and D. Kuhn. Data-driven distributionally robust optimization using the Wasserstein metric: Performance guarantees and tractable reformulations. Mathematical Programming, 171(1-2):115–166, Sept. 2018
work page 2018
-
[58]
B. O’Donoghue. Operator splitting for a homogeneous embedding of the linear comple- mentarity problem.SIAM Journal on Optimization, 31(3):1999–2023, 2021
work page 1999
-
[59]
B. O’Donoghue, E. Chu, N. Parikh, and S. Boyd. Conic optimization via operator splitting and homogeneous self-dual embedding.Journal of Optimization Theory and Applications, 169(3):1042–1068, 2016
work page 2016
-
[60]
N. Parikh and S. Boyd. Proximal Algorithms.Foundations and Trends®in Optimiza- tion, 1(3):127–239, 2014
work page 2014
-
[61]
J. Park, V. Ranjan, and B. Stellato. Data-driven Analysis of First-Order Methods via Distributionally Robust Optimization, Dec. 2025
work page 2025
-
[62]
F. Pedregosa and D. Scieur. Average-case Acceleration through spectral density estima- tion. InProceedings of the 37th International Conference on Machine Learning, pages 7553–7562, Austria (Virtual), Nov. 2020. PMLR. 18
work page 2020
-
[63]
I. Pr´ emont-Schwarz, J. V´ ıtk˚ u, and J. Feyereisl. A Simple Guard for Learned Optimizers. InProceedings of the 39th International Conference on Machine Learning, pages 17910– 17925. PMLR, July 2022
work page 2022
- [64]
-
[65]
V. Ranjan and B. Stellato. Verification of first-order methods for parametric quadratic optimization.Mathematical Programming, July 2025
work page 2025
-
[66]
R. T. Rockafellar and S. Uryasev. Conditional Value-at-Risk: Optimization Approach. In S. Uryasev and P. M. Pardalos, editors,Stochastic Optimization: Algorithms and Applications, pages 411–435. Springer US, Boston, MA, 2001
work page 2001
-
[67]
E. K. Ryu, A. B. Taylor, C. Bergeling, and P. Giselsson. Operator Splitting Perfor- mance Estimation: Tight Contraction Factors and Optimal Parameter Selection.SIAM Journal on Optimization, 30(3):2251–2271, Jan. 2020
work page 2020
-
[68]
E. K. Ryu and W. Yin.Large-Scale Convex Optimization: Algorithms & Analyses via Monotone Operators. Cambridge University Press, Cambridge, UK, 1 edition, 2022
work page 2022
-
[69]
F. Samaria and A. Harter. Parameterisation of a stochastic model for human face identification. InProceedings of 1994 IEEE Workshop on Applications of Computer Vision, pages 138–142, 1994
work page 1994
-
[70]
R. Sambharya, J. Bok, N. Matni, and G. Pappas. Learning Acceleration Algorithms for Fast Parametric Convex Optimization with Certified Robustness, Oct. 2025
work page 2025
-
[71]
R. Sambharya and B. Stellato. Learning Algorithm Hyperparameters for Fast Paramet- ric Convex Optimization, Nov. 2024
work page 2024
-
[72]
R. Sambharya and B. Stellato. Data-Driven Performance Guarantees for Classical and Learned Optimizers.Journal of Machine Learning Research, 26(171):1–49, 2025
work page 2025
-
[73]
S. Smale. On the average number of steps of the simplex method of linear programming. Mathematical Programming, 27(3):241–262, Oct. 1983
work page 1983
-
[74]
Q. Song, W. Lin, J. Wang, and H. Xu. Towards Robust Learning to Optimize with Theoretical Guarantees. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27498–27506, 2024
work page 2024
-
[75]
B. Stellato, G. Banjac, P. Goulart, A. Bemporad, and S. Boyd. OSQP: An opera- tor splitting solver for quadratic programs.Mathematical Programming Computation, 12(4):637–672, 2020
work page 2020
- [76]
-
[77]
A. B. Taylor, J. M. Hendrickx, and F. Glineur. Smooth strongly convex interpolation and exact worst-case performance of first-order methods.Mathematical Programming, 161(1-2):307–345, Jan. 2017
work page 2017
-
[78]
Vershynin.High-Dimensional Probability: An Introduction with Applications in Data Science
R. Vershynin.High-Dimensional Probability: An Introduction with Applications in Data Science. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, Cambridge, 2018
work page 2018
-
[79]
W. Wiesemann, D. Kuhn, and M. Sim. Distributionally Robust Convex Optimization. Operations Research, 62(6):1358–1376, Dec. 2014
work page 2014
-
[80]
Z. Xiong. High-Probability Polynomial-Time Complexity of Restarted PDHG for Linear Programming, Jan. 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.