Locally Near Optimal Piecewise Linear Regression in High Dimensions via Difference of Max-Affine Functions
Pith reviewed 2026-05-11 00:49 UTC · model grok-4.3
The pith
The ABGD algorithm recovers piecewise linear functions in high dimensions with near-minimax sample complexity by parametrizing them as differences of max-affine functions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
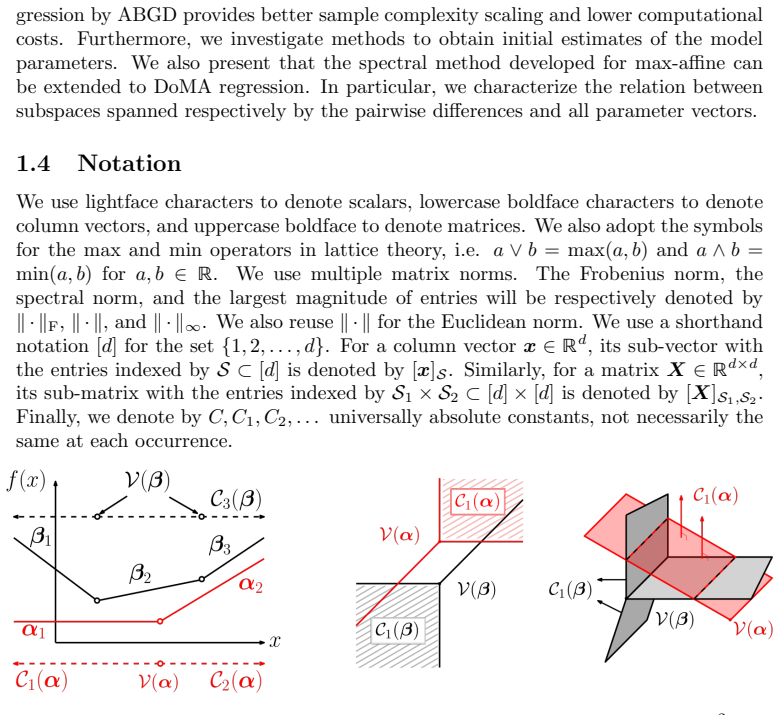
The paper establishes that when a piecewise linear function admits a representation as the difference of max-affine functions, the Adaptive Block Gradient Descent algorithm, suitably initialized, converges linearly to an epsilon-accurate estimate from tilde O(d max(sigma_z / epsilon, 1)^2) observations under sub-Gaussian covariate and noise distributions. This yields exact recovery with tilde O(d) samples in the noiseless case, and the rate is minimax optimal up to log factors. Numerical experiments confirm the guarantees and show competitive performance on real data.
What carries the argument
The difference of max-affine (DoMA) parametrization of piecewise linear functions, which enables adaptive block gradient descent to perform local linear convergence analysis and estimation.
If this is right
- ABGD achieves linear convergence to epsilon accuracy with sample complexity scaling as d times (max(sigma_z/epsilon,1))^2
- Exact recovery of the parameters is possible with order d samples when there is no noise
- The achieved rate matches the minimax lower bound up to logarithmic factors
- Synthetic experiments validate the theoretical sample complexity and convergence rates
- ABGD performs competitively with state-of-the-art methods on real-world regression tasks
Where Pith is reading between the lines
- The method may still work well for approximate DoMA representations of general piecewise linear functions.
- Pairing ABGD with stronger global initializers could widen the basin of attraction.
- Similar difference-based parametrizations might be useful for other structured non-smooth regression tasks.
Load-bearing premise
The piecewise linear target function must be exactly or approximately representable as a difference of max-affine functions and the initialization must land in the basin of attraction for linear convergence.
What would settle it
Observing that ABGD does not achieve linear convergence or requires more than the stated number of samples for epsilon accuracy even in the noiseless case with proper initialization.
Figures




read the original abstract
This paper presents a parametric solution to piecewise linear regression through the Adaptive Block Gradient Descent (ABGD) algorithm. The heart of the method is the parametrization of piecewise linear functions as the difference of max-affine (DoMA) functions. A non-asymptotic local convergence analysis for ABGD is provided under sub-Gaussian covariate and noise distributions. To initialize ABGD, we adapt a prior algorithm originally developed for the simpler setting of max-affine functions. When suitably initialized, ABGD converges linearly to an $\epsilon$-accurate estimate given $\tilde{\mathcal{O}}(d\max(\sigma_z/\epsilon,1)^2)$ observations where $\sigma_z^2$ denotes the noise variance. This implies exact recovery given $\tilde{\mathcal{O}}(d)$ samples in the noiseless case. Also, such a rate is shown to be minimax optimal up to logarithmic factors. Synthetic numerical results corroborate the theoretical guarantees for ABGD. We also observe competitive performance compared to the state-of-the-art methods on real-world datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper introduces the difference of max-affine (DoMA) parametrization for piecewise linear functions and proposes the Adaptive Block Gradient Descent (ABGD) algorithm for high-dimensional piecewise linear regression. It provides a non-asymptotic analysis of local linear convergence for ABGD under sub-Gaussian assumptions, showing that with appropriate initialization, an ε-accurate estimate is obtained with Õ(d max(σ_z/ε,1)^2) samples, implying exact recovery with Õ(d) samples in the noiseless case. The rate is proven minimax optimal up to logarithmic factors, supported by synthetic experiments and competitive real-data results.
Significance. Should the local convergence and optimality results hold, this work contributes a parametric, near-optimal method for piecewise linear regression in high dimensions, extending beyond max-affine models via the DoMA class. The explicit sample complexity, adaptation of initialization, and matching lower bound are valuable for theoretical understanding and practical applications in regression tasks where piecewise linearity is natural. The synthetic corroboration strengthens the claims.
minor comments (2)
- [Abstract] The abstract states that the rate is 'minimax optimal up to logarithmic factors' but provides no indication of the lower-bound construction or the precise norm in which optimality holds; adding a one-sentence pointer to the relevant theorem would improve clarity.
- [Experiments] The synthetic experiments are described as corroborating the theoretical sample complexity, yet the text does not report how the observed convergence scales with d or σ_z relative to the predicted Õ(d max(σ_z/ε,1)^2) bound; including such a scaling plot or table entry would strengthen the empirical support.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and the recommendation for minor revision. We appreciate the recognition of the significance of the DoMA parametrization, the local convergence guarantees for ABGD, and the matching minimax lower bound.
Circularity Check
No significant circularity; minor self-citation in initialization
full rationale
The paper derives its local linear convergence guarantee and sample complexity for ABGD via standard non-convex optimization analysis under explicitly stated assumptions (DoMA representation of the target, sub-Gaussian covariates/noise, and initialization in the basin of attraction). The adaptation of an initialization algorithm from prior max-affine work constitutes at most a minor self-citation that is not load-bearing for the central claims. No step reduces by construction to a fitted parameter, self-definition, or unverified self-citation chain; the minimax lower bound is presented as an independent result. The derivation is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Covariates and noise are sub-Gaussian
invented entities (1)
-
Difference of Max-Affine (DoMA) functions
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Constructive approximation , volume=
A simple proof of the restricted isometry property for random matrices , author=. Constructive approximation , volume=. 2008 , publisher=
work page 2008
-
[2]
Sparse Max Affine Regression , author=. arXiv preprint arXiv:2411.02225 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Visualizable and interpretable regression models with good prediction power , author=. IIE Transactions , volume=. 2007 , publisher=
work page 2007
-
[4]
ARESLab: Adaptive regression splines toolbox for Matlab/Octave , author=. URL: http://www. cs. rtu. lv/jekabsons , year=
-
[5]
International Conference on Machine Learning , pages=
Spectral experts for estimating mixtures of linear regressions , author=. International Conference on Machine Learning , pages=. 2013 , organization=
work page 2013
-
[6]
Advances in neural information processing systems , volume=
Spectral methods meet EM: A provably optimal algorithm for crowdsourcing , author=. Advances in neural information processing systems , volume=
-
[7]
Solving a mixture of many random linear equations by tensor decomposition and alternating minimization , author=. arXiv preprint arXiv:1608.05749 , year=
-
[8]
SIAM Journal on Matrix Analysis and Applications , volume=
On the sum of the largest eigenvalues of a symmetric matrix , author=. SIAM Journal on Matrix Analysis and Applications , volume=. 1992 , publisher=
work page 1992
-
[9]
Fantope projection and selection: A near-optimal convex relaxation of sparse
Vu, Vincent Q and Cho, Juhee and Lei, Jing and Rohe, Karl , journal=. Fantope projection and selection: A near-optimal convex relaxation of sparse
-
[10]
Artificial Intelligence and Statistics , pages=
Provable tensor methods for learning mixtures of generalized linear models , author=. Artificial Intelligence and Statistics , pages=. 2016 , organization=
work page 2016
-
[11]
High-dimensional statistics: A non-asymptotic viewpoint , author=. 2019 , publisher=
work page 2019
-
[12]
Tan, Kai and Shi, Lei and Yu, Zhou , journal=. Sparse. 2020 , publisher=
work page 2020
-
[13]
Communications of the ACM , volume=
CoSaMP: iterative signal recovery from incomplete and inaccurate samples , author=. Communications of the ACM , volume=. 2010 , publisher=
work page 2010
-
[14]
IEEE transactions on information theory , volume=
Decoding by linear programming , author=. IEEE transactions on information theory , volume=. 2005 , publisher=
work page 2005
-
[15]
Proceedings of the IEEE , volume=
Tropical geometry and machine learning , author=. Proceedings of the IEEE , volume=. 2021 , publisher=
work page 2021
-
[16]
International Conference on Machine Learning , pages=
Tropical geometry of deep neural networks , author=. International Conference on Machine Learning , pages=. 2018 , organization=
work page 2018
-
[17]
arXiv preprint arXiv:2309.02046 , year=
A Fast and Provable Algorithm for Sparse Phase Retrieval , author=. arXiv preprint arXiv:2309.02046 , year=
-
[18]
IEEE Transactions on Signal Processing , volume=
Sparse phase retrieval via truncated amplitude flow , author=. IEEE Transactions on Signal Processing , volume=. 2017 , publisher=
work page 2017
-
[19]
The American Statistician , volume=
Hierarchical variable selection in polynomial regression models , author=. The American Statistician , volume=. 1987 , publisher=
work page 1987
-
[20]
The Annals of Statistics , pages=
SPARSITY IN MULTIPLE KERNEL LEARNING , author=. The Annals of Statistics , pages=. 2010 , publisher=
work page 2010
-
[21]
The Annals of Statistics , pages=
HIGH-DIMENSIONAL ADDITIVE MODELING , author=. The Annals of Statistics , pages=. 2009 , publisher=
work page 2009
-
[22]
Journal of the American Statistical Association , volume=
The variable selection problem , author=. Journal of the American Statistical Association , volume=. 2000 , publisher=
work page 2000
- [23]
-
[24]
The Annals of Statistics , pages=
High-Dimensional Variable Selection , author=. The Annals of Statistics , pages=. 2009 , publisher=
work page 2009
-
[25]
On difference convexity of locally
Ba. On difference convexity of locally. Optimization , volume=. 2011 , publisher=
work page 2011
-
[26]
Advances in neural information processing systems , volume=
k-NN regression adapts to local intrinsic dimension , author=. Advances in neural information processing systems , volume=
-
[27]
Advances in neural information processing systems , volume=
Convergence analysis of two-layer neural networks with relu activation , author=. Advances in neural information processing systems , volume=
-
[28]
A comparison of deep networks with ReLU activation function and linear spline-type methods , author=. Neural Networks , volume=. 2019 , publisher=
work page 2019
-
[29]
The Annals of Statistics , pages=
Comparing nonparametric versus parametric regression fits , author=. The Annals of Statistics , pages=. 1993 , publisher=
work page 1993
-
[30]
arXiv preprint arXiv:1906.10221 , year=
Parametric versus semi and nonparametric regression models , author=. arXiv preprint arXiv:1906.10221 , year=
-
[31]
The American Statistician , volume=
Nonlinear regression , author=. The American Statistician , volume=. 1975 , publisher=
work page 1975
-
[32]
Nonlinear regression analysis and its applications , author=. 1988 , publisher=
work page 1988
-
[33]
International conference on machine learning , pages=
Piecewise linear regression via a difference of convex functions , author=. International conference on machine learning , pages=. 2020 , organization=
work page 2020
-
[34]
SIAM Journal on Mathematics of Data Science , volume=
Max-affine regression via first-order methods , author=. SIAM Journal on Mathematics of Data Science , volume=. 2024 , publisher=
work page 2024
- [35]
-
[36]
New concepts in nondifferentiable programming , author=. M. 1979 , publisher=
work page 1979
-
[37]
Applied Economics Letters , volume=
Marginal effects and significance testing with Heckman's sample selection model: a methodological note , author=. Applied Economics Letters , volume=. 2009 , publisher=
work page 2009
-
[38]
Advanced Mathematical Techniques in Computational and Intelligent Systems , author=. 2023 , publisher=
work page 2023
-
[39]
Advances in Neural Information Processing Systems , volume=
Kernel feature selection via conditional covariance minimization , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
Nonparametric sparsity and regularization , author=. 2013 , publisher=
work page 2013
-
[41]
arXiv preprint arXiv:1805.06258 , year=
Structured nonlinear variable selection , author=. arXiv preprint arXiv:1805.06258 , year=
-
[42]
Journal of computational and graphical statistics , volume=
Sparse principal component analysis , author=. Journal of computational and graphical statistics , volume=. 2006 , publisher=
work page 2006
-
[43]
Advances in Neural Information Processing Systems , volume=
Efficient sampling for learning sparse additive models in high dimensions , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
Group sparse additive models , author=. Proceedings of the... International Conference on Machine Learning. International Conference on Machine Learning , volume=. 2012 , organization=
work page 2012
-
[45]
Statistical learning with sparsity: the lasso and generalizations , author=. 2015 , publisher=
work page 2015
-
[46]
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
work page 2000
-
[47]
arXiv preprint arXiv:1505.05114 , year=
Solving random quadratic systems of equations is nearly as easy as solving linear systems , author=. arXiv preprint arXiv:1505.05114 , year=
work page internal anchor Pith review arXiv
-
[48]
International conference on machine learning , pages=
How to escape saddle points efficiently , author=. International conference on machine learning , pages=. 2017 , organization=
work page 2017
-
[49]
Bietti, Alberto and Bruna, Joan and Pillaud-Vivien, Loucas , journal=. On learning
-
[50]
Advances in Neural Information Processing Systems , volume=
Multiclass learning approaches: A theoretical comparison with implications , author=. Advances in Neural Information Processing Systems , volume=
-
[51]
Conference on Learning Theory , pages=
Tight analyses for non-smooth stochastic gradient descent , author=. Conference on Learning Theory , pages=. 2019 , organization=
work page 2019
-
[52]
Journal of machine learning research , volume=
On the algorithmic implementation of multiclass kernel-based vector machines , author=. Journal of machine learning research , volume=
-
[53]
ACM Transactions on Economics and Computation (TEAC) , volume=
Simple mechanisms for a subadditive buyer and applications to revenue monotonicity , author=. ACM Transactions on Economics and Computation (TEAC) , volume=. 2018 , publisher=
work page 2018
-
[54]
Conference on Learning Theory , pages=
Learning simple auctions , author=. Conference on Learning Theory , pages=. 2016 , organization=
work page 2016
-
[55]
International Conference on Machine Learning , pages=
Escaping saddles with stochastic gradients , author=. International Conference on Machine Learning , pages=. 2018 , organization=
work page 2018
- [56]
-
[57]
Siberian Mathematical Journal , volume=
-entropy of convex sets and functions , author=. Siberian Mathematical Journal , volume=. 1976 , publisher=
work page 1976
-
[58]
Entropy of Convex Functions on
Gao, Fuchang and Wellner, Jon A , journal=. Entropy of Convex Functions on. 2017 , publisher=
work page 2017
-
[59]
A Polynomial Time Algorithm for Maximum Likelihood Estimation of Multivariate Log-concave Densities
A polynomial time algorithm for maximum likelihood estimation of multivariate log-concave densities , author=. arXiv preprint arXiv:1812.05524 , year=
-
[60]
Optimality of maximum likelihood for log-concave density estimation and bounded convex regression , author=. arXiv preprint arXiv:1903.05315 , year=
-
[61]
International Conference on Artificial Intelligence and Statistics , pages=
Adaptively Partitioning Max-Affine Estimators for Convex Regression , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2022 , organization=
work page 2022
-
[62]
Optimization and Engineering , volume=
Convex piecewise-linear fitting , author=. Optimization and Engineering , volume=. 2009 , publisher=
work page 2009
-
[63]
Econometrica: Journal of the Econometric Society , pages=
The nonparametric approach to demand analysis , author=. Econometrica: Journal of the Econometric Society , pages=. 1982 , publisher=
work page 1982
-
[64]
International journal of imaging systems and technology , volume=
Three-dimensional support function estimation and application for projection magnetic resonance imaging , author=. International journal of imaging systems and technology , volume=. 2002 , publisher=
work page 2002
-
[65]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Reconstructing convex sets from support line measurements , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 1990 , publisher=
work page 1990
- [66]
-
[67]
Convex-polygon estimation from support-line measurements and applications to target reconstruction from laser-radar data , author=. JOSA A , volume=. 1992 , publisher=
work page 1992
-
[68]
Handbooks in operations research and management science , volume=
Stochastic programming in transportation and logistics , author=. Handbooks in operations research and management science , volume=. 2003 , publisher=
work page 2003
-
[69]
Combinatorial methods in density estimation , author=. 2001 , publisher=
work page 2001
-
[70]
Tighten after Relax: Minimax-Optimal Sparse
Wang, Zhaoran and Lu, Huanran and Liu, Han , booktitle =. Tighten after Relax: Minimax-Optimal Sparse
-
[71]
Siahkamari, Ali and Xia, Xide and Saligrama, Venkatesh and Casta. Learning to approximate a. Advances in Neural Information Processing Systems , volume=
-
[72]
Convex regression: theory, practice, and applications , author=
-
[73]
The Journal of Machine Learning Research , volume=
Multivariate convex regression with adaptive partitioning , author=. The Journal of Machine Learning Research , volume=. 2013 , publisher=
work page 2013
-
[74]
arXiv preprint arXiv:2006.02044 , year=
Convex regression in multidimensions: Suboptimality of least squares estimators , author=. arXiv preprint arXiv:2006.02044 , year=
-
[75]
IEEE Transactions on Information Theory , volume=
Covering numbers for convex functions , author=. IEEE Transactions on Information Theory , volume=. 2012 , publisher=
work page 2012
-
[76]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
An adaptive estimation of dimension reduction space , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2002 , publisher=
work page 2002
- [77]
-
[78]
Upper and lower bounds for stochastic processes , author=. 2014 , publisher=
work page 2014
-
[79]
Journal of the American Statistical Association , volume=
Sliced inverse regression for dimension reduction , author=. Journal of the American Statistical Association , volume=. 1991 , publisher=
work page 1991
-
[80]
Exact and approximation algorithms for sparse
Li, Yongchun and Xie, Weijun , journal=. Exact and approximation algorithms for sparse
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.