Query-efficient model evaluation using cached responses
Pith reviewed 2026-05-11 00:50 UTC · model grok-4.3
The pith
DKPS with cached responses allows benchmark evaluation of new models using far fewer queries while matching baseline accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
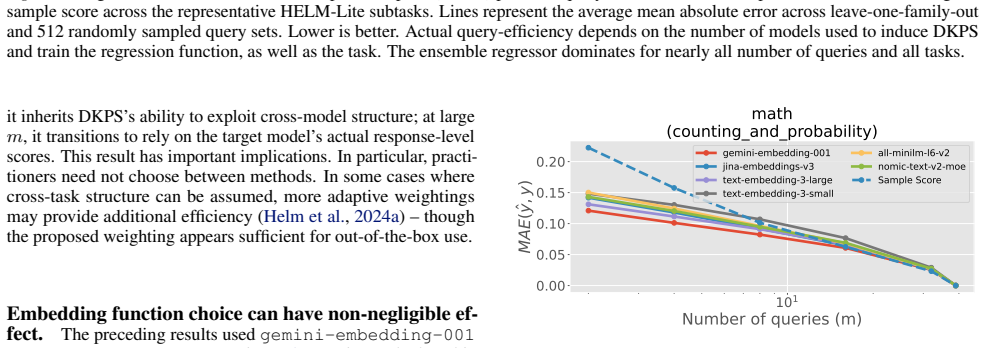
The authors claim that DKPS-based methods achieve the same mean absolute error as baselines with a substantially decreased query budget by leveraging cached model responses. They provide theoretical results on query-efficiency under certain conditions and empirical validation on benchmarks, plus an offline query selection method that improves accuracy over random choice.
What carries the argument
The Data Kernel Perspective Space (DKPS), which quantifies relationships between models in the black-box setting to leverage cached responses for performance prediction.
If this is right
- Benchmark performance can be estimated accurately without querying every test case.
- Existing caches of model responses become a resource for reducing evaluation costs of future models.
- Query selection can be done offline to maximize prediction quality based on reference models.
- The approach applies when theoretical conditions on model similarities hold in practice.
Where Pith is reading between the lines
- Shared evaluation caches could become standard in model development to speed up testing.
- The method might extend to selecting minimal query sets for entire model families.
- It suggests potential for dynamic evaluation strategies that adapt based on observed similarities.
Load-bearing premise
The Data Kernel Perspective Space reliably quantifies black-box relationships between models, allowing the theoretical query-efficiency conditions to hold in actual benchmark evaluations.
What would settle it
An experiment on a standard benchmark where the DKPS method requires the same or more queries than a non-DKPS baseline to achieve equivalent mean absolute error in performance prediction.
Figures




read the original abstract
Evaluating a new model on an existing benchmark is often necessary to understand its behavior before deployment. For modern evaluation frameworks, generating and evaluating a response for all queries can be prohibitively expensive. In practice, responses from previously-evaluated models are often cached -- creating a potential opportunity to use this additional information to decrease the number of queries required to accurately evaluate a new model. In this paper, we introduce an approach for predicting benchmark performance that leverages cached model responses based on the Data Kernel Perspective Space (DKPS), a method for quantifying the relationship between models in the black-box setting. Theoretically, we show that DKPS-based methods are query-efficient under certain conditions. Empirically, we demonstrate that DKPS-based methods achieve the same mean absolute error as baselines with a substantially decreased query budget. We conclude by proposing an offline method for selecting a set of queries that maximizes the goodness-of-fit on reference models, improving prediction accuracy over random query selection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DKPS (Data Kernel Perspective Space) as a black-box method to leverage cached responses from previously evaluated models, enabling query-efficient prediction of a new model's full benchmark score. It provides theoretical conditions under which DKPS-based predictors are query-efficient, demonstrates empirically that they match baseline mean absolute error at substantially lower query budgets, and proposes an offline procedure that selects a fixed query subset by maximizing goodness-of-fit on a reference model cache.
Significance. If the central claims hold, the work offers a practical route to amortize the cost of large-scale benchmarking by reusing cached model outputs, which is increasingly relevant as evaluation budgets grow. The offline query-selection method and the explicit statement of kernel-span conditions are concrete strengths that could be built upon.
major comments (2)
- [Experiments] The empirical protocol (Experiments section) evaluates only models whose response vectors lie inside the linear/kernel span of the cached reference set; no out-of-distribution trials are reported in which the target model belongs to a qualitatively different architecture family or training regime. Because the DKPS coordinate estimation and the claimed MAE preservation both rely on the new model remaining well-conditioned within that span, the absence of such tests makes the general query-efficiency claim load-bearing and unverified.
- [§3] §3 (theoretical analysis): the query-efficiency guarantee is stated to hold “under certain conditions” on the kernel matrix and the target response vector, yet the manuscript does not quantify how often these conditions are satisfied for realistic model caches or provide a diagnostic that practitioners could use to check them before deployment.
minor comments (2)
- [§2] Notation for the DKPS kernel and the projection operator is introduced without an explicit comparison table to standard kernel ridge regression or Nyström approximations; a short side-by-side would clarify the novelty.
- [Abstract] The abstract claims “substantially decreased query budget” but supplies neither the exact reduction factor nor the identity of the strongest baseline; these numbers should appear in the abstract or a prominent table.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the practical relevance of amortizing benchmark costs via cached responses. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Experiments] The empirical protocol (Experiments section) evaluates only models whose response vectors lie inside the linear/kernel span of the cached reference set; no out-of-distribution trials are reported in which the target model belongs to a qualitatively different architecture family or training regime. Because the DKPS coordinate estimation and the claimed MAE preservation both rely on the new model remaining well-conditioned within that span, the absence of such tests makes the general query-efficiency claim load-bearing and unverified.
Authors: We agree that the reported experiments focus on in-span models, which is the setting in which the theoretical guarantees of DKPS hold. The method is explicitly intended for cases where the target response vector lies in the kernel span of the reference cache; out-of-span models are expected to exhibit higher error, consistent with the analysis in §3. To clarify the scope of the query-efficiency claim, we will add a new subsection in the Experiments section that includes out-of-distribution trials using models from qualitatively different architecture families and training regimes. These results will show the anticipated degradation in MAE when the span condition is violated, together with a discussion of how practitioners can detect such cases. This addition will make the boundaries of the method explicit rather than leaving the claim unverified. revision: yes
-
Referee: [§3] §3 (theoretical analysis): the query-efficiency guarantee is stated to hold “under certain conditions” on the kernel matrix and the target response vector, yet the manuscript does not quantify how often these conditions are satisfied for realistic model caches or provide a diagnostic that practitioners could use to check them before deployment.
Authors: We will expand §3 with a new subsection that empirically quantifies the prevalence of the required conditions across the reference caches used in the paper. Concretely, we will report the distribution of kernel-matrix condition numbers, effective ranks, and residual norms of the projection of held-out target vectors onto the span for each benchmark and cache size. In addition, we will define and validate a simple, computable diagnostic: the normalized residual norm of the target response vector after projection onto the cached kernel span (which can be evaluated using only the existing cache before any new queries are made). This diagnostic will be presented with threshold guidelines derived from the empirical distributions, enabling practitioners to decide whether DKPS is likely to be query-efficient for a given new model. revision: yes
Circularity Check
No significant circularity; DKPS derivation and query selection remain independent of target predictions
full rationale
The paper introduces DKPS as a black-box quantification of model relationships, derives query-efficiency under stated theoretical conditions, and empirically shows equivalent MAE at lower query budgets. The offline query-selection procedure optimizes goodness-of-fit explicitly on reference models before applying the reduced set to new models; this is presented as an engineering improvement rather than a statistical tautology. No equations or claims reduce a prediction to a fitted quantity by construction, no load-bearing self-citations close the central argument, and the derivation chain does not rely on renaming or smuggling an ansatz. The result is therefore self-contained against external benchmarks and receives only a minor score for the inherent reference-set dependence of any caching method.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DKPS representations … argmin … (||zi − zj|| − Dii′)² … nearest neighbor regression … Assumption 1 (Lipschitz Score Function)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 2 … MSE(ŷNN) ≤ ε … query-efficient relative to ŷQ
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Learning on LoRAs: GL-Equivariant Processing of Low-Rank Weight Spaces for Large Finetuned Models , author=. 2024 , eprint=
work page 2024
-
[3]
We Should Chart an Atlas of All the World's Models , author=. 2025 , eprint=
work page 2025
-
[4]
Tracking the per- spectives of interacting language models
Helm, Hayden and Duderstadt, Brandon and Park, Youngser and Priebe, Carey. Tracking the perspectives of interacting language models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.90
-
[5]
Statistical inference on black-box generative models in the data kernel perspective space
Helm, Hayden and Acharyya, Aranyak and Park, Youngser and Duderstadt, Brandon and Priebe, Carey. Statistical inference on black-box generative models in the data kernel perspective space. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.204
-
[6]
A probabilistic theory of pattern recognition , author=. 2013 , publisher=
work page 2013
-
[7]
Computational Statistics & Data Analysis , volume=
Automatic dimensionality selection from the scree plot via the use of profile likelihood , author=. Computational Statistics & Data Analysis , volume=. 2006 , publisher=
work page 2006
-
[8]
LoRA: Low-Rank Adaptation of Large Language Models
Lora: Low-rank adaptation of large language models , author=. arXiv preprint arXiv:2106.09685 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Multidimensional scaling: I. Theory and method , author=. Psychometrika , volume=. 1952 , publisher=
work page 1952
- [10]
-
[11]
IEEE Transactions on knowledge and data engineering , volume=
A survey on transfer learning , author=. IEEE Transactions on knowledge and data engineering , volume=. 2009 , publisher=
work page 2009
- [12]
-
[13]
IEEE transactions on pattern analysis and machine intelligence , volume=
Representation learning: A review and new perspectives , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2013 , publisher=
work page 2013
-
[14]
Proceedings of ICML workshop on unsupervised and transfer learning , pages=
Deep learning of representations for unsupervised and transfer learning , author=. Proceedings of ICML workshop on unsupervised and transfer learning , pages=
- [15]
-
[16]
IEEE Transactions on Information Theory , volume=
On divergences and informations in statistics and information theory , author=. IEEE Transactions on Information Theory , volume=. 2006 , publisher=
work page 2006
- [17]
-
[18]
studia scientiarum Mathematicarum Hungarica , volume=
Information-type measures of difference of probability distributions and indirect observation , author=. studia scientiarum Mathematicarum Hungarica , volume=
-
[19]
The annals of statistics , pages=
Consistent nonparametric regression , author=. The annals of statistics , pages=. 1977 , publisher=
work page 1977
-
[20]
Shape quantization and recognition with randomized trees , author=. Neural computation , volume=. 1997 , publisher=
work page 1997
-
[21]
Random forests , author=. Machine learning , volume=. 2001 , publisher=
work page 2001
- [22]
-
[23]
Discriminatory analysis, nonparametric discrimination , author=. 1951 , publisher=
work page 1951
-
[24]
Journal of Machine Learning Research , volume=
Consistency of random forests and other averaging classifiers , author=. Journal of Machine Learning Research , volume=
-
[25]
Approximation capabilities of multilayer feedforward networks , author=. Neural networks , volume=. 1991 , publisher=
work page 1991
- [26]
-
[27]
Advances in neural information processing systems , pages=
On the number of linear regions of deep neural networks , author=. Advances in neural information processing systems , pages=
-
[28]
Priebe, Carey E. and Vogelstein, Joshua T. and Engert, Florian and White, Christopher M. , title =. 2020 , doi =. https://www.biorxiv.org/content/early/2020/04/30/2020.04.29.068460.full.pdf , journal =
work page 2020
-
[29]
Nomic Embed: Training a Reproducible Long Context Text Embedder , author=. 2024 , eprint=
work page 2024
-
[30]
Character-level Convolutional Networks for Text Classification , url =
Zhang, Xiang and Zhao, Junbo and LeCun, Yann , booktitle =. Character-level Convolutional Networks for Text Classification , url =
-
[31]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
The outstanding scientist, RA Fisher: his views on eugenics and race , author=. Heredity , volume=. 2021 , publisher=
work page 2021
-
[33]
Mistral 7B , author=. arXiv preprint arXiv:2310.06825 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell
Dhamala, Jwala and Sun, Tony and Kumar, Varun and Krishna, Satyapriya and Pruksachatkun, Yada and Chang, Kai-Wei and Gupta, Rahul , title =. 2021 , isbn =. doi:10.1145/3442188.3445924 , booktitle =
-
[35]
A Kernel Method for the Two-Sample-Problem , url =
Gretton, Arthur and Borgwardt, Karsten and Rasch, Malte and Sch\". A Kernel Method for the Two-Sample-Problem , url =. Advances in Neural Information Processing Systems , editor =
- [36]
-
[37]
The woman worked as a babysitter: On biases in language generation
The woman worked as a babysitter: On biases in language generation , author=. arXiv preprint arXiv:1909.01326 , year=
-
[38]
Learning from the Worst: Dynamically Generated Datasets to Improve Online Hate Detection , author=. ACL , year=
-
[39]
RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models
Realtoxicityprompts: Evaluating neural toxic degeneration in language models , author=. arXiv preprint arXiv:2009.11462 , year=
work page internal anchor Pith review arXiv 2009
-
[40]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Huggingface's transformers: State-of-the-art natural language processing , author=. arXiv preprint arXiv:1910.03771 , year=
work page internal anchor Pith review arXiv 1910
-
[41]
Eric Eaton and Marie desJardins and Terran Lane , title =. 2008 , pages =
work page 2008
-
[42]
Proceedings of the IEEE International Conference on Computer Vision , pages=
Task2vec: Task embedding for meta-learning , author=. Proceedings of the IEEE International Conference on Computer Vision , pages=
-
[43]
Proceedings of the IEEE International Conference on Computer Vision , pages=
Transferability and hardness of supervised classification tasks , author=. Proceedings of the IEEE International Conference on Computer Vision , pages=
-
[44]
arXiv preprint arXiv:2002.12462 , year=
LEEP: A New Measure to Evaluate Transferability of Learned Representations , author=. arXiv preprint arXiv:2002.12462 , year=
-
[45]
An information-theoretic metric of transferability for task transfer learning , author=
-
[46]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , pages=
P2L: Predicting Transfer Learning for Images and Semantic Relations , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , pages=
-
[47]
Detecting change in data streams , author=
-
[48]
Estimating Information-Theoretic Quantities with Uncertainty Forests , author=. arXiv , pages=
-
[49]
Learning to rank via combining representations , author=. 2020 , eprint=
work page 2020
-
[50]
William M. Rand , title =. Journal of the American Statistical Association , volume =. 1971 , publisher =. doi:10.1080/01621459.1971.10482356 , URL =
-
[51]
Journal of classification , volume=
Comparing partitions , author=. Journal of classification , volume=. 1985 , publisher=
work page 1985
-
[52]
the Journal of machine Learning research , volume=
Scikit-learn: Machine learning in Python , author=. the Journal of machine Learning research , volume=. 2011 , publisher=
work page 2011
-
[53]
Alex Krizhevsky , title =
-
[54]
An Overview of Multi-Task Learning in Deep Neural Networks
An overview of multi-task learning in deep neural networks , author=. arXiv preprint arXiv:1706.05098 , year=
work page internal anchor Pith review arXiv
-
[55]
Multitask learning , author=. Machine learning , volume=. 1997 , publisher=
work page 1997
-
[56]
Journal of artificial intelligence research , volume=
A model of inductive bias learning , author=. Journal of artificial intelligence research , volume=
-
[57]
Learning Theory and Kernel Machines , pages=
Exploiting task relatedness for multiple task learning , author=. Learning Theory and Kernel Machines , pages=. 2003 , publisher=
work page 2003
-
[58]
Journal of Machine Learning Research , volume=
Multi-task learning for classification with dirichlet process priors , author=. Journal of Machine Learning Research , volume=
-
[59]
Energy and Policy Considerations for Deep Learning in NLP
Energy and policy considerations for deep learning in NLP , author=. arXiv preprint arXiv:1906.02243 , year=
work page Pith review arXiv 1906
-
[60]
Classifier technology and the illusion of progress , author=. Statistical science , pages=. 2006 , publisher=
work page 2006
-
[61]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[62]
Visualization in Engineering , volume=
Detection, classification, and mapping of US traffic signs using google street view images for roadway inventory management , author=. Visualization in Engineering , volume=. 2015 , publisher=
work page 2015
-
[63]
Language Models are Few-Shot Learners
Language models are few-shot learners , author=. arXiv preprint arXiv:2005.14165 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[64]
Pattern recognition and machine learning , author=. 2006 , publisher=
work page 2006
-
[65]
Jorg Tiedemann , title =. Proceedings of the Eight International Conference on Language Resources and Evaluation (LREC'12) , year =
-
[66]
Transactions of the Association for Computational Linguistics , volume=
Enriching word vectors with subword information , author=. Transactions of the Association for Computational Linguistics , volume=. 2017 , publisher=
work page 2017
-
[67]
Journal of the Royal Statistical Society: Series A (General) , volume=
A review of hierarchical classification , author=. Journal of the Royal Statistical Society: Series A (General) , volume=. 1987 , publisher=
work page 1987
-
[68]
Data Mining and Knowledge Discovery , volume=
A survey of hierarchical classification across different application domains , author=. Data Mining and Knowledge Discovery , volume=. 2011 , publisher=
work page 2011
-
[69]
International Conference on Medical Imaging with Deep Learning , pages=
Deep hierarchical multi-label classification of chest X-ray images , author=. International Conference on Medical Imaging with Deep Learning , pages=. 2019 , organization=
work page 2019
-
[70]
Journal of Computer and System Sciences , volume=
Hierarchical multi-label classification using local neural networks , author=. Journal of Computer and System Sciences , volume=. 2014 , publisher=
work page 2014
-
[71]
IEEE transactions on neural networks and learning systems , volume=
Mandatory leaf node prediction in hierarchical multilabel classification , author=. IEEE transactions on neural networks and learning systems , volume=. 2014 , publisher=
work page 2014
-
[72]
IEEE Transactions on Pattern Analysis and Machine Intelligence , title=
T. IEEE Transactions on Pattern Analysis and Machine Intelligence , title=. 2002 , volume=
work page 2002
- [73]
-
[74]
The estimation of probabilities: An essay on modern bayesian methods, pp. xi-xii , author=. 1965 , publisher=
work page 1965
-
[75]
Electronic journal of statistics , volume=
Perfect clustering for stochastic blockmodel graphs via adjacency spectral embedding , author=. Electronic journal of statistics , volume=. 2014 , publisher=
work page 2014
-
[76]
Reproducing kernel Hilbert spaces in probability and statistics , author=. 2011 , publisher=
work page 2011
-
[77]
The Journal of Machine Learning Research , volume=
A kernel two-sample test , author=. The Journal of Machine Learning Research , volume=. 2012 , publisher=
work page 2012
-
[78]
Advances in neural information processing systems , pages=
The kernel trick for distances , author=. Advances in neural information processing systems , pages=
-
[79]
Cencheng Shen and Carey E. Priebe and Joshua T. Vogelstein , title =. Journal of the American Statistical Association , volume =. 2020 , publisher =
work page 2020
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.