INO-SGD: Addressing Utility Imbalance under Individualized Differential Privacy
Pith reviewed 2026-05-11 02:59 UTC · model grok-4.3
The pith
INO-SGD down-weights data with stronger privacy needs inside each SGD batch to reduce utility imbalance while keeping individualized differential privacy intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
INO-SGD strategically down-weights data within each batch to improve performance on the more private data across all iterations while satisfying IDP. Existing techniques for fixing utility imbalance do not meet IDP constraints and cannot be adapted without losing those guarantees. The method therefore supplies both the imbalance correction and the required privacy property in one algorithm.
What carries the argument
INO-SGD, a stochastic gradient descent variant that assigns per-sample weights inside each batch according to individual privacy levels to counteract under-representation of high-privacy data.
If this is right
- Trained models achieve higher accuracy on data drawn from the same distribution as the high-privacy subset.
- The privacy loss for each individual remains bounded exactly as required by their chosen privacy parameter.
- No separate post-processing or re-weighting stage is needed after the weighted SGD steps.
- The same batch-wise weighting rule applies uniformly across all training iterations.
Where Pith is reading between the lines
- The weighting rule could be tested on optimizers other than SGD to check whether the imbalance correction generalizes.
- In domains with many privacy tiers the method might reduce the need for separate models per privacy level.
- Deployment pipelines could expose the per-sample weights as an audit log for privacy compliance.
Load-bearing premise
Strategically down-weighting data within each batch will improve performance on more private data across iterations without breaking the individualized privacy guarantees or introducing new imbalances.
What would settle it
A controlled training run in which the down-weighting either produces a measurable privacy violation for some users or leaves accuracy on the high-privacy subset no better than standard IDP-SGD would falsify the central claim.
Figures




















read the original abstract
Differential privacy (DP) is widely employed in machine learning to protect confidential or sensitive training data from being revealed. As data owners gain greater control over their data due to personal data ownership, they are more likely to set their own privacy requirements, necessitating individualized DP (IDP) to fulfil such requests. In particular, owners of data from more sensitive subsets, such as positive cases of stigmatized diseases, likely set stronger privacy requirements, as leakage of such data could incur more serious societal impact. However, existing IDP algorithms induce a critical utility imbalance problem: Data from owners with stronger privacy requirements may be severely underrepresented in the trained model, resulting in poorer performance on similar data from subsequent users during deployment. In this paper, we analyze this problem and propose the INO-SGD algorithm, which strategically down-weights data within each batch to improve performance on the more private data across all iterations. Notably, our algorithm is specially designed to satisfy IDP, while existing techniques addressing utility imbalance neither satisfy IDP nor can be easily adapted to do so. Lastly, we demonstrate the empirical feasibility of our approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes INO-SGD to address utility imbalance under individualized differential privacy (IDP). It observes that data owners with stronger privacy requirements (e.g., sensitive medical cases) cause their samples to be underrepresented in the trained model under standard IDP mechanisms. The algorithm strategically down-weights samples within each batch to boost performance on high-privacy data across iterations, while claiming to be specially designed to satisfy IDP—unlike prior imbalance-correction techniques that neither meet IDP nor adapt easily to it. Empirical results are presented to demonstrate feasibility.
Significance. If the IDP invariant is rigorously established and the utility gains are shown without new privacy violations, the work would meaningfully advance practical deployment of DP in heterogeneous-privacy settings such as healthcare or personalized services. The explicit focus on IDP compliance by design, rather than post-hoc fixes, distinguishes it from existing literature on utility imbalance.
major comments (3)
- [Algorithm and Privacy Analysis sections] The core claim that INO-SGD satisfies IDP while performing batch down-weighting requires that the per-sample sensitivity and noise calibration explicitly incorporate the weights w_i (e.g., noise scaled to max |w_i · clipped ∇ℓ_i| rather than the unweighted clipping bound). No equations or accountant adjustment are visible in the abstract or high-level description to confirm this folding; without it, the privacy loss for low-ε samples can exceed their budget when their relative weight increases.
- [Introduction and Related Work] The assertion that existing imbalance techniques 'neither satisfy IDP nor can be easily adapted' is load-bearing for the novelty claim. The manuscript must demonstrate (via a concrete counter-example or failed adaptation attempt) why standard re-weighting or re-sampling methods cannot be made IDP-compliant by simply adjusting the noise multiplier, rather than asserting non-adaptability at a high level.
- [INO-SGD Algorithm description] The down-weighting rule is described as 'strategically' chosen to improve performance on more private data, yet the selection of w_i appears deterministic from the known privacy vector. It is unclear whether this choice preserves the 'individualized' property across iterations or introduces a new form of imbalance; a formal statement of the weight function and its effect on the gradient expectation is needed.
minor comments (2)
- [Abstract] The abstract states that the approach 'demonstrate[s] the empirical feasibility' but provides no details on datasets, baselines, or metrics; a short summary of the experimental setup would improve readability.
- [Preliminaries and Algorithm] Notation for the privacy vector, per-sample weights, and the resulting sensitivity bound should be introduced consistently in the algorithm section to aid readers unfamiliar with IDP.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments highlight important points on clarity of the privacy analysis, the novelty argument, and the formalization of the weighting scheme. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Algorithm and Privacy Analysis sections] The core claim that INO-SGD satisfies IDP while performing batch down-weighting requires that the per-sample sensitivity and noise calibration explicitly incorporate the weights w_i (e.g., noise scaled to max |w_i · clipped ∇ℓ_i| rather than the unweighted clipping bound). No equations or accountant adjustment are visible in the abstract or high-level description to confirm this folding; without it, the privacy loss for low-ε samples can exceed their budget when their relative weight increases.
Authors: We agree that explicit incorporation of the weights into the sensitivity bound and noise calibration is essential for the IDP guarantee. The full manuscript (Section 4 and Theorem 1) defines the per-sample noise scale as σ_i = (C · w_i) / ε_i, where the weighted gradient norm is used in the sensitivity calculation and the moments accountant is applied per sample. To improve visibility, we will add the explicit weighted sensitivity equation and a short accountant adjustment paragraph to the high-level algorithm description and introduction. revision: yes
-
Referee: [Introduction and Related Work] The assertion that existing imbalance techniques 'neither satisfy IDP nor can be easily adapted' is load-bearing for the novelty claim. The manuscript must demonstrate (via a concrete counter-example or failed adaptation attempt) why standard re-weighting or re-sampling methods cannot be made IDP-compliant by simply adjusting the noise multiplier, rather than asserting non-adaptability at a high level.
Authors: The referee correctly identifies that a concrete demonstration would strengthen the novelty claim. We will add a brief counter-example in the Related Work section (or an appendix) showing that applying standard re-weighting to IDP-SGD without per-sample noise recalibration causes the effective privacy loss for low-ε samples to exceed their budget, computed via the weighted moments accountant. This illustrates why simple multiplier adjustment is insufficient. revision: yes
-
Referee: [INO-SGD Algorithm description] The down-weighting rule is described as 'strategically' chosen to improve performance on more private data, yet the selection of w_i appears deterministic from the known privacy vector. It is unclear whether this choice preserves the 'individualized' property across iterations or introduces a new form of imbalance; a formal statement of the weight function and its effect on the gradient expectation is needed.
Authors: We will insert a formal definition of the weight function: w_i = ε_i / max_{j in batch} ε_j (normalized to preserve batch sum). Because each w_i is computed from the fixed, known per-sample privacy vector and the noise is calibrated individually, the IDP guarantee is preserved across iterations. We will also add a short lemma proving that the weighted gradient estimator remains unbiased in expectation after batch normalization. revision: yes
Circularity Check
No circularity detected; derivation chain self-contained with no reductions to inputs by construction
full rationale
The provided abstract and claims introduce INO-SGD as a new algorithm that down-weights batches to address utility imbalance while satisfying IDP, with the explicit statement that existing imbalance techniques neither satisfy IDP nor adapt easily. No equations, parameter fits, predictions, or derivations are shown that reduce to the inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in the text. The central claim is a design proposal whose validity rests on external verification of the IDP accounting rather than any internal tautology or renaming of known results. This is the normal case of a self-contained algorithmic contribution.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
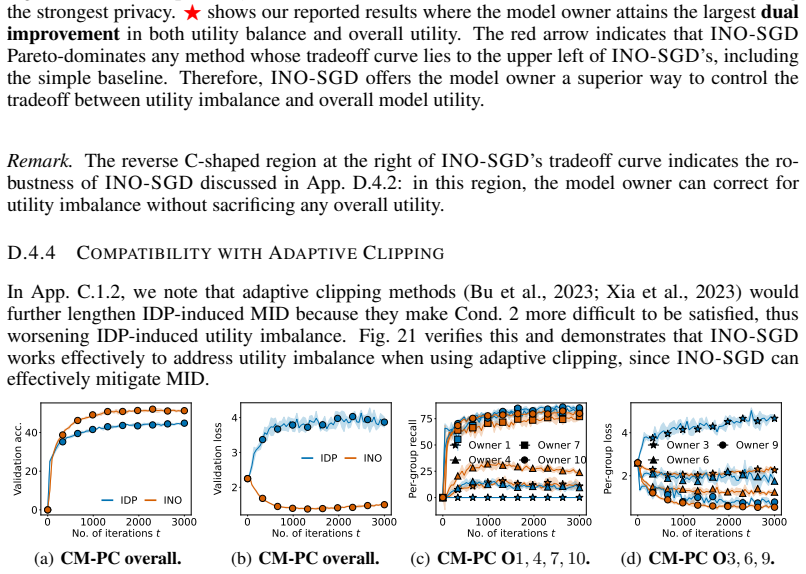
Theorem 3.3 (Privacy of INO-SGD). ... ¯ϵ_n = 2T α_n C_n² q_n² / σ². ... modular sensitivity Δ_d^A at iteration t is bounded by d’s clipping threshold C_o(d).
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
INO-SGD ... strategically down-weights data within each batch ... tail importance function (TIF) f_tail ... batch importance function (BIF) f_t
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Journal of Privacy and Confidentiality , volume=
Heterogeneous Differential Privacy , author=. Journal of Privacy and Confidentiality , volume=
-
[2]
IEEE Transactions on Neural Networks , volume=
An Improved Algorithm for Neural Network Classification of Imbalanced Training Sets , author=. IEEE Transactions on Neural Networks , volume=. 1993 , publisher=
work page 1993
-
[3]
Journal of Privacy and Confidentiality , volume=
Privacy Profiles and Amplification by Subsampling , author=. Journal of Privacy and Confidentiality , volume=
-
[4]
American Sociological Review , volume=
The Stigma of Diseases: Unequal Burden, Uneven Decline , author=. American Sociological Review , volume=. 2023 , publisher=
work page 2023
-
[5]
ACM Computing Surveys , volume=
Fairness in Machine Learning: A Survey , author=. ACM Computing Surveys , volume=. 2024 , publisher=
work page 2024
-
[6]
The economic journal , volume=
The Measurement of the Inequality of Incomes , author=. The economic journal , volume=. 1920 , publisher=
work page 1920
-
[7]
Another look at “cultural fairness” , author=. Journal of educational measurement , volume=. 1971 , publisher=
work page 1971
-
[8]
Distributionally Robust Optimization and Its Tractable Approximations , author=. Operations research , volume=. 2010 , publisher=
work page 2010
-
[9]
IEEE Transactions on Knowledge and Data Engineering , volume=
Learning from Imbalanced Data , author=. IEEE Transactions on Knowledge and Data Engineering , volume=. 2009 , publisher=
work page 2009
-
[10]
Examining the Intersection of Data Privacy and Civil Rights , author=. 2022 , journal=
work page 2022
-
[11]
Differentially private synthetic data via foundation model
Lin, Zinan and Gopi, Sivakanth and Kulkarni, Janardhan and Nori, Harsha and Yekhanin, Sergey , journal=. Differentially private synthetic data via foundation model
-
[12]
ACM Transactions on Knowledge Discovery From Data , volume=
l -Diversity: Privacy Beyond k -Anonymity , author=. ACM Transactions on Knowledge Discovery From Data , volume=. 2007 , publisher=
work page 2007
-
[13]
Identifying medical diagnoses and treatable diseases by image-based deep learning , author=. Cell , volume=. 2018 , publisher=
work page 2018
-
[14]
Learning Multiple Layers of Features from Tiny Images , author=. 2009 , journal=
work page 2009
-
[15]
Proceedings of the IEEE , volume=
Gradient-Based Learning Applied to Document Recognition , author=. Proceedings of the IEEE , volume=. 1998 , publisher=
work page 1998
-
[16]
Incentivizing the Sharing of Healthcare Data in the
Andreas Panagopoulos and Timo Minssen and Katerina Sideri and Helen Yu and Marcelo Corrales Compagnucci , keywords =. Incentivizing the Sharing of Healthcare Data in the. Computer Law & Security Review , volume =. 2022 , issn =. doi:https://doi.org/10.1016/j.clsr.2022.105670 , url =
-
[17]
Pardau, Stuart L , journal=. The. 2018 , publisher=
work page 2018
-
[18]
ACM Computing Surveys (CSUR) , volume=
A Review on Fairness in Machine Learning , author=. ACM Computing Surveys (CSUR) , volume=. 2022 , publisher=
work page 2022
- [19]
-
[20]
Regulation, General Data Protection , journal=. General
-
[21]
Robertson, Sean , journal=
-
[22]
Carnegie Mellon University, Data Privacy , year=
Simple Demographics Often Identify People Uniquely , author=. Carnegie Mellon University, Data Privacy , year=
-
[23]
International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems , volume=
k -Anonymity: A Model for Protecting Privacy , author=. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems , volume=. 2002 , publisher=
work page 2002
- [24]
- [25]
-
[26]
IEEE Transactions on Neural Networks and Learning Systems , volume=
Balancing Learning Model Privacy, Fairness, and Accuracy with Early Stopping Criteria , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. 2021 , publisher=
work page 2021
-
[27]
International Journal of Human-Computer Studies , volume=
Privacy practices of Internet users: Self-reports versus observed behavior , author=. International Journal of Human-Computer Studies , volume=. 2005 , publisher=
work page 2005
-
[28]
Privacy in e-commerce: Stated preferences vs. actual behavior , author=. Communications of the ACM , volume=. 2005 , publisher=
work page 2005
-
[29]
Journal of Machine Learning Research , volume=
Inherent tradeoffs in learning fair representations , author=. Journal of Machine Learning Research , volume=
-
[30]
Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security , pages=
Deep Learning with Differential Privacy , author=. Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security , pages=
work page 2016
-
[31]
On k -Anonymity and the Curse of Dimensionality , author=. Proc. VLDB , volume=
-
[32]
Faster rates of convergence to stationary points in differentially private optimization , author=. Proc. ICML , pages=. 2023 , organization=
work page 2023
-
[33]
Differential Privacy Has Disparate Impact on Model Accuracy , author=. Proc. NeurIPS , volume=
-
[34]
Hypothesis Testing Interpretations and
Balle, Borja and Barthe, Gilles and Gaboardi, Marco and Hsu, Justin and Sato, Tetsuya , booktitle=. Hypothesis Testing Interpretations and
-
[35]
Private stochastic convex optimization with optimal rates , author=. Proc. NeurIPS , volume=
-
[36]
Have It Your Way: Individualized Privacy Assignment for
Boenisch, Franziska and M. Have It Your Way: Individualized Privacy Assignment for. Proc. NeurIPS , volume=
-
[37]
IEEE Symposium on Security and Privacy , pages=
Machine Unlearning , author=. IEEE Symposium on Security and Privacy , pages=
-
[38]
Scalable and efficient training of large convolutional neural networks with differential privacy , author=. Proc. NeurIPS , volume=
-
[39]
Automatic clipping: Differentially private deep learning made easier and stronger , author=. Proc. NeurIPS , volume=
-
[40]
2022 IEEE symposium on security and privacy (SP) , pages=
Membership inference attacks from first principles , author=. 2022 IEEE symposium on security and privacy (SP) , pages=. 2022 , organization=
work page 2022
-
[41]
Big self-supervised models are strong semi-supervised learners , author=. Proc. NeurIPS , volume=
-
[42]
Understanding gradient clipping in private
Chen, Xiangyi and Wu, Steven Z and Hong, Mingyi , booktitle=. Understanding gradient clipping in private
-
[43]
Chen, Yongqiang and Zhou, Kaiwen and Bian, Yatao and Xie, Binghui and Wu, Bingzhe and Zhang, Yonggang and KAILI, MA and Yang, Han and Zhao, Peilin and Han, Bo and others , booktitle=
-
[44]
Das, Rudrajit and Kale, Satyen and Xu, Zheng and Zhang, Tong and Sanghavi, Sujay , booktitle=. Beyond uniform. 2023 , organization=
work page 2023
-
[45]
Differentially private and fair classification via calibrated functional mechanism , author=. Proc. AAAI , volume=
- [46]
-
[47]
Dukler, Yonatan and Bowman, Benjamin and Achille, Alessandro and Golatkar, Aditya and Swaminathan, Ashwin and Soatto, Stefano , booktitle=
-
[48]
Is Fairness Only Metric Deep? Evaluating and Addressing Subgroup Gaps in Deep Metric Learning , author=. Proc. ICLR , year=
-
[49]
International Colloquium on Automata, Languages, and Programming , pages=
Differential Privacy , author=. International Colloquium on Automata, Languages, and Programming , pages=
-
[50]
Our Data, Ourselves: Privacy via Distributed Noise Generation , author=. Advances in Cryptology-EUROCRYPT 2006: 24th Annual International Conference on the Theory and Applications of Cryptographic Techniques , pages=. 2006 , organization=
work page 2006
-
[51]
IEEE 51st Annual Symposium on Foundations of Computer Science , pages=
Boosting and Differential Privacy , author=. IEEE 51st Annual Symposium on Foundations of Computer Science , pages=. 2010 , organization=
work page 2010
-
[52]
Proceedings of the 3rd Innovations in Theoretical Computer Science Conference , pages=
Fairness through awareness , author=. Proceedings of the 3rd Innovations in Theoretical Computer Science Conference , pages=
-
[53]
Disparate Impact in Differential Privacy from Gradient Misalignment , author=. Proc. ICLR , year=
-
[54]
Improved Convergence of Differential Private
Fang, Huang and Li, Xiaoyun and Fan, Chenglin and Li, Ping , booktitle=. Improved Convergence of Differential Private
-
[55]
Proceedings of the 2020 Workshop on Privacy-Preserving Machine Learning in Practice , pages=
Neither private nor fair: Impact of data imbalance on utility and fairness in differential privacy , author=. Proceedings of the 2020 Workshop on Privacy-Preserving Machine Learning in Practice , pages=
work page 2020
-
[56]
A Theoretical Analysis of the Learning Dynamics under Class Imbalance , author=. Proc. ICML , pages=. 2023 , organization=
work page 2023
-
[57]
Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency , pages=
On the Impact of Machine Larning Randomness on Group Fairness , author=. Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency , pages=
work page 2023
-
[58]
Ganev, Georgi and Oprisanu, Bristena and De Cristofaro, Emiliano , booktitle=. 2022 , organization=
work page 2022
-
[59]
Equality of opportunity in supervised learning , author=. Proc. NeurIPS , volume=
-
[60]
Deep Residual Learning for Image Recognition , author=. Proc. CVPR , pages=
-
[61]
Differentially private fair learning , author=. Proc. ICML , pages=. 2019 , organization=
work page 2019
-
[62]
Proceedings of the International Conference on Artificial Intelligence , volume=
The Class Imbalance Problem: Significance and Strategies , author=. Proceedings of the International Conference on Artificial Intelligence , volume=
-
[63]
Kawaguchi, Kenji and Lu, Haihao , booktitle=. Ordered. 2020 , organization=
work page 2020
-
[64]
Imagenet Classification with Deep Convolutional Neural Networks , author=. Proc. NeurIPS , volume=
-
[65]
What you see is what you get: Principled deep learning via distributional generalization , author=. Proc. NeurIPS , volume=
-
[66]
Proceedings of the IEEE international conference on computer vision , pages=
Deeper, Broader and Artier Domain Generalization , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[67]
Li, Haochuan and Rakhlin, Alexander and Jadbabaie, Ali , booktitle=. Convergence of
-
[68]
Workshop on Algorithmic Fairness through the Lens of Causality and Privacy , pages=
Stochastic differentially private and fair learning , author=. Workshop on Algorithmic Fairness through the Lens of Causality and Privacy , pages=. 2023 , organization=
work page 2023
-
[69]
51st Annual Allerton Conference on Communication, Control, and Computing , pages=
Privacy-Utility Tradeoff Under Statistical Uncertainty , author=. 51st Annual Allerton Conference on Communication, Control, and Computing , pages=. 2013 , organization=
work page 2013
-
[70]
Mitigating Disparate Impact of Differential Privacy in Federated Learning through Robust Clustering , author=. Proc. CVPR Causal and Object-Centric Representations for Robotics Workshop , year=
-
[71]
Mironov, Ilya , booktitle=
-
[72]
Nearly tight black-box auditing of differentially private machine learning , author=. Proc. NeurIPS , volume=
-
[73]
Proceedings of the 2nd International Conference on Computing Advancements , pages=
Class Imbalance Problems in Machine Learning: A Review of Methods and Future Challenges , author=. Proceedings of the 2nd International Conference on Computing Advancements , pages=
-
[74]
Annals of Operations Research , volume=
Multiple Criteria Linear Programming Model for Portfolio Selection , author=. Annals of Operations Research , volume=. 2000 , publisher=
work page 2000
-
[75]
Tempered Sigmoid Activations for Deep Learning with Differential Privacy , author=. Proc. AAAI , volume=
-
[76]
Group-robust Sample Reweighting for Subpopulation Shifts via Influence Functions , author=. Proc. ICLR , year=
-
[77]
Focal loss for dense object detection , author=. Proc. ICCV , pages=
-
[78]
Minimizing the Maximal Loss: How and why , author=. Proc. ICML , pages=. 2016 , organization=
work page 2016
-
[79]
IEEE Symposium on Security and Privacy , pages=
Membership Inference Attacks Against Machine Learning Models , author=. IEEE Symposium on Security and Privacy , pages=. 2017 , organization=
work page 2017
-
[80]
Training Region-Based Object Detectors with Online Hard Example Mining , author=. Proc. CVPR , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.