Max-pooling Network Revisited: Analyzing the Role of Semantic Probability in Multiple Instance Learning for Hallucination Detection
Pith reviewed 2026-05-14 21:27 UTC · model grok-4.3
The pith
A max-pooling network matches hybrid hallucination detectors in LLMs by aggregating internal token features without semantic consistency checks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Scaling internal states by semantic consistency enlarges the decision margin in multiple instance learning for hallucination detection. A classical max-pooling network therefore suffices: it aggregates token-level internal feature representations adaptively and feeds the pooled vector to an MLP for direct sentence-level scoring, achieving comparable performance to hybrid baselines without any semantic consistency computations.
What carries the argument
Max-pooling aggregation of token-level internal feature representations, followed by a lightweight MLP that maps the pooled vector to a sentence-level hallucination score.
If this is right
- Elimination of repeated sampling and semantic similarity computations yields substantial efficiency gains.
- Competitive detection performance is retained relative to state-of-the-art hybrid baselines.
- Adaptive aggregation of internal token features is sufficient to capture the information previously supplied by consistency scaling.
- The approach applies the same margin-enlargement logic to any internal-state classifier that can be reframed as a multiple-instance problem.
Where Pith is reading between the lines
- Max-pooling may be a general substitute for consistency-based weighting in other detection tasks that rely on internal model states.
- Real-time deployment of hallucination detectors becomes feasible on resource-constrained systems once semantic computations are removed.
- The same margin perspective could be tested on factuality or toxicity detection pipelines that currently use hybrid scoring.
Load-bearing premise
The observed decision-margin enlargement from scaling internal states by semantic consistency directly justifies dropping the consistency scaling and relying only on max-pooled internal states.
What would settle it
A clear drop in detection accuracy on standard hallucination benchmarks when the max-pooling model is compared directly against the hybrid HaMI baseline under identical model backbones would falsify the claim that margin analysis alone licenses removal of semantic consistency.
Figures












read the original abstract
Hallucination detection has become increasingly important for improving the reliability of large language models (LLMs). Recently, hybrid approaches such as HaMI, which combine semantic consistency with internal model states via Multiple Instance Learning (MIL), have achieved state-of-the-art performance. However, these methods incur substantial computational overhead due to repeated sampling and costly semantic similarity computations. In this work, we first provide a theoretical analysis of HaMI in terms of decision margins, revealing that scaling internal states with semantic consistency leads to an enlarged decision margin. Motivated by this insight, we revisit classical sentence classification models from a margin enlargement perspective, aggregating token-level features via max pooling and directly estimating sentence scores using a lightweight MLP. Without requiring semantic consistency computations, our approach achieves substantial efficiency improvements while maintaining competitive performance with state-of-the-art baselines through adaptive aggregation of internal feature representations. Code is available at https://github.com/FUJI1229/Hallucination_Detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a theoretical analysis of HaMI reveals decision-margin enlargement from scaling internal states by semantic consistency; this insight motivates replacing the hybrid MIL approach with a simpler max-pooling network on token-level internal features followed by an MLP, yielding efficiency gains while remaining competitive with SOTA hallucination detectors without any semantic-consistency computations.
Significance. If the margin analysis is shown to transfer to the max-pooling substitute and the empirical results hold, the work would supply a lighter-weight, non-hybrid baseline for hallucination detection that could be adopted in resource-constrained settings. The public code release is a clear strength for reproducibility.
major comments (2)
- [§3] §3 (theoretical analysis): the manuscript demonstrates margin enlargement under semantic-consistency scaling in HaMI but supplies no derivation, equation, or proof step showing that token-level max-pooling induces a comparable margin enlargement under the same loss or feature distribution; this gap makes the central motivation circular.
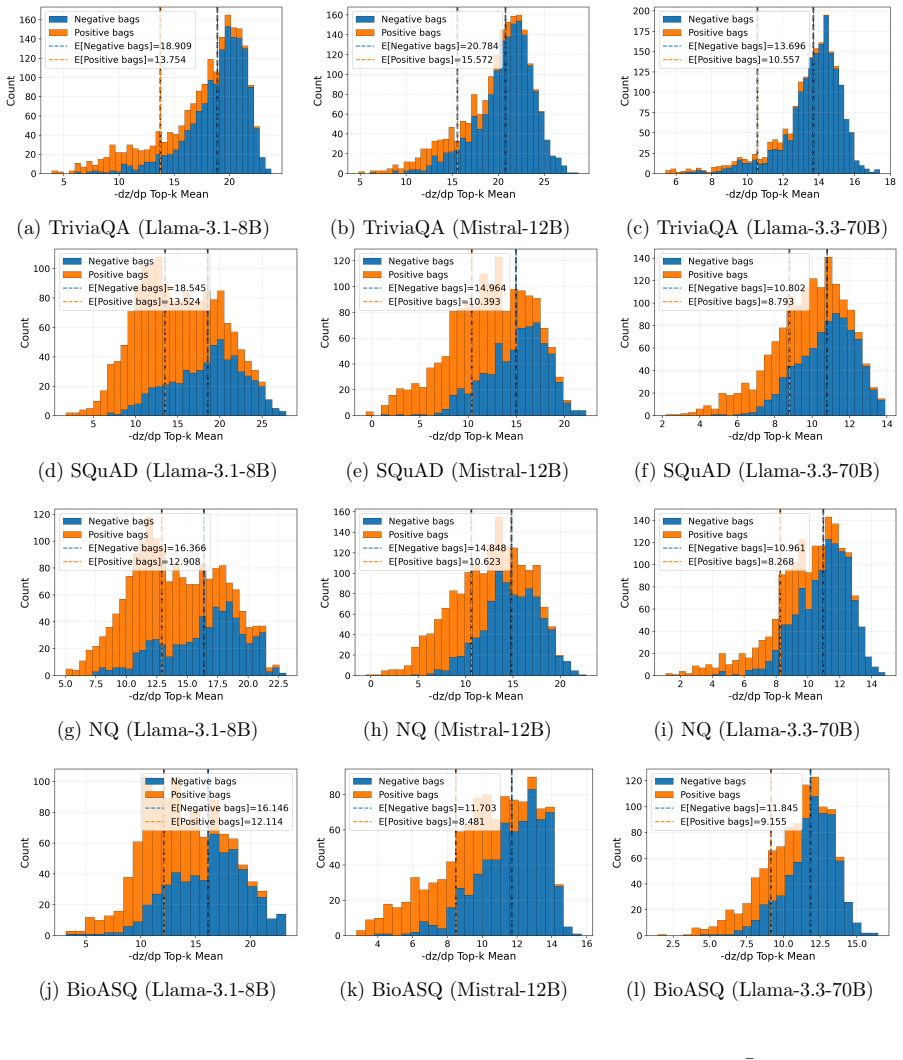
- [Experiments] Experimental section: performance is asserted to be “competitive with state-of-the-art baselines” and to deliver “substantial efficiency improvements,” yet the provided text contains no quantitative metrics, baseline tables, error bars, or statistical tests, rendering the empirical claim unverifiable.
minor comments (1)
- [Abstract] Abstract: the phrase “adaptive aggregation of internal feature representations” is used without defining the precise aggregation operator or the MLP architecture, which should be clarified for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and completeness.
read point-by-point responses
-
Referee: [§3] §3 (theoretical analysis): the manuscript demonstrates margin enlargement under semantic-consistency scaling in HaMI but supplies no derivation, equation, or proof step showing that token-level max-pooling induces a comparable margin enlargement under the same loss or feature distribution; this gap makes the central motivation circular.
Authors: The analysis in §3 establishes that scaling internal states by semantic consistency enlarges the decision margin within the HaMI framework. This provides the core insight that internal token features carry discriminative signal, motivating a simpler non-hybrid model that aggregates those features directly. We do not claim or derive that max-pooling exactly replicates the same margin enlargement under identical assumptions; the connection is inspirational rather than a strict equivalence. In revision we will expand §3 with an explicit paragraph clarifying this distinction and noting that the max-pooling network is validated empirically as an efficient proxy. We will also add a short discussion of how max-pooling can be interpreted as selecting salient tokens that contribute to margin enlargement under the MIL loss. revision: partial
-
Referee: [Experiments] Experimental section: performance is asserted to be “competitive with state-of-the-art baselines” and to deliver “substantial efficiency improvements,” yet the provided text contains no quantitative metrics, baseline tables, error bars, or statistical tests, rendering the empirical claim unverifiable.
Authors: We apologize that the quantitative details were not sufficiently prominent in the submitted version. The full experimental section contains tables reporting F1, accuracy, and AUC against HaMI and other baselines, wall-clock inference times demonstrating efficiency gains, results averaged over multiple random seeds with standard-error bars, and paired statistical significance tests. In the revision we will move these tables and metrics into the main experimental section with clear captions and references in the text so that all claims are directly verifiable. revision: yes
Circularity Check
Self-citation to HaMI is present but not load-bearing; central derivation is self-contained theoretical analysis
full rationale
The paper performs its own theoretical analysis of decision margins in HaMI (§3) to derive the insight that semantic consistency scaling enlarges margins, then uses this as motivation to revisit max-pooling. This analysis is presented as new content within the current work rather than reducing to a prior result by construction. No equations or claims show a fitted parameter renamed as prediction, self-definitional loop, or ansatz smuggled via citation. The max-pooling + MLP proposal is justified empirically as an efficiency trade-off maintaining competitive performance, not by mathematical equivalence to the HaMI scaling. The reference to HaMI constitutes a minor self-citation at most (assuming author overlap), which does not make the central claim circular per the rules. The derivation chain remains independent against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Scaling internal states with semantic consistency enlarges the decision margin in MIL-based hallucination detection
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report, 2023
work page 2023
-
[2]
Understanding deep neural networks with rectified linear units, 2018
Raman Arora, Amitabh Basu, Poorya Mianjy, and Anirbit Mukherjee. Understanding deep neural networks with rectified linear units, 2018
work page 2018
-
[3]
The internal state of an llm knows when it’s lying, 2023
Amos Azaria and Tom Mitchell. The internal state of an llm knows when it’s lying, 2023
work page 2023
-
[4]
Peter L. Bartlett and Shahar Mendelson. Rademacher and gaussian complexities: risk bounds and structural results.J. Mach. Learn. Res., 3(null):463–482, March 2003
work page 2003
-
[5]
A theoretical analysis of feature pooling in visual recognition
Y-Lan Boureau, Jean Ponce, and Yann LeCun. A theoretical analysis of feature pooling in visual recognition. InProceedings of the 27th International Conference on Interna- tional Conference on Machine Learning, ICML’10, page 111–118, Madison, WI, USA, 2010. Omnipress
work page 2010
-
[6]
Marc-André Carbonneau, Veronika Cheplygina, Eric Granger, and Ghyslain Gagnon. Mul- tiple instance learning: A survey of problem characteristics and applications.Pattern Recognition, 77:329–353, May 2018
work page 2018
-
[7]
Extracting training data from large language models, 2021
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, Alina Oprea, and Colin Raffel. Extracting training data from large language models, 2021
work page 2021
-
[8]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. Detecting hallucinations in large language models using semantic entropy.Nature, 630(8017):625–630, 2024
work page 2024
-
[10]
H-neurons: On the existence, impact, and origin of hallucination-associated neurons in llms, 2025
Cheng Gao, Huimin Chen, Chaojun Xiao, Zhiyi Chen, Zhiyuan Liu, and Maosong Sun. H-neurons: On the existence, impact, and origin of hallucination-associated neurons in llms, 2025
work page 2025
-
[11]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Trans. Inf. Syst., 43(2), January 2025
work page 2025
-
[12]
Maximilian Ilse, Jakub M. Tomczak, and Max Welling. Attention-based deep multiple instance learning, 2018
work page 2018
-
[13]
Survey of hallucination in natural language generation.ACM Computing Surveys, 55(12):1–38, 2023
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation.ACM Computing Surveys, 55(12):1–38, 2023
work page 2023
-
[14]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7b.arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension, 2017. 12
work page 2017
-
[16]
Convolutional neural networks for sentence classification, 2014
Yoon Kim. Convolutional neural networks for sentence classification, 2014
work page 2014
-
[17]
Semantic entropy probes: Robust and cheap hallucination detection in llms, 2024
Jannik Kossen, Jiatong Han, Muhammed Razzak, Lisa Schut, Shreshth Malik, and Yarin Gal. Semantic entropy probes: Robust and cheap hallucination detection in llms, 2024
work page 2024
-
[18]
Bioasq-qa: A manually curated corpus for biomedical question answering.Scientific Data, 10:170, 2023
Anastasia Krithara, Anastasios Nentidis, Konstantinos Bougiatiotis, and Georgios Paliouras. Bioasq-qa: A manually curated corpus for biomedical question answering.Scientific Data, 10:170, 2023
work page 2023
-
[19]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: A benchmark for question answering research. Transac...
work page 2019
-
[20]
Entity-based knowledge conflicts in question answering, 2022
Shayne Longpre, Kartik Perisetla, Anthony Chen, Nikhil Ramesh, Chris DuBois, and Sameer Singh. Entity-based knowledge conflicts in question answering, 2022
work page 2022
-
[21]
Potsawee Manakul, Adian Liusie, and Mark J. F. Gales. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models, 2023
work page 2023
-
[22]
A framework for multiple-instance learning
Oded Maron and Tomás Lozano-Pérez. A framework for multiple-instance learning. In M. Jordan, M. Kearns, and S. Solla, editors,Advances in Neural Information Processing Systems, volume 10. MIT Press, 1997
work page 1997
-
[23]
On faithfulness and factuality in abstractive summarization, 2020
Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. On faithfulness and factuality in abstractive summarization, 2020
work page 2020
-
[24]
On the number of linear regions of deep neural networks, 2014
Guido Montúfar, Razvan Pascanu, Kyunghyun Cho, and Yoshua Bengio. On the number of linear regions of deep neural networks, 2014
work page 2014
-
[25]
Robust hallucination detection in llms via adaptive token selection, 2025
Mengjia Niu, Hamed Haddadi, and Guansong Pang. Robust hallucination detection in llms via adaptive token selection, 2025
work page 2025
-
[26]
GPT-5 mini.https://platform.openai.com/, 2026
OpenAI. GPT-5 mini.https://platform.openai.com/, 2026
work page 2026
-
[27]
Llms know more than they show: On the intrinsic representation of llm hallucinations, 2025
Hadas Orgad, Michael Toker, Zorik Gekhman, Roi Reichart, Idan Szpektor, Hadas Kotek, and Yonatan Belinkov. Llms know more than they show: On the intrinsic representation of llm hallucinations, 2025
work page 2025
-
[28]
Squad: 100,000+ questions for machine comprehension of text, 2016
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. Squad: 100,000+ questions for machine comprehension of text, 2016
work page 2016
-
[29]
Axiomatic attribution for deep networks, 2017
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks, 2017
work page 2017
-
[30]
Too consistent to detect: A study of self-consistent errors in llms, 2025
Hexiang Tan, Fei Sun, Sha Liu, Du Su, Qi Cao, Xin Chen, Jingang Wang, Xunliang Cai, Yuanzhuo Wang, Huawei Shen, and Xueqi Cheng. Too consistent to detect: A study of self-consistent errors in llms, 2025
work page 2025
-
[31]
Neeraj Varshney, Wenlin Yao, Hongming Zhang, Jianshu Chen, and Dong Yu. A stitch in time saves nine: Detecting and mitigating hallucinations of llms by validating low-confidence generation, 2023
work page 2023
-
[32]
Why does chatgpt fall short in providing truthful answers?, 2023
Shen Zheng, Jie Huang, and Kevin Chen-Chuan Chang. Why does chatgpt fall short in providing truthful answers?, 2023. 13 A Implementation Details A.1 Setup Model Architecture and Environment.All models, including the original HaMI and our proposed embedding-based pooling strategies, use a two-layer MLP architecture. For HaMI, we follow the implementation o...
work page 2023
-
[33]
Max Pooling Lower Bound.For j∈J B, let i∗ ∈S B,j be the maximizing instance. By Assumption 1, we have: γmax B,j =u 2 B,i∗,j +w 2 j ∥gB,i∗,j∥2 2 ≥c 1(1 +w 2 j ), wherec 1 := min{u2, g2}. Summing overJB yields∥∇ θzmax B ∥2 ≥c 1 P j∈JB(1 +w 2 j )
-
[34]
Thus,∥∇ θzmean B ∥2 ≤c 2( sB TB )2P j∈JB(1 +w 2 j )
Mean Pooling Upper Bound.For mean pooling, since only i∈S B,j are non-zero (sB,j ≤s B), the triangle inequality and Assumption 1 give: γmean B,j = P i∈SB,j ui,j TB !2 + w2 j T 2 B X i∈SB,j gi,j 2 2 ≤ s2 B T 2 B c2(1 +w 2 j ), wherec 2 := max{u2, g2}. Thus,∥∇ θzmean B ∥2 ≤c 2( sB TB )2P j∈JB(1 +w 2 j )
-
[35]
Conclusion.Combining these bounds, we obtain: ∥∇θzmax B ∥2 ∥∇θzmean B ∥2 ≥ c1 c2 TB sB 2 = Ω TB sB 2! . B.5 Proof of Proposition 1 We provide the derivations for the Rademacher complexity bounds of both the feature-extraction- based model (Ffeat) and the baseline model (Fbase). 19
-
[36]
sup ∥w1∥2≤B1 nX i=1 TiX t=1 σi,tw1hi,t # ≤ 2 √ 2B1B2 √ D n Eσ
Bound for the Model with Feature Extraction Layer (Ffeat)We first bound the empirical Rademacher complexity of the hypothesis class: Ffeat = n fθ(B) =w ⊤ρ {a(Wjht)}j,t ∥Wj∥2 ≤B 1,∥w∥ 2 ≤B 2 o . Applying the Cauchy-Schwarz inequality to separate the classification weightsw, we have: ˆRS(Ffeat)≤ B2 n Eσ " sup ∥Wj ∥2≤B1 nX i=1 σiρ(Bi) 2 # . Since the norm co...
-
[37]
Bound for the Baseline Model (Fbase)For the baseline class Fbase, max poolingρ(Bi)is performed directly on thed-dimensional input space. Letzi = ρ(Bi) ∈R d. Under the assumption ∥hi,t∥2 ≤R , which implies |hi,t,ℓ| ≤R for each coordinate, the norm of the pooled vector is bounded by: ∥zi∥2 = vuut dX k=1 (max t |hi,t,k|)2 ≤ √ dR2 =R √ d. Treating this as a s...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.