BatchWeave: A Consistent Object-Store-Native Data Plane for Large Foundation Model Training
Pith reviewed 2026-05-19 17:51 UTC · model grok-4.3
The pith
BatchWeave builds a consistent object-store-native data plane that delivers atomic all-rank batch visibility and exactly-once recovery for distributed foundation model training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
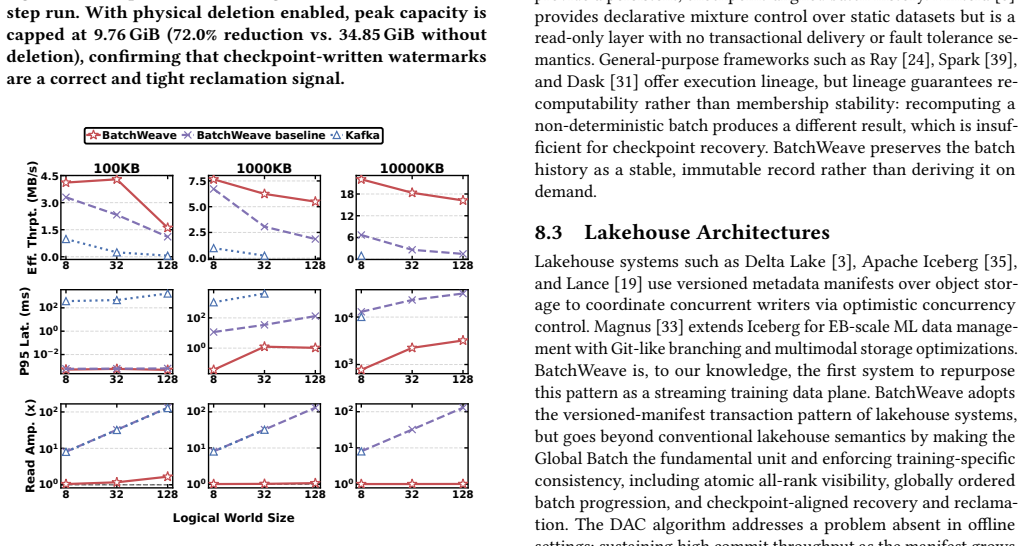
BatchWeave uses versioned manifests and conditional object writes to coordinate batch publication, recovery, and lifecycle management in an object-store-native data plane. It introduces the Transactional Global Batch, which builds on versioned-manifest ACID storage semantics and adds training-specific consistency including atomic all-rank batch visibility, a globally ordered step sequence, checkpoint-aligned lifecycle management, and end-to-end exactly-once recovery. Recovery and retention are realized directly in the storage layer by durably persisting producer state through the commit protocol and tying reclamation to distributed checkpoint state. Its Decentralized Adaptive Commitalgorithm
What carries the argument
The Transactional Global Batch (TGB) that extends versioned-manifest ACID storage semantics with training-specific consistency guarantees such as atomic all-rank batch visibility, globally ordered steps, and checkpoint-aligned lifecycle management.
If this is right
- Training frameworks can separate data loading from compute nodes while preserving consistency and fault isolation.
- Object stores can replace message queues for batch ingestion without sacrificing speed or introducing coordination bottlenecks.
- Data retention policies can be tied directly to training checkpoints, reducing unnecessary storage during long runs.
- Exactly-once recovery becomes a storage-layer property, simplifying fault handling in large-scale pre-training jobs.
Where Pith is reading between the lines
- The design could generalize to other distributed systems that need batch-level consistency guarantees over commodity object storage.
- Cluster operators might simplify architectures by moving more coordination logic into the storage service itself.
- Smaller-scale experiments on 8- or 16-GPU setups could test whether the throughput and latency advantages hold before full 64-GPU deployment.
Load-bearing premise
Object stores can deliver the versioned-manifest ACID semantics and conditional-write performance needed for atomic all-rank batch visibility and checkpoint-aligned lifecycle management without introducing latency or throughput penalties that would erase the reported gains over colocated and Kafka baselines.
What would settle it
A head-to-head run of the 64-GPU multimodal pre-training workload in which BatchWeave fails to exceed colocated dataloader throughput or Apache Kafka ingestion throughput while still providing full failure isolation and lower consumer read latency.
Figures









read the original abstract
Modern Large Foundation Model (LFM) training has transformed the data pipeline from a static ingestion layer into a dynamic component that must co-evolve with the training process. Existing systems are ill-equipped: colocated dataloaders offer no failure isolation, while message queue-based disaggregated dataloaders operate on a record/offset abstraction that cannot express the batch-level semantics required by distributed training. We present BatchWeave, an object-store-native training data plane for distributed LFM training. BatchWeave uses versioned manifests and conditional object writes to coordinate batch publication, recovery, and lifecycle management. First, it introduces the Transactional Global Batch (TGB), which builds on versioned-manifest ACID storage semantics and extends them with training-specific consistency, including atomic all-rank batch visibility, a globally ordered step sequence, checkpoint-aligned lifecycle management, and end-to-end exactly-once recovery. Second, it realizes recovery and retention directly in the storage layer, by durably persisting producer state through the commit protocol and tying reclamation to distributed checkpoint state. Third, its Decentralized Adaptive Commit (DAC) algorithm sustains stable ingestion throughput as the manifest grows, without any inter-producer communication. Evaluations on large-scale multimodal pre-training and SFT workloads using 64 GPUs show that BatchWeave outperforms colocated dataloader throughput while providing full failure isolation, outperforms Apache Kafka in ingestion throughput, and achieves lower consumer read latency than Kafka.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents BatchWeave as an object-store-native data plane for large foundation model training. It leverages versioned manifests and conditional object writes to implement the Transactional Global Batch (TGB) construct, which provides atomic all-rank batch visibility, globally ordered step sequences, checkpoint-aligned lifecycle management, and exactly-once recovery. The Decentralized Adaptive Commit (DAC) algorithm is introduced to maintain stable ingestion throughput as manifests grow without inter-producer communication. Evaluations on multimodal pre-training and SFT workloads using 64 GPUs claim that BatchWeave exceeds colocated dataloader throughput with full failure isolation, surpasses Apache Kafka in ingestion throughput, and delivers lower consumer read latency than Kafka.
Significance. Should the performance and consistency claims be substantiated, this work would represent a meaningful advance in disaggregated data planes for distributed ML training. By shifting coordination to object store primitives, it offers a path to better failure isolation and scalability compared to traditional colocated or queue-based approaches. The integration of training-specific semantics like checkpoint alignment directly into the storage layer is a promising direction that could influence future system designs in the field.
major comments (3)
- [§5 (Evaluation)] The performance results for the 64-GPU multimodal and SFT workloads are presented without error bars, detailed workload specifications, or exclusion criteria. This omission makes it difficult to assess whether the reported gains in throughput and latency are statistically robust or influenced by specific experimental conditions.
- [§3.1 (TGB)] The assumption that object stores can deliver versioned-manifest ACID semantics and conditional-write performance at the rates required for training batches without introducing penalties that offset the gains is load-bearing for the central claim. The manuscript compares overall system performance to baselines but does not provide isolated measurements of manifest operation overheads or conditional write latencies under sustained load.
- [§4 (DAC)] The DAC algorithm is claimed to sustain stable throughput without inter-producer communication, but the scaling behavior with manifest size and the impact of object store list operation consistency models are not sufficiently analyzed to confirm it avoids the eventual consistency issues common in object stores.
minor comments (2)
- [Abstract] The abstract mentions 'large-scale' workloads but could benefit from specifying the exact model sizes or dataset characteristics for context.
- [Throughout] Ensure consistent use of acronyms like TGB and DAC upon first introduction in the main text.
Simulated Author's Rebuttal
We are grateful to the referee for their detailed and insightful comments, which have helped us improve the clarity and rigor of our evaluation and analysis sections. We address each major comment below, indicating the revisions we have made or will make in the next version of the manuscript.
read point-by-point responses
-
Referee: [§5 (Evaluation)] The performance results for the 64-GPU multimodal and SFT workloads are presented without error bars, detailed workload specifications, or exclusion criteria. This omission makes it difficult to assess whether the reported gains in throughput and latency are statistically robust or influenced by specific experimental conditions.
Authors: We agree with this observation and have revised the manuscript to include error bars on all throughput and latency figures in Section 5, representing the standard deviation across at least five independent runs for each data point. We have also expanded the workload specifications to include precise details on dataset composition, batch sizes, sequence lengths, and the exact hardware configuration for the 64-GPU setup. Additionally, we now describe the exclusion criteria, which were limited to runs affected by transient hardware faults unrelated to the data plane. These changes should allow readers to better evaluate the statistical robustness of our results. revision: yes
-
Referee: [§3.1 (TGB)] The assumption that object stores can deliver versioned-manifest ACID semantics and conditional-write performance at the rates required for training batches without introducing penalties that offset the gains is load-bearing for the central claim. The manuscript compares overall system performance to baselines but does not provide isolated measurements of manifest operation overheads or conditional write latencies under sustained load.
Authors: This is a valid point regarding the need for more granular performance data. While the end-to-end evaluations demonstrate that any overheads are outweighed by the benefits, we have added isolated microbenchmark results in a new subsection of §3.1. These measure the latency and throughput of versioned manifest operations and conditional writes under sustained load matching our training batch rates. The results confirm that these primitives introduce negligible overhead compared to the overall system gains, supporting the central claim without offsetting penalties. revision: yes
-
Referee: [§4 (DAC)] The DAC algorithm is claimed to sustain stable throughput without inter-producer communication, but the scaling behavior with manifest size and the impact of object store list operation consistency models are not sufficiently analyzed to confirm it avoids the eventual consistency issues common in object stores.
Authors: We acknowledge that a more detailed analysis of scaling and consistency would strengthen the presentation. In the revised manuscript, we have extended Section 4 with additional experiments plotting ingestion throughput against increasing manifest sizes up to the maximum observed in our workloads. We also include a discussion of the object store's consistency model (strong consistency for list operations in the evaluated setup) and how the DAC algorithm's design—relying on conditional writes rather than list operations for critical paths—mitigates potential eventual consistency issues. This analysis confirms stable throughput without inter-producer communication. revision: yes
Circularity Check
No significant circularity detected; design and claims are self-contained
full rationale
The paper introduces architectural components (TGB extending versioned-manifest ACID semantics, DAC algorithm for commit without inter-producer communication) and supports performance claims via direct empirical evaluation against external baselines (colocated dataloaders, Apache Kafka) on 64-GPU workloads. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described derivation. The central claims rest on implementation details and comparative measurements rather than reducing to self-defined inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Object stores can support versioned manifests and conditional object writes with ACID properties suitable for training coordination.
invented entities (2)
-
Transactional Global Batch (TGB)
no independent evidence
-
Decentralized Adaptive Commit (DAC)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Transactional Global Batch (TGB) ... atomic all-rank batch visibility, a globally ordered step sequence, checkpoint-aligned lifecycle management, and end-to-end exactly-once recovery
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Decentralized Adaptive Commit (DAC) algorithm sustains stable ingestion throughput as the manifest grows, without any inter-producer communication
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Tyler Akidau, Robert Bradshaw, Craig Chambers, Slava Chernyak, Rafael J Dagum, Sam Knight, Frances Perry, Reiner Schmidt, and Sam Whittle. 2015. The dataflow model: a practical approach to balancing correctness, latency, and BatchWeave: A Consistent Object-Store-Native Data Plane for Large Foundation Model Training cost in massive-scale, unbounded, out-of...
work page 2015
-
[3]
Michael Armbrust, Tathagata Das, Liwen Sun, Burak Yavuz, Shixiong Zhu, Mukul Murthy, Joseph Torres, Herman van Hovell, Adrian Ionescu, Bogdan Ghit, Mad- hukara Bhat, Reynold Xin, Ali Ghodsi, Ion Stoica, and Matei Zaharia. 2020. Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores. Proceedings of the VLDB Endowment (PVLDB)13, 12 (2020),...
work page 2020
-
[4]
Michael Armbrust, Tathagata Das, Joseph Torres, Burak Yavuz, Shixiong Liao, Yin Huai, Hossein Hosseini, Matei Zaharia, and Reynold Xin. 2018. Structured streaming: A declarative api for real-time applications in apache spark. InPro- ceedings of the 2018 International Conference on Management of Data (SIGMOD). Association for Computing Machinery, New York,...
work page 2018
-
[5]
Andrew Audibert, Yang Chen, Dan Graur, Ana Klimovic, Jiri Simsa, and Chan- dramohan A. Thekkath. 2023. tf.data service: A Case for Disaggregating ML Input Data Processing. InProceedings of the 2023 ACM Symposium on Cloud Computing (SoCC). Association for Computing Machinery, New York, NY, USA, 358–375
work page 2023
-
[6]
AutoMQ Team. 2024. AutoMQ: Cloud-Native Streaming with Offloaded Storage. https://www.automq.com
work page 2024
-
[7]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Maximilian Böther, Xiaozhe Yao, Tolga Kerimoglu, Dan Graur, Viktor Gsteiger, and Ana Klimovic. 2026. Mixtera: A Data Plane for Foundation Model Training. Proc. ACM Manag. Data4, 1 (April 2026). doi:10.1145/3786668
-
[9]
Remi Cadene, Simon Alibert, Alexander Soare, Quentin Gallouedec, Adil Zoui- tine, Steven Palma, Pepijn Kooijmans, Michel Aractingi, Mustafa Shukor, Dana Aubakirova, Martino Russi, Francesco Capuano, Caroline Pascal, Jade Choghari, Jess Moss, and Thomas Wolf. 2024. LeRobot: State-of-the-art Machine Learning for Real-World Robotics in PyTorch. https://githu...
work page 2024
-
[10]
Paris Carbone, Asterios Katsifodimos, Stephan Ewen, Volker Markl, Seif Haridi, and Kostas Kostas. 2015. Apache Flink™: Stream processing at scale.ACM SIGMOD Record44, 4 (2015), 28–39
work page 2015
-
[11]
DeepSeek-AI. 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Dan Graur, Damien Aymon, Dan Kluser, Tanguy Albrici, Chandramohan A. Thekkath, and Ana Klimovic. 2022. Cachew: Machine Learning Input Data Processing as a Service. InProceedings of the 2022 USENIX Annual Technical Conference (USENIX ATC). USENIX Association, Berkeley, CA, USA, 689–706
work page 2022
-
[13]
Dan Graur, Oto Mraz, Muyu Li, Sepehr Pourghannad, Chandramohan A. Thekkath, and Ana Klimovic. 2024. Pecan: Cost-Efficient ML Data Preprocessing with Automatic Transformation Ordering and Hybrid Placement. InProceed- ings of the 2024 USENIX Annual Technical Conference (USENIX ATC). USENIX Association, Berkeley, CA, USA, 649–665
work page 2024
-
[14]
Gabriel Ilharco, Mitchell Wortsman, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt. 2021. OpenCLIP. doi:10.5281/zenodo.5143773
-
[15]
Uber Technologies Inc. 2018. Petastorm: Open source library to enable training deep learning models from Apache Parquet datasets. https://github.com/uber/ petastorm
work page 2018
-
[16]
Van Jacobson. 1988. Congestion Avoidance and Control. InSymposium Proceed- ings on Communications Architectures and Protocols (SIGCOMM ’88). Association for Computing Machinery, New York, NY, USA, 314–329. doi:10.1145/52324.52356
-
[17]
Taeyoon Kim, Youngbin Jeong, Myeongjae Jang, and Jong-Geun Lee. 2023. Fu- sionFlow: Accelerating Data Preprocessing for Machine Learning with CPU-GPU Cooperation.Proceedings of the VLDB Endowment (PVLDB)17, 3 (2023), 488–502
work page 2023
-
[18]
Jay Kreps, Neha Narkhede, and Jun Rao. 2011. Kafka: A Distributed Messaging System for Log Processing. InProceedings of the 4th International Workshop on Networking Meets Databases (NetDB). Association for Computing Machinery, New York, NY, USA, 1–7
work page 2011
-
[19]
Lance Format. 2025. Lance. https://github.com/lance-format/lance/
work page 2025
-
[20]
Chengshu Li, Ruohan Zhang, Josiah Wong, Cem Gokmen, Sanjana Srivastava, Roberto Martín-Martín, Chen Wang, Gabrael Levine, Michael Lingelbach, Jiankai Sun, Mona Anvari, Minjune Hwang, Manasi Sharma, Arman Aydin, Dhruva Bansal, Samuel Hunter, Kyu-Young Kim, Alan Lou, Caleb R Matthews, Ivan Villa-Renteria, Jerry Huayang Tang, Claire Tang, Fei Xia, Silvio Sav...
work page 2023
-
[21]
Jiahao Li, Biao Cao, Jielong Jian, Cheng Li, Sen Han, Yiduo Wang, Yufei Wu, Kang Chen, Zhihui Yin, Qiushi Chen, Jiwei Xiong, Jie Zhao, Fengyuan Liu, Yan Xing, Liguo Duan, Miao Yu, Ran Zheng, Feng Wu, and Xianjun Meng. 2025. Mantle: Efficient Hierarchical Metadata Management for Cloud Object Storage Services. InProceedings of the ACM SIGOPS 31st Symposium ...
-
[22]
Matteo Merli, Sijie Guo, Penghui Li, Hang Chen, and Neng Lu. 2025. Ursa: A Lakehouse-Native Data Streaming Engine for Kafka.Proceedings of the VLDB Endowment (PVLDB)18, 12 (2025), 5184–5196
work page 2025
-
[23]
Jayashree Mohan, Amar Phanishayee, Janardhan Kulkarni, and Vijay Chi- dambaram. 2021. CoorDL: Co-ordinated Data Loading for Deep Learning. In Proceedings of the 2021 USENIX Annual Technical Conference (USENIX ATC). USENIX Association, Berkeley, CA, USA, 305–319
work page 2021
-
[24]
Philipp Moritz, Robert Nishihara, Stephanie Wang, Alexey Tumanov, Richard Liaw, Eric Liang, Melih Elibol, Zongheng Yang, William Paul, Michael I. Jordan, and Ion Stoica. 2018. Ray: A Distributed Framework for Emerging AI Applications. InProceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI). USENIX Association, Berk...
work page 2018
-
[25]
MosaicML. 2023. StreamingDataset: A high-performance dataset for deep learn- ing. https://github.com/mosaicml/streaming
work page 2023
-
[26]
Murray, Jiří Šimša, Ana Klimovic, and Ihor Indyk
Derek G. Murray, Jiří Šimša, Ana Klimovic, and Ihor Indyk. 2021. tf.data: a machine learning data processing framework.Proc. VLDB Endow.14, 12 (July 2021), 2945–2958. doi:10.14778/3476311.3476374
-
[27]
NVIDIA, :, Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi "Jim" Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, Y...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Christiano, Jan Leike, and Ryan Lowe
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schul- man, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with huma...
work page 2022
-
[29]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gre- gory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. 2019. PyTorch: An Imperative Style, Hi...
work page 2019
-
[30]
PyTorch Team. 2025. torch.distributed.checkpoint Documentation. https:// pytorch.org/docs/stable/distributed.checkpoint.html
work page 2025
-
[31]
Matthew Rocklin. 2015. Dask: Parallel computation with blocked algorithms and task scheduling. InProceedings of the 14th Python in Science Conference, Vol. 130. SciPy, Austin, TX, USA, 136
work page 2015
-
[32]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Jun Song, Jingyi Ding, Irshad Kandy, Yanghao Lin, Zhongjia Wei, Zilong Zhou, Zhiwei Peng, Jixi Shan, Hongyue Mao, Xiuqi Huang, Xun Song, Cheng Chen, Yanjia Li, Tianhao Yang, Wei Jia, Xiaohong Dong, Kang Lei, Rui Shi, Pengwei Zhao, and Wei Chen. 2025. Magnus: A Holistic Approach to Data Management for Large-Scale Machine Learning Workloads.Proc. VLDB Endow...
-
[34]
The Apache Software Foundation. 2015. Apache Pulsar. https://pulsar.apache. org
work page 2015
-
[35]
The Apache Software Foundation. 2025. Apache Iceberg. https://iceberg.apache. org/
work page 2025
-
[36]
Taegeon Um, Goeun Byun, Hwarim Choi, Mincheol Han, and Hyuck Park. 2023. FastFlow: Accelerating Deep Learning Model Training with Smart Offloading of Input Data Pipeline.Proceedings of the VLDB Endowment (PVLDB)16, 11 (2023), 1086–1099
work page 2023
-
[37]
Xin Wang, Taein Kwon, Mahdi Rad, Bowen Pan, Ishani Chakraborty, Sean Andrist, Dan Bohus, Ashley Feniello, Bugra Tekin, Felipe Vieira Frujeri, Neel Joshi, and Marc Pollefeys. 2023. HoloAssist: an Egocentric Human Interaction Dataset for Interactive AI Assistants in the Real World. https://openaccess.thecvf. com/content/ICCV2023/html/Wang_HoloAssist_an_Egoc...
work page 2023
-
[38]
WarpStream Labs. 2025. WarpStream: A Cloud-Native, Zero-Disk Apache Kafka Alternative. https://www.warpstream.com
work page 2025
-
[39]
Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J Franklin, Scott Shenker, and Ion Stoica. 2012. Re- silient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing. In9th USENIX Symposium on Networked Systems Design and Imple- mentation (NSDI 12). USENIX Association, Berkeley, C...
work page 2012
-
[40]
Juntao Zhao, Qi Lu, Wei Jia, Borui Wan, Lei Zuo, Junda Feng, Jianyu Jiang, Yangrui Chen, Shuaishuai Cao, Jialing He, Kaihua Jiang, Yuanzhe Hu, Shibiao Nong, Yanghua Peng, Haibin Lin, and Chuan Wu. 2026. MegaScale-Data: Scaling Dataloader for Multisource Large Foundation Model Training. https://arxiv.org/ abs/2504.09844
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[41]
Mark Zhao, Emanuel Adamiak, and Christos Kozyrakis. 2024. Cedar: Optimized and Unified Machine Learning Input Data Pipelines.Proceedings of the VLDB Endowment (PVLDB)18, 2 (2024), 488–502
work page 2024
-
[42]
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, Alban Desmaison, Can Balioglu, Pritam Damania, Bernard Nguyen, Geeta Chauhan, Yuchen Hao, Ajit Mathews, and Shen Li. 2023. PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel.Proc. VLDB Endow.16, 12 (2023), 3848–386...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.