Recognition: 2 theorem links
· Lean TheoremQwen-Image-2.0 Technical Report
Pith reviewed 2026-05-12 04:16 UTC · model grok-4.3
The pith
Qwen-Image-2.0 unifies high-fidelity image generation and precise editing by coupling Qwen3-VL with a Multimodal Diffusion Transformer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
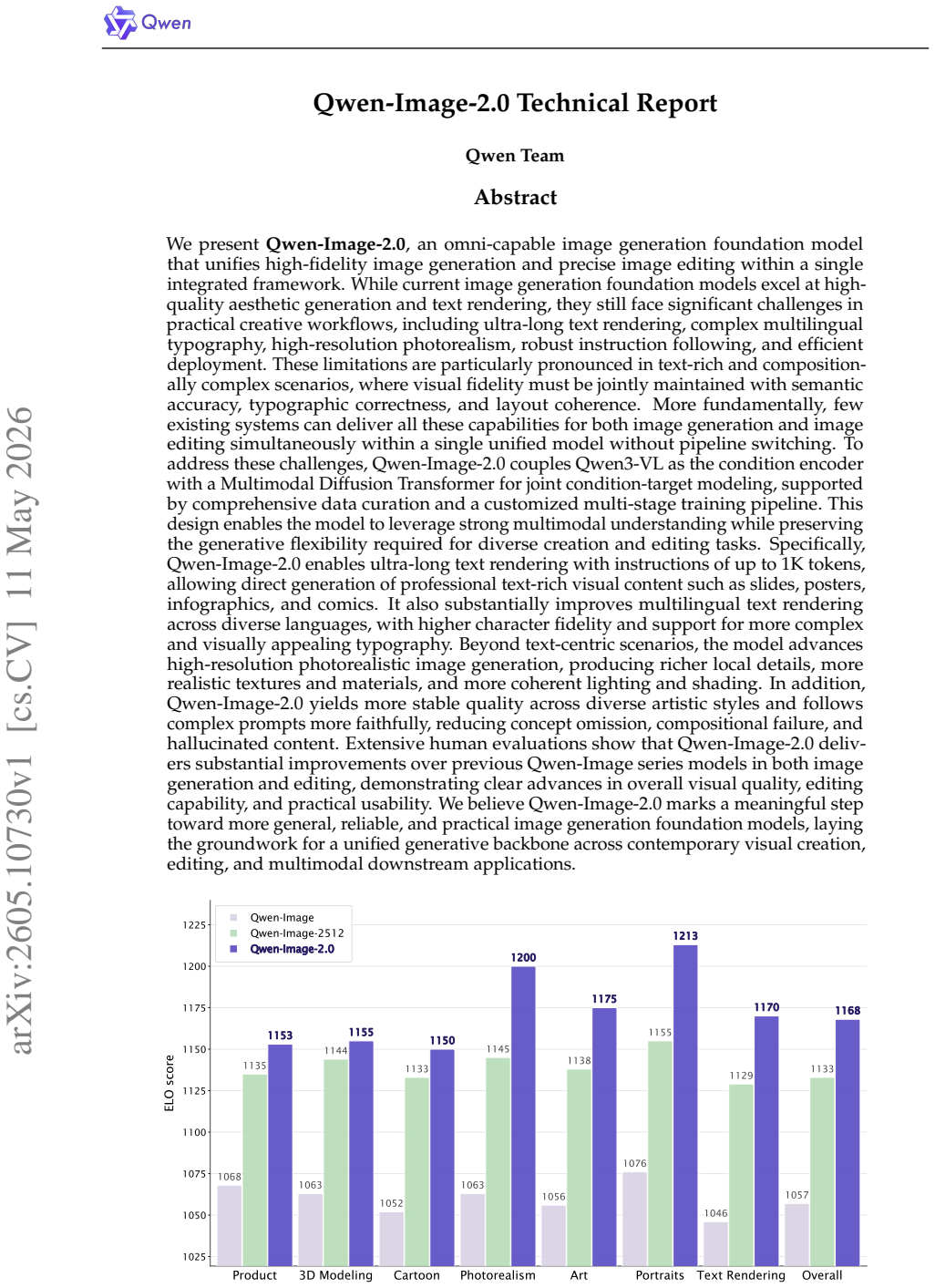
Qwen-Image-2.0 addresses limitations in ultra-long text rendering, multilingual typography, high-resolution photorealism, and instruction following by integrating Qwen3-VL as the condition encoder with a Multimodal Diffusion Transformer for joint condition-target modeling, supported by large-scale data curation and a customized multi-stage training pipeline, enabling strong multimodal understanding while preserving flexible generation and editing capabilities, with extensive human evaluations showing substantial outperformance over previous Qwen-Image models.
What carries the argument
Coupling of Qwen3-VL as condition encoder with Multimodal Diffusion Transformer for joint condition-target modeling.
If this is right
- The model accepts prompts up to 1K tokens and produces coherent text-rich outputs such as slides, posters, infographics, and comics.
- Multilingual text rendering and typography improve markedly over prior versions.
- Photorealistic images gain richer details, more accurate textures, and consistent lighting.
- Complex prompts are followed more reliably across varied artistic styles.
- Both pure generation and targeted editing tasks show higher success rates in human preference tests.
Where Pith is reading between the lines
- If the joint modeling pattern generalizes, similar encoder-transformer pairings could be tested on video or 3D content creation.
- The absence of component ablations leaves open the question of how much each part contributes, which future experiments could isolate.
- Practitioners may find the 1K-token prompt length useful for generating structured documents without post-processing.
- Scaling the same data-curation and training recipe to larger backbones could further reduce failure modes on edge cases like dense typography.
Load-bearing premise
That the performance gains result specifically from the Qwen3-VL coupling, multimodal diffusion transformer, and multi-stage training rather than from untested factors such as overall data volume or compute.
What would settle it
A controlled comparison in which Qwen-Image-2.0 is retrained without the Qwen3-VL encoder or without the staged training pipeline, followed by the same human evaluations, showing no measurable improvement in text fidelity or editing accuracy.
Figures


















read the original abstract
We present Qwen-Image-2.0, an omni-capable image generation foundation model that unifies high-fidelity generation and precise image editing within a single framework. Despite recent progress, existing models still struggle with ultra-long text rendering, multilingual typography, high-resolution photorealism, robust instruction following, and efficient deployment, especially in text-rich and compositionally complex scenarios. Qwen-Image-2.0 addresses these challenges by coupling Qwen3-VL as the condition encoder with a Multimodal Diffusion Transformer for joint condition-target modeling, supported by large-scale data curation and a customized multi-stage training pipeline. This enables strong multimodal understanding while preserving flexible generation and editing capabilities. The model supports instructions of up to 1K tokens for generating text-rich content such as slides, posters, infographics, and comics, while significantly improving multilingual text fidelity and typography. It also enhances photorealistic generation with richer details, more realistic textures, and coherent lighting, and follows complex prompts more reliably across diverse styles. Extensive human evaluations show that Qwen-Image-2.0 substantially outperforms previous Qwen-Image models in both generation and editing, marking a step toward more general, reliable, and practical image generation foundation models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Qwen-Image-2.0, an omni-capable image generation foundation model that unifies high-fidelity generation and precise editing. It couples Qwen3-VL as the condition encoder with a Multimodal Diffusion Transformer for joint condition-target modeling, supported by large-scale data curation and a customized multi-stage training pipeline. The model is claimed to improve ultra-long text rendering, multilingual typography, photorealism, and complex instruction following (up to 1K tokens), with extensive human evaluations showing substantial outperformance over prior Qwen-Image models in both generation and editing.
Significance. If the empirical claims hold, the work advances practical image foundation models by demonstrating a unified architecture for generation and editing that handles text-rich, multilingual, and compositionally complex content more reliably. The emphasis on scalable training and data curation for real-world usability could inform subsequent efforts in multimodal generative systems.
major comments (3)
- [Evaluation] Evaluation section: The central claim that 'extensive human evaluations show that Qwen-Image-2.0 substantially outperforms previous Qwen-Image models' is presented without any quantitative metrics, baseline details beyond prior versions, evaluation protocol (e.g., prompt sets, rater instructions, number of comparisons), or statistical significance testing. This leaves the headline empirical result unverifiable and weakens the paper's primary contribution.
- [Model Architecture] Model Architecture and Training sections: The improvements are attributed to the specific coupling of Qwen3-VL with the Multimodal Diffusion Transformer plus the multi-stage training and data curation, yet no ablation studies, controlled variants, or component-isolation experiments are reported. Without these, alternative explanations (e.g., scale, data distribution shifts) cannot be ruled out, making the architectural claims load-bearing but unsupported.
- [Training Pipeline] Training Pipeline section: The customized multi-stage training is described at a high level without specifics on per-stage objectives, data mixtures, loss formulations, or how each stage targets the listed challenges (ultra-long text, photorealism). This prevents assessment of whether the pipeline is responsible for the reported gains.
minor comments (2)
- [Abstract] The abstract states support for 'instructions of up to 1K tokens' but provides no implementation details, context-length handling, or empirical limits on this capability.
- Notation for the Multimodal Diffusion Transformer and condition encoding mechanism would benefit from an explicit equation or diagram on first introduction to improve clarity for readers unfamiliar with the exact formulation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for improving the transparency and rigor of our technical report. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The central claim that 'extensive human evaluations show that Qwen-Image-2.0 substantially outperforms previous Qwen-Image models' is presented without any quantitative metrics, baseline details beyond prior versions, evaluation protocol (e.g., prompt sets, rater instructions, number of comparisons), or statistical significance testing. This leaves the headline empirical result unverifiable and weakens the paper's primary contribution.
Authors: We agree that the current presentation of human evaluation results is insufficiently detailed for full verifiability. In the revised manuscript, we will expand the Evaluation section with a dedicated subsection on the protocol. This will include: the composition and size of the prompt sets (covering text-rich, multilingual, photorealistic, and complex instruction categories), the number of expert raters, the exact instructions and rating scales provided to them, the total number of pairwise comparisons, win-rate percentages with 95% confidence intervals, and results from statistical significance tests (e.g., paired t-tests or McNemar's test). We will also clarify that baselines include prior Qwen-Image versions as well as selected open models where direct comparisons were feasible. revision: yes
-
Referee: [Model Architecture] Model Architecture and Training sections: The improvements are attributed to the specific coupling of Qwen3-VL with the Multimodal Diffusion Transformer plus the multi-stage training and data curation, yet no ablation studies, controlled variants, or component-isolation experiments are reported. Without these, alternative explanations (e.g., scale, data distribution shifts) cannot be ruled out, making the architectural claims load-bearing but unsupported.
Authors: We acknowledge that the lack of explicit ablation studies limits the ability to isolate the precise contribution of the Qwen3-VL coupling versus other factors such as scale or data. Full-scale ablations on a model of this size are computationally prohibitive and were not performed. In the revision, we will add a discussion subsection that explains the architectural rationale, drawing on internal smaller-scale experiments and failure-mode analysis from Qwen-Image-1.0. We will also highlight how the joint condition-target modeling in the Multimodal Diffusion Transformer directly enables the observed gains in text rendering and instruction following, as evidenced by the comparative human evaluations against prior versions. revision: partial
-
Referee: [Training Pipeline] Training Pipeline section: The customized multi-stage training is described at a high level without specifics on per-stage objectives, data mixtures, loss formulations, or how each stage targets the listed challenges (ultra-long text, photorealism). This prevents assessment of whether the pipeline is responsible for the reported gains.
Authors: We agree that greater specificity on the training pipeline would improve reproducibility and allow readers to better assess the source of improvements. In the revised version, we will expand the Training Pipeline section to describe the objectives of each stage (e.g., initial alignment on broad image-text data, targeted fine-tuning for typography and photorealism), approximate data mixture proportions across stages, the primary loss formulations (including any auxiliary terms for text fidelity), and the progressive targeting of challenges such as ultra-long text rendering and coherent lighting. Certain proprietary details regarding exact data sources will remain summarized at a high level. revision: yes
Circularity Check
No circularity: empirical performance claims rest on human evaluations, not derivations or self-referential fits
full rationale
The paper describes an architecture (Qwen3-VL coupled to Multimodal Diffusion Transformer) and training pipeline, then asserts outperformance via human evaluations. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claim reduces to comparative preference data rather than any quantity defined in terms of itself or forced by prior author work. This is the expected non-finding for an empirical model report without mathematical reduction steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A Multimodal Diffusion Transformer can jointly model condition and target for both generation and editing tasks.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
couples Qwen3-VL as the condition encoder with a Multimodal Diffusion Transformer for joint condition-target modeling, supported by large-scale data curation and a customized multi-stage training pipeline
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Extensive human evaluations show that Qwen-Image-2.0 substantially outperforms previous Qwen-Image models
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Qwen-Image-VAE-2.0 Technical Report
Qwen-Image-VAE-2.0 achieves state-of-the-art high-compression image reconstruction and superior diffusability for diffusion models, with a new text-rich document benchmark.
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai. arXiv preprint arXiv:2501.03575,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
URLhttps://arena.ai/leaderboard. Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025a. Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhon...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Zhaohui Hou, Shijie Huang, Dengyang Jiang, Xin Jin, Liangchen Li, et al. Z-image: An efficient image generation foundation model with single-stream diffusion transformer.arXiv preprint arXiv:2511.22699,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Hunyuanimage 3.0 technical report.arXiv preprint arXiv:2509.23951, 2025
Siyu Cao, Hangting Chen, Peng Chen, Yiji Cheng, Yutao Cui, Xinchi Deng, Ying Dong, Kipper Gong, Tianpeng Gu, Xiusen Gu, et al. Hunyuanimage 3.0 technical report.arXiv preprint arXiv:2509.23951,
-
[5]
Pixart-alpha: Fast training of diffusion transformer for photorealistic text-to-image synthesis
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart-alpha: Fast training of diffusion transformer for photorealistic text-to-image synthesis. InInternational conference on learning representations, volume 2024, pp. 57611– 57640,
work page 2024
-
[6]
1Alphabetical order. 2Alphabetical order. 27 Junyu Chen, Han Cai, Junsong Chen, Enze Xie, Shang Yang, Haotian Tang, Muyang Li, and Song Han. Deep compression autoencoder for efficient high-resolution diffusion models. InInternational Conference on Learning Representations, volume 2025, pp. 96539–96560,
work page 2025
-
[7]
Yu Gao, Lixue Gong, Qiushan Guo, Xiaoxia Hou, Zhichao Lai, Fanshi Li, Liang Li, Xiaochen Lian, Chao Liao, Liyang Liu, et al. Seedream 3.0 technical report.arXiv preprint arXiv:2504.11346,
work page internal anchor Pith review arXiv
-
[8]
Mean Flows for One-step Generative Modeling
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J Zico Kolter, and Kaiming He. Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Lixue Gong, Xiaoxia Hou, Fanshi Li, Liang Li, Xiaochen Lian, Fei Liu, Liyang Liu, Wei Liu, Wei Lu, Yichun Shi, et al. Seedream 2.0: A native chinese-english bilingual image generation foundation model. arXiv preprint arXiv:2503.07703,
-
[10]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Zhimin Li, Jianwei Zhang, Qin Lin, Jiangfeng Xiong, Yanxin Long, Xinchi Deng, Yingfang Zhang, Xingchao Liu, Minbin Huang, Zedong Xiao, et al. Hunyuan-dit: A powerful multi-resolution diffusion transformer with fine-grained chinese understanding.arXiv preprint arXiv:2405.08748,
-
[15]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
arXiv preprint arXiv:2511.22677 (2025) 4, 5
Dongyang Liu, Peng Gao, David Liu, Ruoyi Du, Zhen Li, Qilong Wu, Xin Jin, Sihan Cao, Shifeng Zhang, Hongsheng Li, et al. Decoupled DMD: CFG augmentation as the spear, distribution matching as the shield.arXiv preprint arXiv:2511.22677,
-
[17]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
28 Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Simplifying, Stabilizing and Scaling Continuous-Time Consistency Models
Cheng Lu and Yang Song. Simplifying, stabilizing and scaling continuous-time consistency models.arXiv preprint arXiv:2410.11081,
work page internal anchor Pith review arXiv
-
[19]
Guoqing Ma, Haoyang Huang, Kun Yan, Liangyu Chen, Nan Duan, Shengming Yin, Changyi Wan, Ranchen Ming, Xiaoniu Song, Xing Chen, et al. Step-video-t2v technical report: The practice, challenges, and future of video foundation model.arXiv preprint arXiv:2502.10248,
-
[20]
Sdxl: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. In International Conference on Learning Representations, volume 2024, pp. 1862–1874,
work page 2024
-
[21]
Seedream 4.0: Toward Next-generation Multimodal Image Generation
Team Seedream, Yunpeng Chen, Yu Gao, Lixue Gong, Meng Guo, Qiushan Guo, Zhiyao Guo, Xiaoxia Hou, Weilin Huang, Yixuan Huang, et al. Seedream 4.0: Toward next-generation multimodal image generation.arXiv preprint arXiv:2509.20427,
work page internal anchor Pith review arXiv
-
[22]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Longcat-image technical report
Mingjie Sun, Xinlei Chen, J Zico Kolter, and Zhuang Liu. Massive activations in large language models. InFirst Conference on Language Modeling, 2024a. Quan Sun, Qiying Yu, Yufeng Cui, Fan Zhang, Xiaosong Zhang, Yueze Wang, Hongcheng Gao, Jingjing Liu, Tiejun Huang, and Xinlong Wang. Emu: Generative pretraining in multimodality. InInternational conference ...
-
[24]
Wan: Open and Advanced Large-Scale Video Generative Models
29 Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
GRPO-Guard: Mitigating implicit over-optimization in flow matching via regulated clipping, 2025
Jing Wang, Jiajun Liang, Jie Liu, Henglin Liu, Gongye Liu, Jun Zheng, Wanyuan Pang, Ao Ma, Zhenyu Xie, Xintao Wang, et al. Grpo-guard: Mitigating implicit over-optimization in flow matching via regulated clipping.arXiv preprint arXiv:2510.22319,
-
[26]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Tianhe Wu, Ruibin Li, Lei Zhang, and Kede Ma. Diversity-preserved distribution matching distillation for fast visual synthesis.arXiv preprint arXiv:2602.03139,
-
[28]
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and Bill Freeman. Improved distribution matching distillation for fast image synthesis. InAdvances in Neural Information Processing Systems, pp. 47455–47487, 2024a. Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung P...
work page internal anchor Pith review arXiv
-
[29]
DiffusionNFT: Online Diffusion Reinforcement with Forward Process
Kaiwen Zheng, Huayu Chen, Haotian Ye, Haoxiang Wang, Qinsheng Zhang, Kai Jiang, Hang Su, Stefano Ermon, Jun Zhu, and Ming-Yu Liu. Diffusionnft: Online diffusion reinforcement with forward process. arXiv preprint arXiv:2509.16117,
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.