When Do LLMs Generate Realistic Social Networks? A Multi-Dimensional Study of Culture, Language, Scale, and Method
Pith reviewed 2026-06-30 21:27 UTC · model grok-4.3
The pith
Prompt architecture functions as a substantive sociological variable that decides which demographic traits drive ties in LLM-generated networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
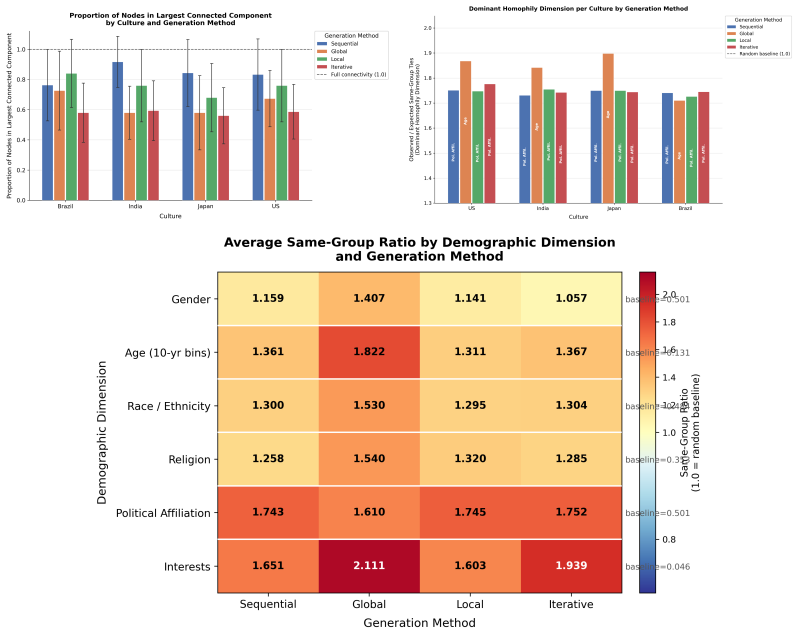
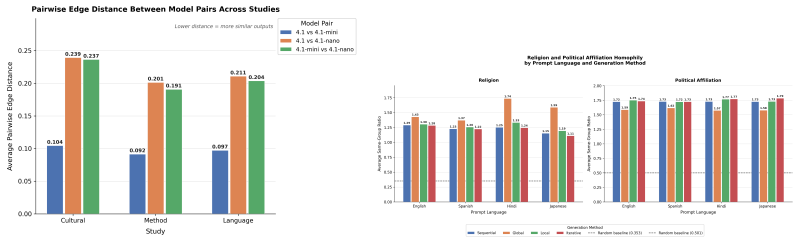
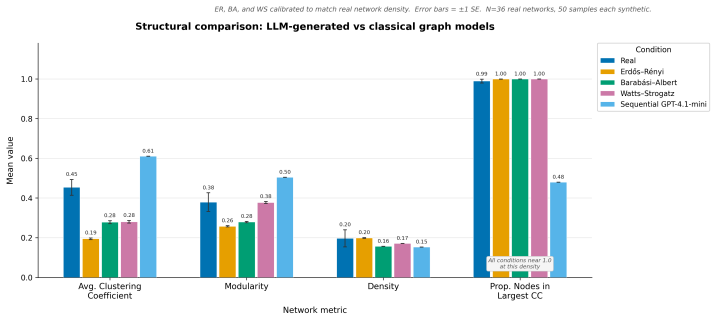
Across four cultural contexts, four prompt languages, three GPT-4.1 variants, and four prompting architectures, political affiliation dominates tie formation under sequential, local, and iterative methods while the global method substitutes age as the primary driver. Cultural framing shifts inbreeding homophily and largest-component connectivity, prompt language sharply alters religion homophily especially under Hindi, and model scale produces a stable divergence ranking rather than random variation. LLM networks match real social graphs on clustering and modularity better than standard baselines but exceed empirical levels of demographic bias.
What carries the argument
Four formalized LLM-based tie-formation mechanisms (sequential, global, local, iterative) treated as distinct conditional distributions over edge sets on a fixed roster of 50 demographically grounded personas.
If this is right
- Cultural framing produces measurable shifts in inbreeding homophily and largest-component connectivity.
- Political affiliation dominates tie formation under sequential, local, and iterative methods while age dominates under the global method.
- Prompt language changes religion homophily substantially, especially under Hindi prompting, but leaves political homophily nearly unchanged.
- Model scale creates a stable ordering of behavioral differences rather than simple increases in noise.
- Generated networks exceed observed empirical demographic biases while reproducing clustering and modularity levels of real graphs.
Where Pith is reading between the lines
- Researchers using LLMs for social simulation must treat prompting architecture as an explicit modeling decision rather than a neutral implementation detail.
- The near-invariance of political homophily across languages suggests training data may embed political patterns more strongly than other demographic signals.
- Testing whether targeted prompt adjustments can bring bias levels closer to empirical values would directly test the practical controllability of these effects.
- Extending the same multi-dimensional design to open-weight models could reveal whether the observed scale divergence generalizes beyond the GPT-4.1 family.
Load-bearing premise
The 50 demographically grounded personas and the four formalized tie-formation mechanisms produce conditional distributions over edge sets that are meaningfully comparable to real human social networks.
What would settle it
Generate networks under the global method and test whether age-based homophily exceeds political homophily while the other three methods show the reverse pattern, then compare both patterns to homophily coefficients measured in real social networks from the same cultural settings.
Figures
read the original abstract
Large language models (LLMs) are increasingly used as substitutes for human subjects in behavioral simulations, including synthetic social network generation. Yet it remains unclear how their relational outputs depend on prompt design, cultural framing, prompt language, and model scale. Building on homophily theory and structural balance theory, we formalize four LLM-based tie-formation mechanisms: sequential, global, local, and iterative, and treat them as distinct conditional distributions over edge sets. Using a fixed roster of 50 demographically grounded personas, we generate 192 verified directed networks across four cultural contexts, four prompt languages, three GPT-4.1 variants, and four prompting architectures, with two seeds per condition. We find that cultural framing shifts inbreeding homophily and largest-component connectivity. Political affiliation dominates tie formation under three methods, while the global method substitutes age, showing that prompt architecture functions as a substantive sociological variable. Model scale produces a stable divergence ranking, with the smallest variant behaving qualitatively differently rather than merely noisily. Prompt language alone sharply shifts religion homophily, especially under Hindi prompting, while leaving political homophily nearly invariant. LLM-generated networks match real social graphs on clustering and modularity better than standard graph baselines, yet encode demographic biases above empirical levels. These results show that prompt choices often treated as implementation details encode substantive sociological assumptions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study of how cultural framing, prompt language, model scale, and tie-formation mechanisms (sequential, global, local, iterative) influence the structure of social networks generated by LLMs from a fixed set of 50 demographically grounded personas. Across 192 networks, it reports that prompt architecture affects which demographic attributes dominate tie formation (political affiliation in most methods, age in global), cultural context shifts homophily and connectivity, language affects religion homophily, and LLM networks outperform graph baselines on clustering and modularity while exhibiting elevated demographic biases. The core claim is that prompt design choices encode substantive sociological assumptions.
Significance. Should the findings prove robust, the work underscores the importance of prompt engineering in LLM-based social simulations and suggests that such models can capture certain structural properties of real networks better than simple baselines. The scale of the experiment (192 networks, multi-factor design) provides a valuable map of sensitivities. It contributes to understanding LLMs as tools in computational social science by treating prompting methods as variables rather than implementation details.
major comments (3)
- [Abstract and Results] Abstract and Results: The claims that 'political affiliation dominates tie formation under three methods' and that cultural framing shifts homophily are presented as directional effects without reported error bars, statistical tests, p-values, or variability measures across the two seeds per condition. This is load-bearing for the central claim that prompt architecture functions as a substantive sociological variable.
- [Methods] Methods: The generation of '192 verified directed networks' is described, but there is no account of the verification procedure for ties, how the four mechanisms were implemented to produce edge sets, or how baselines for clustering/modularity comparisons were constructed. This affects the interpretability of all reported differences.
- [Discussion] Discussion: The interpretation of prompt architecture as encoding 'substantive sociological assumptions' rests on LLM outputs from the 50 personas; without a human-subject control arm using identical personas and mechanism instructions, it remains unclear whether the observed shifts (e.g., political vs. age dominance) reflect general tie-formation processes or LLM-specific artifacts.
minor comments (1)
- [Abstract] Abstract: The phrase 'three GPT-4.1 variants' should specify whether these are different model scales, temperatures, or other parameters to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments identify opportunities to strengthen statistical reporting, methodological transparency, and interpretive framing. We respond to each major comment below and commit to revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results: The claims that 'political affiliation dominates tie formation under three methods' and that cultural framing shifts homophily are presented as directional effects without reported error bars, statistical tests, p-values, or variability measures across the two seeds per condition. This is load-bearing for the central claim that prompt architecture functions as a substantive sociological variable.
Authors: We agree that the directional claims would be more robust with explicit variability measures and statistical support. In the revision we will add error bars (or standard deviations) computed across the two seeds for all reported homophily and dominance metrics. We will also include paired statistical tests (e.g., Wilcoxon signed-rank or ANOVA with post-hoc corrections) comparing the four prompting methods on the key attributes, and will reference these results in the Abstract and Results sections. revision: yes
-
Referee: [Methods] Methods: The generation of '192 verified directed networks' is described, but there is no account of the verification procedure for ties, how the four mechanisms were implemented to produce edge sets, or how baselines for clustering/modularity comparisons were constructed. This affects the interpretability of all reported differences.
Authors: We accept that additional procedural detail is needed for reproducibility. The revised Methods section will explicitly describe: (1) the tie-verification protocol (automated consistency checks across seeds plus manual review of a 10% sample); (2) the precise prompt templates and parsing rules used to implement each of the four tie-formation mechanisms (sequential, global, local, iterative); and (3) the construction and parameterization of the graph baselines (Erdős–Rényi, configuration model, and stochastic block model) matched to the empirical degree sequences and node counts of the LLM networks. revision: yes
-
Referee: [Discussion] Discussion: The interpretation of prompt architecture as encoding 'substantive sociological assumptions' rests on LLM outputs from the 50 personas; without a human-subject control arm using identical personas and mechanism instructions, it remains unclear whether the observed shifts (e.g., political vs. age dominance) reflect general tie-formation processes or LLM-specific artifacts.
Authors: We agree that a human control arm would help distinguish LLM-specific artifacts from general sociological processes. However, running an equivalent human-subject experiment with the same 50 personas and mechanism instructions lies outside the scope and resources of the present computational study. In the revision we will (a) explicitly qualify all claims as pertaining to LLM-generated networks, (b) add a dedicated limitations paragraph acknowledging the absence of human controls, and (c) frame the observed prompt-architecture effects as LLM-specific sensitivities rather than universal tie-formation rules. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper is a purely empirical study that generates directed networks from a fixed set of 50 personas under four explicitly defined tie-formation mechanisms (sequential, global, local, iterative) and four cultural/prompt conditions, then measures observable properties (inbreeding homophily, giant-component size, clustering, modularity) against external real-world social graphs and standard graph baselines. No derivation, prediction, or uniqueness claim reduces by construction to a fitted parameter, self-citation, or ansatz internal to the paper; all reported differences are direct experimental outcomes compared to independent benchmarks. The central interpretation that prompt architecture acts as a sociological variable follows from those external comparisons rather than from any self-referential loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The four LLM-based tie-formation mechanisms can be treated as distinct conditional distributions over edge sets.
Reference graph
Works this paper leans on
-
[1]
A. Abid, M. Farooqi, and J. Zou. Persistent anti-Muslim bias in large language models. InProceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society (AIES), pages 298–306,
2021
-
[2]
E. M. Bender, T. Gebru, A. McMillan-Major, and S. Shmitchell. On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT), pages 610–623,
2021
-
[3]
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, pages 1877–1901,
1901
- [4]
-
[5]
P. Törnberg, D. Valeeva, J. Uitermark, and C. Bail. Simulating social media using large language models to evaluate alternative news feed algorithms. arXiv preprint arXiv:2310.05984,
-
[6]
Census Bureau
U.S. Census Bureau. ACS demographic and housing estimates: 2023 american community survey 1-year estimates. Available athttps: //data.census.gov/,
2023
-
[7]
adult population estimates [U.S
Demo- graphic marginals were sampled from U.S. adult population estimates [U.S. Census Bureau, 2023]; persona interests were synthesized using GPT-4o conditional on the other five attributes. The roster is generated once and used unchanged across every experimental condition, which makes it a con- trolled constant rather than an experimental variable. The...
2023
-
[8]
All generated networks are saved as adjacency lists with filenames encoding the full experimental condition (METHOD_MODEL_CONDITION_SEED.adj), making provenance unambiguous
under its original license. All generated networks are saved as adjacency lists with filenames encoding the full experimental condition (METHOD_MODEL_CONDITION_SEED.adj), making provenance unambiguous. Network analysis is performed in NetworkX. All API calls use a fixed temperature ofτ= 0.8. Code and the 192 verified adjacency lists are released as supple...
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.