Recognition: unknown
Byzantine-Robust Distributed Sparse Learning Revisited
Pith reviewed 2026-05-14 19:37 UTC · model grok-4.3
The pith
Local l1-regularized robust estimators plus server-side robust aggregation deliver non-asymptotic guarantees and near-optimal rates for Byzantine-robust distributed sparse learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By combining local ℓ1-regularized robust estimation with robust aggregation at the server, the framework produces estimators with non-asymptotic guarantees that attain near-optimal statistical rates for high-dimensional sparse linear models under mild conditions on data and Byzantine fraction, while remaining communication-efficient.
What carries the argument
Local ℓ1-regularized robust estimation performed at each worker, paired with robust aggregation at the server, applied across pseudo-Huber regression, quantile regression, and sparse SVM.
If this is right
- The estimators achieve non-asymptotic convergence rates close to the minimax optimal rates.
- Performance holds when a fraction of machines below one-half behave adversarially.
- Only aggregated information is communicated, keeping total communication low.
- Support recovery and classification accuracy remain reliable under the listed attacks.
Where Pith is reading between the lines
- The same local-plus-robust-aggregate structure could extend to other high-dimensional tasks such as sparse logistic regression.
- Removing the central server to obtain a fully decentralized version is a natural next direction.
- Evaluating the method on real datasets containing natural outliers would test robustness beyond synthetic attacks.
Load-bearing premise
Data distributions satisfy bounded moments, the sparsity level is suitable, and fewer than half the machines are Byzantine.
What would settle it
Run the estimators on data whose moments are unbounded or with more than half the machines Byzantine; the non-asymptotic rates should cease to hold and estimation error should degrade sharply.
Figures









read the original abstract
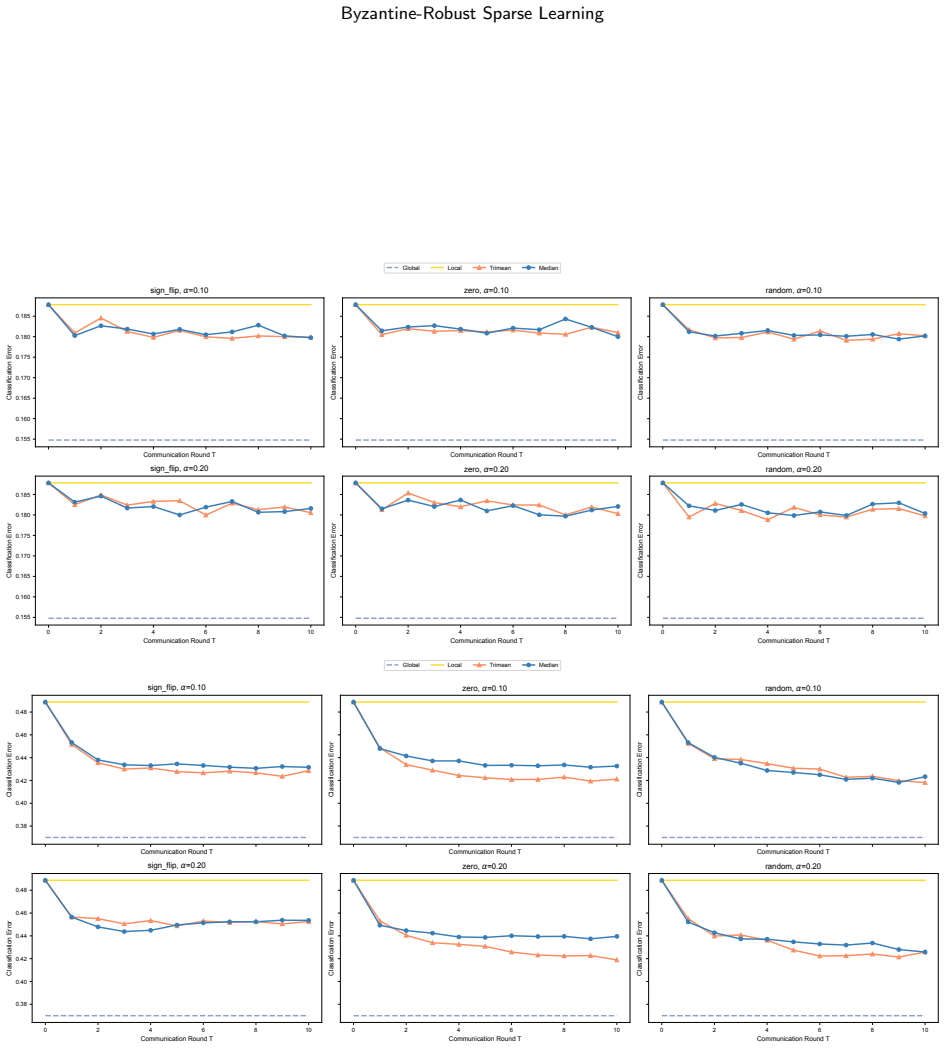
We revisit Byzantine robust distributed estimation for high-dimensional sparse linear models. By combining local $\ell_1$-regularized robust estimation with robust aggregation at the server, the framework applies to pseudo-Huber regression, quantile regression, and sparse SVM. We show that the resulting estimators yield non-asymptotic guarantees and attain near-optimal statistical rates under mild conditions, while remaining communication-efficient. Simulations confirm strong robustness in estimation, support recovery and classification accuracy under various Byzantine attacks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper revisits Byzantine-robust distributed estimation for high-dimensional sparse linear models. It combines local ℓ1-regularized robust M-estimation with a server-side robust aggregator (e.g., trimmed or median-type) to handle pseudo-Huber regression, quantile regression, and sparse SVM. The central claims are non-asymptotic error bounds, near-optimal statistical rates under mild conditions on moments, restricted eigenvalues, sparsity, and Byzantine fraction below 1/2, plus communication efficiency linear in dimension, with simulations confirming robustness in estimation, support recovery, and classification accuracy.
Significance. If the non-asymptotic guarantees and near-optimal rates hold under the stated mild conditions, the work provides a practical, communication-efficient framework for robust distributed sparse learning. This is significant for federated or distributed ML settings with potential adversaries, as it extends standard robust statistics arguments to high-dimensional sparse models with concrete losses and empirical validation. The approach avoids circularity by relying on local sparse recovery plus aggregation rather than self-referential definitions.
major comments (1)
- [Theoretical Results] Abstract and theoretical results section: the non-asymptotic guarantees and near-optimal rates are asserted, but the explicit error bounds, dependence on the Byzantine fraction, and precise conditions (e.g., restricted eigenvalue constants and moment bounds) must be stated in the main theorems to allow verification that the rates are indeed near-optimal and not degraded by the robust aggregator.
minor comments (2)
- [Simulations] Simulations section: the description of the experimental setup (number of machines, dimension p, sparsity level, specific Byzantine attack models, and number of repetitions) should be expanded with exact parameter values and tables for reproducibility.
- [Notation and Preliminaries] Notation: ensure consistent use of symbols for the local estimator, aggregator, and loss functions across sections to avoid ambiguity in the communication complexity analysis.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and the recommendation for minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [Theoretical Results] Abstract and theoretical results section: the non-asymptotic guarantees and near-optimal rates are asserted, but the explicit error bounds, dependence on the Byzantine fraction, and precise conditions (e.g., restricted eigenvalue constants and moment bounds) must be stated in the main theorems to allow verification that the rates are indeed near-optimal and not degraded by the robust aggregator.
Authors: We agree that greater explicitness will aid verification. The main theorems (Theorem 3.1 for pseudo-Huber, Theorem 3.3 for quantile regression, and Theorem 3.5 for sparse SVM) already contain the full non-asymptotic bounds: with probability at least 1-δ, ||θ̂ - θ*||₂ ≤ C(√(s log(p/δ)/n) + α), where α < 1/2 is the Byzantine fraction, under the restricted eigenvalue condition with constant κ > 0 and moment assumptions E[|ψ(X,Y)|^{2+ν}] < ∞ for ν > 0. The robust aggregator contributes only the additive α term and does not degrade the statistical rate. In the revision we will restate these bounds verbatim at the start of each theorem (rather than only in the proof) and add a short remark after each statement clarifying that the rate matches the minimax lower bound for sparse estimation up to the unavoidable Byzantine term. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper derives non-asymptotic guarantees and near-optimal rates for Byzantine-robust sparse estimators by combining local ℓ1-regularized robust M-estimation (for pseudo-Huber, quantile, and sparse SVM losses) with server-side robust aggregation. These steps rest on standard assumptions including restricted eigenvalue conditions, bounded moments, and Byzantine fraction below 1/2, without reducing any claimed prediction or rate to a fitted quantity by construction, self-referential definitions, or load-bearing self-citations. The framework follows conventional robust statistics arguments, and simulations serve only as corroboration.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Standard regularity conditions on data distribution and sparsity level for high-dimensional linear models
- domain assumption Byzantine fraction strictly less than 1/2
Reference graph
Works this paper leans on
-
[1]
Sparse Quantile Huber Regression for Efficient and Robust Estimation
Sparse quantile huber regression for efficient and robust estimation. arXiv preprint arXiv:1402.4624 . Battey, H., Fan, J., Liu, H., Lu, J., Zhu, Z.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Distributed testing and estimation under sparse high dimensional models. Ann. Statist. 46, 1352–1382. doi:10.1214/17-AOS1587. Belloni,A.,Chernozhukov,V.,2011.𝓁 1-penalizedquantileregressioninhigh-dimensionalsparsemodels. Ann.Statist.39,82–130. doi:10.1214/ 10-AOS827. Blanchard, P., El Mhamdi, E.M., Guerraoui, R., Stainer, J.,
- [3]
-
[4]
Estimation of high dimensional mean regression in the absence of symmetry and light tail assumptions. J. R. Stat. Soc. B: Stat. Methodol. 79, 247–265. doi:10.1111/rssb.12166. Fan, J., Liu, H., Sun, Q., Zhang, T.,
-
[5]
I-lamm for sparse learning: Simultaneous control of algorithmic complexity and statistical error. Ann. Statist. 46, 814–841. doi:10.1214/17-AOS1568. He, X., Pan, X., Tan, K.M., Zhou, W.X.,
-
[6]
Smoothed quantile regression with large-scale inference. J. Econometrics 232, 367–388. doi:10.1016/j.jeconom.2021.07.010. Hermann, P., Holzmann, H.,
-
[7]
Support estimation and sign recovery in high-dimensional heteroscedastic mean regression. Scand J Statist 52, 805–839. doi:10.1111/sjos.12772. Huber, P.J.,
-
[8]
Robust estimation of a location parameter, in: Breakthroughs in Statistics: Methodology and Distribution. Springer, New York, pp. 492–518. doi:10.1007/978-1-4612-4380-9_35. Jordan,M.I.,Lee,J.D.,Yang,Y.,2018. Communication-efficientdistributedstatisticalinference. J.Am.Stat.Assoc.114,668–681. doi:10.1080/ 01621459.2018.1429274. Koenker, R., Bassett Jr., G.,
-
[9]
Econometrica46(1), 33 (1978) https://doi
Regression quantiles. Econometrica 46, 33–50. doi:10.2307/1913643. Koltchinskii,V.,2011. Oracleinequalitiesinempiricalriskminimizationandsparserecoveryproblems:Écoled’ÉtédeProbabilitésdeSaint-Flour XXXVIII-2008. volume
-
[10]
Springer. doi:10.1007/978-3-642-22147-7. Lee, J.D., Liu, Q., Sun, Y., Taylor, J.E.,
-
[11]
Communication-efficient sparse regression. J. Mach. Learn. Res. 18, 1–30. Luo,J.,Sun,Q.,Zhou,W.X.,2022. Distributedadaptivehuberregression. Comput.Statist.DataAnal.169,107419. doi:10.1016/j.csda.2021. 107419. Shamir, O., Srebro, N., Zhang, T.,
-
[12]
Weak Convergence and Empirical Processes: With Applications to Statistics. Springer, New York. doi:10.1007/978-1-4757-2545-2. Vershynin, R.,
-
[13]
Efficient distributed learning with sparsity, in: International Conference on Machine Learning, PMLR. pp. 3636–3645. Wang,L.,Lian,H.,2020. Communication-efficientestimationofhigh-dimensionalquantileregression. Anal.Appl.18,1057–1075. doi:10.1142/ S0219530520500098. Xu, W., Liu, J., Lian, H.,
work page 2020
-
[14]
Distributed estimation of support vector machines for matrix data. IEEE Trans. Neural Netw. Learn. Syst. 35, 6643–6653. doi:10.1109/TNNLS.2022.3212390. Yin,D.,Chen,Y.,Kannan,R.,Bartlett,P.,2018.Byzantine-robustdistributedlearning:Towardsoptimalstatisticalrates,in:InternationalConference on Machine Learning, PMLR. pp. 5650–5659. Zhao,P.,Yu,F.,Wan,Z.,2024. ...
-
[15]
Communication-efficient and byzantine-robust distributed learning with statistical guarantee. Pattern Recognit. 137, 109312. doi:10.1016/j.patcog.2023.109312. Zhou, X., Shen, H.,
-
[16]
Wang et al.:Preprint submitted to ElsevierPage 36 of 36
doi:10.3390/math10071029. Wang et al.:Preprint submitted to ElsevierPage 36 of 36
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.