Do Composed Image Retrieval Benchmarks Require Multimodal Composition?
Pith reviewed 2026-05-20 21:16 UTC · model grok-4.3
The pith
Many queries in composed image retrieval benchmarks can be solved using only a single modality instead of requiring true multimodal composition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
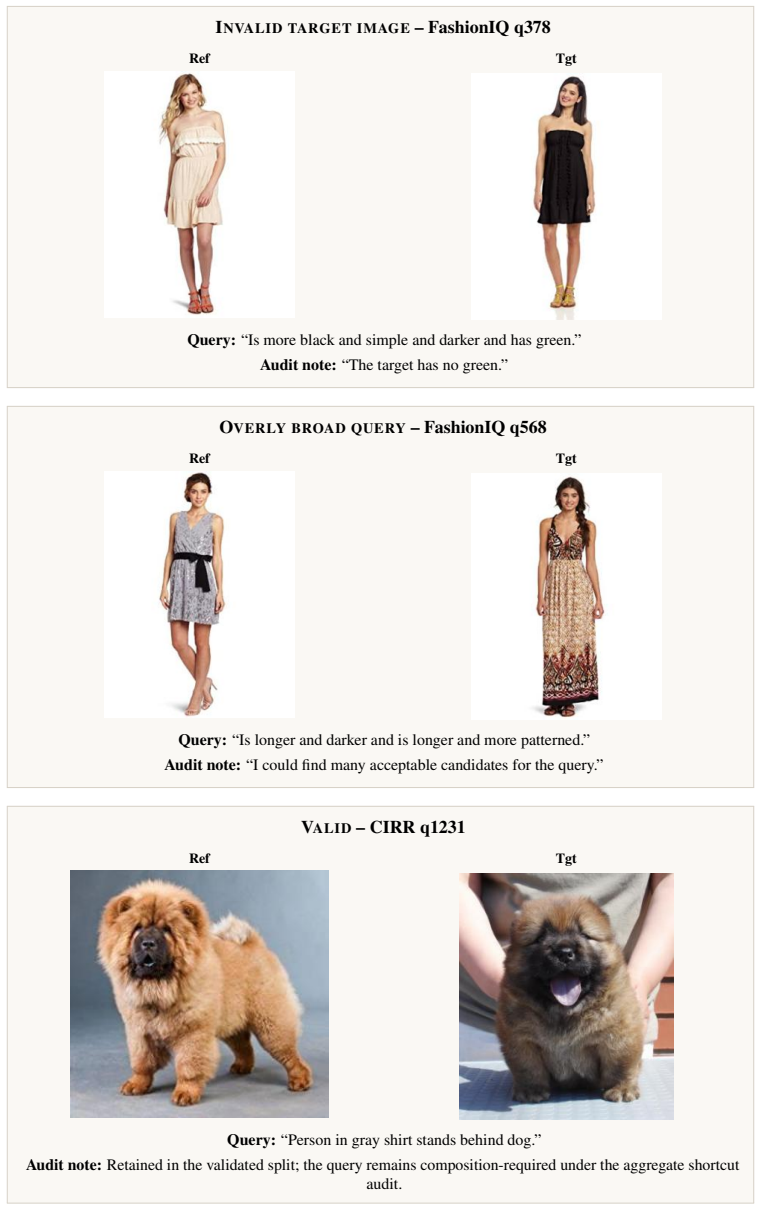
The authors demonstrate that a large fraction of queries in four standard CIR benchmarks can be solved using unimodal signals alone, ranging from 32.2% to 83.6% across eleven models. Through cross-model analysis and human validation of 4,741 shortcut-free queries, they identify only 1,689 as well-formed, with issues like ambiguous edits and mismatched targets common in the rest. Re-evaluation on this subset shows that successful retrieval now requires multimodal composition and cannot be achieved with a single modality.
What carries the argument
A two-stage audit that first uses cross-model agreement to detect shortcut-solvable queries and then applies human validation to confirm which remaining queries are well-formed and truly compositional.
If this is right
- High scores on existing CIR benchmarks can come from unimodal shortcuts rather than actual composition of image and text.
- Accuracy drops on the cleaned subset while models must now combine both inputs to succeed.
- Benchmarks mix shortcut-solvable queries, noisy queries, and genuinely compositional queries.
- Reported multimodal capabilities of current models are overestimated on standard tests.
Where Pith is reading between the lines
- Future benchmarks could add explicit checks to remove unimodal shortcuts before release.
- The same shortcut problem may appear in other multimodal retrieval or editing tasks.
- Training on only the validated compositional queries might push models toward better use of both modalities.
Load-bearing premise
Cross-model patterns and human judgments correctly separate queries that need both modalities from those solvable by shortcuts or that are malformed.
What would settle it
If models still reach high accuracy on the 1,689 validated queries when given only the reference image or only the text, the claim that these queries require multimodal composition would be false.
Figures









































read the original abstract
Composed Image Retrieval (CIR) is a multimodal retrieval task where a query consists of a reference image and a textual modification, and the goal is to retrieve a target image satisfying both. In principle, strong performance on CIR benchmarks is assumed to require multimodal composition, i.e., combining complementary information from reference image and textual modification. In this work, we show that this assumption does not always hold. Across four widely used CIR benchmarks and eleven Generalist Multimodal Embedding models, a large fraction of queries can be solved using a single modality (from 32.2% to 83.6%), revealing pervasive unimodal shortcuts. Thus, high CIR performance can arise from unimodal signals rather than true multimodal composition. To better understand this issue, we perform a two-stage audit. First, we identify shortcut-solvable queries through cross-model analysis. Second, we conduct human validation on 4,741 shortcut-free queries, of which only 1,689 are well-formed, with common issues including ambiguous edits and mismatched targets. Re-evaluating models on this validated subset reveals qualitatively different behaviour: queries can no longer be solved with a single modality, and successful retrieval requires combining both inputs. While accuracy decreases, reliance on multimodal information increases. Overall, current CIR benchmarks conflate shortcut-solvable, noisy, and genuinely compositional queries, leading to an overestimation of model capability in multimodal composition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Composed Image Retrieval (CIR) benchmarks do not always require multimodal composition. Across four standard benchmarks and eleven generalist multimodal embedding models, 32.2% to 83.6% of queries are solvable using only the reference image or only the modification text. A two-stage audit first uses cross-model analysis to flag shortcut-solvable queries, then performs human validation on the remaining 4,741 queries, of which only 1,689 are deemed well-formed. Re-evaluation on this validated subset shows that single-modality solutions no longer suffice and that successful retrieval requires combining both inputs, leading to the conclusion that current benchmarks conflate shortcut-solvable, noisy, and genuinely compositional queries.
Significance. If the two-stage audit is shown to be reliable, the result would be significant for multimodal retrieval research. It provides concrete evidence that high performance on existing CIR benchmarks can arise from unimodal signals rather than composition, and it supplies an auditing procedure (cross-model filtering followed by human review) that could be adopted to improve future benchmark construction. The scale of the analysis (four benchmarks, eleven models, 4,741 human-validated queries) adds weight to the practical implications for model evaluation.
major comments (2)
- [§3.2] §3.2 (Cross-model analysis): The precise operational criterion for labeling a query as shortcut-solvable (e.g., minimum number of the eleven models that must succeed with a single modality, retrieval rank threshold, or agreement rule) is not stated. Without this definition the reported range 32.2–83.6% cannot be reproduced or stress-tested for sensitivity to model correlation.
- [Human validation subsection] Human validation subsection: No inter-annotator agreement metric (Cohen’s κ, Fleiss’ κ, or raw percentage) is reported for the labeling of the 4,741 shortcut-free queries. This statistic is load-bearing for the claim that only 1,689 queries are well-formed and for the subsequent finding that multimodal reliance increases on the validated subset.
minor comments (2)
- [Abstract] Abstract: The percentages 32.2%–83.6% are given as a range; stating the per-benchmark values would make the per-dataset variation immediately visible.
- [§3.1] The manuscript would benefit from a short table listing the eleven models, their training data sources, and architectural families to allow readers to assess possible correlation in the cross-model analysis.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below and will revise the paper to improve methodological clarity and reproducibility.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Cross-model analysis): The precise operational criterion for labeling a query as shortcut-solvable (e.g., minimum number of the eleven models that must succeed with a single modality, retrieval rank threshold, or agreement rule) is not stated. Without this definition the reported range 32.2–83.6% cannot be reproduced or stress-tested for sensitivity to model correlation.
Authors: We thank the referee for pointing out this omission. The exact operational criteria used to label queries as shortcut-solvable (including the minimum number of models succeeding on a single modality, the retrieval rank threshold, and any agreement rules across the eleven models) were not stated with sufficient precision in §3.2. We will add a complete description of these criteria in the revised manuscript so that the reported percentages can be reproduced and sensitivity to model correlation can be evaluated. revision: yes
-
Referee: [Human validation subsection] Human validation subsection: No inter-annotator agreement metric (Cohen’s κ, Fleiss’ κ, or raw percentage) is reported for the labeling of the 4,741 shortcut-free queries. This statistic is load-bearing for the claim that only 1,689 queries are well-formed and for the subsequent finding that multimodal reliance increases on the validated subset.
Authors: We agree that an inter-annotator agreement metric is important for establishing the reliability of the human validation. We will include this statistic (raw percentage agreement or Fleiss’ κ, as appropriate) for the labeling of the 4,741 shortcut-free queries in the revised human validation subsection. This addition will strengthen the claim that 1,689 queries are well-formed and support the observed increase in multimodal reliance on the validated subset. revision: yes
Circularity Check
Empirical audit relies on external models and human validation with no definitional or fitted reduction
full rationale
The paper conducts a two-stage empirical audit: cross-model analysis across 11 independent generalist multimodal embedding models to flag shortcut-solvable queries, followed by human validation on the remaining 4,741 queries. No equations, parameter fitting, or self-citations are used to derive the central percentages (32.2%–83.6% shortcut-solvable) or the final 1,689 well-formed count. These quantities are direct observations from retrieval experiments and annotations, not reductions to inputs by construction. The derivation chain is self-contained against external benchmarks and does not match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Strong performance on CIR benchmarks is assumed to require multimodal composition of reference image and textual modification
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A query is said to admit a unimodal shortcut if any model can retrieve the target using a single modality... We define the best achievable unimodal ranks: rtxt*(i) = min_p rtxt_p(i), rimg*(i) = min_p rimg_p(i).
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Re-evaluating models on this validated subset reveals qualitatively different behaviour: queries can no longer be solved with a single modality, and successful retrieval requires combining both inputs.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Image retrieval on real-life images with pre-trained vision-and-language models
Zheyuan Liu, Cristian Rodriguez-Opazo, Damien Teney, and Stephen Gould. Image retrieval on real-life images with pre-trained vision-and-language models. InICCV, pages 2125–2134. IEEE, 2021
work page 2021
-
[2]
Fashion IQ: A new dataset towards retrieving images by natural language feedback
Hui Wu, Yupeng Gao, Xiaoxiao Guo, Ziad Al-Halah, Steven Rennie, Kristen Grauman, and Rogério Feris. Fashion IQ: A new dataset towards retrieving images by natural language feedback. InCVPR, pages 11307–11317. Computer Vision Foundation / IEEE, 2021
work page 2021
-
[3]
Data roaming and quality assessment for composed image retrieval
Matan Levy, Rami Ben-Ari, Nir Darshan, and Dani Lischinski. Data roaming and quality assessment for composed image retrieval. InAAAI, pages 13601–13609. AAAI Press, 2024
work page 2024
-
[4]
Zero-shot composed image retrieval with textual inversion
Alberto Baldrati, Lorenzo Agnolucci, Marco Bertini, and Alberto Del Bimbo. Zero-shot composed image retrieval with textual inversion. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 15338–15347, 2023
work page 2023
-
[5]
Making the V in VQA matter: Elevating the role of image understanding in visual question answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the V in VQA matter: Elevating the role of image understanding in visual question answering. In CVPR, pages 6325–6334. IEEE Computer Society, 2017
work page 2017
-
[6]
Zemel, Wieland Brendel, Matthias Bethge, and Felix A
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard S. Zemel, Wieland Brendel, Matthias Bethge, and Felix A. Wichmann. Shortcut learning in deep neural networks.Nature Machine Intelligence, 2(11):665–673, 2020
work page 2020
-
[7]
arXiv preprint arXiv:2603.21687 , year=
Mohammad Asadi, Jack W O’Sullivan, Fang Cao, Tahoura Nedaee, Kamyar Fardi, Fei-Fei Li, Ehsan Adeli, and Euan Ashley. Mirage the illusion of visual understanding.arXiv preprint arXiv:2603.21687, 2026
-
[8]
GME: Improving Universal Multimodal Retrieval by Multimodal LLMs
Xin Zhang, Yanzhao Zhang, Wen Xie, Mingxin Li, Ziqi Dai, Dingkun Long, Pengjun Xie, Meishan Zhang, Wenjie Li, and Min Zhang. GME: improving universal multimodal retrieval by multimodal llms.CoRR, abs/2412.16855, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Mm-embed: Universal multimodal retrieval with multimodal LLMS
Sheng-Chieh Lin, Chankyu Lee, Mohammad Shoeybi, Jimmy Lin, Bryan Catanzaro, and Wei Ping. Mm-embed: Universal multimodal retrieval with multimodal LLMS. InICLR. OpenReview.net, 2025
work page 2025
-
[10]
Lamra: Large multimodal model as your advanced retrieval assistant
Yikun Liu, Yajie Zhang, Jiayin Cai, Xiaolong Jiang, Yao Hu, Jiangchao Yao, Yanfeng Wang, and Weidi Xie. Lamra: Large multimodal model as your advanced retrieval assistant. InCVPR, pages 4015–4025. Computer Vision Foundation / IEEE, 2025
work page 2025
-
[11]
e5-omni: Explicit cross-modal alignment for omni-modal embeddings.CoRR, abs/2601.03666, 2026
Haonan Chen, Sicheng Gao, Radu Timofte, Tetsuya Sakai, and Zhicheng Dou. e5-omni: Explicit cross-modal alignment for omni-modal embeddings.CoRR, abs/2601.03666, 2026
-
[13]
Mllms are deeply affected by modality bias.CoRR, abs/2505.18657, 2025
Xu Zheng, Chenfei Liao, Yuqian Fu, Kaiyu Lei, Yuanhuiyi Lyu, Lutao Jiang, Bin Ren, Jialei Chen, Jiawen Wang, Chengxin Li, Linfeng Zhang, Danda Pani Paudel, Xuanjing Huang, Yu- Gang Jiang, Nicu Sebe, Dacheng Tao, Luc Van Gool, and Xuming Hu. Mllms are deeply affected by modality bias.CoRR, abs/2505.18657, 2025
-
[14]
Vlm2vec-v2: Advancing multimodal embedding for videos, images, and visual documents.Trans
Rui Meng, Ziyan Jiang, Ye Liu, Mingyi Su, Xinyi Yang, Yuepeng Fu, Can Qin, Raghuveer Thirukovalluru, Xuan Zhang, Zeyuan Chen, Ran Xu, Caiming Xiong, Yingbo Zhou, Wenhu Chen, and Semih Yavuz. Vlm2vec-v2: Advancing multimodal embedding for videos, images, and visual documents.Trans. Mach. Learn. Res., 2026, 2026
work page 2026
-
[15]
Rzenembed: Towards comprehensive multimodal retrieval.CoRR, abs/2510.27350, 2025
Weijian Jian, Yajun Zhang, Dawei Liang, Chunyu Xie, Yixiao He, Dawei Leng, and Yuhui Yin. Rzenembed: Towards comprehensive multimodal retrieval.CoRR, abs/2510.27350, 2025
-
[16]
Mingxin Li, Yanzhao Zhang, Dingkun Long, Keqin Chen, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state-of-the-art multimodal retrieval and ranking, 2026. URLhttps://arxiv.org/abs/2601.04720
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Composing text and image for image retrieval - an empirical odyssey
Nam V o, Lu Jiang, Chen Sun, Kevin Murphy, Li-Jia Li, Li Fei-Fei, and James Hays. Composing text and image for image retrieval - an empirical odyssey. InCVPR, pages 6439–6448. Computer Vision Foundation / IEEE, 2019
work page 2019
-
[18]
Compositional learning of image-text query for image retrieval
Muhammad Umer Anwaar, Egor Labintcev, and Martin Kleinsteuber. Compositional learning of image-text query for image retrieval. InWACV, pages 1140–1149. IEEE, 2021
work page 2021
-
[19]
SAC: semantic attention composition for text-conditioned image retrieval
Surgan Jandial, Pinkesh Badjatiya, Pranit Chawla, Ayush Chopra, Mausoom Sarkar, and Balaji Krishnamurthy. SAC: semantic attention composition for text-conditioned image retrieval. In IEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2022, Waikoloa, HI, USA, January 3-8, 2022, pages 597–606. IEEE, 2022. doi: 10.1109/W ACV51458.2022.00067....
work page doi:10.1109/w 2022
-
[20]
Pic2word: Mapping pictures to words for zero-shot composed image retrieval
Kuniaki Saito, Kihyuk Sohn, Xiang Zhang, Chun-Liang Li, Chen-Yu Lee, Kate Saenko, and Tomas Pfister. Pic2word: Mapping pictures to words for zero-shot composed image retrieval. InCVPR, pages 19305–19314. IEEE, 2023
work page 2023
-
[21]
Zero-shot composed image retrieval with textual inversion
Alberto Baldrati, Lorenzo Agnolucci, Marco Bertini, and Alberto Del Bimbo. Zero-shot composed image retrieval with textual inversion. InICCV, pages 15338–15347. IEEE, 2023
work page 2023
-
[22]
Language-only training of zero-shot composed image retrieval
Geonmo Gu, Sanghyuk Chun, Wonjae Kim, Yoohoon Kang, and Sangdoo Yun. Language-only training of zero-shot composed image retrieval. InCVPR, pages 13225–13234. IEEE, 2024
work page 2024
-
[23]
Vision-by- language for training-free compositional image retrieval
Shyamgopal Karthik, Karsten Roth, Massimiliano Mancini, and Zeynep Akata. Vision-by- language for training-free compositional image retrieval. InThe Twelfth International Con- ference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenRe- view.net, 2024. URLhttps://openreview.net/forum?id=EDPxCjXzSb. 11
work page 2024
-
[24]
CompoDiff: Versatile composed image retrieval with latent diffusion.Trans
Geonmo Gu, Sanghyuk Chun, Wonjae Kim, HeeJae Jun, Yoohoon Kang, and Sangdoo Yun. CompoDiff: Versatile composed image retrieval with latent diffusion.Trans. Mach. Learn. Res., 2024, 2024. URLhttps://openreview.net/forum?id=mKtlzW0bWc
work page 2024
-
[25]
Spherical linear interpolation and text-anchoring for zero-shot composed image retrieval
Young Kyun Jang, Dat Huynh, Ashish Shah, Wen-Kai Chen, and Ser-Nam Lim. Spherical linear interpolation and text-anchoring for zero-shot composed image retrieval. InComputer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part XIX, Lecture Notes in Computer Science, pages 239–254. Springer, 2024. doi:...
-
[26]
Magiclens: Self-supervised image retrieval with open-ended instructions
Kai Zhang, Yi Luan, Hexiang Hu, Kenton Lee, Siyuan Qiao, Wenhu Chen, Yu Su, and Ming-Wei Chang. Magiclens: Self-supervised image retrieval with open-ended instructions. InICML. OpenReview.net, 2024
work page 2024
-
[27]
Collm: A large language model for composed image retrieval
Chuong Huynh, Jinyu Yang, Ashish Tawari, Mubarak Shah, Son Tran, Raffay Hamid, Trishul Chilimbi, and Abhinav Shrivastava. Collm: A large language model for composed image retrieval. InCVPR, pages 3994–4004. Computer Vision Foundation / IEEE, 2025
work page 2025
-
[28]
UniIR: Training and benchmarking universal multimodal information retrievers
Cong Wei, Yang Chen, Haonan Chen, Hexiang Hu, Ge Zhang, Jie Fu, Alan Ritter, and Wenhu Chen. UniIR: Training and benchmarking universal multimodal information retrievers. In ECCV, volume 15145 ofLecture Notes in Computer Science, pages 383–404. Springer, 2024
work page 2024
-
[29]
Hypothesis only baselines in natural language inference
Adam Poliak, Jason Naradowsky, Aparajita Haldar, Rachel Rudinger, and Benjamin Van Durme. Hypothesis only baselines in natural language inference. InProceedings of the Seventh Joint Conference on Lexical and Computational Semantics, *SEM@NAACL-HLT 2018, New Orleans, Louisiana, USA, June 5-6, 2018, pages 180–191. Association for Computational Linguistics,
work page 2018
-
[30]
doi: 10.18653/V1/S18-2023
-
[31]
Suchin Gururangan, Swabha Swayamdipta, Omer Levy, Roy Schwartz, Samuel R. Bowman, and Noah A. Smith. Annotation artifacts in natural language inference data. InNAACL-HLT, pages 107–112. Association for Computational Linguistics, 2018
work page 2018
-
[32]
Don’t take the easy way out: Ensemble based methods for avoiding known dataset biases
Christopher Clark, Mark Yatskar, and Luke Zettlemoyer. Don’t take the easy way out: Ensemble based methods for avoiding known dataset biases. InEMNLP-IJCNLP, pages 4069–4082. Association for Computational Linguistics, 2019
work page 2019
-
[33]
Don’t just assume; look and answer: Overcoming priors for visual question answering
Aishwarya Agrawal, Dhruv Batra, Devi Parikh, and Aniruddha Kembhavi. Don’t just assume; look and answer: Overcoming priors for visual question answering. InCVPR, pages 4971–4980. Computer Vision Foundation / IEEE Computer Society, 2018
work page 2018
-
[34]
Overcoming language priors in visual question answering with adversarial regularization
Sainandan Ramakrishnan, Aishwarya Agrawal, and Stefan Lee. Overcoming language priors in visual question answering with adversarial regularization. InAdvances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada, pages 1548–1558, 2018
work page 2018
-
[35]
RUBi: Reducing unimodal biases for visual question answering
Rémi Cadène, Corentin Dancette, Hedi Ben-Younes, Matthieu Cord, and Devi Parikh. RUBi: Reducing unimodal biases for visual question answering. InNeurIPS, pages 841–852, 2019
work page 2019
-
[36]
Counterfactual VQA: A cause-effect look at language bias
Yulei Niu, Kaihua Tang, Hanwang Zhang, Zhiwu Lu, Xian-Sheng Hua, and Ji-Rong Wen. Counterfactual VQA: A cause-effect look at language bias. InCVPR, pages 12700–12710. Computer Vision Foundation / IEEE, 2021
work page 2021
-
[37]
Beyond question-based biases: Assessing multimodal shortcut learning in visual question answering
Corentin Dancette, Rémi Cadène, Damien Teney, and Matthieu Cord. Beyond question-based biases: Assessing multimodal shortcut learning in visual question answering. InICCV, pages 1574–1583. IEEE, 2021
work page 2021
-
[38]
Nan Wu, Stanislaw Jastrzebski, Kyunghyun Cho, and Krzysztof J. Geras. Characterizing and overcoming the greedy nature of learning in multi-modal deep neural networks. InICML, volume 162 ofProceedings of Machine Learning Research, pages 24043–24055. PMLR, 2022
work page 2022
-
[39]
Vision-and-language or vision-for- language? On cross-modal influence in multimodal transformers
Stella Frank, Emanuele Bugliarello, and Desmond Elliott. Vision-and-language or vision-for- language? On cross-modal influence in multimodal transformers. InEMNLP, pages 9847–9857. Association for Computational Linguistics, 2021. 12
work page 2021
-
[40]
When and why vision-language models behave like bags-of-words, and what to do about it? InICLR
Mert Yuksekgonul, Federico Bianchi, Pratyusha Kalluri, Dan Jurafsky, and James Zou. When and why vision-language models behave like bags-of-words, and what to do about it? InICLR. OpenReview.net, 2023
work page 2023
-
[41]
Winoground: Probing vision and language models for visio-linguistic compositionality
Tristan Thrush, Ryan Jiang, Max Bartolo, Amanpreet Singh, Adina Williams, Douwe Kiela, and Candace Ross. Winoground: Probing vision and language models for visio-linguistic compositionality. InCVPR, pages 5238–5248. IEEE, 2022
work page 2022
-
[42]
Jack Hessel and Lillian Lee. Does my multimodal model learn cross-modal interactions? It’s harder to tell than you might think! InEMNLP, pages 861–877. Association for Computational Linguistics, 2020
work page 2020
-
[43]
Bradley Efron and Robert J. Tibshirani.An Introduction to the Bootstrap. Chapman and Hall, New York, 1993. doi: 10.1007/978-1-4899-4541-9. 13 NeurIPS Paper Checklist 1.Claims Question: Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope? Answer: [Yes] Justification: The abstract and Introduction ...
-
[44]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
-
[45]
Is white with shorter sleeves and a flower and is shorter sleeved
We report the original benchmark (Full) together with theshortcut-freesubset (SF) and the validatedsubset (V). For each split, we show the multimodal query score (MM) and the three signed delta columns ∆MM-I, ∆MM-T, and ∆I-T, where I and T denote image-only and text-only queries. Full SF V Dataset Retriever MM∆MM-I∆MM-T∆I-T MM∆MM-I∆MM-T∆I-T MM∆MM-I∆MM-T∆I...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.