Quantum Circuit Synthesis Using an Exact T Library
Pith reviewed 2026-05-19 14:31 UTC · model grok-4.3
The pith
Precomputing T-optimal implementations for Boolean functions of up to seven variables, after Clifford canonicalization, yields quantum circuits with substantially lower T counts than AND-count minimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
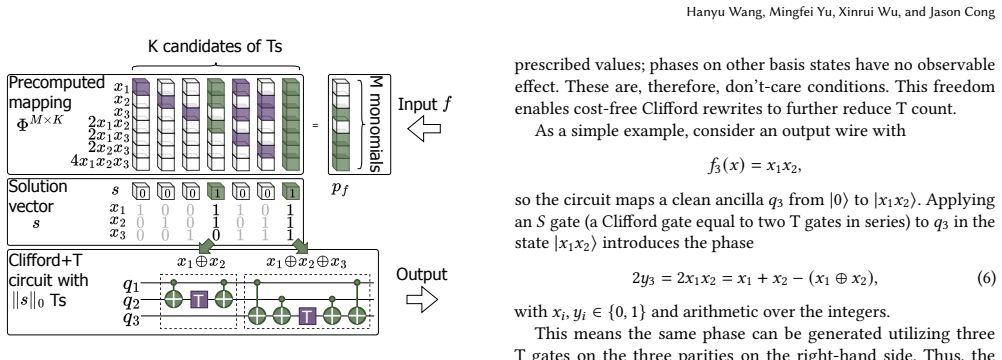
By precomputing T-optimal implementations up to seven variables and developing a customized mapper after canonicalizing Boolean functions under Clifford equivalence, the method reduces T count by up to 14.3 percent on EPFL benchmarks and improves the T counts of several cryptographic modules by up to 40 percent.
What carries the argument
Precomputed exact T-optimal library for functions of at most seven variables, combined with Clifford canonicalization and a customized mapper that assembles larger circuits.
If this is right
- Conventional flows that minimize AND count in an XOR-AND-NOT basis are suboptimal for T-count because they ignore phase cancellation.
- T-count reductions directly lower the space-time cost of fault-tolerant quantum computation since T gates require magic states.
- The mapper can be applied to real-world benchmarks including EPFL combinational logic and cryptographic modules.
- Precomputation limited to seven variables plus canonicalization is treated as adequate for the tested cases.
Where Pith is reading between the lines
- The same library could be reused as a subroutine inside larger synthesis tools that handle functions beyond seven variables by recursive decomposition.
- If T-optimal small blocks generalize across different error-correcting codes, the approach might reduce overhead in other magic-state distillation schemes.
- Extending the precomputation to eight variables would test whether the current cutoff already captures most practical savings or leaves further gains on the table.
Load-bearing premise
That the precomputed library for functions of at most seven variables, together with Clifford canonicalization, is sufficient to cover the structure of practical benchmarks without missing better global optimizations or adding prohibitive mapping overhead.
What would settle it
Finding a concrete circuit on the EPFL or cryptographic benchmark set whose T count is lower when the synthesis is allowed to consider functions with eight or more variables without Clifford canonicalization would falsify the sufficiency of the seven-variable library.
Figures








read the original abstract
In fault-tolerant quantum circuit synthesis, T gates supplied via magic states dominate space-time cost, while Clifford gates incur negligible overhead. Conventional flows minimize AND count in an {XOR, AND, NOT} basis as a proxy for T, which neglects phase cancellation and can be far from T-optimal. We instead formulate an exact T synthesis problem and canonicalize Boolean functions under Clifford equivalence. By precomputing T-optimal implementations up to seven variables and developing a customized mapper, we reduce the T count by up to 14.3% on EPFL benchmarks and improve the T counts of several cryptographic modules by up to 40%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an exact T synthesis method for fault-tolerant quantum circuits by precomputing T-optimal implementations for all Boolean functions of at most seven variables, canonicalizing under Clifford equivalence, and using a customized mapper to decompose larger circuits. It reports T-count reductions of up to 14.3% versus conventional flows on EPFL benchmarks and up to 40% on selected cryptographic modules.
Significance. If the reported improvements are reproducible and the mapper does not introduce hidden overhead, the work would be significant for reducing the dominant space-time cost of T gates in magic-state-based fault tolerance. Precomputing an exact library up to seven variables is a concrete engineering contribution that could be reused by the community.
major comments (2)
- [Mapping procedure (implied in abstract and methods)] The central claim that the mapper yields strictly lower total T counts rests on the assumption that every relevant subfunction in the benchmarks has an optimal 7-variable cover and that decomposition/re-assembly introduces no net overhead. The manuscript provides no explicit bound on the number of stored functions, no completeness proof for multi-output Clifford canonicalization, and no comparison against a global T-count ILP or SAT solver on even one benchmark subcircuit (see skeptic note on mapping step).
- [Abstract] Abstract: concrete percentage improvements are stated for named benchmarks, yet no verification protocol, error bars, or description of how post-synthesis T counts were obtained is supplied, leaving the empirical support for the central claim limited.
minor comments (2)
- Clarify storage size and lookup time of the precomputed library; state whether all 2^128 functions up to 7 variables are stored or only a canonical subset.
- Add a short description or reference for the Clifford canonicalization algorithm employed.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: The central claim that the mapper yields strictly lower total T counts rests on the assumption that every relevant subfunction in the benchmarks has an optimal 7-variable cover and that decomposition/re-assembly introduces no net overhead. The manuscript provides no explicit bound on the number of stored functions, no completeness proof for multi-output Clifford canonicalization, and no comparison against a global T-count ILP or SAT solver on even one benchmark subcircuit (see skeptic note on mapping step).
Authors: We will add an explicit statement of the library size, which equals the number of distinct Clifford equivalence classes of Boolean functions on at most seven variables (obtained by exhaustive enumeration of representatives). We will also include a short argument establishing completeness of the multi-output canonicalization, based on the invariants we employ being sufficient to distinguish all orbits under the Clifford group. A direct comparison against a global ILP or SAT solver on full benchmark subcircuits is computationally intractable; we will instead add a validation on one small extracted subcircuit where an exact solver remains feasible, to illustrate that the mapper recovers the optimal T count in that case. revision: partial
-
Referee: Abstract: concrete percentage improvements are stated for named benchmarks, yet no verification protocol, error bars, or description of how post-synthesis T counts were obtained is supplied, leaving the empirical support for the central claim limited.
Authors: We agree that the experimental protocol requires clarification. In the revised version we will expand the abstract and add a dedicated paragraph in the experimental section that describes how post-synthesis T counts are obtained: each final circuit is parsed by our synthesis tool, which performs an exact gate-by-gate T-count. The reported reductions are therefore deterministic integer differences relative to the baseline flow; error bars are inapplicable. We will also list the precise EPFL and cryptographic benchmarks used. revision: yes
Circularity Check
No circularity: precomputed library and mapper evaluated on external benchmarks
full rationale
The paper precomputes T-optimal implementations for Boolean functions of at most seven variables via exact synthesis and Clifford canonicalization, then applies a customized mapper to produce circuits for larger functions. Reported T-count reductions (up to 14.3% on EPFL benchmarks and 40% on cryptographic modules) are measured against independent external benchmarks and conventional AND-count minimization flows rather than being fitted or defined by the method itself. No derivation step reduces by construction to its own inputs, no self-citation is load-bearing for the central claim, and the evaluation uses externally verifiable data, rendering the chain self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Clifford gates incur negligible overhead compared with T gates in fault-tolerant settings
Reference graph
Works this paper leans on
-
[1]
L. Amarú, P.-E. Gaillardon, and G. De Micheli. The EPFL combinational bench- mark suite.Hypotenuse, 256(128):214335, 2015
work page 2015
- [2]
- [3]
- [4]
-
[5]
R. Babbush, C. Gidney, D. W. Berry, N. Wiebe, J. McClean, A. Paler, A. Fowler, and H. Neven. Encoding electronic spectra in quantum circuits with linear T complexity.Physical Review X, 8(4):041015, 2018
work page 2018
-
[6]
M. E. Beverland, P. Murali, M. Troyer, K. M. Svore, T. Hoefler, V. Kliuchnikov, G. H. Low, M. Soeken, A. Sundaram, and A. Vaschillo. Assessing requirements to scale to practical quantum advantage (2022).arXiv preprint arXiv:2211.07629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
D. Bluvstein, S. J. Evered, A. A. Geim, S. H. Li, H. Zhou, T. Manovitz, S. Ebadi, M. Cain, M. Kalinowski, D. Hangleiter, et al. Logical quantum processor based on reconfigurable atom arrays.Nature, 626(7997):58–65, 2024
work page 2024
-
[8]
R. Brayton and A. Mishchenko. Abc: An academic industrial-strength verification tool. InComputer Aided Verification: 22nd International Conference, CA V 2010, Edinburgh, UK, July 15-19, 2010. Proceedings 22, pages 24–40. Springer, 2010
work page 2010
-
[9]
D. Chen and J. Cong. DAOmap: A depth-optimal area optimization mapping algorithm for FPGA designs. InIEEE/ACM International Conference on Computer Aided Design, 2004. ICCAD-2004., pages 752–759. IEEE, 2004
work page 2004
-
[10]
J. Cong, C. Wu, and Y. Ding. Cut ranking and pruning: Enabling a general and efficient FPGA mapping solution. InProceedings of the 1999 ACM/SIGDA Seventh International Symposium on Field Programmable Gate Arrays, pages 29–35, 1999
work page 1999
- [11]
-
[12]
C. Gidney. Windowed quantum arithmetic.arXiv preprint arXiv:1905.07682, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[13]
C. Gidney. How to factor 2048 bit RSA integers with less than a million noisy qubits.arXiv preprint arXiv:2505.15917, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2048
-
[14]
Magic state cultivation: growing T states as cheap as CNOT gates
C. Gidney, N. Shutty, and C. Jones. Magic state cultivation: growing T states as cheap as CNOT gates.arXiv preprint arXiv:2409.17595, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Suppressing quantum errors by scaling a surface code logical qubit
Google. Suppressing quantum errors by scaling a surface code logical qubit. Nature, 614(7949):676–681, 2023
work page 2023
-
[16]
Quantum error correction below the surface code threshold.Nature, 638(8052):920–926, 2025
Google. Quantum error correction below the surface code threshold.Nature, 638(8052):920–926, 2025
work page 2025
-
[17]
I. Haleček, P. Fišer, and J. Schmidt. Are XORs in logic synthesis really necessary? In2017 IEEE 20th International Symposium on Design and Diagnostics of Electronic Circuits & Systems (DDECS), pages 134–139. IEEE, 2017
work page 2017
-
[18]
T. Häner and M. Soeken. Lowering the T-depth of quantum circuits by reducing the multiplicative depth of logic networks.arXiv preprint arXiv:2006.03845, 2020
- [19]
-
[20]
L. E. Heyfron and E. T. Campbell. An efficient quantum compiler that reduces T count.Quantum Science and Technology, 4(1):015004, 2018
work page 2018
-
[21]
S.-B. Ko and J.-C. Lo. Efficient decomposition techniques for FPGAs. InInter- national Conference on High-Performance Computing, pages 630–639. Springer, 2002
work page 2002
- [22]
- [23]
-
[24]
G. H. Low, V. Kliuchnikov, and L. Schaeffer. Trading T gates for dirty qubits in state preparation and unitary synthesis.Quantum, 8:1375, 2024
work page 2024
- [25]
- [26]
- [27]
- [28]
-
[29]
D. E. Muller. Application of Boolean Algebra to Switching Circuit Design and to Error Detection.Transactions of the I.R.E. Professional Group on Electronic Computers, EC-3(3):6–12, 1954
work page 1954
- [30]
-
[31]
F. J. Ruiz, T. Laakkonen, J. Bausch, M. Balog, M. Barekatain, F. J. Heras, A. Novikov, N. Fitzpatrick, B. Romera-Paredes, J. van de Wetering, et al. Quantum circuit optimization with AlphaTensor.Nature Machine Intelligence, pages 1–12, 2025
work page 2025
-
[32]
P. Sales Rodriguez, J. M. Robinson, P. N. Jepsen, Z. He, C. Duckering, C. Zhao, K.-H. Wu, J. Campo, K. Bagnall, M. Kwon, et al. Experimental demonstration of logical magic state distillation.Nature, pages 1–3, 2025
work page 2025
-
[33]
D. B. Tan, M. Y. Niu, and C. Gidney. A SAT scalpel for lattice surgery: Repre- sentation and synthesis of subroutines for surface-code fault-tolerant quantum computing. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA), pages 325–339. IEEE, 2024
work page 2024
-
[34]
A. Tempia Calvino and G. De Micheli. Technology mapping using multi-output library cells. In2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD), pages 1–9. IEEE, 2023. Hanyu Wang, Mingfei Yu, Xinrui Wu, and Jason Cong
work page 2023
- [35]
-
[36]
Vandaele, Lower T-count with faster algorithms (2024), arXiv:2407.08695 [quant-ph]
V. Vandaele. Lower T-count with faster algorithms.arXiv preprint arXiv:2407.08695, 2024
-
[37]
V. Vandaele, S. Martiel, and T. Goubault de Brugière. Phase polynomials synthesis algorithms for NISQ architectures and beyond.Quantum Science and Technology, 7(4):045027, 2022
work page 2022
- [38]
-
[39]
H. Wang, S.-Y. Lee, and G. De Micheli. AnySyn: A Cost-Generic Logic Synthesis Framework with Customizable Cost Functions.arXiv preprint arXiv:2311.14721, 2023
-
[40]
M. Yu, M. Soeken, and G. De Micheli. A New Perspective of Constructing Resource-Efficient Data-Lookup Quantum Oracles. In2025 IEEE International Conference on Quantum Computing and Engineering (QCE), pages 511–519. IEEE,
-
[41]
DOI: 10.1109/QCE65121.2025.00063
-
[42]
M. Yu, A. Tempia Calvino, M. Soeken, and G. De Micheli. Back-end-aware Fault- tolerant Quantum Oracle Synthesis. InProceedings of the 30th Asia and South Pacific Design Automation Conference, pages 930–937, 2025
work page 2025
-
[43]
H. Zhou, C. Duckering, C. Zhao, D. Bluvstein, M. Cain, A. Kubica, S.-T. Wang, and M. D. Lukin. Resource Analysis of Low-Overhead Transversal Architectures for Reconfigurable Atom Arrays. InProceedings of the 52nd Annual International Symposium on Computer Architecture, pages 1432–1448, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.