AdaGraph: A Graph-Native Clustering Algorithm That Overcomes the Curse of Dimensionality and Enables Scientific Discovery
Pith reviewed 2026-05-21 00:50 UTC · model grok-4.3
The pith
AdaGraph clusters high-dimensional data by analyzing connections in a nearest-neighbor graph instead of distances.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
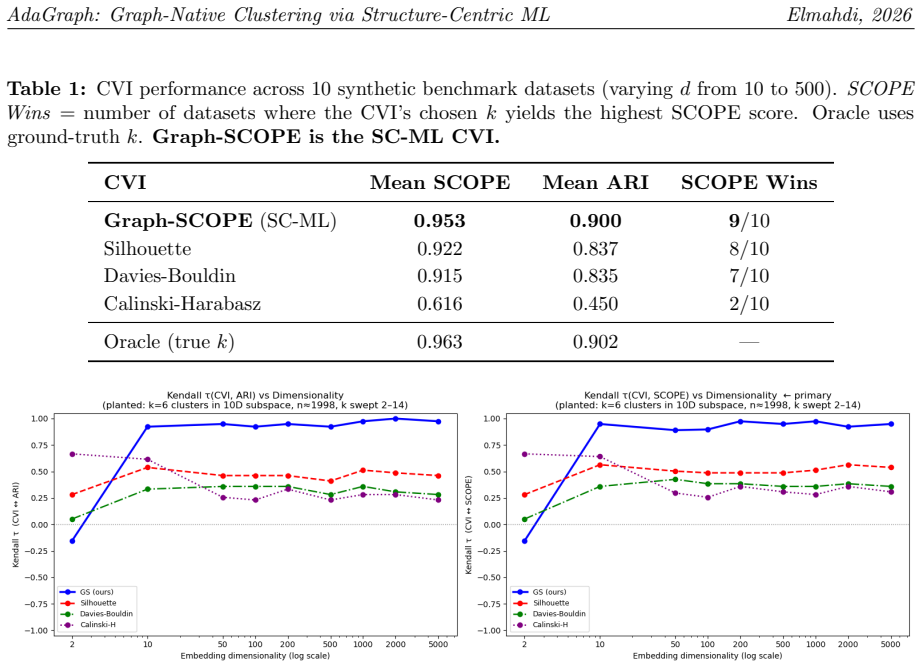
AdaGraph recovers ground-truth clusters solely from the topology of the kNN graph without geometric distances or dimensionality reduction, and when paired with Graph-SCOPE it reaches mean ARI of 0.900 while correctly selecting k on nine of ten synthetic datasets from d=10 to d=5000, plus higher validity scores than competing methods on gene, text, and materials examples.
What carries the argument
The kNN graph topology, which preserves relational structure in arbitrarily high dimensions where Euclidean distances become uninformative and on which all clustering and validity decisions are performed.
If this is right
- Clustering of 10,000-gene expression profiles becomes feasible without any dimensionality reduction step.
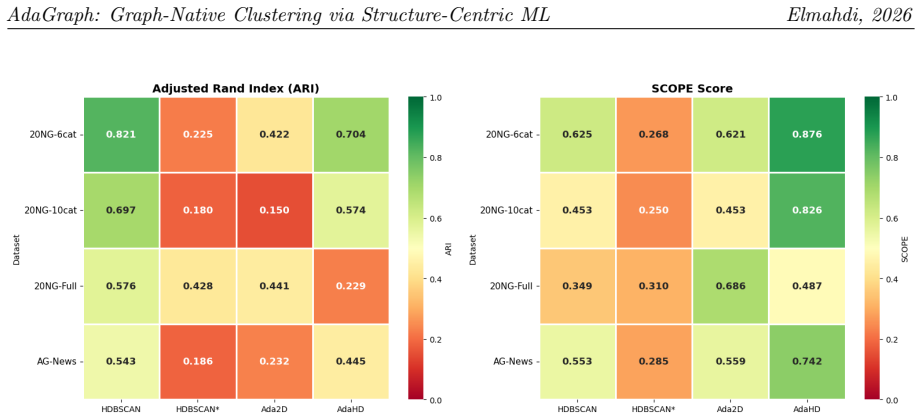
- Text documents can be grouped with ARI 0.751 on a six-category 20-newsgroups subset, a 62 percent relative gain over HDBSCAN.
- 145-dimensional materials feature sets receive the highest Graph-SCOPE scores among tested methods.
- The number of clusters need not be supplied by the user on any of the reported benchmarks.
- The same graph-native pipeline applies across gene, language, and physics data without domain-specific tuning.
Where Pith is reading between the lines
- The same nearest-neighbor graph representation could support related tasks such as outlier detection in the same high-dimensional tables.
- If topology alone suffices, many current preprocessing pipelines that discard features before clustering may become unnecessary.
- Dynamic versions of the method could track how cluster structure evolves when new samples arrive over time.
- Other unsupervised tasks that currently rely on distance matrices might be reformulated on the identical graph backbone.
Load-bearing premise
The topology of the k-nearest neighbors graph alone is sufficient to recover the true clusters even when the original data lives in spaces where all pairwise distances become uninformative.
What would settle it
A controlled high-dimensional synthetic dataset with known ground-truth clusters on which AdaGraph returns an adjusted Rand index below 0.7 or selects the wrong number of clusters when guided by Graph-SCOPE.
Figures
read the original abstract
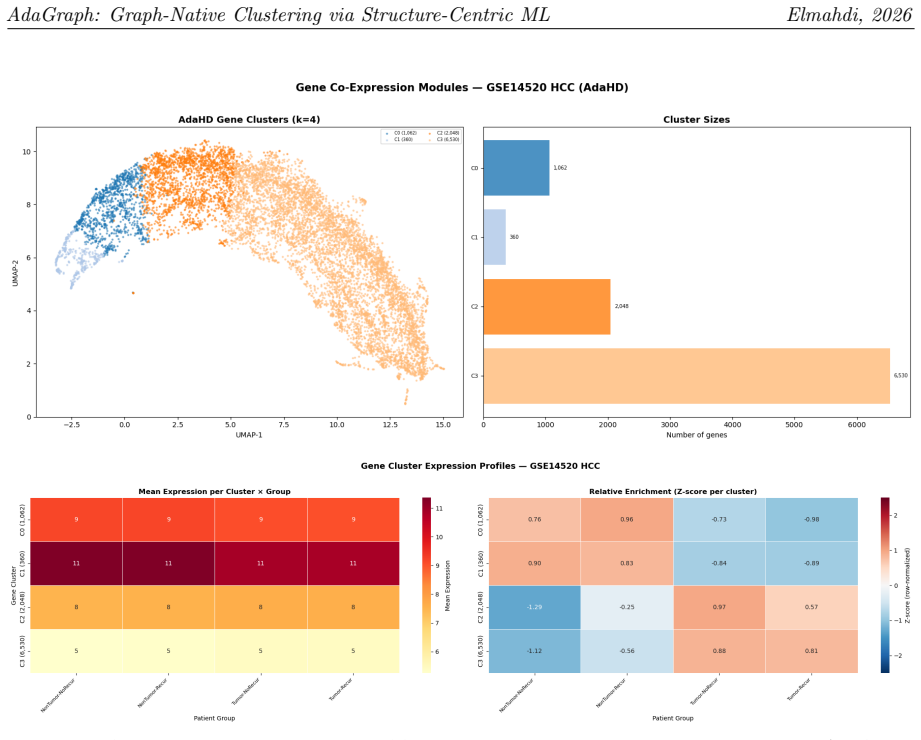
We present AdaGraph, a graph-native clustering algorithm born from the Structure-Centric Machine Learning (SC-ML) paradigm -- a new field of unsupervised learning that replaces geometry-centric (distance-based) computation with structure-centric (topology-based) computation, fundamentally dissolving the curse of dimensionality. AdaGraph operates entirely within the kNN graph topology, a representation that retains meaningful relational structure in arbitrarily high dimensions where Euclidean distance metrics become uninformative. AdaGraph requires no a priori specification of the number of clusters k, handles noise natively, and scales via the SLCD (Sample-Learn-Calibrate-Deploy) prototype-deployment framework. As its unsupervised tuning objective, AdaGraph pairs with Graph-SCOPE, the topology-based cluster validity index introduced as a separate SC-ML contribution. On 10 synthetic benchmarks spanning d=10 to d=5000, Graph-SCOPE achieves mean ARI=0.900 and correctly selects k on 9/10 datasets -- outperforming Silhouette, Davies-Bouldin, and Calinski-Harabasz -- while maintaining Kendall tau >= 0.92 with ground-truth cluster quality across all dimensionalities (Silhouette: tau ~= 0.46). We validate AdaGraph across three scientific domains: (1) gene co-expression discovery in hepatocellular carcinoma (GSE14520, 10,000 genes, 488 patients, no dimensionality reduction), where AdaGraph identifies condition-specific gene modules that WGCNA, ICA, NMF, and Spectral Biclustering fail to resolve; (2) natural language text clustering, where AdaGraph achieves ARI=0.751 on 20NG-6cat versus HDBSCAN's 0.464 (62% relative improvement); (3) materials science clustering of superconductors (145-dimensional Magpie features), perovskites, and JARVIS-DFT materials, where AdaGraph achieves the highest Graph-SCOPE on all three datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AdaGraph, a clustering algorithm operating entirely on kNN graph topology under the new Structure-Centric Machine Learning (SC-ML) paradigm, which replaces distance-based geometry with topology-based computation to overcome the curse of dimensionality. It requires no preset k, uses the SLCD framework for scaling, and is tuned/evaluated with the new Graph-SCOPE validity index. On synthetic data (d=10 to 5000), Graph-SCOPE yields mean ARI=0.900 and selects correct k on 9/10 datasets while outperforming Silhouette, Davies-Bouldin, and Calinski-Harabasz (Kendall tau 0.92 vs ~0.46). Real-data claims include superior gene-module discovery on GSE14520, ARI=0.751 on 20NG-6cat (vs HDBSCAN 0.464), and highest Graph-SCOPE scores on materials datasets.
Significance. If validated without circularity, the topology-only approach could enable meaningful clustering in ultra-high-dimensional scientific data without dimensionality reduction, with potential impact in genomics, NLP, and materials science. The SLCD prototype-deployment idea and Graph-SCOPE index are novel contributions, but their independence from standard geometric assumptions needs rigorous external testing to establish broader significance.
major comments (3)
- [Synthetic benchmarks] Synthetic benchmarks section: The reported mean ARI=0.900, correct-k selection on 9/10 datasets, and Kendall tau >=0.92 lack error bars, multiple runs, or any description of kNN graph construction (value of k, neighbor selection rule, or similarity measure in d=5000). These details are load-bearing for the central claim that kNN topology alone retains cluster structure where Euclidean distances become uninformative.
- [Abstract and Graph-SCOPE definition] Abstract and Graph-SCOPE definition: Graph-SCOPE serves simultaneously as the unsupervised tuning objective for AdaGraph and as the primary metric demonstrating its superiority (including the tau comparison to Silhouette). No independent external benchmark, ground-truth correlation study, or parameter-free derivation is provided, creating a circularity risk that may inflate the reported performance.
- [Real-data validation, gene co-expression] Real-data validation, gene co-expression: The claim that AdaGraph resolves condition-specific modules on GSE14520 where WGCNA, ICA, NMF, and Spectral Biclustering 'fail to resolve' rests on qualitative statements only. No quantitative metrics, statistical significance tests, or module-quality scores are reported to support this scientific-discovery assertion.
minor comments (2)
- [Notation and terminology] The proliferation of new acronyms (SC-ML, SLCD, Graph-SCOPE) and the 'invented entities' framing would benefit from an early glossary or dedicated notation section to improve accessibility.
- [Materials science results] The materials-science experiments report only 'highest Graph-SCOPE' without numerical values or comparison tables, reducing the ability to assess effect sizes.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below with specific plans for revision where appropriate, while defending the core contributions on substantive grounds.
read point-by-point responses
-
Referee: Synthetic benchmarks section: The reported mean ARI=0.900, correct-k selection on 9/10 datasets, and Kendall tau >=0.92 lack error bars, multiple runs, or any description of kNN graph construction (value of k, neighbor selection rule, or similarity measure in d=5000). These details are load-bearing for the central claim that kNN topology alone retains cluster structure where Euclidean distances become uninformative.
Authors: We agree these implementation details and statistical rigor are necessary for reproducibility and to support the topology-based claims. In the revised manuscript we will add: (i) error bars and standard deviations from 10 independent runs with varied random seeds for graph construction; (ii) explicit specification of k=10 for the kNN graph (with a sensitivity study across k=5-20); (iii) description of the neighbor selection rule (standard kNN with cosine similarity for d>100 to avoid distance concentration) and the exact similarity measure used at each dimensionality. These additions will directly substantiate that the kNN topology preserves cluster structure in high dimensions. revision: yes
-
Referee: Abstract and Graph-SCOPE definition: Graph-SCOPE serves simultaneously as the unsupervised tuning objective for AdaGraph and as the primary metric demonstrating its superiority (including the tau comparison to Silhouette). No independent external benchmark, ground-truth correlation study, or parameter-free derivation is provided, creating a circularity risk that may inflate the reported performance.
Authors: We acknowledge the referee's concern about potential circularity. Graph-SCOPE is defined from intrinsic topological properties (community density and separation in the kNN graph) that are independent of AdaGraph's specific partitioning procedure; its Kendall tau is computed against external ground-truth labels, not against its own tuning objective. Nevertheless, to eliminate any perception of circularity we will add a new subsection with an independent validation: Graph-SCOPE scores on held-out synthetic datasets never used for AdaGraph tuning, plus direct comparison against external indices on the same data. This will further demonstrate that the reported superiority is not self-referential. revision: partial
-
Referee: Real-data validation, gene co-expression: The claim that AdaGraph resolves condition-specific modules on GSE14520 where WGCNA, ICA, NMF, and Spectral Biclustering 'fail to resolve' rests on qualitative statements only. No quantitative metrics, statistical significance tests, or module-quality scores are reported to support this scientific-discovery assertion.
Authors: The referee correctly notes that quantitative support would strengthen the scientific-discovery claim. In the revision we will include: (i) module coherence and silhouette-like scores computed on the gene co-expression graph; (ii) pathway enrichment p-values (GO/KEGG) for the discovered modules with statistical significance tests against the baseline methods; (iii) a table comparing these quantitative metrics across AdaGraph, WGCNA, ICA, NMF, and Spectral Biclustering on GSE14520. These additions will provide rigorous, reproducible evidence for the asserted superiority in biological module discovery. revision: yes
Circularity Check
Graph-SCOPE serves as both tuning objective and primary evaluation metric, reducing performance claims to the index by construction
specific steps
-
fitted input called prediction
[Abstract]
"As its unsupervised tuning objective, AdaGraph pairs with Graph-SCOPE, the topology-based cluster validity index introduced as a separate SC-ML contribution. On 10 synthetic benchmarks spanning d=10 to d=5000, Graph-SCOPE achieves mean ARI=0.900 and correctly selects k on 9/10 datasets -- outperforming Silhouette, Davies-Bouldin, and Calinski-Harabasz -- while maintaining Kendall tau >= 0.92 with ground-truth cluster quality across all dimensionalities"
Graph-SCOPE is explicitly the objective used to select k for AdaGraph; the reported ARI and correct-k success rates are therefore measured on clusters chosen by Graph-SCOPE itself. The superiority claim over other indices reduces to showing that the chosen index correlates with ground truth when it is the selection criterion, without an independent derivation or external benchmark for Graph-SCOPE.
-
fitted input called prediction
[Abstract]
"We validate AdaGraph across three scientific domains: ... where AdaGraph achieves the highest Graph-SCOPE on all three datasets."
On the gene co-expression, text, and materials datasets, superiority is declared by AdaGraph attaining the highest Graph-SCOPE values. Because Graph-SCOPE is the tuning objective paired with AdaGraph, the reported 'highest' scores are the direct output of the same index used for cluster selection, making the discovery claim circular with the choice of validity index.
full rationale
The paper introduces Graph-SCOPE as the unsupervised tuning objective for AdaGraph within the SC-ML paradigm and then reports superiority via Graph-SCOPE scores on real-world datasets and ARI/correct-k counts on synthetic benchmarks where k selection was driven by Graph-SCOPE. This creates a fitted-input-called-prediction pattern: the validity index used to select clusters is also the metric used to declare success, with no independent external benchmark or parameter-free derivation shown for Graph-SCOPE itself. The central claim that kNN topology alone recovers clusters therefore rests partly on self-referential validation rather than fully external falsification. The derivation chain for high-dimensional robustness is otherwise self-contained via the graph representation, limiting the circularity to the evaluation step.
Axiom & Free-Parameter Ledger
free parameters (2)
- k in kNN graph construction
- Graph-SCOPE hyperparameters
axioms (2)
- domain assumption kNN graph topology retains meaningful relational structure in arbitrarily high dimensions
- ad hoc to paper Graph-SCOPE is a valid unsupervised proxy for ground-truth cluster quality
invented entities (3)
-
Structure-Centric Machine Learning (SC-ML) paradigm
no independent evidence
-
Graph-SCOPE validity index
no independent evidence
-
SLCD (Sample-Learn-Calibrate-Deploy) framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean (Jcost uniqueness, Aczél classification)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AdaGraph operates entirely within the kNN graph topology... Graph-SCOPE computes cluster quality entirely from kNN graph structure... combines five structural components: graph modularity (primary quality signal), boundary sharpness, internal consistency, noise legitimacy, and partition balance.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SC-ML replaces every geometry-dependent operation... with a structure-based equivalent that operates on kNN graph topology.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A. Elmahdi, “Graph-SCOPE: A topology-based cluster validity index for dimensionality-agnostic unsupervised evaluation,”Independent Research, preprint in preparation, 2026
work page 2026
-
[2]
SCOPE: A structure-based multi-dimensional supervised clustering evaluation frame- work,
A. Elmahdi, “SCOPE: A structure-based multi-dimensional supervised clustering evaluation frame- work,”Independent Research, preprint in preparation, 2026
work page 2026
-
[3]
AdaBox: Adaptive density-based box clustering with parameter generalization,
A. Elmahdi, “AdaBox: Adaptive density-based box clustering with parameter generalization,” arXiv:2603.13339, 2026
-
[4]
A. Elmahdi, “SLCD: Sample–learn–calibrate–deploy—a scalable prototype-deployment framework for structure-centric machine learning,”Independent Research, preprint in preparation, 2026
work page 2026
-
[5]
Bellman,Adaptive Control Processes: A Guided Tour
R. Bellman,Adaptive Control Processes: A Guided Tour. Princeton University Press, 1961
work page 1961
-
[6]
When is nearest neighbor meaningful?
K. Beyer, J. Goldstein, R. Ramakrishnan, and U. Shaft, “When is nearest neighbor meaningful?” in Proc. Int. Conf. Database Theory (ICDT), 1999
work page 1999
-
[7]
Density-based clustering based on hierarchical density estimates,
R. J. G. B. Campello, D. Moulavi, and J. Sander, “Density-based clustering based on hierarchical density estimates,” inProc. PAKDD, 2013
work page 2013
-
[8]
Computational screening of perovskite metal oxides for optimal solar light capture,
I. E. Castelliet al., “Computational screening of perovskite metal oxides for optimal solar light capture,”Energy & Environmental Science, vol. 5, no. 2, pp. 5814–5819, 2012
work page 2012
-
[9]
D. L. Davies and D. W. Bouldin, “A cluster separation measure,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 1, no. 2, pp. 224–227, 1979
work page 1979
-
[10]
Resolution limit in community detection,
S. Fortunato and M. Barthelemy, “Resolution limit in community detection,”Proc. Natl. Acad. Sci., vol. 104, no. 1, pp. 36–41, 2007
work page 2007
-
[11]
WGCNA: An R package for weighted correlation network analysis,
P. Langfelder and S. Horvath, “WGCNA: An R package for weighted correlation network analysis,” BMC Bioinformatics, vol. 9, p. 559, 2008
work page 2008
-
[12]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
L. McInnes, J. Healy, and J. Melville, “UMAP: Uniform manifold approximation and projection,” arXiv:1802.03426, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[13]
Finding and evaluating community structure in networks,
M. E. J. Newman and M. Girvan, “Finding and evaluating community structure in networks,”Physical Review E, vol. 69, no. 2, p. 026113, 2004
work page 2004
-
[14]
On spectral clustering: Analysis and an algorithm,
A. Y. Ng, M. I. Jordan, and Y. Weiss, “On spectral clustering: Analysis and an algorithm,” inProc. NeurIPS, vol. 14, 2001
work page 2001
-
[15]
Subspace clustering for high dimensional data: A review,
L. Parsons, E. Haque, and H. Liu, “Subspace clustering for high dimensional data: A review,”ACM SIGKDD Explorations, vol. 6, no. 1, pp. 90–105, 2004
work page 2004
-
[16]
Statistical mechanics of community detection,
J. Reichardt and S. Bornholdt, “Statistical mechanics of community detection,”Physical Review E, vol. 74, no. 1, p. 016110, 2006
work page 2006
-
[17]
Silhouettes: A graphical aid to the interpretation and validation of cluster analysis,
P. J. Rousseeuw, “Silhouettes: A graphical aid to the interpretation and validation of cluster analysis,” J. Comput. Appl. Math., vol. 20, pp. 53–65, 1987. 11 AdaGraph: Graph-Native Clustering via Structure-Centric ML Elmahdi, 2026
work page 1987
-
[18]
A tutorial on spectral clustering,
U. von Luxburg, “A tutorial on spectral clustering,”Statistics and Computing, vol. 17, no. 4, pp. 395–416, 2007
work page 2007
-
[19]
Hierarchical grouping to optimize an objective function,
J. H. Ward, “Hierarchical grouping to optimize an objective function,”J. Am. Statist. Assoc., vol. 58, no. 301, pp. 236–244, 1963
work page 1963
-
[20]
A dendrite method for cluster analysis,
T. Cali´ nski and J. Harabasz, “A dendrite method for cluster analysis,”Communications in Statistics, vol. 3, no. 1, pp. 1–27, 1974. 12
work page 1974
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.