OmniVL-Guard Pro: A Tool-Augmented Agent for Omnibus Vision-Language Forensics
Pith reviewed 2026-05-21 07:41 UTC · model grok-4.3
The pith
A tool-augmented agent moves vision-language forgery detection from closed-world model predictions to open-world reasoning that pulls in external clues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
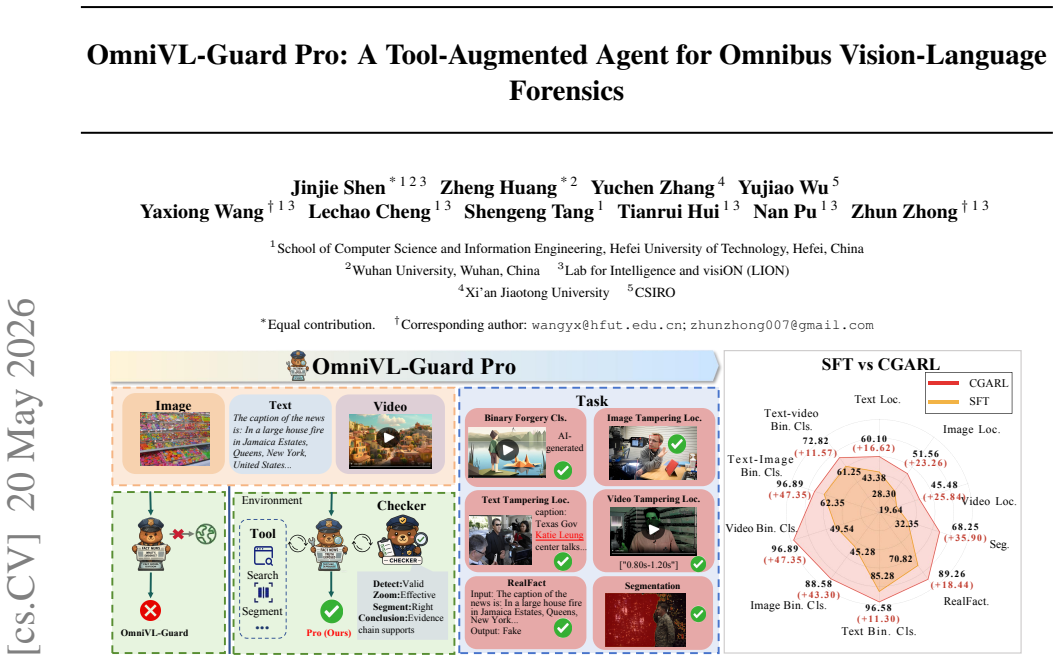
OmniVL-Guard Pro integrates tools for real-time event search, local cropping and zooming, edge-anomaly screening, face detection, video frame extraction, and SAM3-based segmentation. Tree-Structured Self-Evolving Tool Trajectory Generation produces diverse reasoning paths through seed guidance, self-evolution, and hard-sample synthesis to build the Full-Spectrum Tool Reasoning dataset. Checker-Guided Agentic Reinforcement Learning supplies process-level supervision that penalizes correct answers reached by flawed steps. Together these elements let the agent perform unified forensics in open-world settings, delivering state-of-the-art results and strong zero-shot generalization.
What carries the argument
The tool-augmented agent that combines external tools with a vision-language backbone, trained via tree-structured self-evolving trajectory generation and checker-guided agentic reinforcement learning.
If this is right
- Real-time event verification becomes feasible by querying external sources instead of depending on static parametric knowledge.
- Fine-grained forgery segmentation improves through repeated local cropping, zooming, and anomaly screening on manipulated regions.
- Zero-shot generalization extends to new forgery types and scenarios because the agent can gather fresh clues on demand.
- Process-level supervision reduces cases where the model reaches the right answer through distorted reasoning steps.
- Unified forensics shifts from closed-world prediction to open-world clues-driven reasoning across images and video.
Where Pith is reading between the lines
- The same tool-use pattern could apply to other domains where models need current external information, such as verifying claims in news videos or analyzing medical scans with up-to-date references.
- Adding more specialized tools like 3D reconstruction or cross-modal web search might further raise performance on complex manipulations.
- Heavy use of synthetic trajectories for training invites tests on purely real-world data to check whether the agent still avoids tool-induced errors outside the generated distribution.
Load-bearing premise
The proposed tool environment and training procedures will reliably produce high-quality trajectories and process-level supervision without introducing tool-induced errors or overfitting to synthetic data.
What would settle it
Performance on a held-out set of real-time forgery cases from live events drops to the level of a non-tool baseline when the agent is restricted to internal knowledge only and denied access to its external search and analysis tools.
Figures




read the original abstract
Existing vision-language forgery detection and grounding methods operate under a closed-world paradigm, assuming verification can be completed by the model alone. However, self-contained MLLMs are constrained by finite parametric knowledge, static training corpora, and limited perceptual resolution, creating a practical ceiling in dynamic open-world forensics -- particularly for real-time event verification requiring external clues and forgery segmentation demanding fine-grained scrutiny of local manipulations. To address these limitations, we shift from scaling up the self-contained model toward reaching beyond it. We propose \textbf{OmniVL-Guard Pro}, a tool-augmented agent that extends unified forensics from closed-world prediction to open-world clues-driven reasoning. OmniVL-Guard Pro integrates a tool environment spanning real-time event search, local cropping and zooming, edge-anomaly screening, face detection, video frame extraction, and SAM3-based segmentation. To generate high-quality tool-reasoning trajectories, we introduce \textbf{Tree-Structured Self-Evolving Tool Trajectory Generation}, which produces diverse trajectories through seed guidance, guider-free self-evolution, and weakly-hinted hard sample synthesis, yielding the Full-Spectrum Tool Reasoning (FSTR) dataset for training. We further propose \textbf{Checker-Guided Agentic Reinforcement Learning} (CGARL), which provides process-level supervision to penalize cases where the answer is correct but the reasoning is distorted. Extensive experiments demonstrate that OmniVL-Guard Pro achieves state-of-the-art performance across various tasks, and exhibits strong zero-shot generalization. The FSTR dataset and code for OmniVL-Guard Pro will be publicly released at https://github.com/shen8424/OmniVL-Guard-Pro.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes OmniVL-Guard Pro, a tool-augmented agent for vision-language forgery detection and grounding. It integrates an environment of external tools (real-time event search, local cropping/zooming, edge-anomaly screening, face detection, video frame extraction, SAM3 segmentation) to overcome limitations of self-contained MLLMs in open-world scenarios. The authors introduce Tree-Structured Self-Evolving Tool Trajectory Generation (via seed guidance, guider-free evolution, and weakly-hinted hard-sample synthesis) to produce the Full-Spectrum Tool Reasoning (FSTR) dataset, and Checker-Guided Agentic Reinforcement Learning (CGARL) to supply process-level supervision that penalizes correct answers reached via distorted reasoning. They claim this yields SOTA performance across tasks and strong zero-shot generalization.
Significance. If the empirical results hold, the work would be significant for shifting vision-language forensics from closed-world parametric prediction to open-world, tool-augmented reasoning. The combination of a new trajectory-generation procedure, process-level RL supervision, and public release of the FSTR dataset plus code would offer a concrete, reproducible path for handling dynamic events and fine-grained manipulations that exceed static model knowledge.
major comments (3)
- [Abstract] Abstract: The central claim that 'OmniVL-Guard Pro achieves state-of-the-art performance across various tasks, and exhibits strong zero-shot generalization' is presented without any metrics, baselines, ablation tables, or error analysis. This absence makes the generalization and SOTA assertions impossible to evaluate and is load-bearing for the paper's contribution.
- [Method] Method section on Tree-Structured Self-Evolving Tool Trajectory Generation: The procedure (seed guidance, guider-free self-evolution, weakly-hinted hard-sample synthesis) is asserted to produce high-quality trajectories for the FSTR dataset, yet no quantitative checks on trajectory fidelity, tool-error amplification (e.g., from real-time search or SAM3), or synthetic-vs-real failure modes are described. This directly affects the validity of the open-world reasoning claim.
- [Method] CGARL description: The Checker-Guided Agentic Reinforcement Learning is said to provide process-level supervision that penalizes 'correct answer but distorted reasoning,' but the manuscript supplies no implementation details, reward formulation, or ablation isolating the effect of this supervision versus standard outcome-only RL. Without such evidence the process-supervision benefit remains unsubstantiated.
minor comments (2)
- [Title] The title uses 'Omnibus Vision-Language Forensics'; a short clarification of how 'omnibus' differs from 'unified' would improve readability.
- [Abstract] The abstract promises public release of the FSTR dataset and code; adding a brief statement on licensing or access timeline would strengthen the reproducibility claim.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable suggestions. We address each of the major comments in detail below and outline the revisions we intend to make to improve the clarity and substantiation of our contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'OmniVL-Guard Pro achieves state-of-the-art performance across various tasks, and exhibits strong zero-shot generalization' is presented without any metrics, baselines, ablation tables, or error analysis. This absence makes the generalization and SOTA assertions impossible to evaluate and is load-bearing for the paper's contribution.
Authors: We agree with the referee that the abstract would benefit from including quantitative evidence to support the SOTA and zero-shot generalization claims. In the revised manuscript, we will modify the abstract to incorporate key results, such as specific accuracy figures on benchmark datasets, comparisons to leading baselines, and highlights from the zero-shot experiments. This change will allow readers to better evaluate the claims without needing to consult the full results section. revision: yes
-
Referee: [Method] Method section on Tree-Structured Self-Evolving Tool Trajectory Generation: The procedure (seed guidance, guider-free self-evolution, weakly-hinted hard-sample synthesis) is asserted to produce high-quality trajectories for the FSTR dataset, yet no quantitative checks on trajectory fidelity, tool-error amplification (e.g., from real-time search or SAM3), or synthetic-vs-real failure modes are described. This directly affects the validity of the open-world reasoning claim.
Authors: The referee correctly identifies a gap in the current manuscript regarding quantitative validation of the generated trajectories. Although the overall experimental results demonstrate the effectiveness of the approach, we did not include dedicated metrics for trajectory fidelity or analyses of potential error propagation from tools such as real-time search and SAM3. We will add this analysis in the revised version, including quantitative checks such as success rates of tool calls, error amplification studies, and comparisons of synthetic versus real-world failure cases. This will strengthen the support for the open-world reasoning claims. revision: yes
-
Referee: [Method] CGARL description: The Checker-Guided Agentic Reinforcement Learning is said to provide process-level supervision that penalizes 'correct answer but distorted reasoning,' but the manuscript supplies no implementation details, reward formulation, or ablation isolating the effect of this supervision versus standard outcome-only RL. Without such evidence the process-supervision benefit remains unsubstantiated.
Authors: We acknowledge that the description of Checker-Guided Agentic Reinforcement Learning (CGARL) in the manuscript is high-level and lacks the specific implementation details requested. To address this, we will expand the relevant section in the revision to include the precise reward formulation, pseudocode or algorithmic details for the checker-guided process, and an ablation study that isolates the contribution of process-level supervision compared to outcome-only reinforcement learning. These additions will provide the necessary evidence to substantiate the benefits of our approach. revision: yes
Circularity Check
No circularity: empirical claims rest on proposed methods and experiments, not self-referential reductions
full rationale
The paper introduces a tool-augmented agent with a described tool environment and two new training procedures (Tree-Structured Self-Evolving Tool Trajectory Generation yielding the FSTR dataset, plus Checker-Guided Agentic Reinforcement Learning) and then reports SOTA performance and zero-shot generalization from extensive experiments. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text; the central claims are framed as direct empirical outcomes of the new architecture and supervision signals rather than derivations that collapse to their own inputs by construction. The chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Hyperparameters for CGARL and trajectory generation
axioms (1)
- domain assumption External tools provide accurate, unbiased, and useful clues for forgery verification without introducing new failure modes.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Tree-Structured Self-Evolving Tool Trajectory Generation... Checker-Guided Agentic Reinforcement Learning (CGARL)
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
OmniVL-Guard Pro integrates a tool environment spanning real-time event search, local cropping... SAM3-based segmentation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Is the event time correctly extracted?
-
[2]
Is the subject correctly identified?
-
[3]
Is the location correctly identified?
-
[4]
Is the key action correctly described?
-
[5]
Is the outcome correctly stated? Input Data: News Article:{article text}Extracted Information:{extracted json} Output Format:For each field, respond with “Correct” or “Incorrect” and provide a brief explanation if incorrect. 13 OmniVL-Guard Pro Prompt 3: Leakage Check (GPT-5.4) System Instruction:You are an expert quality assurance assistant. Your task is...
-
[6]
Does the claim contain obvious factual errors that can be detected without verification?
-
[7]
Does the claim contain self-contradictory information?
-
[8]
Does the claim contain explicit hints about its truthfulness? Input Data: Claim:{claim text}Evidence:{evidence text} Output Format:Respond with “No Leakage” if the claim does not contain obvious cues, or “Leakage Detected” with explanation. Prompt 4: Parametric Memory Reasoning (Qwen3VL-235B) System Instruction:You are a knowledgeable assistant. Based sol...
-
[9]
Consider the factual accuracy of the claim
-
[10]
Consider the temporal consistency (does the time match known events?)
-
[11]
True” if you believe the claim is factually correct. • “False
Consider the plausibility of the described event. Input Data: Claim:{claim text} Output Format:Respond with: • “True” if you believe the claim is factually correct. • “False” if you believe the claim is factually incorrect. • “Uncertain” if you cannot determine the truthfulness from your knowledge. Prompt 5: Evidence-Grounded Reasoning (Qwen3VL-235B) Syst...
-
[12]
Does the evidence support the claim?
-
[13]
Is there any contradiction between the claim and the evidence?
-
[14]
Is the evidence sufficient to make a definitive judgment? Input Data: Claim:{claim text}Evidence:{evidence text} Output Format:Respond with: • “Supported” if the evidence confirms the claim is true. • “Refuted” if the evidence contradicts the claim. • “Insufficient” if the evidence is not enough to make a judgment. 14 OmniVL-Guard Pro B.3. Human Verificat...
-
[15]
For negative samples, the introduced manipulation should be realistic and non-trivial
Claim Authenticity:Does the claim accurately reflect the original event? For positive samples, the claim should be factually consistent with the event. For negative samples, the introduced manipulation should be realistic and non-trivial
-
[16]
Evidence Sufficiency:Is the provided evidence sufficient to verify or refute the claim? The evidence should be directly relevant and conclusive
-
[17]
Temporal Consistency:Is the event timestamp accurate and consistent with the claim? The temporal information should be verifiable through the evidence
-
[18]
Manipulation Subtlety:For negative samples, is the manipulation subtle enough to challenge models? Obvious or trivial manipulations are flagged for removal. ▷Verification Results:98.6% of the sampled instances are accepted, indicating high quality of the automated pipeline. These results demonstrate that our automated construction pipeline produces high-q...
work page 2025
-
[19]
Parameter Quality:Are the tool parameters (e.g., search query, crop box, zoom region) specific and reason- able? 3.Observation Utility:Does the returned observation provide useful, non-redundant information? 4.Progress Toward Answer:Does this step bring the reasoning closer to the ground truth answera ⋆? Input Data: Task Question: {question} Ground Truth ...
-
[20]
Trajectory Coherence:The overall trajectory should be logically coherent, with each step building upon previous steps without abrupt jumps or contradictions
-
[21]
Evidence Support:The intermediate reasoning steps and tool usage should collectively support the final conclusion. The evidence gathered should directly verify or refute the claim, reveal manipulations, or localize relevant regions
-
[22]
No Ineffective Steps:The trajectory should not contain redundant tool invocations, empty observations, or reasoning steps that do not contribute to the final conclusion
-
[23]
Completeness:The trajectory should contain sufficient evidence to support the prediction, rather than arriving at the correct answer through lucky guessing. The detailed prompt used for trajectory quality assessment is provided below. Prompt for Trajectory Quality Assessment System Instruction:You are an expert quality assessor for tool-use trajectories i...
-
[24]
Judgment:Evaluate whether the tool step is valid based on tool relevance, parameter quality, observation utility, and progress toward the answer
-
[25]
Weak Hint:If the step is invalid or suboptimal, provide a weak hint to guide the Explorer. The hint should be: • Sufficient to narrow down the search space (e.g., a rough region for cropping, keywords for search). • Vague enough to avoid directly revealing the answera ⋆. • Focused on local clues rather than global conclusions. Input Data: Task Question: {...
-
[26]
Remove explicit references to the hint (e.g., “the Guider suggested region X”→ “based on visual analysis, region X appears suspicious”)
-
[27]
Rephrase the reasoning to sound as if it were generated autonomously by the Explorer
-
[28]
The detailed prompt used for theRefineris provided below
Preserve the factual content and logical flow of the original reasoning. The detailed prompt used for theRefineris provided below. 18 OmniVL-Guard Pro Prompt for Refiner (Hint Trace Elimination) System Instruction:You are an expert Refiner responsible for rewriting reasoning processes in tool-use trajectories. Your task is to eliminate explicit traces of ...
-
[29]
Remove any explicit references to hints (e.g., “the Guider suggested...”, “based on the hint...”)
-
[30]
Rephrase the reasoning to sound natural and autonomous, as if the Explorer discovered the information through its own analysis
-
[31]
Preserve the factual content, logical flow, and tool invocation decisions
-
[32]
Ensure the rewritten reasoning is consistent with the tool invocationu t and the returned observationo t. Input Data: Task Question: {question} Original Trajectory: τ={(r t, ut, ot)}T t=1 ∪ {ˆa}Weak Hints Used: {hints provided by the Guider at each step} Output Format:Return the rewritten trajectory with hint traces eliminated: τ ′ ={(r ′ t, ut, ot)}T t=1...
-
[33]
Task-Specific Performance Reward (Rtask) We employ distinct metrics for different forensic tasks. To encourage the model to strive for high-precision grounding rather than mediocre overlap, we apply an exponential mapping function to continuous metrics (IoU, F1, tIoU). • Binary Forgery Classification:For the binary classification task, we use a simple dis...
-
[34]
Format Compliance Reward (Rfmt) To enforce the tool trajectory structure, we employ a strict regular expression check. The model receives a positive reward if and only if the output strictly follows the required format: Rfmt = ( 0.2if format is valid 0.0otherwise (16)
-
[35]
Repetition Penalty (Rrep) To prevent degenerate generation loops, we implement an N-gram repetition penalty. We calculate the ratio of unique N-grams to total N-grams in the generated text. With a set hyperparameters of N= 3 and a maximum penalty coefficient λpen =−1.0, the penalty is defined as: Rrep =λ pen × 1− |SN unique| Ntotal ! (17) where |SN unique...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.