Beyond Accuracy: Robustness, Interpretability and Expressiveness of EEG Foundation Models
Pith reviewed 2026-05-20 13:45 UTC · model grok-4.3
The pith
No single EEG foundation model dominates every robustness test, with models attending to correct brain regions but decoding corrupted signals when perturbed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
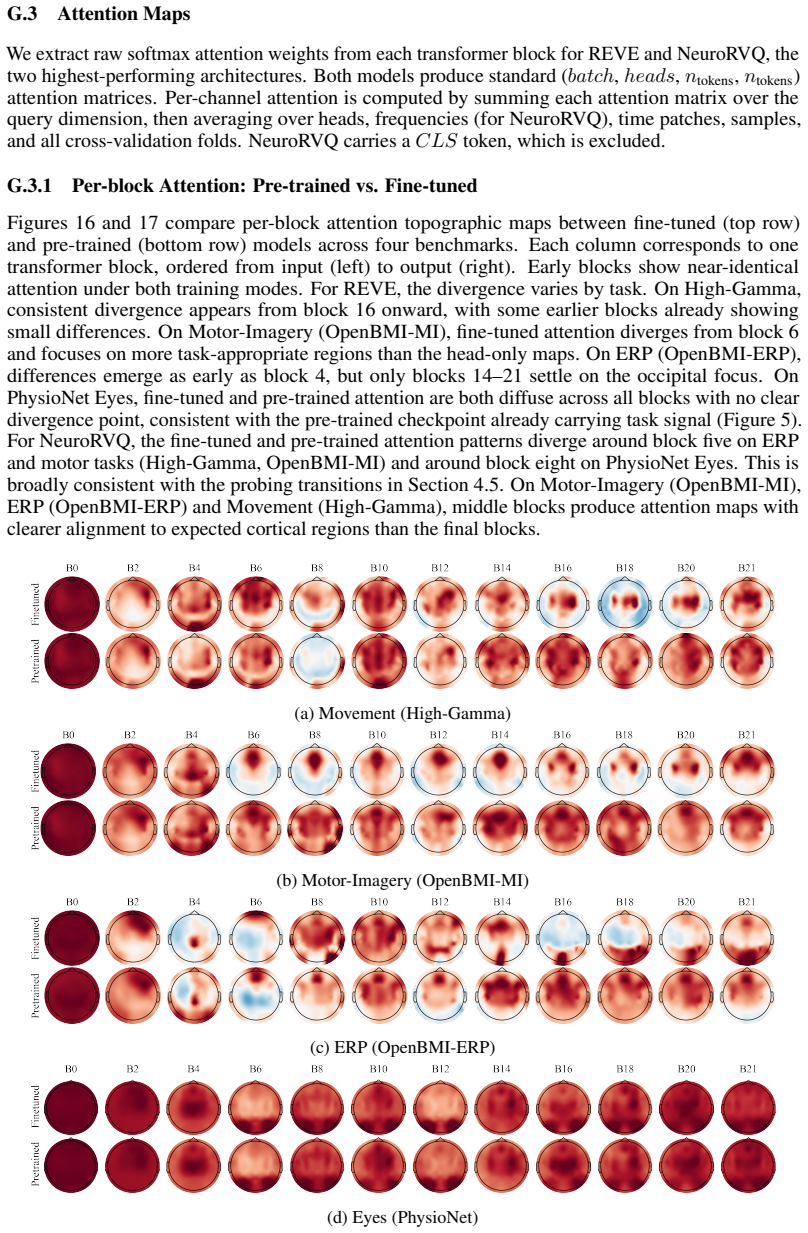
No single EEG-FM dominates all failure modes. Models concentrate relevance on task-appropriate brain regions consistent with known neurophysiology but decode corrupted content when inputs are perturbed. Late blocks are repurposed during fine-tuning while early blocks already hold task-related information. Poor head-only performance is largely explained by pooling rather than low-quality pre-trained representations.
What carries the argument
Test-time perturbations (additive noise, channel dropout, region-specific noise) combined with Attention-Aware Layer-Wise Relevance Propagation and block-wise probing to dissect robustness, interpretability, and expressiveness beyond accuracy.
If this is right
- Different EEG foundation models will suit different expected data corruption patterns in practice.
- Models attend to appropriate regions but require mechanisms to better decode signals when content is corrupted.
- Fine-tuning mainly adapts later layers, so targeted adaptation of early layers may be unnecessary.
- Preserving token-level embeddings rather than relying on pooled heads improves expressiveness for downstream tasks.
Where Pith is reading between the lines
- Real-world EEG deployments would benefit from robustness benchmarks that include additional artifact types such as motion or electrode drift.
- Stable attribution maps under performance drops suggest a need for training objectives that enforce content fidelity in addition to spatial focus.
- Early-layer features could support efficient transfer to new tasks with limited labeled EEG data.
Load-bearing premise
The chosen perturbations and eight datasets capture the main real-world failure modes that matter for EEG foundation model deployment.
What would settle it
A single EEG foundation model that consistently outperforms the others across additive noise, channel dropout, and region-specific noise on all eight datasets would falsify the no-single-dominance result.
Figures























read the original abstract
EEG foundation models (EEG-FMs) have been evaluated predominantly on clean, in-distribution accuracy, leaving their robustness, interpretability and representational quality largely unexamined. This study addresses these gaps by benchmarking six EEG-FMs against a baseline deep learning model across eight datasets. Beyond clean accuracy, we conduct three layers of analysis: (i) Robustness: we apply test-time perturbations including additive noise, random and region-based channel dropout and region-specific noise injection. Our analyses show that no single model dominates all failure modes. The most noise-robust model is among the most fragile under channel dropout and much of the dropout fragility disappears when channels are removed rather than zero-padded. (ii) Interpretability: we present the first application of Attention-Aware Layer-Wise Relevance Propagation (AttnLRP) to EEG-FMs and show that models broadly concentrate relevance on task-appropriate brain regions consistent with known neurophysiology. However, attribution maps remain spatially stable under perturbation while predictions degrade, suggesting that the models attend to the correct brain regions but decode corrupted content. (iii) Expressiveness: With block-wise probing we show that late blocks are repurposed during fine-tuning, while early blocks already hold task-related information. Furthermore, we demonstrate that the poor head-only performance previously attributed to low-quality pre-trained representations is largely explained by pooling and that EEG-FMs possess sufficient representational capacity when their token-level embeddings are preserved. Together, these findings provide the first systematic assessment of robustness, interpretability and expressiveness for EEG-FMs and highlight critical considerations for their development.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript benchmarks six EEG foundation models (EEG-FMs) against a baseline deep learning model across eight datasets. Beyond clean accuracy, it evaluates robustness via test-time perturbations (additive noise, random/region channel dropout, region-specific noise), applies Attention-Aware Layer-Wise Relevance Propagation (AttnLRP) to show that models concentrate relevance on task-appropriate brain regions consistent with neurophysiology (yet attribution maps remain stable while predictions degrade under perturbation), and uses block-wise probing to demonstrate that late blocks are repurposed during fine-tuning while early blocks already contain task-related information. It further claims that poor head-only performance is largely explained by pooling operations rather than low-quality pre-trained representations, concluding that no single EEG-FM dominates all failure modes.
Significance. If the results hold, this provides the first systematic multi-faceted evaluation of EEG-FMs beyond accuracy, offering practical guidance on model selection for noisy real-world EEG data and clarifying how pre-trained representations are utilized during fine-tuning. The alignment of attribution maps with known neurophysiology and the clarification of pooling effects are particularly useful strengths.
major comments (1)
- [Robustness analysis] Robustness section (abstract and methods): The central claim that 'no single model dominates all failure modes' and the reported trade-offs (noise-robust models being dropout-fragile) rest exclusively on the four synthetic perturbation families (additive noise, random/region channel dropout, region-specific noise) applied at test time. These are not calibrated against empirical distributions of real EEG artifacts (e.g., muscle artifact, electrode displacement, baseline wander, or non-stationary drift), nor is there an ablation adding physiologically motivated corruptions. This makes it unclear whether the observed rankings and fragility patterns generalize or are artifacts of the chosen test distribution.
minor comments (1)
- [Abstract] The abstract states that 'much of the dropout fragility disappears when channels are removed rather than zero-padded' but provides no quantitative deltas, exact experimental protocol, or reference to the relevant table/figure for this comparison.
Simulated Author's Rebuttal
We thank the referee for their insightful feedback on the robustness evaluation. We agree that the synthetic perturbations provide a controlled but limited perspective and have revised the manuscript to better acknowledge this limitation while preserving the value of the controlled analysis.
read point-by-point responses
-
Referee: [Robustness analysis] Robustness section (abstract and methods): The central claim that 'no single model dominates all failure modes' and the reported trade-offs (noise-robust models being dropout-fragile) rest exclusively on the four synthetic perturbation families (additive noise, random/region channel dropout, region-specific noise) applied at test time. These are not calibrated against empirical distributions of real EEG artifacts (e.g., muscle artifact, electrode displacement, baseline wander, or non-stationary drift), nor is there an ablation adding physiologically motivated corruptions. This makes it unclear whether the observed rankings and fragility patterns generalize or are artifacts of the chosen test distribution.
Authors: We appreciate this observation and agree that our robustness results are based on synthetic perturbations chosen for their reproducibility and ability to isolate specific failure modes (additive noise for signal degradation, channel dropout for electrode loss). These do not fully replicate the statistical properties of real EEG artifacts. In the revised manuscript we have added a new paragraph in the Discussion section that explicitly compares the chosen perturbations to common real-world artifacts, qualifies the scope of the 'no single model dominates' claim to the tested conditions, and identifies the need for future work with empirically calibrated corruptions. We have also updated the abstract and conclusions to reflect this scope. No new experiments were performed, as that would exceed the scope of a major revision. revision: partial
- Whether the observed model rankings and fragility patterns would persist under real-world EEG artifact distributions cannot be answered without new experiments using calibrated physiological corruptions.
Circularity Check
Empirical benchmarking study with no circular derivations or self-referential reductions
full rationale
The paper conducts an empirical benchmarking analysis of EEG foundation models across robustness (test-time perturbations on eight datasets), interpretability (AttnLRP attributions), and expressiveness (block-wise probing). No mathematical derivations, predictions, or first-principles results are presented that reduce to fitted parameters, self-definitions, or self-citation chains. All claims rest on external datasets, baselines, and experimental outcomes rather than internal redefinitions or ansatzes smuggled via prior work. This is a standard self-contained empirical study, warranting a score of 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selected perturbations adequately simulate real-world EEG artifacts and channel failures.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
no single model dominates all failure modes... models concentrate relevance on task-appropriate brain regions... late blocks are repurposed during fine-tuning while early blocks hold task-related information
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
eight datasets... region-based perturbations... 8-tick periodic micro-structure absent
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Kim, Hong-Kyung and Williamson, John and Lee, Min-Ho and Kwon, O-Yeon and Lee, Seong-Whan and Fazli, Siamac and Kim, Yong-Jeong and Lee, Young-Eun , year =. Supporting data for ``
-
[2]
Lee, Min-Ho and Kwon, O-Yeon and Kim, Yong-Jeong and Kim, Hong-Kyung and Lee, Young-Eun and Williamson, John and Fazli, Siamac and Lee, Seong-Whan , journal =. 2019 , volume =
work page 2019
-
[3]
and Kasanov, Dauren and Kosachenko, Alexandra I
Pavlov, Yuri G. and Kasanov, Dauren and Kosachenko, Alexandra I. and Kotyusov, Alexander I. , year =
-
[4]
Kemp, B. and Zwinderman, A. H. and Tuk, B. and Kamphuisen, H. A. C. and Oberye, J. J. L. , journal =. Analysis of a sleep-dependent neuronal feedback loop: the slow-wave microcontinuity of the. 2000 , volume =
work page 2000
-
[5]
PhysioBank, PhysioToolkit, and PhysioNet: Components of a New Research Resource for Complex Physiologic Signals , author =. Circulation , year =
-
[6]
Proceedings of the IEEE , year =
Motor imagery and direct brain--computer communication , author =. Proceedings of the IEEE , year =
-
[7]
Large Brain Model for Learning Generic Representations with Tremendous
Weibang Jiang and Liming Zhao and Bao-liang Lu , booktitle=. Large Brain Model for Learning Generic Representations with Tremendous. 2024 , doi =
work page 2024
-
[8]
Jiquan Wang and Sha Zhao and Zhiling Luo and Yangxuan Zhou and Haiteng Jiang and Shijian Li and Tao Li and Gang Pan , booktitle=. 2025 , doi=
work page 2025
-
[9]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Yassine El Ouahidi and Jonathan Lys and Philipp Th. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[10]
and Laskaris, Nikolaos and Zafeiriou, Stefanos , year =
Barmpas, Konstantinos and Lee, Na and Koliousis, Andreas and Panagakis, Yannis and Adamos, Dimitrios A. and Laskaris, Nikolaos and Zafeiriou, Stefanos , year =. CoRR , volume =
-
[11]
Chaoqi Yang and M Brandon Westover and Jimeng Sun , booktitle=. 2023 , doi =
work page 2023
-
[12]
BrainOmni: A Brain Foundation Model for Unified
Qinfan Xiao and Ziyun Cui and Chi Zhang and SiQi Chen and Wen Wu and Andrew Thwaites and Alexandra Woolgar and Bowen Zhou and Chao Zhang , booktitle=. BrainOmni: A Brain Foundation Model for Unified. 2026 , doi=
work page 2026
-
[13]
Lukas Rauch and René Heinrich and Houtan Ghaffari and Lukas Miklautz and Ilyass Moummad and Bernhard Sick and Christoph Scholz , title=. CoRR , volume=. 2025 , month=
work page 2025
-
[14]
Cheng and Hanlin Goh and Kaan Dogrusoz and Oncel Tuzel and Erdrin Azemi , title=
Joseph Y. Cheng and Hanlin Goh and Kaan Dogrusoz and Oncel Tuzel and Erdrin Azemi , title=. CoRR , volume=. 2020 , cdate=
work page 2020
-
[15]
Deep learning with convolutional neural networks for
Schirrmeister, Robin Tibor and Springenberg, Jost Tobias and Fiederer, Lukas Dominique Josef and Glasstetter, Martin and Eggensperger, Katharina and Tangermann, Michael and Hutter, Frank and Burgard, Wolfram and Ball, Tonio , journal =. Deep learning with convolutional neural networks for. 2017 , volume =
work page 2017
-
[16]
Santamaría-Vázquez, Eduardo and Martínez-Cagigal, Víctor and Vaquerizo-Villar, Fernando and Hornero, Roberto , journal=. EEG-Inception: A Novel Deep Convolutional Neural Network for Assistive ERP-Based Brain-Computer Interfaces , year=
-
[17]
BrainWave-Scattering Net: a lightweight network for EEG-based motor imagery recognition , volume =
Barmpas, Konstantinos and Panagakis, Yannis and Adamos, Dimitrios A and Laskaris, Nikolaos and Zafeiriou, Stefanos , year =. BrainWave-Scattering Net: a lightweight network for EEG-based motor imagery recognition , volume =. Journal of Neural Engineering , publisher =
-
[18]
EEG Conformer: Convolutional Transformer for EEG Decoding and Visualization , year=
Song, Yonghao and Zheng, Qingqing and Liu, Bingchuan and Gao, Xiaorong , journal=. EEG Conformer: Convolutional Transformer for EEG Decoding and Visualization , year=
-
[19]
Lawhern, V. J. and Solon, A. J. and Waytowich, N. R. and Gordon, S. M. and Hung, C. P. and Lance, B. J. , journal =. 2018 , volume =
work page 2018
-
[20]
Širca, Urban and Brulec, Lovro and Alimardani, Maryam , booktitle=. Parameter-Efficient Fine-Tuning of EEG Foundation Models for Plug-and-Play Motor Imagery BCIs , year=
-
[21]
Journal of Neural Engineering , abstract =
Kuruppu, Gayal and Wagh, Neeraj and Kremen, Vaclav and Varatharajah, Yogatheesan , title =. Journal of Neural Engineering , abstract =. doi:10.1088/1741-2552/ae4455 , year =
-
[22]
Forty-second International Conference on Machine Learning , year=
Are Large Brainwave Foundation Models Capable Yet ? Insights from Fine-Tuning , author=. Forty-second International Conference on Machine Learning , year=
-
[23]
Assessing the Capabilities of Large Brainwave Foundation Models , year=
Lee, Na and Bakas, Stylianos and Barmpas, Konstantinos and Panagakis, Yannis and Adamos, Dimitrios and Laskaris, Nikolaos and Zafeiriou, Stefanos , booktitle=. Assessing the Capabilities of Large Brainwave Foundation Models , year=
-
[24]
A comprehensive review of biosignal foundation models , author =. 2025 , doi =
work page 2025
-
[25]
Journal of Neural Engineering , year =
A causal perspective on brainwave modeling for brain--computer interfaces , author =. Journal of Neural Engineering , year =
-
[26]
EEG-FM-Bench: A Comprehensive Benchmark for the Systematic Evaluation of EEG Foundation Models , author=. 2026 , eprint=
work page 2026
-
[27]
EEG Foundation Models: Progresses, Benchmarking, and Open Problems , author=. 2026 , eprint=
work page 2026
-
[28]
and Hinterberger, Thilo and Birbaumer, Niels and Wolpaw, Jonathan R
Schalk, Gerwin and McFarland, Dennis J. and Hinterberger, Thilo and Birbaumer, Niels and Wolpaw, Jonathan R. , journal =. 2004 , volume =
work page 2004
-
[29]
Communications of the ACM , year =
Brain--computer interfaces for communication and control , author =. Communications of the ACM , year =
-
[30]
A review of classification algorithms for
Lotte, Fabien and Bougrain, Laurent and Cichocki, Andrzej and Clerc, Maureen and Congedo, Marco and Rakotomamonjy, Alain and Yger, Fabrice , journal =. A review of classification algorithms for. 2018 , volume =
work page 2018
- [31]
-
[32]
Saha, S. and Baumert, M. , journal =. Intra- and inter-subject variability in. 2020 , volume =
work page 2020
-
[33]
Sujatha and Contreras-Vidal, Jose , journal =
Ravindran, A. Sujatha and Contreras-Vidal, Jose , journal =. An empirical comparison of deep learning explainability approaches for. 2023 , volume =
work page 2023
-
[34]
Xinliang Zhou and Chenyu Liu and Liming Zhai and Ziyu Jia and Cuntai Guan and Yang Liu , title=. CoRR , volume=. 2023 , cdate=
work page 2023
-
[35]
Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra
Ramprasaath R. Selvaraju and Michael Cogswell and Abhishek Das and Ramakrishna Vedantam and Devi Parikh and Dhruv Batra , title=. 2017 , cdate=. doi:10.1109/ICCV.2017.74 , booktitle=
-
[36]
Avanti Shrikumar and Peyton Greenside and Anshul Kundaje , title=. ICML , doi =. 2017 , cdate=
work page 2017
-
[37]
SmoothGrad: removing noise by adding noise , doi =
Smilkov, Daniel and Thorat, Nikhil and Kim, Been and Viégas, Fernanda and Wattenberg, Martin , year =. SmoothGrad: removing noise by adding noise , doi =
-
[38]
International Conference on Learning Representations , year=
Towards better understanding of gradient-based attribution methods for Deep Neural Networks , author=. International Conference on Learning Representations , year=
-
[39]
On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation , year =. PLOS ONE , publisher =. doi:10.1371/journal.pone.0130140 , author =
-
[40]
Achtibat, Reduan and Hatefi, Sayed Mohammad Vakilzadeh and Dreyer, Maximilian and Jain, Aakriti and Wiegand, Thomas and Lapuschkin, Sebastian and Samek, Wojciech , booktitle =. 2024 , editor =
work page 2024
-
[41]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , year =
Quantifying Attention Flow in Transformers , author =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , year =
-
[42]
2021 IEEE/CVF International Conference on Computer Vision (ICCV) , year =
Generic attention-model explainability for interpreting bi-modal and encoder-decoder transformers , author =. 2021 IEEE/CVF International Conference on Computer Vision (ICCV) , year =
work page 2021
-
[43]
Proceedings of the 2019 Conference of the North
Linguistic Knowledge and Transferability of Contextual Representations , author =. Proceedings of the 2019 Conference of the North. 2019 , month = jun, address =
work page 2019
-
[44]
The Bottom-up Evolution of Representations in the Transformer: A Study with Machine Translation and Language Modeling Objectives , author =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , year =
work page 2019
-
[45]
Advances in Neural Information Processing Systems 31 (NeurIPS) , year =
Sanity Checks for Saliency Maps , author =. Advances in Neural Information Processing Systems 31 (NeurIPS) , year =
-
[46]
Alon Jacovi and Yoav Goldberg , title=. 2020 , cdate=. doi:10.48550/arXiv.2004.03685 , booktitle=
-
[47]
What Happens To BERT Embeddings During Fine-tuning?
Merchant, Amil and Rahimtoroghi, Elahe and Pavlick, Ellie and Tenney, Ian. What Happens To BERT Embeddings During Fine-tuning?. Proceedings of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP. 2020. doi:10.18653/v1/2020.blackboxnlp-1.4
-
[48]
doi:10.1088/1741-2560/4/2/r03 , url =
Ali Bashashati and Mehrdad Fatourechi and Rabab K Ward and Gary E Birch , title =. doi:10.1088/1741-2560/4/2/r03 , url =
-
[49]
Brain signal analysis advances in neuroelectric and neuromagnetic methods. Cambridge, Mass, MIT Press. , author=
-
[50]
Brain-computer interfacing: an introduction , author=
-
[51]
Brain–Computer Interfaces Handbook: Technological and Theoretical Advances, CRC Press , author=
-
[52]
McFarland, D.J. and Anderson, C.W. and Muller, K.-R. and Schlogl, A. and Krusienski, D.J. , journal=. BCI meeting 2005-workshop on BCI signal processing: feature extraction and translation , year=. doi:10.1109/TNSRE.2006.875637 , url=
-
[53]
Language Models are Few-Shot Learners , doi =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
- [54]
-
[55]
LLaMA: Open and Efficient Foundation Language Models , author=. 2023 , eprint=
work page 2023
-
[56]
Proceedings of the European Conference on Computer Vision (ECCV) , year=
Arc2Face: A Foundation Model for ID-Consistent Human Faces , author=. Proceedings of the European Conference on Computer Vision (ECCV) , year=
-
[57]
and Laskaris, Nikolaos and Zafeiriou, Stefanos , journal=
Barmpas, Konstantinos and Panagakis, Yannis and Bakas, Stylianos and Adamos, Dimitrios A. and Laskaris, Nikolaos and Zafeiriou, Stefanos , journal=. Improving Generalization of CNN-Based Motor-Imagery EEG Decoders via Dynamic Convolutions , year=
-
[58]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[59]
International Conference on Learning Representations (ICLR) , year =
Adam: A Method for Stochastic Optimization , author =. International Conference on Learning Representations (ICLR) , year =
- [60]
-
[61]
Khan, W. and Khan, M. S. and Qasem, S. N. and Ghaban, W. and Saeed, F. and Hanif, M. and Ahmad, J. , journal =. An explainable and efficient deep learning framework for. 2025 , volume =
work page 2025
-
[62]
Almadhor, A. and Ojo, S. and Nathaniel, T. I. and Alsubai, S. and Alharthi, A. and Hejaili, A. A. and Sampedro, G. A. , journal =. An interpretable. 2025 , volume =
work page 2025
-
[63]
ERD/ERS patterns reflecting sensorimotor activation and deactivation , editor =. 2006 , booktitle =. doi:10.1016/S0079-6123(06)59014-4 , author =
-
[64]
EEG differences between eyes-closed and eyes-open resting conditions , journal =. 2007 , issn =. doi:10.1016/j.clinph.2007.07.028 , author =
-
[65]
Brain topography of the human sleep
Werth, Esther and Achermann, Peter and Borb. Brain topography of the human sleep. NeuroReport , volume =. 1996 , doi =
work page 1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.