Same Signal, Different Semantics: A Cross-Framework Behavioral Analysis of Software Engineering Agents
Pith reviewed 2026-05-20 09:05 UTC · model grok-4.3
The pith
Swapping the framework while holding the LLM fixed reverses the direction of most behavioral signals tied to task success in software engineering agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
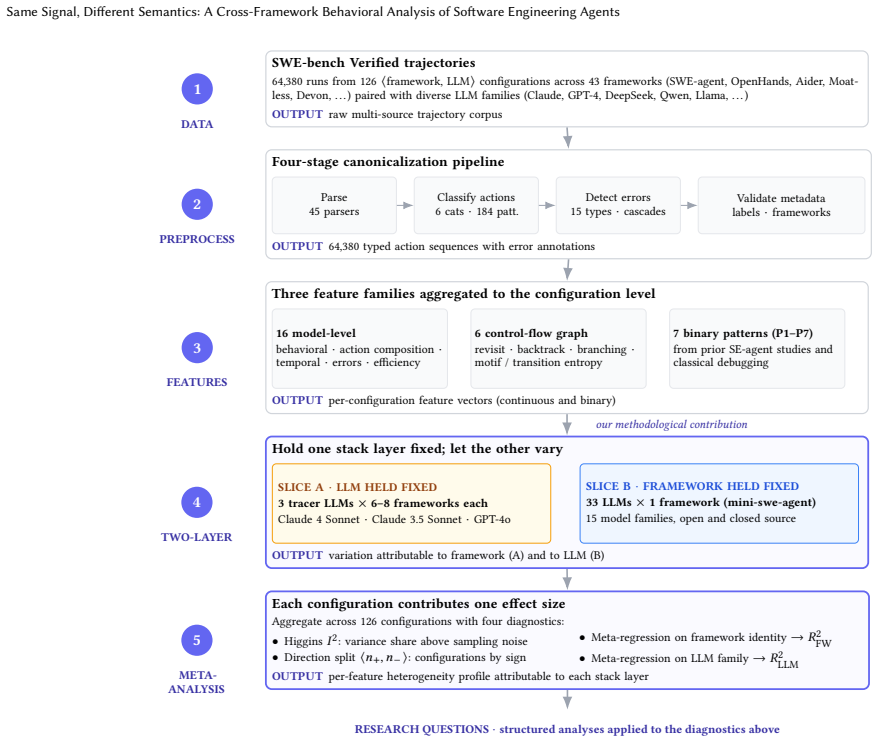
The paper establishes that framework identity accounts for more variation in behavior-outcome effects than LLM family, with 47 configurations resolving more issues at lower error rates and 48 resolving more at higher error rates, plus similar directional disagreements on five other continuous features and three binary patterns from prior work.
What carries the argument
The per-configuration measurement of behavior-outcome effects with framework or LLM held fixed in turn, applied to action features such as error rate, mean turns, and trajectory patterns.
If this is right
- Error rate shows positive correlation with success in roughly half of configurations and negative correlation in the other half.
- Framework explains 64 percent of between-configuration variance in mean turns while LLM family explains only 10 percent.
- Five additional continuous behavioral features exhibit similar magnitude and directional disagreements across frameworks.
- Three of seven binary patterns from earlier single-framework studies reverse direction when tested in other frameworks.
- Any behavioral rule derived from one framework requires explicit cross-configuration checks before being treated as general.
Where Pith is reading between the lines
- Designers of new agents may need to validate assumed behavioral heuristics inside the specific framework they intend to deploy.
- Standardization of tool interfaces and prompt templates could reduce but not eliminate the observed framework-specific semantics.
- Benchmarks that report only aggregate performance may mask these configuration-dependent signal meanings.
Load-bearing premise
That holding the LLM fixed while swapping only the framework isolates framework effects without confounding from differing prompts, tool definitions, or implementation details.
What would settle it
Re-running the analysis after standardizing prompts, tool sets, and workflows across frameworks to check whether directional disagreements on signals such as error rate disappear.
Figures



read the original abstract
Behavioral studies of LLM-based software engineering agents extract operational rules about which trajectory shapes correlate with higher resolution rates: that a test step follows a code modification, that error cascades are short, or that trajectories are compact. Each rule is typically derived from a single framework, and whether it transfers, in sign as well as magnitude, to structurally different agent designs has not been directly tested. We address this at ecosystem scale: 64,380 SWE-bench runs from 126 agent configurations spanning 43 frameworks, where each configuration pairs an LLM with a framework (e.g., SWE-Agent, OpenHands) that supplies its tools and workflow. We separate framework effects from LLM effects by holding each layer fixed in turn, then measure one behavior-outcome effect per configuration and examine how those effects agree or disagree. Swapping the framework while the LLM is held fixed produces large behavioral differences in every action feature. On most signals, configurations disagree not merely in magnitude but in direction. Error rate is the cleanest case: 47 configurations resolve more issues when their error rate is lower, while 48 resolve more when it is higher. Five other continuous features and three of seven binary patterns from prior SE literature show similar directional disagreement. Framework identity accounts for more of this variation than LLM family: for mean turns, framework explains 64% of the between-configuration variance against the LLM's 10%. The implication is that the same observable behavioral signal can carry opposite meaning for different agent configurations. Behavioral findings from any single framework therefore warrant cross-configuration validation before being claimed as general.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a large-scale empirical study of 64,380 SWE-bench runs across 126 configurations spanning 43 frameworks. By holding the LLM fixed while varying the framework (and vice versa), it measures per-configuration behavioral effects on resolution rates and finds that swapping frameworks produces large differences in every action feature, with directional disagreements on most signals (e.g., 47 configurations resolve more issues at lower error rates while 48 resolve more at higher error rates). Framework identity is reported to explain substantially more between-configuration variance than LLM family (64% vs. 10% for mean turns). The central claim is that the same observable behavioral signal can carry opposite semantic meaning across frameworks, so single-framework findings require cross-configuration validation.
Significance. If the results are robust to the noted design issues, the work is significant because it supplies quantitative evidence at ecosystem scale that behavioral rules extracted from one agent framework often fail to transfer in sign or magnitude to others. The scale of the experiment (64k runs, 43 frameworks) and the variance-partitioning analysis are strengths that directly address the generalizability problem in LLM-based SE agent research.
major comments (2)
- [Abstract / experimental design] Abstract, experimental design paragraph: the claim that 'holding each layer fixed in turn' isolates framework effects from LLM effects is load-bearing for the variance-partitioning result and the directional-disagreement counts. However, frameworks differ by construction in tool definitions, default system prompts, error-recovery loops, and message formatting; these are not controlled and directly shape the next-token distribution, so the 64% vs. 10% attribution may reflect prompt-engineering and schema differences rather than the workflow abstraction itself.
- [Results on directional disagreement] Results on error-rate and binary patterns: the split of 47 vs. 48 configurations for error rate (and similar counts for five continuous features and three binary patterns) is presented as evidence of directional disagreement, but the manuscript does not report whether these counts reflect all configurations or result from post-hoc selection or filtering; this directly affects the strength of the 'opposite meaning' claim.
minor comments (2)
- Clarify the exact statistical procedure used to compute the 64% / 10% variance percentages and whether any normalization or random-effect modeling was applied.
- Add a table or appendix listing the 43 frameworks and the precise tool schemas / prompt templates used for each to allow readers to assess the degree of standardization.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and indicate planned revisions. The responses focus on clarifying scope and reporting details while preserving the empirical results.
read point-by-point responses
-
Referee: [Abstract / experimental design] Abstract, experimental design paragraph: the claim that 'holding each layer fixed in turn' isolates framework effects from LLM effects is load-bearing for the variance-partitioning result and the directional-disagreement counts. However, frameworks differ by construction in tool definitions, default system prompts, error-recovery loops, and message formatting; these are not controlled and directly shape the next-token distribution, so the 64% vs. 10% attribution may reflect prompt-engineering and schema differences rather than the workflow abstraction itself.
Authors: We agree that the observed framework effects encompass differences in tool definitions, system prompts, error-recovery loops, and message formatting, as these are intrinsic to each framework's implementation. Our design compares complete, production-style agent configurations rather than abstract workflow layers stripped of implementation details. The variance attribution therefore reflects the framework layer as deployed in practice. We will revise the abstract and experimental-design paragraph to state explicitly that framework effects include prompt-engineering and schema differences and that the study does not isolate a pure workflow abstraction independent of these elements. This clarification does not change the central finding that the same behavioral signal can carry opposite outcome associations across frameworks. revision: partial
-
Referee: [Results on directional disagreement] Results on error-rate and binary patterns: the split of 47 vs. 48 configurations for error rate (and similar counts for five continuous features and three binary patterns) is presented as evidence of directional disagreement, but the manuscript does not report whether these counts reflect all configurations or result from post-hoc selection or filtering; this directly affects the strength of the 'opposite meaning' claim.
Authors: The 47-versus-48 split for error rate, and the corresponding counts for the other features, are computed over all configurations that supplied sufficient variation in the given behavioral feature to permit a correlation with resolution rate. Inclusion was determined solely by data-availability and variance thresholds; no post-hoc filtering on sign or magnitude was performed. We will add a methods/results paragraph that reports the exact number of configurations retained for each feature and states that selection criteria were independent of the direction of the observed associations. revision: yes
Circularity Check
No circularity: empirical variance partitioning from controlled runs
full rationale
The manuscript reports an observational study of 64,380 SWE-bench runs across 126 configurations. Framework and LLM effects are isolated by the experimental protocol of holding one factor fixed while varying the other, then computing per-configuration behavior-outcome correlations and variance components. No equations, fitted parameters, or self-referential definitions appear; the reported directional disagreements and 64 % vs. 10 % variance split are direct empirical aggregates, not reductions of the input data by construction. The analysis therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SWE-bench task outcomes are a valid and comparable measure of agent success across different frameworks.
Reference graph
Works this paper leans on
-
[1]
2021.Introduction to meta-analysis
Michael Borenstein, Larry V Hedges, Julian PT Higgins, and Hannah R Roth- stein. 2021.Introduction to meta-analysis. John wiley & sons
work page 2021
-
[2]
Islem Bouzenia and Michael Pradel. 2025. Understanding Software Engineering Agents: A Study of Thought-Action-Result Trajectories. In2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2846– 2857. Wei Ma, Zhi Chen, Jingxu Gu, Tianling Li, Shangqing Liu, and Lingxiao Jiang
work page 2025
-
[3]
Zhi Chen, Wei Ma, and Lingxiao Jiang. 2026. Beyond Final Code: A Process- Oriented Error Analysis of Software Development Agents in Real-World GitHub Scenarios. InProceedings of the 48th IEEE/ACM International Conference on Soft- ware Engineering (ICSE)
work page 2026
-
[4]
William G Cochran. 1954. The combination of estimates from different experi- ments.Biometrics10, 1 (1954), 101–129
work page 1954
-
[5]
2013.Statistical power analysis for the behavioral sciences
Jacob Cohen. 2013.Statistical power analysis for the behavioral sciences. rout- ledge
work page 2013
-
[6]
Peter Craig, Srinivasa Vittal Katikireddi, Alastair Leyland, and Frank Popham
-
[7]
Natural experiments: an overview of methods, approaches, and contribu- tions to public health intervention research.Annual review of public health38 (2017), 39–56
work page 2017
-
[8]
1999.Mathematical methods of statistics
Harald Cramér. 1999.Mathematical methods of statistics. Vol. 9. Princeton uni- versity press
work page 1999
-
[9]
Alejandro Cuadron, Aditya Desai, Luis Gaspar Schroeder, Xingyao Wang, Wen- jie Ma, Dacheng Li, Yichuan Wang, Ion Stoica, Graham Neubig, and Joseph E. Gonzalez. 2026. Shepherd: Pattern-Guided Trajectory Selection for Coding Agents on SWE-Bench. https://openreview.net/forum?id=ZBOFr4ryBk
work page 2026
-
[10]
Xiang Deng, Jeff Da, Edwin Pan, Yannis Y. He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Chetan Rane, Karmini Sampath, Maya Krishnan, Sri- vatsa R Kundurthy, Sean M. Hendryx, Zifan Wang, Chen Bo Calvin Zhang, Noah Jacobson, Bing Liu, and Brad Kenstler. 2026. SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks? https://ope...
work page 2026
-
[11]
Rebecca DerSimonian and Nan Laird. 1986. Meta-analysis in clinical trials.Con- trolled clinical trials7, 3 (1986), 177–188
work page 1986
-
[12]
Julian PT Higgins, Simon G Thompson, Jonathan J Deeks, and Douglas G Alt- man. 2003. Measuring inconsistency in meta-analyses.bmj327, 7414 (2003), 557–560
work page 2003
-
[13]
Julian P. T. Higgins and Simon G. Thompson. 2002. Quantifying Heterogeneity in a Meta-Analysis.Statistics in Medicine21, 11 (2002), 1539–1558
work page 2002
-
[14]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-world Github Issues?. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=VTF8yNQM66
work page 2024
-
[15]
Dave S Kerby. 2014. The simple difference formula: An approach to teaching nonparametric correlation.Comprehensive Psychology3 (2014), 11–IT
work page 2014
-
[16]
William H Kruskal and W Allen Wallis. 1952. Use of ranks in one-criterion variance analysis.Journal of the American statistical Association47, 260 (1952), 583–621
work page 1952
- [17]
-
[18]
Henry B Mann and Donald R Whitney. 1947. On a test of whether one of two random variables is stochastically larger than the other.The annals of mathe- matical statistics(1947), 50–60
work page 1947
-
[19]
Stephen W Raudenbush. 2009. Analyzing effect sizes: Random-effects models. The handbook of research synthesis and meta-analysis2 (2009), 295–316
work page 2009
-
[20]
Gail M. Sullivan and Richard Feinn. 2012. Using Effect Size—or Why the P Value Is Not Enough.Journal of Graduate Medical Education4, 3 (2012), 279–282
work page 2012
-
[21]
SWE-agent Team. 2024. mini-SWE-agent: The 100 Line AI Agent That Solves GitHub Issues. https://github.com/SWE-agent/mini-swe-agent. Software avail- able at https://mini-swe-agent.com
work page 2024
-
[22]
Nalin Wadhwa, Atharv Sonwane, Daman Arora, Abhav Mehrotra, Saiteja Ut- pala, Ramakrishna B Bairi, Aditya Kanade, and Nagarajan Natarajan. 2024. MA- SAI: Modular Architecture for Software-engineering AI Agents. InNeurIPS 2024 Workshop on Open-World Agents. https://openreview.net/forum?id= NSINt8lLYB
work page 2024
-
[23]
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. 2025. Openhands: An open platform for ai software developers as generalist agents. InInterna- tional Conference on Learning Representations, Vol. 2025. 65882–65919
work page 2025
-
[24]
Ronald L. Wasserstein and Nicole A. Lazar. 2016. The ASA Statement on p- Values: Context, Process, and Purpose.The American Statistician70, 2 (2016), 129–133
work page 2016
-
[25]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2025. De- mystifying LLM-Based Software Engineering Agents.Proc. ACM Softw. Eng.2, FSE, Article FSE037 (June 2025), 24 pages. doi:10.1145/3715754
-
[26]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R Narasimhan, and Ofir Press. 2024. SWE-agent: Agent-Computer In- terfaces Enable Automated Software Engineering. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems. https://openreview.net/ forum?id=mXpq6ut8J3
work page 2024
-
[27]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InInternational Conference on Learning Representations (ICLR)
work page 2023
- [28]
-
[29]
2009.Why programs fail: a guide to systematic debugging
Andreas Zeller. 2009.Why programs fail: a guide to systematic debugging. Mor- gan Kaufmann
work page 2009
-
[30]
Guibin Zhang, Junhao Wang, Junjie Chen, Wangchunshu Zhou, Kun Wang, and Shuicheng YAN. 2026. AgenTracer: Who Is Inducing Failure in the LLM Agentic Systems?. InThe Fourteenth International Conference on Learning Representations. https://openreview.net/forum?id=l05DseqvuD
work page 2026
-
[31]
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. 2024. Au- toCodeRover: Autonomous Program Improvement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis(Vi- enna, Austria)(ISSTA 2024). Association for Computing Machinery, New York, NY, USA, 1592–1604. doi:10.1145/3650212.3680384
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.