EVA-0: Test-Time Model Evolution with Only Two Forward Passes per Sample
Pith reviewed 2026-05-20 21:17 UTC · model grok-4.3
The pith
EVA-0 adapts models at test time using only two forward passes and no backpropagation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
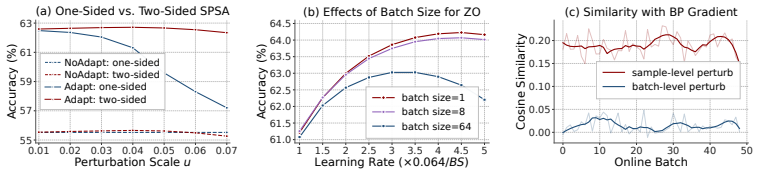
EVA-0 is a minimal zeroth-order adaptation framework that requires no backpropagation and performs both inference and adaptation within only two forward passes per sample. It overcomes shortcut solutions with a scale-invariant loss, controls weight drift through anchor-guided optimization, and estimates reliable update directions via sample-wise symmetric two-sided perturbation. On ImageNet-C with ViT-Base it outperforms both the backpropagation-based DeYO and the forward-only FOA while delivering a 14x speed-up over FOA.
What carries the argument
The EVA-0 framework built from a scale-invariant loss, anchor-guided optimization, and sample-wise symmetric two-sided perturbation that together enable two-forward-pass test-time evolution.
If this is right
- Deployed models can update themselves from unlabeled test data on hardware that supplies only forward passes.
- Adaptation becomes possible for quantized, accelerator-specific, and black-box models that cannot expose gradients.
- Test-time updates run at speeds that make continual improvement practical rather than a research-only step.
- Accuracy on corrupted-image benchmarks improves relative to both gradient-based and prior forward-only baselines.
Where Pith is reading between the lines
- The same two-pass structure could be tested on tasks outside image classification such as object detection or language-model fine-tuning.
- Pairing the method with existing quantization or pruning pipelines might allow on-device adaptation with even lower memory.
- One natural next measurement is whether the same three components remain effective if the budget is tightened to a single forward pass.
Load-bearing premise
The three components together are sufficient to remove shortcut solutions, uncontrolled weight drift, and ineffective update directions when adaptation is forced to exactly two forward passes.
What would settle it
A run on ImageNet-C with ViT-Base in which EVA-0 either fails to beat DeYO and FOA or requires more than two forward passes per sample would show the central claim is not correct.
Figures


read the original abstract
Test-time model evolution offers a promising way for deployed models to improve from unlabeled test-time experience, yet most existing methods depend on backpropagation (BP), which incurs substantial memory overhead and makes them difficult to deploy on edge devices, quantized models, specialized accelerators, or black-box models. In this work, we study test-time model evolution under a strict two-forward budget, a setting that pushes adaptation toward highly efficient real-world deployment. We reveal three key obstacles in zeroth-order test-time optimization: susceptibility to shortcut solutions, uncontrolled weight drift, and ineffective update direction estimation. To overcome them, we propose EVA-0, a minimal zeroth-order adaptation framework that: 1) keeps the loss scale-invariant to prevent shortcut solutions; 2) devises an anchor-guided optimization strategy to alleviate weight drift; 3) uses sample-wise symmetric two-sided perturbation for update direction estimation and inference. EVA-0 requires no BP and performs both inference and adaptation within only two forward passes per sample. Results on ImageNet-C & ViT-Base show that EVA-0 outperforms both BP-based DeYO and BP-free FOA, while achieving a 14x speed-up over FOA. Code will be released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EVA-0, a zeroth-order test-time adaptation framework for model evolution that requires no backpropagation and completes both inference and adaptation in only two forward passes per sample. It identifies three obstacles in this constrained setting (shortcut solutions, uncontrolled weight drift, and ineffective update direction estimation) and maps them to three proposed components: a scale-invariant loss, anchor-guided optimization, and sample-wise symmetric two-sided perturbation. Empirical results on ImageNet-C with ViT-Base are reported to show outperformance over BP-based DeYO and BP-free FOA, together with a 14x speedup relative to FOA.
Significance. If the central claims hold, the work offers a practical advance for test-time adaptation on edge devices, quantized models, specialized accelerators, and black-box APIs where backpropagation is unavailable or prohibitively expensive. The strict two-forward-pass budget and explicit component-to-obstacle mapping constitute a clear contribution; the planned code release supports reproducibility.
major comments (1)
- [§4] §4 (Experiments): the reported outperformance on ImageNet-C lacks error bars, statistical significance tests, or ablation studies isolating the contribution of each of the three components; without these, the claim that the proposed components are jointly sufficient to overcome the three obstacles remains under-supported.
minor comments (1)
- [§3] Notation for the symmetric two-sided perturbation (e.g., the exact definition of the two forward passes and how the update direction is extracted) should be made fully explicit with a small algorithmic box or pseudocode for clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback on our manuscript. We address the single major comment below.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): the reported outperformance on ImageNet-C lacks error bars, statistical significance tests, or ablation studies isolating the contribution of each of the three components; without these, the claim that the proposed components are jointly sufficient to overcome the three obstacles remains under-supported.
Authors: We agree that the current experimental presentation would benefit from additional statistical rigor and component-wise analysis. In the revised manuscript we will report mean and standard deviation over at least three independent runs with different random seeds, include paired statistical significance tests (e.g., Wilcoxon signed-rank or t-tests) against the strongest baselines, and add a dedicated ablation table that isolates the contribution of the scale-invariant loss, the anchor-guided optimization, and the symmetric two-sided perturbation. These additions will directly substantiate that the three components together overcome the identified obstacles. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper constructs EVA-0 as a new zeroth-order framework whose three components are explicitly mapped to three independently stated obstacles (shortcut solutions, weight drift, ineffective direction estimation). No equations or claims reduce by construction to fitted parameters, prior self-citations, or renamed known results; the two-forward-pass budget is a design constraint, not a derived prediction. Empirical results on ImageNet-C are presented as external validation rather than tautological confirmation. The argument remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
keeps the loss scale-invariant to prevent shortcut solutions... scale normalization and output decentering... s(o) = r̄t,i / ||o||₂ + ϵ o − ct
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection refines?
refinesRelation between the paper passage and the cited Recognition theorem.
anchor-guided optimization strategy to alleviate weight drift... θt+1 = (1−γ)θ′t+1 + γθanc
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A. Bartler, A. Bühler, F. Wiewel, M. Döbler, and B. Yang. Mt3: Meta test-time training for self-supervised test-time adaption. InInternational Conference on Artificial Intelligence and Statistics, pages 3080–3090. PMLR, 2022
work page 2022
-
[2]
M. Boudiaf, R. Mueller, I. Ben Ayed, and L. Bertinetto. Parameter-free online test-time adaptation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8344–8353, 2022
work page 2022
-
[3]
H. Cai, D. McKenzie, W. Yin, and Z. Zhang. Zeroth-order regularized optimization (zoro): Ap- proximately sparse gradients and adaptive sampling.SIAM Journal on Optimization, 32(2):687– 714, 2022
work page 2022
- [4]
-
[5]
A. Chen, Y . Zhang, J. Jia, J. Diffenderfer, K. Parasyris, J. Liu, Y . Zhang, Z. Zhang, B. Kailkhura, and S. Liu. Deepzero: Scaling up zeroth-order optimization for deep model training. In International Conference on Learning Representations, 2024
work page 2024
- [6]
-
[7]
W. Choi, D.-Y . Kim, J. Park, J. Lee, Y . Park, D.-J. Han, and J. Moon. Adaptive energy alignment for accelerating test-time adaptation. InThe Thirteenth International Conference on Learning Representations, 2024
work page 2024
-
[8]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. InIEEE Conference on Computer Vision and Pattern Recognition, pages 248– 255, 2009
work page 2009
- [9]
-
[10]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021
work page 2021
-
[11]
J. C. Duchi, M. I. Jordan, M. J. Wainwright, and A. Wibisono. Optimal rates for zero-order convex optimization: The power of two function evaluations.IEEE Transactions on Information Theory, 61(5):2788–2806, 2015
work page 2015
- [12]
-
[13]
C. Finn, P. Abbeel, and S. Levine. Model-agnostic meta-learning for fast adaptation of deep networks. InInternational conference on machine learning, pages 1126–1135. PMLR, 2017
work page 2017
-
[14]
A. Flaxman, A. Kalai, and H. McMahan. Online convex optimization in the bandit setting: Gradient descent without a gradient. InProceedings of the Annual ACM-SIAM Symposium on Discrete Algorithms, pages 385–394, 2005
work page 2005
-
[15]
Y . Gandelsman, Y . Sun, X. Chen, and A. Efros. Test-time training with masked autoencoders. InAdvances in Neural Information Processing Systems, volume 35, pages 29374–29385, 2022
work page 2022
-
[16]
J. Gao, J. Zhang, X. Liu, T. Darrell, E. Shelhamer, and D. Wang. Back to the source: Diffusion- driven adaptation to test-time corruption. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11786–11796, 2023. 10
work page 2023
- [17]
-
[18]
S. Ghadimi and G. Lan. Stochastic first-and zeroth-order methods for nonconvex stochastic programming.SIAM journal on optimization, 23(4):2341–2368, 2013
work page 2013
-
[19]
S. Gidaris, P. Singh, and N. Komodakis. Unsupervised representation learning by predicting image rotations. InInternational Conference on Learning Representations, pages 1–14, 2018
work page 2018
- [20]
-
[21]
W. Gu, L. Gu, Z. Wang, C. Y . Suen, and Y . Wang. Docttt: Test-time training for handwritten document recognition using meta-auxiliary learning. InProceedings of the Winter Conference on Applications of Computer Vision, pages 1904–1913, 2025
work page 1904
-
[22]
N. Hansen. The cma evolution strategy: A tutorial.arXiv preprint arXiv:1604.00772, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[23]
K. He, X. Chen, S. Xie, Y . Li, P. Dollár, and R. Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
work page 2022
-
[24]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. InIEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016
work page 2016
-
[25]
D. Hendrycks and T. Dietterich. Benchmarking neural network robustness to common corrup- tions and perturbations. InInternational Conference on Learning Representations, pages 1–11, 2019
work page 2019
-
[26]
Y . Iwasawa and Y . Matsuo. Test-time classifier adjustment module for model-agnostic domain generalization. InAdvances in Neural Information Processing Systems, volume 34, pages 2427–2440, 2021
work page 2021
- [27]
-
[28]
P. W. Koh, S. Sagawa, H. Marklund, S. M. Xie, M. Zhang, A. Balsubramani, W. Hu, M. Ya- sunaga, R. L. Phillips, I. Gao, et al. Wilds: A benchmark of in-the-wild distribution shifts. In International Conference on Machine Learning, pages 5637–5664, 2021
work page 2021
-
[29]
J. Lee, D. Jung, S. Lee, J. Park, J. Shin, U. Hwang, and S. Yoon. Entropy is not enough for test-time adaptation: From the perspective of disentangled factors. InInternational Conference on Learning Representations, 2024
work page 2024
- [30]
- [31]
-
[32]
J. Liu, R. Xu, S. Yang, R. Zhang, Q. Zhang, Z. Chen, Y . Guo, and S. Zhang. Continual-mae: Adaptive distribution masked autoencoders for continual test-time adaptation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 28653–28663, 2024
work page 2024
- [33]
-
[34]
S. Malladi, T. Gao, E. Nichani, A. Damian, J. D. Lee, D. Chen, and S. Arora. Fine-tuning language models with just forward passes. InAdvances in Neural Information Processing Systems, pages 53038–53075, 2023. 11
work page 2023
-
[35]
S. Niu, C. Miao, G. Chen, P. Wu, and P. Zhao. Test-time model adaptation with only forward passes. InInternational Conference on Machine Learning, 2024
work page 2024
-
[36]
S. Niu, J. Wu, Y . Zhang, Z. Wen, Y . Chen, P. Zhao, and M. Tan. Towards stable test-time adaptation in dynamic wild world. InInternetional Conference on Learning Representations, pages 1–14, 2023
work page 2023
-
[37]
D. Osowiechi, G. A. V . Hakim, M. Noori, M. Cheraghalikhani, A. Bahri, M. Yazdanpanah, I. Ben Ayed, and C. Desrosiers. Nc-ttt: A noise constrastive approach for test-time training. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6078–6086, 2024
work page 2024
-
[38]
D. Osowiechi, G. A. V . Hakim, M. Noori, M. Cheraghalikhani, I. Ben Ayed, and C. Desrosiers. Tttflow: Unsupervised test-time training with normalizing flow. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2126–2134, 2023
work page 2023
-
[39]
D. Silver and R. S. Sutton. Welcome to the era of experience.Google AI, 1:11, 2025
work page 2025
-
[40]
J. C. Spall. Multivariate stochastic approximation using a simultaneous perturbation gradient approximation.IEEE transactions on automatic control, 37(3):332–341, 2002
work page 2002
-
[41]
Y . Sun, X. Wang, Z. Liu, J. Miller, A. Efros, and M. Hardt. Test-time training with self- supervision for generalization under distribution shifts. InInternational Conference on Machine Learning, pages 9229–9248, 2020
work page 2020
-
[42]
J.-A. Termöhlen, M. Klingner, L. J. Brettin, N. M. Schmidt, and T. Fingscheidt. Continual unsupervised domain adaptation for semantic segmentation by online frequency domain style transfer. In2021 IEEE International Intelligent Transportation Systems Conference (ITSC), pages 2881–2888. IEEE, 2021
work page 2021
-
[43]
D. Wang, E. Shelhamer, S. Liu, B. Olshausen, and T. Darrell. Tent: Fully test-time adaptation by entropy minimization. InInternational Conference on Learning Representations, pages 1–12, 2021
work page 2021
-
[44]
Q. Wang, O. Fink, L. Van Gool, and D. Dai. Continual test-time domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7201–7211, 2022
work page 2022
-
[45]
X. Wang and T. Wang. Fozo: Forward-only zeroth-order prompt optimization for test-time adaptation. InIEEE Conference on Computer Vision and Pattern Recognition, 2026
work page 2026
- [46]
- [47]
-
[48]
Y . Yuan, B. Xu, L. Hou, F. Sun, H. Shen, and X. Cheng. Tea: Test-time energy adaptation. In IEEE Conference on Computer Vision and Pattern Recognition, pages 23901–23911, 2024
work page 2024
-
[49]
Z. Yuan, C. Xue, Y . Chen, Q. Wu, and G. Sun. Ptq4vit: Post-training quantization for vision transformers with twin uniform quantization. InEuropean Conference on Computer Vision, pages 191–207. Springer, 2022
work page 2022
-
[50]
EV A-0: Test-Time Model Evolution with Only Two Forward Passes per Sample
M. M. Zhang, S. Levine, and C. Finn. Memo: Test time robustness via adaptation and augmentation. InAdvances in Neural Information Processing Systems, pages 38629–38642, 2022. 12 Supplementary Materials for “ EV A-0: Test-Time Model Evolution with Only Two Forward Passes per Sample ” Contents A Pseudo-Code of EV A-0 14 B Related Work 15 C More Design Detai...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.