EventPrune: Cascaded Event-Assisted Token Pruning for Efficient First-Person Dynamic Spatial Reasoning
Pith reviewed 2026-05-20 06:51 UTC · model grok-4.3
The pith
Event camera motion signals let video models prune 80 percent of tokens and still beat the full baseline on first-person spatial reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Event Cascade Pruning is a training-free pipeline that treats event-camera data as a motion prior. Event-Triggered Causal Sampling anchors keyframes to event bursts. Event-guided Motion Saliency Filtering removes tokens lacking recent events. Event-Attention Ranking Fusion then fuses those scores into the model's spatial attention. At 80 percent token reduction the method records 37.62 percent accuracy versus 36.31 percent for the dense baseline, together with 1.89 times faster inference and 52 percent fewer GFLOPs. The same pipeline lifts accuracy 2.68 points on the new ESR-Real benchmark.
What carries the argument
Event Cascade Pruning, a three-stage cascade that uses event motion priors to select and re-rank visual tokens in Video-LLMs.
If this is right
- Inference speed rises by a factor of 1.89 at 80 percent token reduction.
- GFLOPs fall by 52 percent while accuracy improves over the dense model.
- Performance gains appear on both existing datasets and the new real-world ESR-Real benchmark.
- The cascade requires no additional training or dataset-specific hyper-parameters.
Where Pith is reading between the lines
- Event-driven pruning could extend to other motion-heavy video tasks such as action recognition or navigation.
- Hybrid RGB-event sensors may become a practical route to efficient on-device video reasoning.
- Sensor priors might replace learned pruning modules in future lightweight video models.
Load-bearing premise
Event camera signals stay reliably aligned with RGB frames and supply sufficient motion information for the target reasoning task without task-specific tuning.
What would settle it
Run the identical pipeline on video where the event stream is deliberately shifted by a few frames relative to RGB and check whether accuracy drops below the full-token baseline.
Figures








read the original abstract
First-person dynamic spatial reasoning requires models to track continuous motion and precise geometric structure, but the quadratic attention cost of Transformer-based Video-LLMs makes dense visual tokens computationally expensive. Existing token pruning paradigms predominantly rely on discrete static snapshots, failing to preserve the motion and geometric cues essential for reasoning. We propose Event Cascade Pruning (ECP), to our knowledge the first training-free framework that leverages the high-frequency motion cues from event cameras as a continuous event-guided motion prior to guide token selection. ECP combines three stages: Event-Triggered Causal Sampling to anchor motion-informative keyframes, Event-guided Motion Saliency Filtering to suppress event-inactive visual tokens, and Event-Attention Ranking Fusion to calibrate spatial attention with motion-salient dynamics. With 80% visual token reduction, ECP outperforms the full-token baseline (37.62% vs. 36.31%) while achieving 1.89x inference speedup and 52% GFLOPs reduction. We further introduce ESR-Real, the first real-world RGB-event benchmark for first-person spatial reasoning, where ECP improves accuracy by 2.68 percentage points over full-token baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Event Cascade Pruning (ECP), a training-free three-stage framework that uses high-frequency motion cues from event cameras to prune visual tokens in Video-LLMs for first-person dynamic spatial reasoning. The stages are Event-Triggered Causal Sampling for keyframe selection, Event-guided Motion Saliency Filtering to suppress inactive tokens, and Event-Attention Ranking Fusion to calibrate attention. The paper introduces the ESR-Real benchmark and reports that 80% token reduction yields 37.62% accuracy (vs. 36.31% full-token baseline), 1.89× speedup, and 52% GFLOPs reduction.
Significance. If the performance claims hold under proper validation, the work provides a practical training-free approach to efficient inference for dynamic video reasoning by exploiting event-based motion priors, which is a strength given the quadratic cost of attention in Video-LLMs. The introduction of the first real-world RGB-event benchmark for this task is a clear contribution. The modest accuracy gain, however, needs statistical backing to be convincing.
major comments (2)
- [Results / ESR-Real experiments] Results section / Table reporting ESR-Real accuracy: the central claim that ECP outperforms the full-token baseline (37.62% vs. 36.31%) at 80% pruning rests on single-point estimates with no error bars, standard deviations, run counts, or significance tests. On a newly introduced benchmark this difference could arise from tokenization order, split variation, or model stochasticity and therefore does not yet substantiate the outperformance assertion.
- [§3] §3 (method description): the three-stage cascade is presented as parameter-free and training-free, yet the Event-Attention Ranking Fusion step implicitly relies on alignment quality between event streams and RGB frames; no ablation or sensitivity analysis quantifies how misalignment affects token selection or final accuracy, which is load-bearing for the claim that event cues reliably improve pruning over static baselines.
minor comments (2)
- [Abstract / §1] Abstract and §1: the phrasing 'to our knowledge the first training-free framework' would be strengthened by a short explicit comparison to the closest prior event-assisted or motion-guided pruning methods.
- [Figure 1/2] Figure 1 or 2 (cascade diagram): add explicit arrows or labels showing the exact input and output tensors at each of the three stages to improve clarity of the data flow.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The recognition of the training-free approach and the ESR-Real benchmark as contributions is appreciated. We address the two major comments below with specific plans for revision to strengthen the statistical rigor and robustness analysis.
read point-by-point responses
-
Referee: [Results / ESR-Real experiments] Results section / Table reporting ESR-Real accuracy: the central claim that ECP outperforms the full-token baseline (37.62% vs. 36.31%) at 80% pruning rests on single-point estimates with no error bars, standard deviations, run counts, or significance tests. On a newly introduced benchmark this difference could arise from tokenization order, split variation, or model stochasticity and therefore does not yet substantiate the outperformance assertion.
Authors: We agree that single-point estimates limit the strength of the outperformance claim, particularly on a newly introduced benchmark where factors such as split variation or stochasticity could influence results. In the revised manuscript, we will rerun the ESR-Real experiments over at least five independent trials using different random seeds for any stochastic elements in tokenization and inference. We will report mean accuracy with standard deviations and include statistical significance testing (e.g., paired t-test p-values) to substantiate the observed improvement. revision: yes
-
Referee: [§3] §3 (method description): the three-stage cascade is presented as parameter-free and training-free, yet the Event-Attention Ranking Fusion step implicitly relies on alignment quality between event streams and RGB frames; no ablation or sensitivity analysis quantifies how misalignment affects token selection or final accuracy, which is load-bearing for the claim that event cues reliably improve pruning over static baselines.
Authors: The method is training-free with no learned parameters, but we acknowledge that the Event-Attention Ranking Fusion stage depends on the temporal alignment between event and RGB streams, which is typically ensured by hardware synchronization. To quantify robustness, the revised manuscript will add a sensitivity analysis that introduces controlled temporal shifts (e.g., ±10 ms to ±50 ms) between the event stream and RGB frames. We will report the resulting impact on token pruning ratios, selected token quality, and final accuracy, thereby demonstrating that the performance gains hold under realistic misalignment conditions. revision: yes
Circularity Check
No circularity: empirical results driven by external event data on new benchmark
full rationale
The paper describes a training-free three-stage cascade (Event-Triggered Causal Sampling, Event-guided Motion Saliency Filtering, Event-Attention Ranking Fusion) that uses independent high-frequency event-camera motion cues to prune visual tokens. Performance numbers such as 37.62% vs. 36.31% accuracy at 80% reduction are reported as direct measurements on the newly introduced ESR-Real benchmark; they are not quantities fitted from the evaluation set, renamed known results, or derived via self-citation chains. The central claim therefore remains self-contained against external benchmarks and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Event cameras supply high-frequency, motion-informative signals that can be directly used to guide visual token selection without task-specific training.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736, 2022
work page 2022
-
[3]
Divprune: Diversity-based visual token pruning for large multimodal models
Saeed Ranjbar Alvar, Gursimran Singh, Mohammad Akbari, and Yong Zhang. Divprune: Diversity-based visual token pruning for large multimodal models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9392–9401, 2025
work page 2025
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, and Jun Tang. Qwen2.5-vl technical report. 2025
work page 2025
-
[6]
Eagle: Egocentric aggregated language-video engine.arXiv preprint arXiv:2409.17523, 2024
Jing Bi, Yunlong Tang, Luchuan Song, Ali V osoughi, Nguyen Nguyen, and Chenliang Xu. Eagle: Egocentric aggregated language-video engine.arXiv preprint arXiv:2409.17523, 2024
-
[7]
Token Merging: Your ViT But Faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your vit but faster.arXiv preprint arXiv:2210.09461, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Recent event camera innovations: A survey
Bharatesh Chakravarthi, Aayush Atul Verma, Kostas Daniilidis, Cornelia Fermuller, and Yezhou Yang. Recent event camera innovations: A survey. InEuropean conference on computer vision, pages 342–376. Springer, 2024
work page 2024
-
[9]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InEuropean Conference on Computer Vision, pages 19–35. Springer, 2024
work page 2024
-
[10]
Sparsevit: Revisiting activation sparsity for efficient high-resolution vision transformer
Xuanyao Chen, Zhijian Liu, Haotian Tang, Li Yi, Hang Zhao, and Song Han. Sparsevit: Revisiting activation sparsity for efficient high-resolution vision transformer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2061–2070, 2023
work page 2061
-
[11]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024
work page 2024
-
[12]
Rynnec: Bringing mllms into embodied world.arXiv preprint arXiv:2508.14160, 2025
Ronghao Dang, Yuqian Yuan, Yunxuan Mao, Kehan Li, Jiangpin Liu, Zhikai Wang, Xin Li, Fan Wang, and Deli Zhao. Rynnec: Bringing mllms into embodied world.arXiv preprint arXiv:2508.14160, 2025
-
[13]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Yue Fan, Xiaojian Ma, Rongpeng Su, Jun Guo, Rujie Wu, Xi Chen, and Qing Li. Embodied videoagent: Persistent memory from egocentric videos and embodied sensors enables dynamic scene understanding. In 2025 IEEE/CVF International Conference on Computer Vision (ICCV), pages 6342–6352. IEEE, 2025
work page 2025
-
[15]
Guillermo Gallego, Tobi Delbrück, Garrick Orchard, Chiara Bartolozzi, Brian Taba, Andrea Censi, Stefan Leutenegger, Andrew J Davison, Jörg Conradt, Kostas Daniilidis, et al. Event-based vision: A survey. IEEE transactions on pattern analysis and machine intelligence, 44(1):154–180, 2020
work page 2020
-
[16]
Video to events: Recycling video datasets for event cameras
Daniel Gehrig, Mathias Gehrig, Javier Hidalgo-Carrió, and Davide Scaramuzza. Video to events: Recycling video datasets for event cameras. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3586–3595, 2020. 10
work page 2020
-
[17]
Prunevid: Visual token pruning for efficient video large language models
Xiaohu Huang, Hao Zhou, and Kai Han. Prunevid: Visual token pruning for efficient video large language models. InFindings of the Association for Computational Linguistics: ACL 2025, pages 19959–19973, 2025
work page 2025
-
[18]
Llmlingua: Compressing prompts for accelerated inference of large language models
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. Llmlingua: Compressing prompts for accelerated inference of large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 13358–13376, 2023
work page 2023
-
[19]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
work page 2023
-
[21]
Kaiyuan Li, Xiaoyue Chen, Chen Gao, Yong Li, and Xinlei Chen. Balanced token pruning: Accelerating vision language models beyond local optimization.arXiv preprint arXiv:2505.22038, 2025
-
[22]
Snapkv: Llm knows what you are looking for before generation
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: Llm knows what you are looking for before generation. Advances in Neural Information Processing Systems, 37:22947–22970, 2024
work page 2024
-
[23]
Boosting multimodal large language models with visual tokens withdrawal for rapid inference
Zhihang Lin, Mingbao Lin, Luxi Lin, and Rongrong Ji. Boosting multimodal large language models with visual tokens withdrawal for rapid inference. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 5334–5342, 2025
work page 2025
-
[24]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
work page 2023
-
[25]
Llavanext: Improved reasoning, ocr, and world knowledge, 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llavanext: Improved reasoning, ocr, and world knowledge, 2024
work page 2024
-
[26]
Eventgpt: Event stream understanding with multimodal large language models
Shaoyu Liu, Jianing Li, Guanghui Zhao, Yunjian Zhang, Xin Meng, Fei Richard Yu, Xiangyang Ji, and Ming Li. Eventgpt: Event stream understanding with multimodal large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29139–29149, 2025
work page 2025
-
[27]
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. Dynamicvit: Efficient vision transformers with dynamic token sparsification.Advances in neural information processing systems, 34:13937–13949, 2021
work page 2021
-
[28]
Henri Rebecq, René Ranftl, Vladlen Koltun, and Davide Scaramuzza. High speed and high dynamic range video with an event camera.IEEE transactions on pattern analysis and machine intelligence, 43(6): 1964–1980, 2019
work page 1964
-
[29]
Events-to-video: Bringing modern computer vision to event cameras
Henri Rebecq, René Ranftl, Vladlen Koltun, and Davide Scaramuzza. Events-to-video: Bringing modern computer vision to event cameras. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3857–3866, 2019
work page 2019
-
[30]
Convoi: Context-aware navigation using vision language models in outdoor and indoor environments
Adarsh Jagan Sathyamoorthy, Kasun Weerakoon, Mohamed Elnoor, Anuj Zore, Brian Ichter, Fei Xia, Jie Tan, Wenhao Yu, and Dinesh Manocha. Convoi: Context-aware navigation using vision language models in outdoor and indoor environments. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 13837–13844. IEEE, 2024
work page 2024
-
[31]
LongVU: Spatiotemporal Adaptive Compression for Long Video-Language Understanding
Xiaoqian Shen, Yunyang Xiong, Changsheng Zhao, Lemeng Wu, Jun Chen, Chenchen Zhu, Zechun Liu, Fanyi Xiao, Balakrishnan Varadarajan, Florian Bordes, et al. Longvu: Spatiotemporal adaptive compression for long video-language understanding.arXiv preprint arXiv:2410.17434, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Alanavlm: A multimodal embodied ai foundation model for egocentric video understanding
Alessandro Suglia, Claudio Greco, Katie Baker, Jose L Part, Ioannis Papaioannou, Arash Eshghi, Ioannis Konstas, and Oliver Lemon. Alanavlm: A multimodal embodied ai foundation model for egocentric video understanding. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 11101–11122, 2024
work page 2024
-
[33]
Jacob Thompson, Emiliano Garcia-Lopez, and Yonatan Bisk. Rem: Evaluating llm embodied spatial reasoning through multi-frame trajectories.arXiv preprint arXiv:2512.00736, 2025
-
[34]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023. 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Antoni Rosinol Vidal, Henri Rebecq, Timo Horstschaefer, and Davide Scaramuzza. Ultimate slam? combining events, images, and imu for robust visual slam in hdr and high-speed scenarios.IEEE Robotics and Automation Letters, 3(2):994–1001, 2018
work page 2018
-
[36]
Haoyang Wang, Ruishan Guo, Pengtao Ma, Ciyu Ruan, Xinyu Luo, Wenhua Ding, Tianyang Zhong, Jingao Xu, Yunhao Liu, and Xinlei Chen. Event camera meets mobile embodied perception: abstraction, algorithm, acceleration, application.ACM Computing Surveys, 58(8):1–41, 2026
work page 2026
-
[37]
Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, et al. Cogvlm: Visual expert for pretrained language models.Advances in Neural Information Processing Systems, 37:121475–121499, 2024
work page 2024
-
[38]
Shiwei Wu, Joya Chen, Kevin Qinghong Lin, Qimeng Wang, Yan Gao, Qianli Xu, Tong Xu, Yao Hu, Enhong Chen, and Mike Zheng Shou. Videollm-mod: Efficient video-language streaming with mixture- of-depths vision computation.Advances in Neural Information Processing Systems, 37:109922–109947, 2024
work page 2024
-
[39]
Eventclip: Adapting clip for event-based object recognition.arXiv preprint arXiv:2306.06354, 2023
Ziyi Wu, Xudong Liu, and Igor Gilitschenski. Eventclip: Adapting clip for event-based object recognition. arXiv preprint arXiv:2306.06354, 2023
-
[40]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
PyramidDrop: Accelerating Your Large Vision-Language Models via Pyramid Visual Redundancy Reduction
Long Xing, Qidong Huang, Xiaoyi Dong, Jiajie Lu, Pan Zhang, Yuhang Zang, Yuhang Cao, Conghui He, Jiaqi Wang, Feng Wu, et al. Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy reduction.arXiv preprint arXiv:2410.17247, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Thinking in space: How multimodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025
work page 2025
-
[43]
Timechat-online: 80% visual tokens are naturally redundant in streaming videos
Linli Yao, Yicheng Li, Yuancheng Wei, Lei Li, Shuhuai Ren, Yuanxin Liu, Kun Ouyang, Lean Wang, Shicheng Li, Sida Li, et al. Timechat-online: 80% visual tokens are naturally redundant in streaming videos. InProceedings of the 33rd ACM International Conference on Multimedia, pages 10807–10816, 2025
work page 2025
-
[44]
Uni-NaVid: A Video-based Vision-Language-Action Model for Unifying Embodied Navigation Tasks
Jiazhao Zhang, Kunyu Wang, Shaoan Wang, Minghan Li, Haoran Liu, Songlin Wei, Zhongyuan Wang, Zhizheng Zhang, and He Wang. Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks.arXiv preprint arXiv:2412.06224, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Zhengyou Zhang. A flexible new technique for camera calibration.IEEE Transactions on pattern analysis and machine intelligence, 22(11):1330–1334, 2000
work page 2000
-
[46]
Baining Zhao, Jianjie Fang, Zichao Dai, Ziyou Wang, Jirong Zha, Weichen Zhang, Chen Gao, Yue Wang, Jinqiang Cui, Xinlei Chen, et al. Urbanvideo-bench: Benchmarking vision-language models on embodied intelligence with video data in urban spaces. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers...
work page 2025
-
[47]
Jiazhou Zhou, Xu Zheng, Yuanhuiyi Lyu, and Lin Wang. Eventbind: Learning a unified representation to bind them all for event-based open-world understanding. InEuropean Conference on Computer Vision, pages 477–494. Springer, 2024
work page 2024
-
[48]
EV-FlowNet: Self-Supervised Optical Flow Estimation for Event-based Cameras
Alex Zihao Zhu, Liangzhe Yuan, Kenneth Chaney, and Kostas Daniilidis. Ev-flownet: Self-supervised optical flow estimation for event-based cameras.arXiv preprint arXiv:1802.06898, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[49]
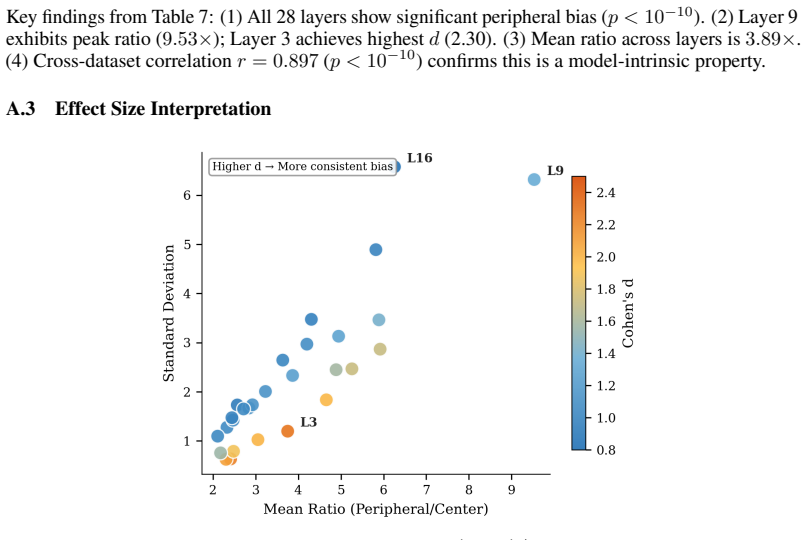
Alex Zihao Zhu, Liangzhe Yuan, Kenneth Chaney, and Kostas Daniilidis. Unsupervised event-based learning of optical flow, depth, and egomotion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 989–997, 2019. 12 A Spatial Attention Bias Analysis This appendix provides statistical analysis of the spatial attention bi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.