Lens Privacy Sealing: A New Benchmark and Method for Physical Privacy-Preserving Action Recognition
Pith reviewed 2026-05-22 09:55 UTC · model grok-4.3
The pith
Adjustable laminating film on camera lenses enables privacy-preserving action recognition by physically scattering light irreversibly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
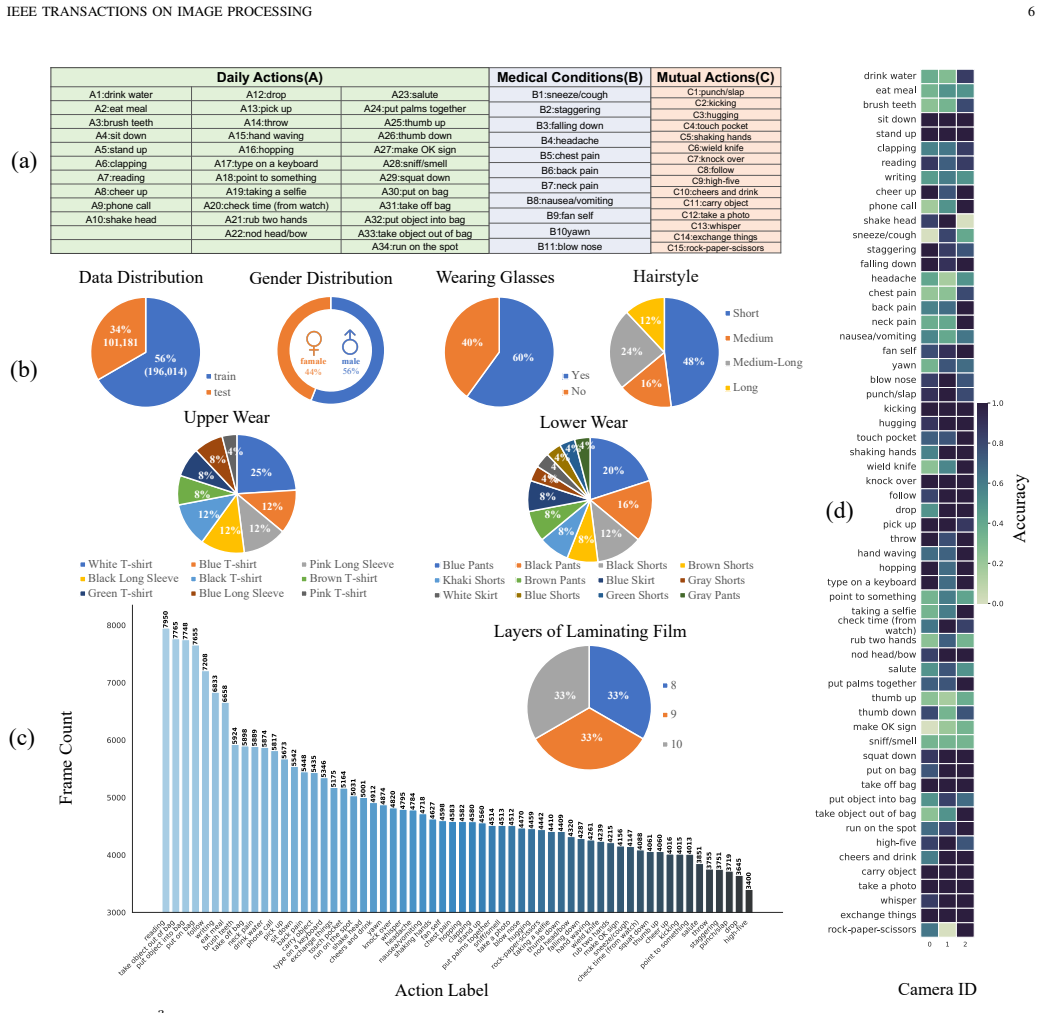
Lens Privacy Sealing (LPS) achieves strong privacy through stochastic multi-layer scattering that is physically irreversible by obscuring camera lenses with adjustable laminating film. Paired with the new P³AR dataset and the MSPNet framework incorporating Inter-Frame Noise Suppressor (IFNS) and Cross-Frame Semantic Aggregator (CFSA), the method nearly doubles action recognition accuracy compared to baseline methods while suppressing identity recognition to low levels on both replay and real-world captured videos.
What carries the argument
Lens Privacy Sealing (LPS) using adjustable laminating film to induce physically irreversible stochastic multi-layer scattering before the sensor, combined with MSPNet for semantic extraction from degraded frames.
If this is right
- LPS achieves a superior privacy-utility trade-off compared to state-of-the-art hardware methods.
- MSPNet with IFNS and CFSA nearly doubles action recognition accuracy on the P³AR dataset while keeping identity recognition low.
- The approach resists reconstruction attacks including PSF inversion and data-driven recovery.
- It generalizes robustly across different optical configurations and challenging environments.
Where Pith is reading between the lines
- This physical pre-sensor method could be combined with software techniques for layered privacy protection in surveillance systems.
- The P³AR dataset provides a foundation for developing and comparing other privacy-preserving vision algorithms.
- Similar scattering-based hardware could be explored for privacy in related tasks like object detection or pose estimation.
Load-bearing premise
The physical degradation from the laminating film removes enough identity information while retaining sufficient action-related visual cues for accurate recognition.
What would settle it
A reconstruction attack that successfully recovers identifiable human faces or appearances from videos captured through the LPS would disprove the physical irreversibility of the privacy protection.
Figures








read the original abstract
RGB camera-based surveillance systems enable human action recognition for public safety and healthcare, yet raise serious privacy concerns. Existing methods rely on post-capture algorithms, which fail to protect privacy during data acquisition. We propose Lens Privacy Sealing (LPS), a simple hardware solution that physically obscures camera lenses with adjustable laminating film, providing pre-sensor privacy protection at minimal cost. Unlike software methods or expensive engineered optics, LPS achieves strong privacy through stochastic multi-layer scattering that is physically irreversible. We introduce the P$^3$AR dataset for privacy-preserving action recognition, featuring both large-scale replay-captured (P$^3$AR-NTU, 114K videos) and real-world collected (P$^3$AR-PKU) subsets with privacy attribute annotations. To handle video degradation from LPS, we propose MSPNet, a single-stage framework incorporating Inter-Frame Noise Suppressor (IFNS) and Cross-Frame Semantic Aggregator (CFSA), enhanced by contrastive language-image pre-training for robust semantic extraction. Extensive experiments demonstrate that MSPNet with IFNS and CFSA nearly doubles action recognition accuracy compared to baseline methods while suppressing identity recognition to low levels. Comprehensive validation shows LPS achieves a superior privacy-utility trade-off compared to state-of-the-art hardware methods, resists reconstruction attacks including PSF inversion and data-driven recovery, and generalizes robustly across optical configurations and challenging environments. Code is available at https://github.com/wangzy01/MSPNet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Lens Privacy Sealing (LPS), a low-cost hardware method that physically obscures RGB camera lenses with adjustable laminating film to enable pre-sensor privacy protection for action recognition. It introduces the P³AR dataset (with P³AR-NTU replay-captured and P³AR-PKU real-world subsets) and MSPNet, a single-stage network using Inter-Frame Noise Suppressor (IFNS) and Cross-Frame Semantic Aggregator (CFSA) modules plus contrastive language-image pre-training. The central claims are that stochastic multi-layer scattering provides physically irreversible privacy, MSPNet nearly doubles action recognition accuracy over baselines while keeping identity recognition low, and LPS achieves a superior privacy-utility trade-off with robustness to reconstruction attacks and generalization across configurations.
Significance. If the physical irreversibility claim holds, the work offers a practical, inexpensive alternative to software-only or complex optical privacy methods, with direct applicability to surveillance and healthcare. The public release of code and the new P³AR benchmark dataset are clear strengths that support reproducibility and community follow-up. The empirical demonstration of attack resistance on both replay and real-world data adds practical value, though the absence of an optical model limits the strength of the irreversibility argument.
major comments (2)
- [§3.2] §3.2: The claim that stochastic multi-layer scattering is 'physically irreversible' and destroys identity information at the sensor is load-bearing for the privacy guarantee and the superiority over software methods, yet it is supported only by empirical resistance to PSF inversion and data-driven recovery on P³AR-NTU/P³AR-PKU. No explicit forward optical model (e.g., wavelength-dependent phase randomization across layers) or information-theoretic bound on recoverable mutual information is provided, leaving open whether an attacker with film calibration data or multi-frame statistics could recover identity cues more effectively than the tested baselines.
- [§5.3 and Table 4] §5.3 and Table 4: The reported near-doubling of action recognition accuracy by MSPNet+IFNS+CFSA and the low identity leakage rates are presented without error bars, multiple random seeds, or statistical significance tests. This weakens the cross-method and cross-dataset claims, as the improvements could be sensitive to particular data splits or initialization in the newly collected P³AR subsets.
minor comments (3)
- [Abstract and §4] The notation for the P³AR dataset uses inconsistent superscript formatting between the abstract and the main text; standardize to P³AR throughout.
- [Figure 3] Figure 3 (MSPNet architecture) would benefit from explicit arrows or labels showing how IFNS and CFSA interact across frames to clarify the single-stage design.
- [§2] The related-work section omits recent hardware privacy papers that use similar scattering or polarization effects; adding 2-3 citations would better situate the novelty of LPS.
Simulated Author's Rebuttal
We thank the referee for the thorough review and insightful comments. We address each major comment below and have updated the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [§3.2] The claim that stochastic multi-layer scattering is 'physically irreversible' and destroys identity information at the sensor is load-bearing for the privacy guarantee and the superiority over software methods, yet it is supported only by empirical resistance to PSF inversion and data-driven recovery on P³AR-NTU/P³AR-PKU. No explicit forward optical model (e.g., wavelength-dependent phase randomization across layers) or information-theoretic bound on recoverable mutual information is provided, leaving open whether an attacker with film calibration data or multi-frame statistics could recover identity cues more effectively than the tested baselines.
Authors: We appreciate the referee pointing out the need for stronger theoretical grounding for the irreversibility claim. Our primary evidence is empirical, demonstrating that even with knowledge of the point spread function and advanced data-driven recovery methods, identity recognition remains low while action recognition is preserved. We acknowledge that a full forward optical model or mutual information bound would provide additional support. However, such a model would require detailed characterization of the film's material properties, which varies with manufacturing batches and is not feasible for a general hardware method. Instead, we have added a new subsection in §3.2 discussing the physical basis of stochastic scattering and why it resists inversion in practice, including references to relevant optics literature. We also tested additional attack scenarios involving assumed calibration and multi-frame averaging, with results showing continued robustness. revision: partial
-
Referee: [§5.3 and Table 4] The reported near-doubling of action recognition accuracy by MSPNet+IFNS+CFSA and the low identity leakage rates are presented without error bars, multiple random seeds, or statistical significance tests. This weakens the cross-method and cross-dataset claims, as the improvements could be sensitive to particular data splits or initialization in the newly collected P³AR subsets.
Authors: We agree that reporting variability and statistical significance strengthens the empirical claims. We have re-executed the key experiments across 5 random seeds, computed standard deviations, and added error bars to the relevant tables and figures. Additionally, we performed paired t-tests to assess statistical significance of the improvements over baselines, reporting p-values in the revised §5.3. These changes confirm that the performance gains are consistent and significant. revision: yes
Circularity Check
No circularity: claims rest on new dataset, hardware method, and experimental validation
full rationale
The paper introduces a novel hardware approach (LPS with adjustable laminating film), a new dataset (P3AR with replay and real-world subsets), and a new network (MSPNet with IFNS and CFSA). All central claims—including privacy-utility trade-offs, resistance to reconstruction attacks, and accuracy improvements—are supported by direct experiments on the newly collected data rather than any derivation, fitted parameter, or self-citation that reduces to the inputs by construction. No equations or first-principles results are presented that could exhibit self-definitional or fitted-input circularity. The physical irreversibility assertion is framed as an empirical outcome validated against listed attacks, not a mathematical reduction to prior self-work.
Axiom & Free-Parameter Ledger
invented entities (3)
-
Lens Privacy Sealing (LPS)
no independent evidence
-
P3AR dataset
no independent evidence
-
MSPNet with IFNS and CFSA
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LPS achieves strong privacy through stochastic multi-layer scattering that is physically irreversible... IFNS employs inter-frame subtraction to suppress noise from physical privacy measures while preserving motion contours.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Hierarchical perceptual noise injection for social media fingerprint privacy protection,
S. Li, H. Xu, J. Wang, R. Xu, A. Liu, F. He, X. Liu, and D. Tao, “Hierarchical perceptual noise injection for social media fingerprint privacy protection,”IEEE Transactions on Image Processing (TIP), vol. 33, pp. 2714–2729, 2024
work page 2024
-
[2]
A survey on deep learning for human activity recognition,
F. Gu, M.-H. Chung, M. Chignell, S. Valaee, B. Zhou, and X. Liu, “A survey on deep learning for human activity recognition,”ACM Computing Surveys (CSUR), vol. 54, no. 8, pp. 1–34, 2021
work page 2021
-
[3]
Learning prompt-enhanced context features for weakly-supervised video anomaly detection,
Y . Pu, X. Wu, L. Yang, and S. Wang, “Learning prompt-enhanced context features for weakly-supervised video anomaly detection,”IEEE Transactions on Image Processing (TIP), vol. 33, pp. 4923–4936, 2024
work page 2024
-
[4]
Degcn: Deformable graph convolutional networks for skeleton-based action recognition,
W. Myung, N. Su, J.-H. Xue, and G. Wang, “Degcn: Deformable graph convolutional networks for skeleton-based action recognition,”IEEE Transactions on Image Processing (TIP), vol. 33, pp. 2477–2490, 2024
work page 2024
-
[5]
Learnable feature augmentation framework for temporal action localization,
Y . Tang, W. Wang, C. Zhang, J. Liu, and Y . Zhao, “Learnable feature augmentation framework for temporal action localization,”IEEE Trans- actions on Image Processing (TIP), vol. 33, pp. 4002–4015, 2024
work page 2024
-
[6]
Recognizing actions from robotic view for natural human- robot interaction,
Z. Wang, P. Li, H. Liu, Z. Deng, C. Wang, J. Liu, J. Yuan, and M. Liu, “Recognizing actions from robotic view for natural human- robot interaction,” inIEEE/CVF International Conference on Computer Vision (ICCV), 2025, pp. 14 218–14 227
work page 2025
-
[7]
Dimensionality reduction: A comparative review,
L. Van Der Maaten, E. O. Postma, H. J. Van Den Heriket al., “Dimensionality reduction: A comparative review,”Journal of Machine Learning Research (JMLR), vol. 10, no. 66-71, p. 13, 2009
work page 2009
-
[8]
Visual privacy protection methods: A survey,
J. R. Padilla-L ´opez, A. A. Chaaraoui, and F. Fl ´orez-Revuelta, “Visual privacy protection methods: A survey,”Expert Systems with Applications (ESWA), vol. 42, no. 9, pp. 4177–4195, 2015
work page 2015
-
[9]
Tools for protecting the privacy of specific individuals in video,
D. Chen, Y . Chang, R. Yan, and J. Yang, “Tools for protecting the privacy of specific individuals in video,”EURASIP Journal on Advances in Signal Processing, vol. 2007, pp. 1–9, 2007
work page 2007
-
[10]
Privacy- preserving human activity recognition from extreme low resolution,
M. S. Ryoo, B. Rothrock, C. Fleming, and H. J. Yang, “Privacy- preserving human activity recognition from extreme low resolution,” in AAAI Conference on Artificial Intelligence (AAAI), 2017, p. 4255–4262. IEEE TRANSACTIONS ON IMAGE PROCESSING 14
work page 2017
-
[11]
Deepprivacy: A generative ad- versarial network for face anonymization,
H. Hukkel ˚as, R. Mester, and F. Lindseth, “Deepprivacy: A generative ad- versarial network for face anonymization,” inInternational Symposium on Visual Computing (ISVC), 2019, pp. 565–578
work page 2019
-
[12]
Learning to anonymize faces for privacy preserving action detection,
Z. Ren, Y . J. Lee, and M. S. Ryoo, “Learning to anonymize faces for privacy preserving action detection,” inEuropean Conference on Computer Vision (ECCV), 2018, pp. 620–636
work page 2018
-
[13]
Extreme low resolution activity recognition with multi-siamese embedding learning,
M. S. Ryoo, K. Kim, and H. J. Yang, “Extreme low resolution activity recognition with multi-siamese embedding learning,” inAAAI Confer- ence on Artificial Intelligence (AAAI), 2017, pp. 7315–7322
work page 2017
-
[14]
Privacy preserving optics for miniature vision sensors,
F. Pittaluga and S. J. Koppal, “Privacy preserving optics for miniature vision sensors,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 314–324
work page 2015
-
[15]
Privacy-preserving deep action recognition: An adversarial learning framework and a new dataset,
Z. Wu, H. Wang, Z. Wang, H. Jin, and Z. Wang, “Privacy-preserving deep action recognition: An adversarial learning framework and a new dataset,”IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), vol. 44, no. 4, pp. 2126–2139, 2022
work page 2022
-
[16]
Spatio- temporal attention networks for action recognition and detection,
J. Li, X. Liu, W. Zhang, M. Zhang, J. Song, and N. Sebe, “Spatio- temporal attention networks for action recognition and detection,”IEEE Transactions on Multimedia (TMM), vol. 22, no. 11, pp. 2990–3001, 2020
work page 2020
-
[17]
Faster R-CNN: Towards real- time object detection with region proposal networks,
S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards real- time object detection with region proposal networks,”IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), vol. 39, no. 6, pp. 1137–1149, 2017
work page 2017
-
[18]
Deep dual consecutive network for human pose estimation,
Z. Liu, H. Chen, R. Feng, S. Wu, S. Ji, B. Yang, and X. Wang, “Deep dual consecutive network for human pose estimation,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 525–534
work page 2021
-
[19]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational Conference on Machine Learning (ICML), 2021, pp. 8748–8763
work page 2021
-
[20]
Clip-it! language-guided video summarization,
M. Narasimhan, A. Rohrbach, and T. Darrell, “Clip-it! language-guided video summarization,” inAdvances in Neural Information Processing Systems (NeurlPS), 2021, pp. 13 988–14 000
work page 2021
-
[21]
Expanding language-image pretrained models for gen- eral video recognition,
B. Ni, H. Peng, M. Chen, S. Zhang, G. Meng, J. Fu, S. Xiang, and H. Ling, “Expanding language-image pretrained models for gen- eral video recognition,” inEuropean Conference on Computer Vision (ECCV), 2022, pp. 1–18
work page 2022
-
[22]
Clip for all things zero-shot sketch-based image retrieval, fine-grained or not,
A. Sain, A. K. Bhunia, P. N. Chowdhury, S. Koley, T. Xiang, and Y .- Z. Song, “Clip for all things zero-shot sketch-based image retrieval, fine-grained or not,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 2765–2775
work page 2023
-
[23]
Videoclip: Contrastive pre-training for zero-shot video-text understanding,
H. Xu, G. Ghosh, P.-Y . B. Huang, D. Okhonko, A. Aghajanyan, and F. M. L. Z. C. Feichtenhofer, “Videoclip: Contrastive pre-training for zero-shot video-text understanding,” inConference on Empirical Meth- ods in Natural Language Processing (EMNLP), 2021, p. 6787–6800
work page 2021
-
[24]
UniMotion: A unified framework for motion-text-vision understanding and generation,
Z. Wang, X. Wang, S. Chen, Y . Cong, and M. Liu, “UniMotion: A unified framework for motion-text-vision understanding and generation,” arXiv preprint arXiv:2603.22282, 2026
-
[25]
Action recognition based on a bag of 3d points,
W. Li, Z. Zhang, and Z. Liu, “Action recognition based on a bag of 3d points,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2010, pp. 9–14
work page 2010
-
[26]
Mining actionlet ensemble for action recognition with depth cameras,
J. Wang, Z. Liu, Y . Wu, and J. Yuan, “Mining actionlet ensemble for action recognition with depth cameras,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2012, pp. 1290– 1297
work page 2012
-
[27]
Modeling 4d human- object interactions for event and object recognition,
P. Wei, Y . Zhao, N. Zheng, and S.-C. Zhu, “Modeling 4d human- object interactions for event and object recognition,” inIEEE/CVF International Conference on Computer Vision (ICCV), 2013, pp. 3272– 3279
work page 2013
-
[28]
Hopc: His- togram of oriented principal components of 3d pointclouds for action recognition,
H. Rahmani, A. Mahmood, D. Q Huynh, and A. Mian, “Hopc: His- togram of oriented principal components of 3d pointclouds for action recognition,” inEuropean Conference on Computer Vision (ECCV), 2014, pp. 742–757
work page 2014
-
[29]
Histogram of oriented principal components for cross-view action recognition,
H. Rahmani, A. Mahmood, D. Huynh, and A. Mian, “Histogram of oriented principal components for cross-view action recognition,”IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), vol. 38, no. 12, pp. 2430–2443, 2016
work page 2016
-
[30]
Ntu rgb+ d: A large scale dataset for 3d human activity analysis,
A. Shahroudy, J. Liu, T.-T. Ng, and G. Wang, “Ntu rgb+ d: A large scale dataset for 3d human activity analysis,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 1010– 1019
work page 2016
-
[31]
Jointly learning hetero- geneous features for rgb-d activity recognition,
J.-F. Hu, W.-S. Zheng, J. Lai, and J. Zhang, “Jointly learning hetero- geneous features for rgb-d activity recognition,”IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), vol. 39, no. 11, pp. 2186–2200, 2017
work page 2017
-
[32]
Ntu rgb+d 120: A large-scale benchmark for 3d human activity understanding,
J. Liu, A. Shahroudy, M. Perez, G. Wang, L.-Y . Duan, and A. C. Kot, “Ntu rgb+d 120: A large-scale benchmark for 3d human activity understanding,”IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), vol. 42, no. 10, pp. 2684–2701, 2019
work page 2019
-
[33]
Uav-human: A large benchmark for human behavior understanding with unmanned aerial vehicles,
T. Li, J. Liu, W. Zhang, Y . Ni, W. Wang, and Z. Li, “Uav-human: A large benchmark for human behavior understanding with unmanned aerial vehicles,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 16 266–16 275
work page 2021
-
[34]
Home action genome: Cooperative compositional action understanding,
N. Rai, H. Chen, J. Ji, R. Desai, K. Kozuka, S. Ishizaka, E. Adeli, and J. C. Niebles, “Home action genome: Cooperative compositional action understanding,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 11 184–11 193
work page 2021
-
[35]
Smg: A micro-gesture dataset towards spontaneous body gestures for emotional stress state analysis,
H. Chen, H. Shi, X. Liu, X. Li, and G. Zhao, “Smg: A micro-gesture dataset towards spontaneous body gestures for emotional stress state analysis,”International Journal of Computer Vision (IJCV), vol. 131, no. 6, pp. 1346–1366, 2023
work page 2023
-
[36]
Multi-view time-series hypergraph neural network for action recognition,
N. Ma, Z. Wu, Y . Feng, C. Wang, and Y . Gao, “Multi-view time-series hypergraph neural network for action recognition,”IEEE Transactions on Image Processing (TIP), vol. 33, pp. 3301–3313, 2024
work page 2024
-
[37]
H. Wang and L. Wang, “Beyond joints: Learning representations from primitive geometries for skeleton-based action recognition and detec- tion,”IEEE Transactions on Image Processing (TIP), vol. 27, no. 9, pp. 4382–4394, 2018
work page 2018
-
[38]
Dual-recommendation disentanglement network for view fuzz in action recognition,
W. Liu, X. Zhong, Z. Zhou, K. Jiang, Z. Wang, and C.-W. Lin, “Dual-recommendation disentanglement network for view fuzz in action recognition,”IEEE Transactions on Image Processing (TIP), vol. 32, pp. 2719–2733, 2023
work page 2023
-
[39]
Universal Skeleton Understanding via Differentiable Rendering and MLLMs
Z. Wang, P. Li, X. Wang, Y . Tang, K.-K. Ma, and M. Liu, “Universal skeleton understanding via differentiable rendering and MLLMs,”arXiv preprint arXiv:2603.18003, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Skeleton optical spectra-based action recognition using convolutional neural networks,
Y . Hou, Z. Li, P. Wang, and W. Li, “Skeleton optical spectra-based action recognition using convolutional neural networks,”IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), vol. 28, no. 3, pp. 807–811, 2016
work page 2016
-
[41]
Action recognition based on joint trajectory maps using convolutional neural networks,
P. Wang, Z. Li, Y . Hou, and W. Li, “Action recognition based on joint trajectory maps using convolutional neural networks,” inACM International Conference on Multimedia (ACMMM), 2016, pp. 102–106
work page 2016
-
[42]
L. Gorelick, M. Blank, E. Shechtman, M. Irani, and R. Basri, “Actions as space-time shapes,”IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), vol. 29, no. 12, pp. 2247–2253, 2007
work page 2007
-
[43]
Action recognition with improved trajec- tories,
H. Wang and C. Schmid, “Action recognition with improved trajec- tories,” inIEEE/CVF International Conference on Computer Vision (ICCV), 2013, pp. 3551–3558
work page 2013
-
[44]
Two-stream convolutional networks for action recognition in videos,
K. Simonyan and A. Zisserman, “Two-stream convolutional networks for action recognition in videos,” inAdvances in Neural Information Processing Systems (NeurlPS), 2014, p. 568–576
work page 2014
-
[45]
Learning spatiotemporal features with 3d convolutional networks,
D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, “Learning spatiotemporal features with 3d convolutional networks,” inIEEE/CVF International Conference on Computer Vision (ICCV), 2015, pp. 4489– 4497
work page 2015
-
[46]
Video action transformer network,
R. Girdhar, J. Carreira, C. Doersch, and A. Zisserman, “Video action transformer network,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 244–253
work page 2019
-
[47]
Is space-time attention all you need for video understanding?
G. Bertasius, H. Wang, and L. Torresani, “Is space-time attention all you need for video understanding?” inInternational Conference on Machine Learning (ICML), 2021, p. 4
work page 2021
-
[48]
Uniformer: Unifying convolution and self-attention for visual recognition,
K. Li, Y . Wang, J. Zhang, P. Gao, G. Song, Y . Liu, H. Li, and Y . Qiao, “Uniformer: Unifying convolution and self-attention for visual recognition,” pp. 12 581–12 600, 2023
work page 2023
-
[49]
Protecting visual secrets using adversarial nets,
N. Raval, A. Machanavajjhala, and L. P. Cox, “Protecting visual secrets using adversarial nets,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2017, pp. 1329–1332
work page 2017
-
[50]
Privacy-preserving action recognition using coded aper- ture videos,
Z. W. Wang, V . Vineet, F. Pittaluga, S. N. Sinha, O. Cossairt, and S. Bing Kang, “Privacy-preserving action recognition using coded aper- ture videos,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2019, pp. 0–0
work page 2019
-
[51]
Diffusercam: lensless single-exposure 3d imaging,
N. Antipa, G. Kuo, R. Heckel, B. Mildenhall, E. Bostan, R. Ng, and L. Waller, “Diffusercam: lensless single-exposure 3d imaging,”Optica, vol. 5, no. 1, pp. 1–9, 2018
work page 2018
-
[52]
Flatcam: Thin, lensless cameras using coded aperture and computation,
M. S. Asif, A. Ayremlou, A. Sankaranarayanan, A. Veeraraghavan, and R. G. Baraniuk, “Flatcam: Thin, lensless cameras using coded aperture and computation,”IEEE Transactions on Computational Imaging, vol. 3, no. 3, pp. 384–397, 2016
work page 2016
-
[53]
Learning a dynamic privacy-preserving camera robust to inversion attacks,
J. Cheng, X. Dai, J. Wan, N. Antipa, and N. Vasconcelos, “Learning a dynamic privacy-preserving camera robust to inversion attacks,” in Computer Vision – ECCV 2024, A. Leonardis, E. Ricci, S. Roth, IEEE TRANSACTIONS ON IMAGE PROCESSING 15 O. Russakovsky, T. Sattler, and G. Varol, Eds. Cham: Springer Nature Switzerland, 2025, pp. 349–367
work page 2024
-
[54]
Privhar: Recognizing human actions from privacy-preserving lens,
C. Hinojosa, M. Marquez, H. Arguello, E. Adeli, L. Fei-Fei, and J. C. Niebles, “Privhar: Recognizing human actions from privacy-preserving lens,” inEuropean Conference on Computer Vision (ECCV), 2022, pp. 314–332
work page 2022
-
[55]
Egoprivacy: What your first-person camera says about you?
Y . Li, G. Zhang, J. Cheng, Y . Li, X. Shan, D. Gao, J. Lyu, Y . Li, N. Bi, and N. Vasconcelos, “Egoprivacy: What your first-person camera says about you?” 2025
work page 2025
-
[56]
Image quality assessment: from error visibility to structural similarity,
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,”IEEE Transactions on Image Processing (TIP), vol. 13, no. 4, pp. 600–612, 2004
work page 2004
-
[57]
Image quality metrics: Psnr vs. ssim,
A. Hore and D. Ziou, “Image quality metrics: Psnr vs. ssim,” in International Conference on Pattern Recognition (ICPR), 2010, pp. 2366–2369
work page 2010
-
[58]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 586–595
work page 2018
-
[59]
R. C. Gonzales and P. Wintz,Digital image processing. Addison- Wesley Longman Publishing Co., Inc., 1987
work page 1987
-
[60]
Calibrating deep neural networks by pairwise constraints,
J. Cheng and N. Vasconcelos, “Calibrating deep neural networks by pairwise constraints,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 13 709–13 718
work page 2022
-
[61]
Temporal segment networks: Towards good practices for deep action recognition,
L. Wang, Y . Xiong, Z. Wang, Y . Qiao, D. Lin, X. Tang, and L. Van Gool, “Temporal segment networks: Towards good practices for deep action recognition,” inEuropean Conference on Computer Vision (ECCV), 2016, pp. 20–36
work page 2016
-
[62]
Slowfast networks for video recognition,
C. Feichtenhofer, H. Fan, J. Malik, and K. He, “Slowfast networks for video recognition,” inIEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 6202–6211
work page 2019
-
[63]
Tsm: Temporal shift module for efficient video understanding,
J. Lin, C. Gan, and S. Han, “Tsm: Temporal shift module for efficient video understanding,” inIEEE/CVF International Conference on Com- puter Vision (ICCV), 2019, pp. 7083–7093
work page 2019
-
[64]
Mvitv2: Improved multiscale vision transformers for classification and detection,
Y . Li, C.-Y . Wu, H. Fan, K. Mangalam, B. Xiong, J. Malik, and C. Feichtenhofer, “Mvitv2: Improved multiscale vision transformers for classification and detection,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 4804–4814
work page 2022
-
[65]
Z. Liu, J. Ning, Y . Cao, Y . Wei, Z. Zhang, S. Lin, and H. Hu, “Video swin transformer,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 3202–3211
work page 2022
-
[66]
Videomae: Masked autoen- coders are data-efficient learners for self-supervised video pre-training,
Z. Tong, Y . Song, J. Wang, and L. Wang, “Videomae: Masked autoen- coders are data-efficient learners for self-supervised video pre-training,” inAdvances in Neural Information Processing Systems (NeurlPS), 2022, pp. 10 078–10 093
work page 2022
-
[67]
Videomae v2: Scaling video masked autoencoders with dual masking,
L. Wang, B. Huang, Z. Zhao, Z. Tong, Y . He, Y . Wang, Y . Wang, and Y . Qiao, “Videomae v2: Scaling video masked autoencoders with dual masking,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 14 549–14 560
work page 2023
-
[68]
Uniformerv2: Unlocking the potential of image vits for video under- standing,
K. Li, Y . Wang, Y . He, Y . Li, Y . Wang, L. Wang, and Y . Qiao, “Uniformerv2: Unlocking the potential of image vits for video under- standing,” inIEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 1632–1643
work page 2023
-
[69]
Internvideo2: Scaling foundation models for multimodal video understanding,
Y . Wang, K. Li, X. Li, J. Yu, Y . He, G. Chen, B. Pei, R. Zheng, Z. Wang, Y . Shiet al., “Internvideo2: Scaling foundation models for multimodal video understanding,” inEuropean Conference on Computer Vision (ECCV), 2024, pp. 396–416
work page 2024
-
[70]
Temporal relational reasoning in videos,
B. Zhou, A. Andonian, A. Oliva, and A. Torralba, “Temporal relational reasoning in videos,” inEuropean Conference on Computer Vision (ECCV), 2018, pp. 803–818
work page 2018
-
[71]
Towards calibrated multi-label deep neural networks,
J. Cheng and N. Vasconcelos, “Towards calibrated multi-label deep neural networks,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024, pp. 27 589–27 599
work page 2024
-
[72]
Restormer: Efficient transformer for high-resolution image restoration,
S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, and M.-H. Yang, “Restormer: Efficient transformer for high-resolution image restoration,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 5728–5739
work page 2022
-
[73]
Arcface: Additive angular margin loss for deep face recognition,
J. Deng, J. Guo, N. Xue, and S. Zafeiriou, “Arcface: Additive angular margin loss for deep face recognition,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 4690– 4699. Mengyuan Liureceived his Ph.D. under the super- vision of Prof. Hong Liu at the School of Electri- cal Engineering and Computer Science (EE&CS), Peking ...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.