Automated Kernel Discovery Towards Understanding High-dimensional Bayesian Optimization
Pith reviewed 2026-05-21 08:22 UTC · model grok-4.3
The pith
An LLM-driven evolutionary framework discovers novel Gaussian process kernels for high-dimensional Bayesian optimization without conditioning on raw observations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
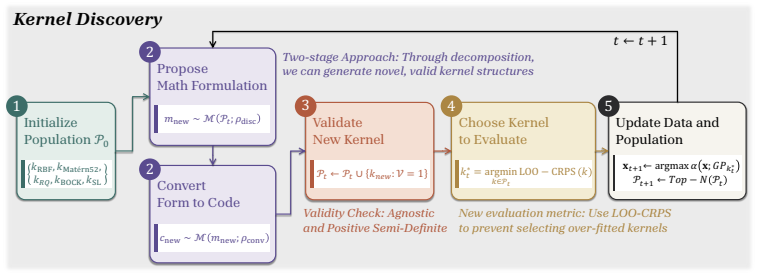
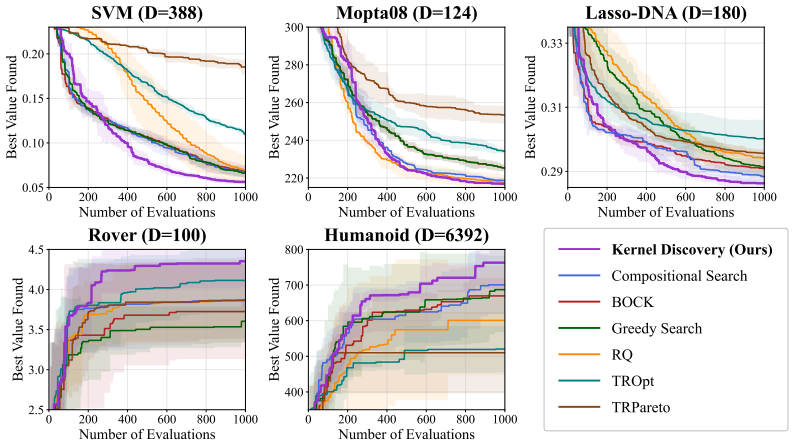
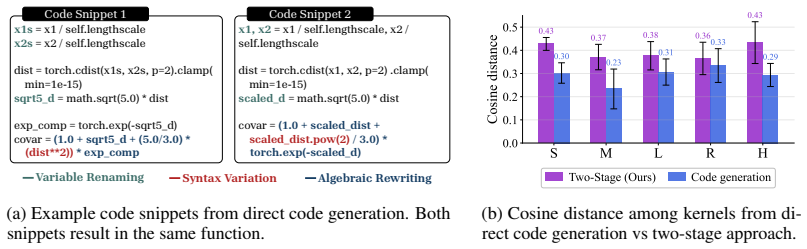
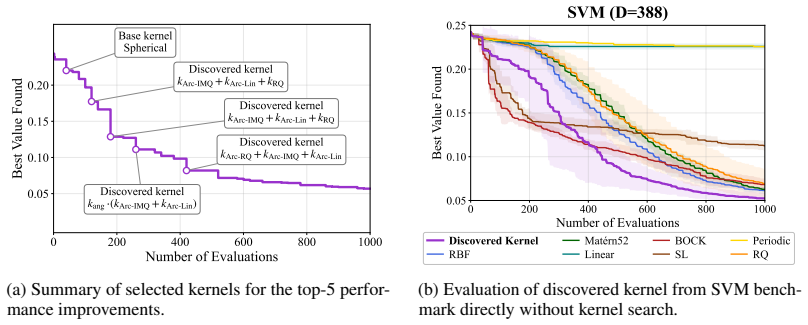
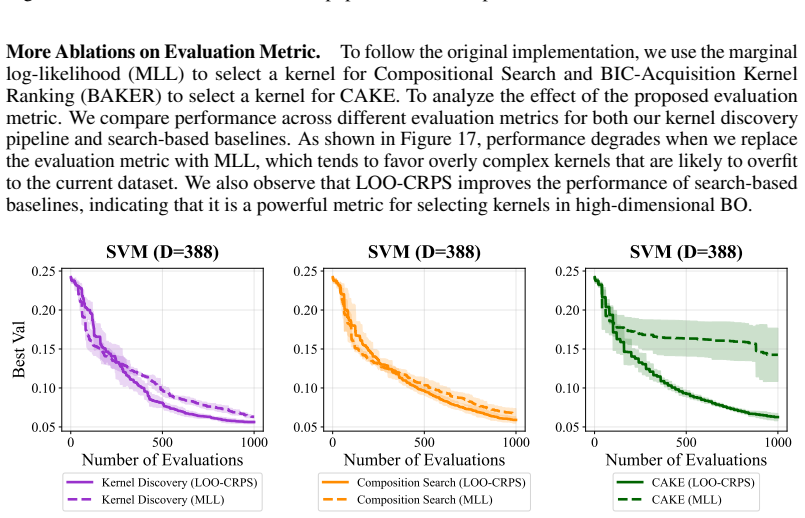
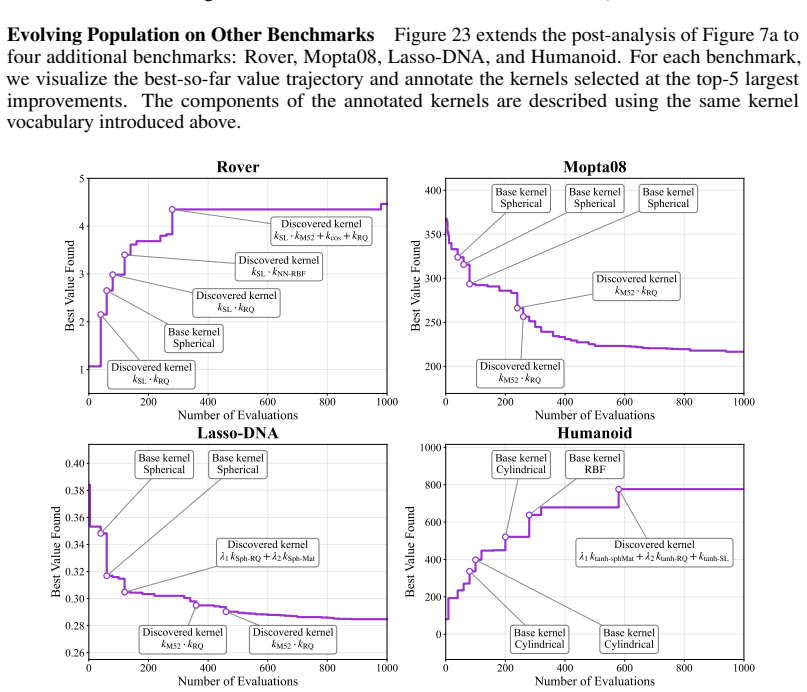
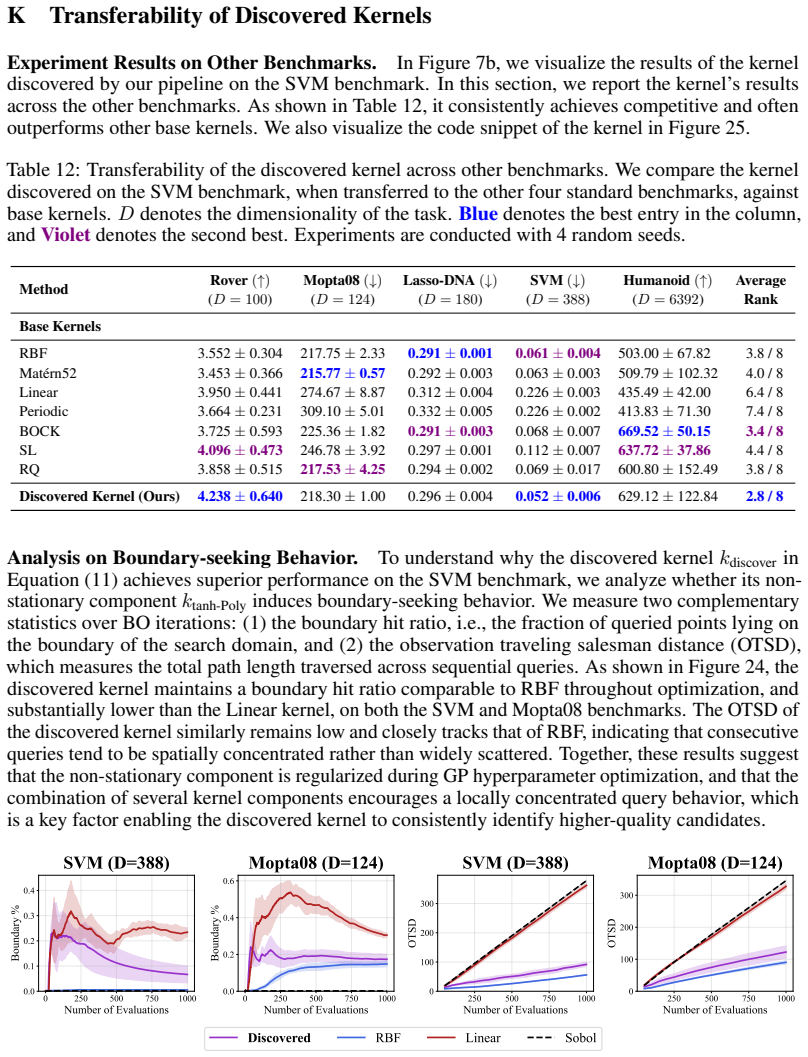
We introduce Kernel Discovery, a LLM-driven evolutionary framework for high-dimensional BO that searches a broader kernel space beyond predefined composition rules and does not require conditioning on observations. Motivated by the observation that directly prompting an LLM to generate kernel code yields syntactically varied but functionally identical kernels, we adopt a two-stage approach: an LLM first proposes novel mathematical forms, then a second LLM call converts each form into validated, executable code. We also propose a leave-one-out continuous ranked probability score (LOO-CRPS) as a selection criterion that penalizes overfitted kernels. On five high-dimensional BO benchmarks, our
What carries the argument
The two-stage LLM process in which one model proposes novel mathematical kernel forms and a second model turns them into executable code, together with LOO-CRPS selection that penalizes overfitting.
Load-bearing premise
Large language models can reliably propose mathematically novel and functionally distinct kernel forms without access to raw observations, and LOO-CRPS will select kernels that generalize rather than overfit in high-dimensional regimes.
What would settle it
Running Kernel Discovery on a new high-dimensional Bayesian optimization benchmark and checking whether the average rank across methods stays near 1.2 or whether the discovered kernels fail to beat standard automatic relevance determination kernels.
Figures





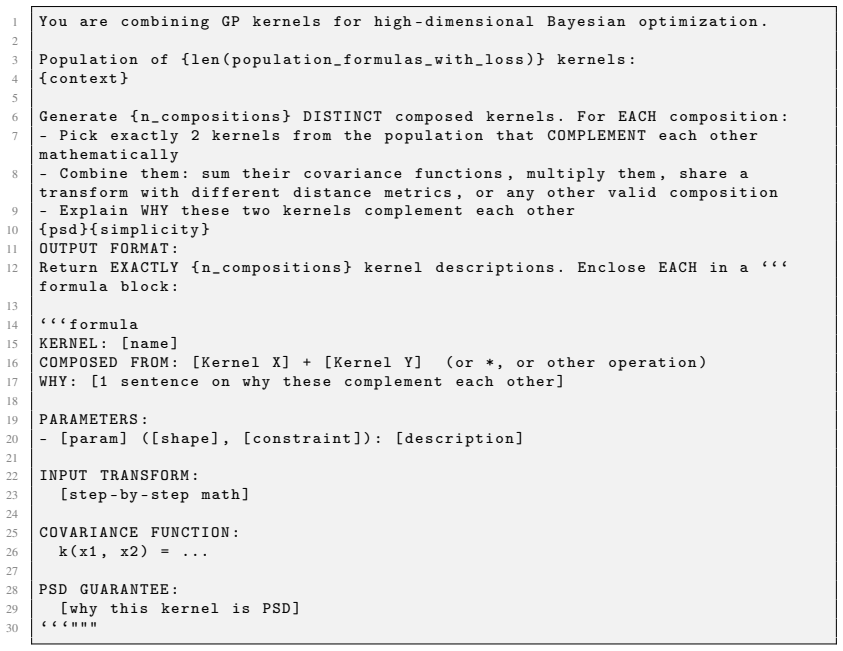
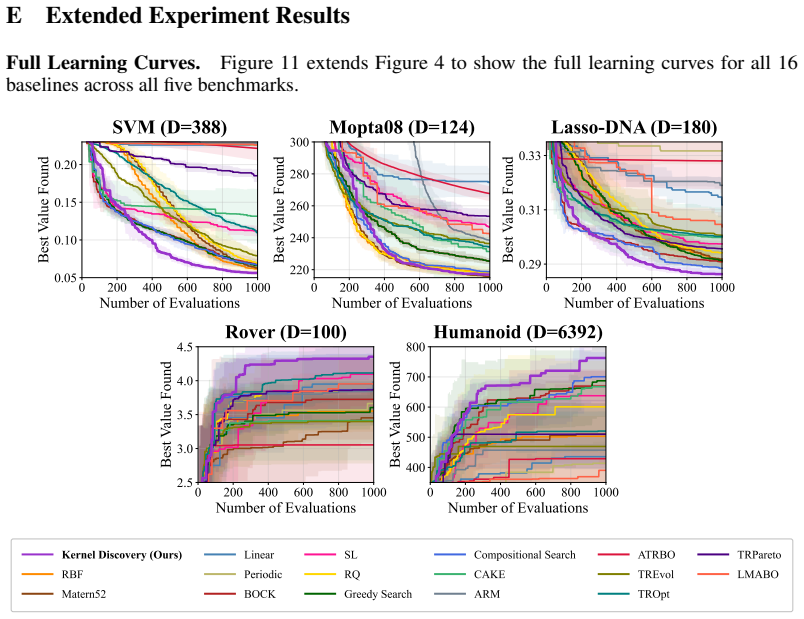



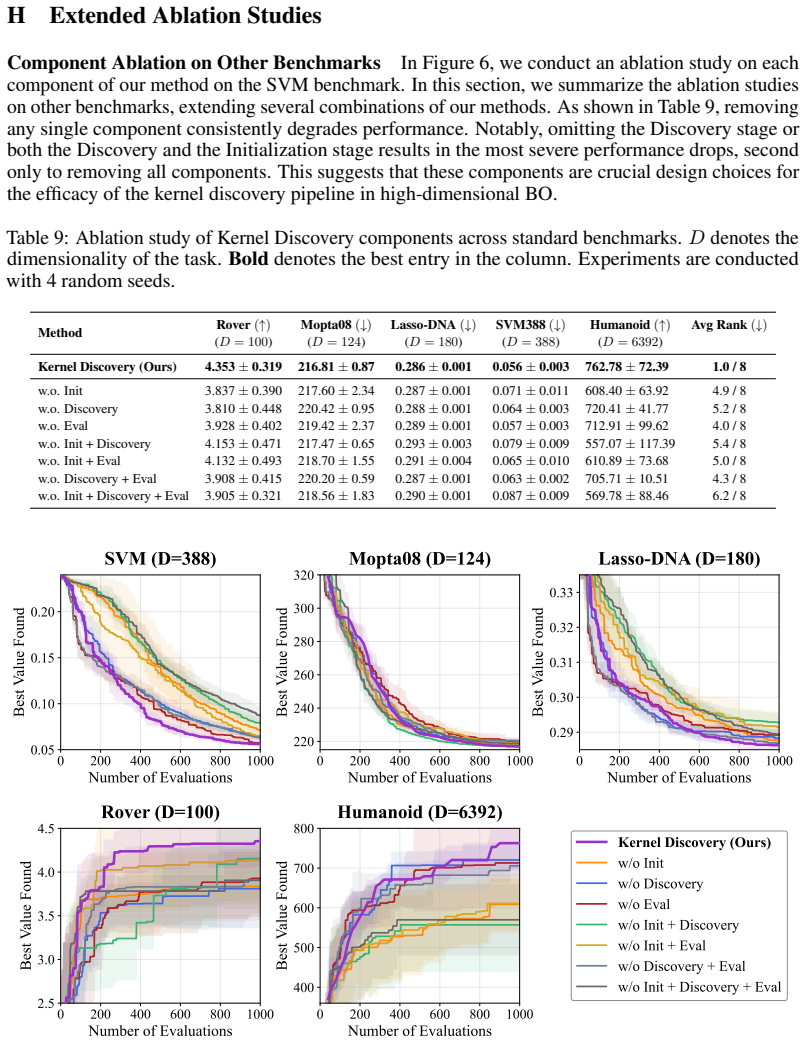
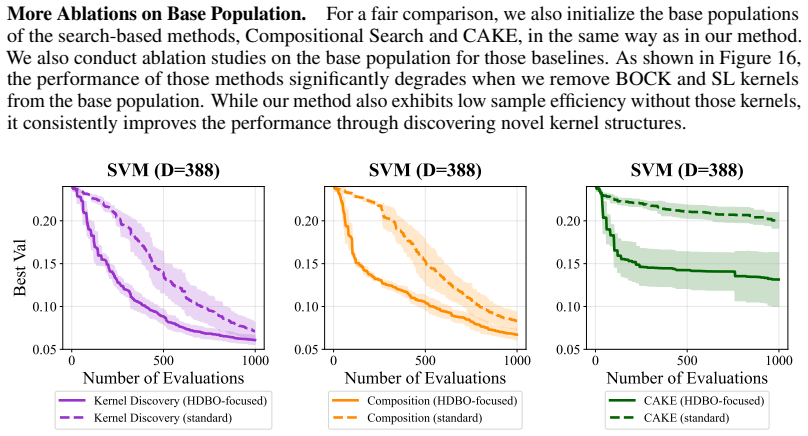








read the original abstract
Gaussian Process (GP) kernels are central to Bayesian optimization (BO), yet designing effective kernels for high-dimensional problems still relies on extensive manual engineering. Existing automated approaches struggle in high dimensions for two bottlenecks: their kernel search space is limited to additions and multiplications of base kernels, and LLM-based approaches require conditioning on raw observations, which becomes infeasible due to context-length limits and the difficulty of extracting meaningful patterns. We introduce \textbf{Kernel Discovery}, a LLM-driven evolutionary framework for high-dimensional BO that searches a broader kernel space beyond predefined composition rules and does not require conditioning on observations. Motivated by the observation that directly prompting an LLM to generate kernel code yields syntactically varied but functionally identical kernels, we adopt a two-stage approach: an LLM first proposes novel mathematical forms, then a second LLM call converts each form into validated, executable code. We also propose a leave-one-out continuous ranked probability score (LOO-CRPS) as a selection criterion that penalizes overfitted kernels. On five high-dimensional BO benchmarks, our method achieves an average rank of \textbf{1.2 out of 17}, outperforming competitive baselines. We further analyze the discovered kernels to identify which kernels lead to improvements in high-dimensional BO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Kernel Discovery, an LLM-driven evolutionary framework for automated kernel design in high-dimensional Bayesian optimization. It uses a two-stage process in which one LLM proposes novel mathematical kernel forms and a second converts them to executable code, avoiding direct observation conditioning to sidestep context-length limits. A leave-one-out continuous ranked probability score (LOO-CRPS) serves as the selection criterion to penalize overfitting. The method is evaluated on five high-dimensional BO benchmarks, where it reports an average rank of 1.2 out of 17 competing approaches, and the discovered kernels are further analyzed to identify properties that improve high-dimensional BO performance.
Significance. If the performance claims are substantiated, the work offers a practical advance in automated kernel engineering for GPs in regimes where manual design is intractable. The two-stage LLM proposal and LOO-CRPS selection address documented bottlenecks in prior search-based and LLM-based kernel methods. Credit is due for the broader kernel space explored beyond fixed composition rules and for the explicit analysis of which kernel characteristics benefit high-dimensional BO. The empirical nature of the contribution makes rigorous experimental reporting essential to its significance.
major comments (3)
- [§4] §4 (Experimental results): the headline claim of average rank 1.2 out of 17 is presented without the number of independent runs, standard deviations across runs, or any statistical significance tests (e.g., paired Wilcoxon or Friedman tests) against the 16 baselines. This information is load-bearing for the central performance assertion.
- [§3.3] §3.3 (LOO-CRPS selection): the criterion is motivated as penalizing overfit kernels, yet the manuscript provides no ablation or held-out generalization test demonstrating that LOO-CRPS prefers kernels that extrapolate rather than fit noise in the sparse high-dimensional regime. Given the skeptic concern that leave-one-out on limited data may still reward excessive flexibility, this validation is required to support the selection mechanism.
- [§3.2] §3.2 (two-stage proposal): the claim that the two-stage LLM process yields functionally distinct kernels is central to the broader search space argument, but the paper does not quantify functional diversity (e.g., via kernel Gram-matrix distances or predictive behavior on synthetic functions) or describe explicit diversity maintenance in the evolutionary loop.
minor comments (2)
- [Abstract / §4] The abstract and §4 refer to “five high-dimensional BO benchmarks” without naming them or providing a summary table of their dimensions and characteristics; explicit identification would aid reproducibility.
- [§3.3] Notation for the LOO-CRPS formula in §3.3 could be clarified by explicitly stating the predictive distribution used for each left-out point.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important aspects for strengthening the experimental rigor and supporting arguments. We address each major comment point by point below, indicating the revisions we plan to make.
read point-by-point responses
-
Referee: [§4] §4 (Experimental results): the headline claim of average rank 1.2 out of 17 is presented without the number of independent runs, standard deviations across runs, or any statistical significance tests (e.g., paired Wilcoxon or Friedman tests) against the 16 baselines. This information is load-bearing for the central performance assertion.
Authors: We agree that the experimental reporting in §4 requires these details to fully substantiate the performance claims. In the revised manuscript, we will explicitly state the number of independent runs, report standard deviations across runs, and include statistical significance tests such as the Friedman test with post-hoc analysis to compare our method against the baselines. revision: yes
-
Referee: [§3.3] §3.3 (LOO-CRPS selection): the criterion is motivated as penalizing overfit kernels, yet the manuscript provides no ablation or held-out generalization test demonstrating that LOO-CRPS prefers kernels that extrapolate rather than fit noise in the sparse high-dimensional regime. Given the skeptic concern that leave-one-out on limited data may still reward excessive flexibility, this validation is required to support the selection mechanism.
Authors: We appreciate the referee's concern regarding the validation of LOO-CRPS. While the criterion is intended to penalize overfitting through its leave-one-out predictive evaluation, we agree that additional evidence would strengthen the case. In the revised manuscript, we will add an ablation study in §3.3 comparing LOO-CRPS to other selection criteria, along with a held-out generalization test on synthetic high-dimensional data to show that it favors kernels with better extrapolation properties. revision: yes
-
Referee: [§3.2] §3.2 (two-stage proposal): the claim that the two-stage LLM process yields functionally distinct kernels is central to the broader search space argument, but the paper does not quantify functional diversity (e.g., via kernel Gram-matrix distances or predictive behavior on synthetic functions) or describe explicit diversity maintenance in the evolutionary loop.
Authors: We thank the referee for this observation. To better support the claim that the two-stage process enables a functionally broader kernel space, we will revise §3.2 to include quantitative analysis of functional diversity, for example by computing distances between kernel Gram matrices evaluated on synthetic functions and by examining predictive performance differences. We will also describe the diversity-promoting aspects of the evolutionary loop, such as the mutation and selection procedures. revision: yes
Circularity Check
No circularity: empirical search procedure with external benchmark evaluation
full rationale
The paper introduces an LLM-driven evolutionary framework for automated kernel discovery in high-dimensional BO. It relies on a two-stage proposal process and LOO-CRPS selection, then reports comparative performance (avg rank 1.2/17) on five external benchmarks. No mathematical derivations, first-principles predictions, or fitted parameters are presented that could reduce to self-definitions or self-citations. The central claims rest on algorithmic description plus independent experimental results rather than any internal consistency loop.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs prompted directly produce syntactically varied but functionally identical kernels, motivating the two-stage separation of form proposal and code generation.
- domain assumption LOO-CRPS penalizes overfitting kernels more effectively than standard likelihood in high-dimensional BO settings.
Reference graph
Works this paper leans on
-
[1]
Ryan Turner, David Eriksson, Michael McCourt, Juha Kiili, Eero Laaksonen, Zhen Xu, and Isabelle Guyon. Bayesian optimization is superior to random search for machine learning hyperparameter tuning: Analysis of the black-box optimization challenge 2020. InNeurIPS 2020 Competition and Demonstration Track, 2021
work page 2020
-
[2]
Pre-training helps bayesian optimization too
Zi Wang, George E Dahl, Kevin Swersky, Chansoo Lee, Zelda Mariet, Zachary Nado, Justin Gilmer, Jasper Snoek, and Zoubin Ghahramani. Pre-training helps bayesian optimization too. InICML Workshop on Adaptive Experimental Design and Active Learning in the Real World, 2022
work page 2022
-
[3]
Raiders of the Lost Architecture: Kernels for Bayesian Optimization in Conditional Parameter Spaces
Kevin Swersky, David Duvenaud, Jasper Snoek, Frank Hutter, and Michael A Osborne. Raiders of the lost architecture: Kernels for bayesian optimization in conditional parameter spaces. arXiv preprint arXiv:1409.4011, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[4]
Neural architecture search with bayesian optimisation and optimal transport
Kirthevasan Kandasamy, Willie Neiswanger, Jeff Schneider, Barnabas Poczos, and Eric P Xing. Neural architecture search with bayesian optimisation and optimal transport. InAdvances in Neural Information Processing Systems (NeurIPS), 2018
work page 2018
-
[5]
Local latent space bayesian optimization over structured inputs
Natalie Maus, Haydn Jones, Juston Moore, Matt J Kusner, John Bradshaw, and Jacob Gard- ner. Local latent space bayesian optimization over structured inputs. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[6]
Latent bayesian optimization via autoregressive normalizing flows
Seunghun Lee, Jinyoung Park, Jaewon Chu, Minseo Yoon, and Hyunwoo J Kim. Latent bayesian optimization via autoregressive normalizing flows. InInternational Conference on Learning Representations (ICLR), 2025
work page 2025
-
[7]
Learning search space partition for black-box optimization using monte carlo tree search
Linnan Wang, Rodrigo Fonseca, and Yuandong Tian. Learning search space partition for black-box optimization using monte carlo tree search. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
work page 2020
-
[8]
Felix Berkenkamp, Andreas Krause, and Angela P Schoellig. Bayesian optimization with safety constraints: safe and automatic parameter tuning in robotics.Machine Learning, 2023
work page 2023
-
[9]
Harold J Kushner. A new method of locating the maximum point of an arbitrary multipeak curve in the presence of noise.Journal of Basic Engineering, 1964
work page 1964
-
[10]
Cambridge University Press, 2023
Roman Garnett.Bayesian optimization. Cambridge University Press, 2023
work page 2023
-
[11]
David K Duvenaud, Hannes Nickisch, and Carl Rasmussen. Additive gaussian processes. In Advances in Neural Information Processing Systems (NeurIPS), 2011
work page 2011
-
[12]
High dimensional bayesian optimisation and bandits via additive models
Kirthevasan Kandasamy, Jeff Schneider, and Barnabás Póczos. High dimensional bayesian optimisation and bandits via additive models. InInternational Conference on Machine Learning (ICML), 2015
work page 2015
-
[13]
Discovering and exploiting additive structure for bayesian optimization
Jacob Gardner, Chuan Guo, Kilian Weinberger, Roman Garnett, and Roger Grosse. Discovering and exploiting additive structure for bayesian optimization. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2017
work page 2017
-
[14]
Additive gaussian processes revisited
Xiaoyu Lu, Alexis Boukouvalas, and James Hensman. Additive gaussian processes revisited. InInternational Conference on Machine Learning (ICML), 2022
work page 2022
-
[15]
Ziyu Wang, Frank Hutter, Masrour Zoghi, David Matheson, and Nando De Feitas. Bayesian optimization in a billion dimensions via random embeddings.Journal of Artificial Intelligence Research, 2016
work page 2016
-
[16]
A framework for bayesian optimization in embedded subspaces
Amin Nayebi, Alexander Munteanu, and Matthias Poloczek. A framework for bayesian optimization in embedded subspaces. InInternational Conference on Machine Learning (ICML), 2019
work page 2019
-
[17]
Re-examining linear em- beddings for high-dimensional bayesian optimization
Ben Letham, Roberto Calandra, Akshara Rai, and Eytan Bakshy. Re-examining linear em- beddings for high-dimensional bayesian optimization. InAdvances in Neural Information Processing Systems (NeurIPS), 2020. 10
work page 2020
-
[18]
High-dimensional bayesian optimization with sparse axis-aligned subspaces
David Eriksson and Martin Jankowiak. High-dimensional bayesian optimization with sparse axis-aligned subspaces. InConference on Uncertainty in Artificial Intelligence (UAI), 2021
work page 2021
-
[19]
Increasing the scope as you learn: Adaptive bayesian optimization in nested subspaces
Leonard Papenmeier, Luigi Nardi, and Matthias Poloczek. Increasing the scope as you learn: Adaptive bayesian optimization in nested subspaces. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[20]
Scalable global optimization via local bayesian optimization
David Eriksson, Michael Pearce, Jacob Gardner, Ryan D Turner, and Matthias Poloczek. Scalable global optimization via local bayesian optimization. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
work page 2019
-
[21]
Scalable constrained bayesian optimization
David Eriksson and Matthias Poloczek. Scalable constrained bayesian optimization. InInterna- tional Conference on Artificial Intelligence and Statistics (AISTATS), 2021
work page 2021
-
[22]
Joint composite latent space bayesian optimization
Natalie Maus, Zhiyuan Jerry Lin, Maximilian Balandat, and Eytan Bakshy. Joint composite latent space bayesian optimization. InInternational Conference on Machine Learning (ICML), 2024
work page 2024
-
[23]
Vanilla bayesian optimization performs great in high dimensions
Carl Hvarfner, Erik Orm Hellsten, and Luigi Nardi. Vanilla bayesian optimization performs great in high dimensions. InInternational Conference on Machine Learning (ICML), 2024
work page 2024
-
[24]
Standard gaussian process is all you need for high-dimensional bayesian optimization
Zhitong Xu, Haitao Wang, Jeff M Phillips, and Shandian Zhe. Standard gaussian process is all you need for high-dimensional bayesian optimization. InInternational Conference on Learning Representations (ICLR), 2025
work page 2025
-
[25]
Bock: Bayesian optimization with cylindrical kernels
ChangYong Oh, Efstratios Gavves, and Max Welling. Bock: Bayesian optimization with cylindrical kernels. InInternational Conference on Machine Learning (ICML), 2018
work page 2018
-
[26]
We still don’t understand high-dimensional bayesian optimization
Colin Doumont, Donney Fan, Natalie Maus, Jacob R Gardner, Henry Moss, and Geoff Pleiss. We still don’t understand high-dimensional bayesian optimization. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2026
work page 2026
-
[27]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Mathematical discoveries from program search with large language models
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. Mathematical discoveries from program search with large language models. Nature, 2024
work page 2024
-
[31]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphaevolve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Funbo: Discovering acquisition functions for bayesian optimization with funsearch
Virginia Aglietti, Ira Ktena, Jessica Schrouff, Eleni Sgouritsa, Francisco Ruiz, Alan Malek, Alexis Bellot, and Silvia Chiappa. Funbo: Discovering acquisition functions for bayesian optimization with funsearch. InInternational Conference on Machine Learning (ICML), 2025
work page 2025
-
[33]
Trajevo: Trajectory prediction heuristics design via llm-driven evolution
Zhikai Zhao, Chuanbo Hua, Federico Berto, Kanghoon Lee, Zihan Ma, Jiachen Li, and Jinkyoo Park. Trajevo: Trajectory prediction heuristics design via llm-driven evolution. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2026. 11
work page 2026
-
[34]
Sein Kim, Sangwu Park, Hongseok Kang, Wonjoong Kim, Jimin Seo, Yeonjun In, Kanghoon Yoon, and Chanyoung Park. Self-evolverec: Self-evolving recommender systems with llm-based directional feedback.arXiv preprint arXiv:2602.12612, 2026
-
[35]
Adaptive and safe bayesian optimization in high dimensions via one-dimensional subspaces
Johannes Kirschner, Mojmir Mutny, Nicole Hiller, Rasmus Ischebeck, and Andreas Krause. Adaptive and safe bayesian optimization in high dimensions via one-dimensional subspaces. In International Conference on Machine Learning (ICML), 2019
work page 2019
-
[36]
Monte carlo tree search based variable selection for high dimensional bayesian optimization
Lei Song, Ke Xue, Xiaobin Huang, and Chao Qian. Monte carlo tree search based variable selection for high dimensional bayesian optimization. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[37]
O., Hvarfner, C., Papenmeier, L., and Nardi, L
Erik Orm Hellsten, Carl Hvarfner, Leonard Papenmeier, and Luigi Nardi. High-dimensional bayesian optimization with group testing.arXiv preprint arXiv:2310.03515, 2023
-
[38]
Multi-objective bayesian optimization over high-dimensional search spaces
Samuel Daulton, David Eriksson, Maximilian Balandat, and Eytan Bakshy. Multi-objective bayesian optimization over high-dimensional search spaces. InConference on Uncertainty in Artificial Intelligence (UAI), 2022
work page 2022
-
[39]
Discovering many diverse solutions with bayesian optimization
Natalie Maus, Kaiwen Wu, David Eriksson, and Jacob Gardner. Discovering many diverse solutions with bayesian optimization. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2023
work page 2023
-
[40]
Feasibility-driven trust region bayesian optimization
Paolo Ascia, Elena Raponi, Thomas Bäck, and Fabian Duddeck. Feasibility-driven trust region bayesian optimization. InInternational Conference on Automated Machine Learning (AutoML), 2025
work page 2025
-
[41]
Understanding high-dimensional bayesian optimization
Leonard Papenmeier, Matthias Poloczek, and Luigi Nardi. Understanding high-dimensional bayesian optimization. InInternational Conference on Machine Learning (ICML), 2025
work page 2025
-
[42]
Cylindrical thompson sampling for high-dimensional bayesian optimization
Bahador Rashidi, Kerrick Johnstonbaugh, and Chao Gao. Cylindrical thompson sampling for high-dimensional bayesian optimization. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2024
work page 2024
-
[43]
Adaptive acquisition selection for bayesian optimization with large language models
Giang Ngo, Dat Phan Trong, Dang Nguyen, Sunil Gupta, and Svetha Venkatesh. Adaptive acquisition selection for bayesian optimization with large language models. InInternational Conference on Learning Representations (ICLR), 2026
work page 2026
-
[44]
Wenhu Li, Niki van Stein, Thomas Bäck, and Elena Raponi. Llamea-bo: A large language model evolutionary algorithm for automatically generating bayesian optimization algorithms. arXiv preprint arXiv:2505.21034, 2025
-
[45]
Large language models to enhance bayesian optimization
Tennison Liu, Nicolás Astorga, Nabeel Seedat, and Mihaela van der Schaar. Large language models to enhance bayesian optimization. InInternational Conference on Learning Representa- tions (ICLR), 2024
work page 2024
-
[46]
Adaptive kernel design for bayesian optimization is a piece of cake with llms
Richard Cornelius Suwandi, Feng Yin, Juntao Wang, Renjie Li, Tsung-Hui Chang, and Sergios Theodoridis. Adaptive kernel design for bayesian optimization is a piece of cake with llms. In Advances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[47]
We are underselling the modularity of Bayesian optimization
Austin Tripp. We are underselling the modularity of Bayesian optimization. https://www. austintripp.ca/blog/2026-02-09-bo-modularity/, 2026. Accessed: 2026-04-14
work page 2026
-
[48]
Gaussian processes in machine learning
Carl Edward Rasmussen. Gaussian processes in machine learning. InSummer School on Machine Learning. Springer, 2003
work page 2003
-
[49]
The application of bayesian methods for seeking the extremum.Towards Global Optimization, 1998
Jonas Mockus. The application of bayesian methods for seeking the extremum.Towards Global Optimization, 1998
work page 1998
-
[50]
Richard H Byrd, Peihuang Lu, Jorge Nocedal, and Ciyou Zhu. A limited memory algorithm for bound constrained optimization.SIAM Journal on Scientific Computing, 1995
work page 1995
-
[51]
Gaussian processes for regression
Christopher Williams and Carl Rasmussen. Gaussian processes for regression. InAdvances in Neural Information Processing Systems (NeurIPS), 1995. 12
work page 1995
-
[52]
Batched large-scale bayesian optimization in high-dimensional spaces
Zi Wang, Clement Gehring, Pushmeet Kohli, and Stefanie Jegelka. Batched large-scale bayesian optimization in high-dimensional spaces. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2018
work page 2018
-
[53]
Lassobench: A high- dimensional hyperparameter optimization benchmark suite for lasso
Kenan Šehi ´c, Alexandre Gramfort, Joseph Salmon, and Luigi Nardi. Lassobench: A high- dimensional hyperparameter optimization benchmark suite for lasso. InInternational Confer- ence on Automated Machine Learning (AutoML), 2022
work page 2022
-
[54]
An experimental study in adaptive kernel selection for bayesian optimization.IEEE Access, 2019
Ibai Roman, Roberto Santana, Alexander Mendiburu, and Jose A Lozano. An experimental study in adaptive kernel selection for bayesian optimization.IEEE Access, 2019
work page 2019
-
[55]
Structure discovery in nonparametric regression through compositional kernel search
David Duvenaud, James Lloyd, Roger Grosse, Joshua Tenenbaum, and Ghahramani Zoubin. Structure discovery in nonparametric regression through compositional kernel search. In International Conference on Machine Learning (ICML), 2013
work page 2013
-
[56]
Unexpected improvements to expected improvement for bayesian optimization
Sebastian Ament, Samuel Daulton, David Eriksson, Maximilian Balandat, and Eytan Bakshy. Unexpected improvements to expected improvement for bayesian optimization. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[57]
Construction and comparison of high-dimensional sobol’generators.Wilmott, 2011
Ilya M Sobol’, Danil Asotsky, Alexander Kreinin, and Sergei Kucherenko. Construction and comparison of high-dimensional sobol’generators.Wilmott, 2011. 13 Appendix A Task Details We evaluate our method on five standard high-dimensional BO benchmarks covering a range of problem types and dimensionalities. Rover (D= 100 ).The Rover benchmark [ 52] is a traj...
work page 2011
-
[58]
The system calls ‘ E v o l v e d K e r n e l ( a r d _ n u m _ d i m s = D ) ‘
_ _i nit __ S I G N A T U R E : ‘ __init__ ‘ MUST accept ‘ a r d _ n u m _ d i m s : int ‘ as the ONLY re qu ir ed p a r a m e t e r . The system calls ‘ E v o l v e d K e r n e l ( a r d _ n u m _ d i m s = D ) ‘. All other args MUST have d ef au lt s . NEVER add re qu ire d args like ‘q : int ‘ , ‘ center : Tensor ‘ , ‘M : int ‘
-
[59]
FORWARD S I G N A T U R E : ‘ def forward ( self , x1 , x2 , diag = False , ** params ) ‘ - always accept ** params
-
[60]
BATCH - SAFE SHAPES ( C RI TIC AL ) : The kernel is tested with these exact shapes - your code MUST handle ALL of them : 13- 2 D : x1 =(5 , D ) vs x2 =(1 , D ) -> output must be (5 , 1) , NOT (5 , 5) 14- 2 D : x1 =(3 , D ) vs x2 =(7 , D ) -> output must be (3 , 7) 15- 3 D batched ( BoTorch acqf o p t i m i z a t i o n ) : x1 =(1 , 4 , D ) vs x2 =(1 , 3 , ...
-
[61]
OUTPUT SHAPE : return (... , N1 , N2 ) for ANY N1 != N2 . If your output is ( N1 , N1 ) instead of ( N1 , N2 ) , you have a bug
-
[62]
cdist ( x1s , x2s , p =2) ‘ - NEVER ‘ x1
D IS TAN CE : ‘ torch . cdist ( x1s , x2s , p =2) ‘ - NEVER ‘ x1 . u n s q u e e z e ( -2) - x2 . u n s q u e e z e ( -3) ‘ ( OOM )
- [63]
- [64]
-
[65]
NO IN - PLACE : ‘x = x + y ‘ not ‘x += y ‘. ‘x = x . clamp (...) ‘ not ‘x . clamp_ (...) ‘
-
[66]
NO DETACH / NUMPY : never ‘. detach () ‘, ‘. numpy () ‘, ‘. item () ‘, ‘ torch . no_grad () ‘ in forward
-
[67]
clamp ( min =1 e -15) ‘ before sqrt / log , ‘
N U M E R I C A L : ‘. clamp ( min =1 e -15) ‘ before sqrt / log , ‘. clamp ( max =20.0) ‘ for exp
-
[68]
L E N G T H S C A L E : if ‘ h a s _ l e n g t h s c a l e = True ‘ , do NOT ‘ r e g i s t e r _ p a r a m e t e r (" r a w _ l e n g t h s c a l e " , ...) ‘
-
[69]
PARAM ORDER : ‘ r e g i s t e r _ p a r a m e t e r ( name , ...) ‘ BEFORE ‘ r e g i s t e r _ c o n s t r a i n t ( name , ...) ‘
-
[70]
d iag on al ( dim1 = -2 , dim2 = -1) ‘
DIAG : ‘ if diag : return covar . d iag on al ( dim1 = -2 , dim2 = -1) ‘
- [71]
-
[72]
NO SELF - R E A S S I G N M E N T in forward () : never ‘ self . x = ... ‘ - use local v a r i a b l e s
-
[73]
ONLY USE EX IS TI NG g py tor ch classes
-
[74]
NO SUB - KERNELS : do NOT i n s t a n t i a t e gp yt orc h kernel objects ( e . g . ‘ M a t e r n K e r n e l () ‘, ‘ R B F K e r n e l () ‘) as sub - c o m p o n e n t s . They produce L a z y E v a l u a t e d K e r n e l T e n s o r with u n p r e d i c t a b l e shapes . Instead , i m p l e m e n t the formula dir ec tl y ( e . g . for Matern -5/2: ‘...
-
[75]
NO DATA - D E P E N D E N T BOUNDS in forward () : never compute bounds / center from the input data ( e . g . ‘ x1 . max ( dim = -2) ‘ or ‘ x1 . min ( dim = -2) ‘) . These change with N and break shape i n v a r i a n c e . Store fixed bounds via ‘ register_buffer ‘ in __init__ , or use c o n s t a n t s ( e . g . 0 and 1)
-
[76]
SCALAR P AI RW ISE DI STA NC E : when c o m p u t i n g d is tan ce between scalar values ( e . g . warped radii of shape (... , N , 1) ) , use ‘ torch . cdist ( r1 , r2 , p =2) ‘ which gives (... , N1 , N2 ) . NEVER use ‘ r1 - r2 ‘ or ‘ torch . abs ( r1 - r2 ) ‘ - this gives (... , N1 , 1) not (... , N1 , N2 ) and breaks cross - pair c o m p u t a t i o ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.