Introspective X Training: Feedback Conditioning Improves Scaling Across all LLM Training Stages
Pith reviewed 2026-05-21 08:24 UTC · model grok-4.3
The pith
Introspective Training prefixes LLM data with critique feedback from reward models to improve scaling from pre-training onward.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
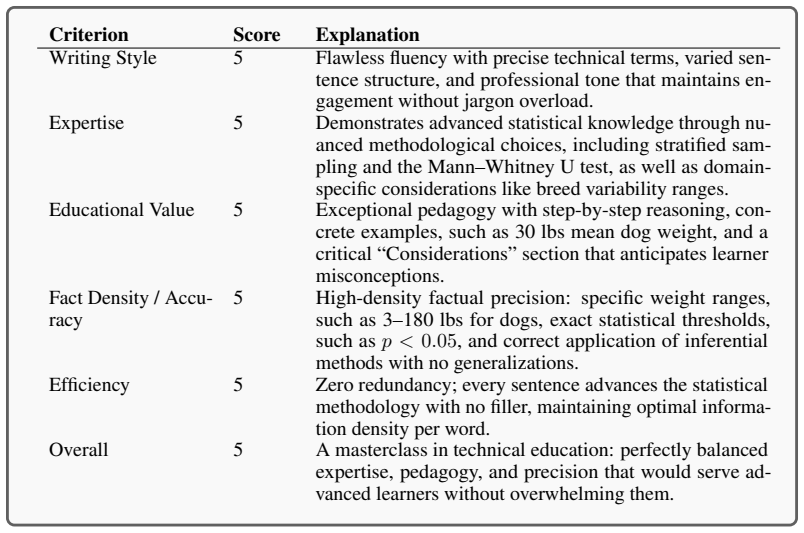
Introspective Training (IXT) uses a thinking reward model to annotate data with natural language critique feedback and then prefix-conditions the training data with this feedback. This enables quality-aware training from the earliest pipeline stages. On 7.5-12B models trained from scratch to 18 trillion tokens, the method produces up to 2.8x compute efficiency gains across scaling curves and performance levels in math and code that remain unreachable for models trained without the conditioning.
What carries the argument
Introspective Training (IXT), a prefix-conditioning technique that inserts natural language critique feedback generated by a thinking reward model into data at any training stage.
If this is right
- Scaling curves improve so that target performance requires substantially less total compute across the full training pipeline.
- Models reach performance levels in math and code that standard training cannot match even with additional tokens or parameters.
- The conditioning technique works at every stage, allowing post-training signals to influence pre-training directly.
- Not all tokens receive equal weight from the start, shifting training toward quality-aware learning much earlier than conventional alignment.
Where Pith is reading between the lines
- The method may reduce reliance on separate post-training alignment by embedding quality signals from the beginning.
- Feedback conditioning could combine with existing data-filtering or curriculum strategies to further amplify efficiency gains.
- If the reward model feedback proves robust, similar introspection loops might apply to multimodal or non-transformer architectures.
Load-bearing premise
Critique feedback generated by the reward model on later-stage data remains useful and non-misleading when applied to data from much earlier training stages whose distribution differs.
What would settle it
Train matched 12B models to 18T tokens with and without the feedback prefixing on identical data and compute, then compare final math and code benchmark scores; equal or better results without IXT would falsify the efficiency and performance claims.
Figures







read the original abstract
We tackle the question of how to scale more efficiently across the many, ever-growing stages of current LLM training pipelines. Our guiding intuition stems from the fact that the dynamics of later stages of the pipeline, e.g. post-training, can be used to inform earlier stages such as pre-training. To this end, we propose Introspective Training (or IXT), inspired by offline reward-conditioned reinforcement learning and applicable to any stage of training. IXT uses a thinking reward model to annotate data with natural language critique based feedback, enabling quality aware training from the earliest stages of the pipeline. Models are then trained by prefix-conditioning the data with the generated feedback -- ensuring that not all tokens are treated equally starting much earlier in training than usual. Comprehensive experiments on 7.5-12B transformer-based dense LLMs trained from scratch all the way up to 18 Trillion tokens seen show that our method: bends scaling curves resulting in up to 2.8x more compute efficiency generally; and reaches performance levels unachievable for models trained otherwise in domains such as math and code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Introspective X Training (IXT), a method inspired by offline reward-conditioned reinforcement learning. A thinking reward model generates natural-language critique feedback that is prefixed to training data, enabling quality-aware conditioning from the earliest pipeline stages rather than only post-training. Experiments train 7.5-12B dense transformers from scratch to 18 trillion tokens and report that IXT bends scaling curves, yielding up to 2.8x compute efficiency gains and performance levels in math and code that are otherwise unreachable.
Significance. If the cross-stage transfer results hold under rigorous controls, the work would offer a practical route to amortize post-training signals backward into pre-training, potentially lowering the compute required to reach target capabilities. The scale of the reported experiments (models trained entirely from scratch to 18 T tokens) is a notable strength that would distinguish the contribution from smaller-scale ablations common in the literature.
major comments (1)
- [Experimental Setup / Results] The central efficiency claim rests on the premise that critiques produced by a reward model trained on later-stage data remain useful and non-misleading when prefixed to tokens drawn from much earlier training distributions. No ablation isolating this cross-stage transfer (e.g., reward-model feedback applied only to matched later-stage data versus early-checkpoint data) is described; without it the observed scaling-curve improvements could be driven by distribution-matched subsets rather than genuine early-stage conditioning.
minor comments (2)
- [Abstract] The abstract states 'up to 2.8x more compute efficiency generally' without specifying the exact baseline (standard next-token prediction, a particular curriculum, or a matched compute budget) or the efficiency metric (tokens to reach a benchmark threshold, FLOPs per accuracy point, etc.).
- [Methods] Clarify whether the thinking reward model is frozen throughout all stages or periodically updated, and report the token volume on which it was itself trained.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting the importance of rigorously validating the cross-stage transfer aspect of our method. We address the major comment below.
read point-by-point responses
-
Referee: [Experimental Setup / Results] The central efficiency claim rests on the premise that critiques produced by a reward model trained on later-stage data remain useful and non-misleading when prefixed to tokens drawn from much earlier training distributions. No ablation isolating this cross-stage transfer (e.g., reward-model feedback applied only to matched later-stage data versus early-checkpoint data) is described; without it the observed scaling-curve improvements could be driven by distribution-matched subsets rather than genuine early-stage conditioning.
Authors: We agree that an explicit ablation isolating the benefit of late-stage feedback on early distributions would provide stronger evidence for genuine cross-stage transfer. Our experiments train models from scratch on the full pre-training corpus up to 18T tokens while using a fixed reward model trained on later-stage data to annotate all tokens; the observed improvements in scaling behavior and downstream math/code performance therefore already reflect the application of late-stage critiques to early data. Nevertheless, to directly rule out the possibility that gains arise only from distribution-matched subsets, we will add a targeted ablation in the revised manuscript that compares (i) feedback from a late-stage reward model applied to early-checkpoint data versus (ii) feedback from an early-stage reward model applied to the same early data, while keeping all other training details identical. revision: yes
Circularity Check
No significant circularity in empirical scaling claims
full rationale
The paper introduces Introspective Training (IXT) as a method that employs an external thinking reward model to generate natural-language critique feedback, which is then prefixed to training data for conditioning across pre-training and later stages. The central claims of improved compute efficiency (up to 2.8x) and superior performance in math and code are presented as outcomes of large-scale empirical experiments training 7.5-12B dense transformers from scratch to 18T tokens, with direct comparisons to baselines. No equations, derivations, or fitted parameters are shown that reduce the reported gains to the method's own inputs by construction. The approach relies on experimental validation rather than self-referential definitions or load-bearing self-citations, rendering the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
IXT uses a thinking reward model to annotate data with natural language critique based feedback, enabling quality aware training... Models are then trained by prefix-conditioning the data with the generated feedback
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
bends scaling curves resulting in up to 2.8x more compute efficiency
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
URLhttps://arxiv.org/abs/1803.05457. 14 Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard H. Hovy. RACE: large-scale reading comprehension dataset from examinations.CoRR, abs/1704.04683, 2017. URL http: //arxiv.org/abs/1704.04683. MAA. American invitational mathematics examination - aime. InAmerican Invitational Mathematics Examination - AIME 20...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
Instruction-Following Evaluation for Large Language Models
URLhttps://maa.org/student-programs/amc/. Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911, 2023. doi: 10.48550/arXiv.2311.07911. Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2311.07911 2023
-
[3]
URLhttps://arxiv.org/abs/2305.13245. David R. So, Wojciech Ma´nke, Hanxiao Liu, Zihang Dai, Noam Shazeer, and Quoc V . Le. Primer: Searching for efficient transformers for language modeling, 2022. URL https://arxiv.org/ abs/2109.08668. Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trun...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
OpenThoughts: Data Recipes for Reasoning Models
URLhttps://arxiv.org/abs/2506.04178. Leo Gao, Jonathan Tow, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Kyle McDonell, and Niklas Muennighoff. A framework for few-shot language model evaluation, 2021. Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by chatgpt really corr...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Given If I live in Los Angeles, then I live in California. True
-
[6]
Contrapositive If I do not live in California, then I do not live in Los Angeles. True
-
[7]
Converse If I live in California, then I live in Los Angeles. False
-
[8]
False Key Concepts: •Contrapositiveis logically equivalent to the original statement
Inverse If I do not live in Los Angeles, then I do not live in California. False Key Concepts: •Contrapositiveis logically equivalent to the original statement. • ConverseandInverseare not logically equivalent to the original and must be evaluated separately. • Truth values depend on real-world context, such as geographic relationships. Critique: 21 Crite...
work page 2025
-
[9]
Check for calculation errors, off-by-one mistakes, wrong formulas, or conclusions that don’t follow
Correctness:Is the final answer correct? Verify the answer — do not assume it is correct just because the reasoning looks plausible. Check for calculation errors, off-by-one mistakes, wrong formulas, or conclusions that don’t follow. An incorrect answer makes the example actively harmful for training
-
[10]
Reasoning quality:Is the reasoning logically sound, well-structured, and free of hallucinated facts or theorems? Does each step follow from the previous one? Does the trace demonstrate good problem-solving habits that a student model should learn? Self-correction is a positive signal; circular reasoning and repeated failed approaches are negative
-
[11]
Efficiency:Is the reasoning proportionate to the problem’s complexity? A concise, direct solution is better than a verbose, meandering one. If the trace is 5x longer than what an expert would write, that is a significant negative even if the answer is correct. Over-explanation of trivial steps and restating the problem multiple times are signs of poor efficiency
-
[12]
Problem difficulty:Correct solutions to harder problems are more valuable for training than correct solutions to easy problems. A competition-level math problem solved well is worth more than a basic arithmetic problem solved well. Example A <example_a> {sample_a} </example_a> Example B <example_b> {sample_b} </example_b> INSTRUCTIONS:You MUST think exten...
-
[13]
What is the problem asking? How difficult is it?
-
[14]
Is the final answer correct? Verify it
-
[15]
Is the reasoning logically sound? Are there errors, hallucinations, or gaps?
-
[16]
Is the reasoning efficient? How does the trace length compare to what an expert would write?
-
[17]
Overall, how valuable is this example for training? After analyzing BOTH examples in detail, compare them and make your decision. Your thinking should be thorough — at least several paragraphs of analysis. Do not rush to a conclusion. After your thinking, respond with this JSON: {"winner": "A" or "B" or "tie", "reasoning": "1-2 sentence summary of why"} F...
work page 2024
-
[18]
dataset to those longer than 4k, randomly select 2.2 million samples, and pack the sequences to the maximum sequence length yielding 611,243 samples. B.2 Evaluation Details Pretraining evaluation details.Using LM Evaluation Harness Gao et al. [2021], we conduct a wide range of evaluations covering: • Math. We evaluate the mathematical reasoning ability of...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.