Codec-Robust Attacks on Audio LLMs
Pith reviewed 2026-05-25 05:43 UTC · model grok-4.3
The pith
Optimizing perturbations inside a neural audio codec's latent space makes attacks on Audio LLMs survive compression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CodecAttack optimizes a perturbation in a neural audio codec's continuous latent space rather than directly perturbing the audio waveform. The codec's compression channel, which discards waveform perturbations, transmits perturbations crafted in its own latent space. Across three realistic Audio LLM deployment scenarios and three target models, CodecAttack achieves an average 85.5% target-substring attack success rate on Opus at moderate bitrates, while the waveform baseline trained with identical EoT hardening does not exceed 26% at any bitrate. The attack transfers to held-out codecs, reaching up to 100% ASR on MP3 and 84% on AAC-LC without retraining.
What carries the argument
Optimization of the perturbation inside the continuous latent space of a neural audio codec, hardened by multi-bitrate straight-through Expectation-over-Transformation.
If this is right
- Lossy compression preprocessing does not reliably defend Audio LLMs against targeted adversarial attacks.
- Latent-space attacks achieve substantially higher success rates than waveform attacks under identical hardening conditions.
- Attacks optimized on one codec transfer to different codecs such as MP3 and AAC-LC without retraining.
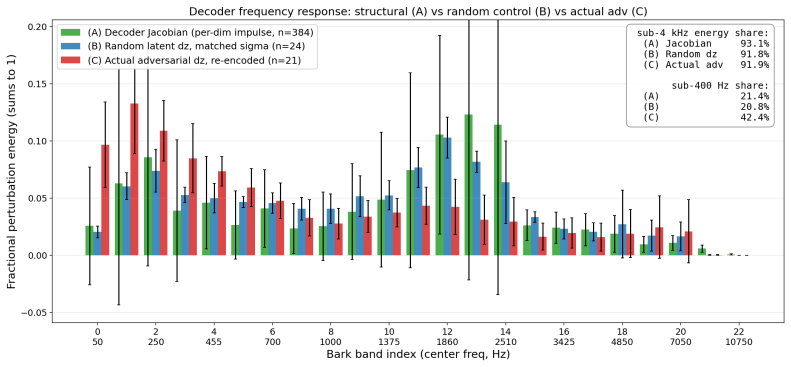
- Effective perturbations concentrate energy below 4 kHz, matching the frequency band where codecs allocate the most bits.
Where Pith is reading between the lines
- Future defenses for Audio LLMs may need to detect or mitigate perturbations directly in codec latent spaces rather than after decoding.
- The low-frequency concentration of successful perturbations suggests frequency-selective filtering could be tested as a lightweight countermeasure.
- The approach may generalize to other compressed input pipelines where preprocessing is relied upon for robustness.
Load-bearing premise
Perturbations optimized in the neural audio codec's continuous latent space survive the codec's compression and decoding steps and still produce the targeted output in the downstream Audio LLM.
What would settle it
An experiment showing that the same multi-bitrate EoT waveform perturbation reaches above 50% ASR on Opus at moderate bitrates, or that CodecAttack drops below 30% ASR after compression, would falsify the advantage of latent-space optimization.
Figures








read the original abstract
Prior attacks on Audio Large Language Models (Audio LLMs) demonstrated that carefully crafted waveform-domain perturbations can force targeted adversarial outputs. As a defense mechanism against these attacks, real-world codec compression preprocessing has been studied to both detect and remove the perturbations. Yet no existing attack has demonstrated robustness against these compressions. We introduce CodecAttack, which optimizes a perturbation in a neural audio codec's continuous latent space rather than directly perturbing the audio waveform. We show that the codec's compression channel, which discards waveform perturbations, transmits perturbations crafted in its own latent space. To further harden the attack across real-world compression channels, we apply multi-bitrate straight-through Expectation-over-Transformation (EoT), all without modifying the target model. Across three realistic Audio LLM deployment scenarios and three target models, CodecAttack achieves an average 85.5% target-substring attack success rate (ASR) on Opus at moderate bitrates, while the waveform baseline trained with identical EoT hardening does not exceed 26% at any bitrate. The attack transfers to held-out codecs, reaching up to 100% ASR on MP3 and 84% on AAC-LC without retraining. A per-band energy analysis shows that the latent perturbation concentrates below 4kHz, exactly where codecs allocate the most bits, while the waveform baseline spreads into higher frequencies that codecs discard. These results demonstrate that lossy compression is not a reliable defense against adversarial audio and that codec-aware attacks pose a practical threat to deployed Audio LLM systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CodecAttack, which generates targeted adversarial perturbations for Audio LLMs by optimizing directly in the continuous latent space of a neural audio codec (rather than the waveform) and applies multi-bitrate straight-through EoT hardening. Across three target models and deployment scenarios, it reports an average 85.5% target-substring ASR on Opus at moderate bitrates (versus ≤26% for an identically hardened waveform baseline), with transfer to held-out codecs reaching 100% on MP3 and 84% on AAC-LC. A per-band energy analysis shows latent perturbations concentrate below 4 kHz (where codecs allocate bits) while the waveform baseline spreads energy higher.
Significance. If the results hold after experimental clarification, the work would show that lossy codec preprocessing is not a reliable defense and that codec-aware attacks constitute a practical threat to deployed Audio LLMs. Credit is due for the quantitative multi-model/multi-codec evaluation, the transfer results on held-out codecs, and the explicit EoT hardening applied to both attack and baseline. The frequency analysis is a useful diagnostic, but the interpretation of the performance gap requires additional controls to isolate the contribution of latent-space optimization from frequency content.
major comments (1)
- [per-band energy analysis and waveform baseline comparison (results section)] The central claim attributes the 85.5% vs. 26% ASR gap to optimization in the codec's latent space (which survives the compression channel). However, the per-band energy analysis shows that latent perturbations concentrate below 4 kHz while the waveform baseline does not. The manuscript applies identical multi-bitrate EoT to both but does not report a waveform control that explicitly constrains or penalizes high-frequency energy. If such a control closes most of the gap, the claim that 'optimizing in the codec's latent space' (as opposed to discovering a compression-surviving frequency band) is what transmits the attack would require qualification. This is load-bearing for the interpretation of the results.
minor comments (2)
- [Abstract] The abstract states results 'across three realistic Audio LLM deployment scenarios' but does not enumerate them; a brief parenthetical or footnote would improve readability.
- [Method / Experiments] Optimization hyperparameters (learning rate, number of EoT samples, latent-space projection details) are referenced but their exact values and sensitivity analysis would benefit from a dedicated table or appendix for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the single major comment below and agree that additional controls are required to support the interpretation of the results.
read point-by-point responses
-
Referee: The central claim attributes the 85.5% vs. 26% ASR gap to optimization in the codec's latent space (which survives the compression channel). However, the per-band energy analysis shows that latent perturbations concentrate below 4 kHz while the waveform baseline does not. The manuscript applies identical multi-bitrate EoT to both but does not report a waveform control that explicitly constrains or penalizes high-frequency energy. If such a control closes most of the gap, the claim that 'optimizing in the codec's latent space' (as opposed to discovering a compression-surviving frequency band) is what transmits the attack would require qualification. This is load-bearing for the interpretation of the results.
Authors: We agree that the per-band energy analysis raises a substantive question about the source of the observed gap and that the manuscript lacks an explicit waveform control with high-frequency energy constraints. Such a control would help isolate whether the advantage arises from latent-space optimization per se or from the resulting low-frequency concentration. In the revised manuscript we will add this control (a waveform attack optimized under an additional high-frequency energy penalty or low-pass constraint while retaining the same multi-bitrate EoT) and report the resulting ASR. We will update the results section and discussion to qualify the central claim if the new control closes most of the gap, or to retain the original interpretation with the supporting evidence if the gap persists. revision: yes
Circularity Check
No circularity: empirical ASR measurements on held-out codecs
full rationale
The paper reports measured attack success rates from optimization experiments and transfer tests on Opus, MP3, and AAC-LC at various bitrates. No derivation chain, equation, or first-principles claim reduces a reported quantity (e.g., the 85.5% ASR) to a fitted parameter or self-citation by construction. The central comparison is between two separately optimized attacks (latent vs. waveform) evaluated on external data; the per-band energy observation is a post-hoc measurement, not a definitional step. This is a standard empirical security evaluation with no load-bearing self-referential structure.
Axiom & Free-Parameter Ledger
free parameters (1)
- attack optimization hyperparameters
axioms (1)
- domain assumption Perturbations in the codec latent space are transmitted through the compression channel and affect the decoded waveform in a way that fools the target Audio LLM.
Reference graph
Works this paper leans on
-
[1]
Realtime API: Speech-to-speech multimodal interactions
OpenAI. Realtime API: Speech-to-speech multimodal interactions. https://platform. openai.com/docs/guides/realtime, 2024
work page 2024
-
[2]
Build real-time conversational agents with Gemini 3.1 Flash Live
Google. Build real-time conversational agents with Gemini 3.1 Flash Live. https://blog.google/innovation-and-ai/technology/developers-tools/ build-with-gemini-3-1-flash-live/, 2026
work page 2026
-
[3]
Gemini Enterprise for Customer Experience
Google Cloud. Gemini Enterprise for Customer Experience. https://cloud.google.com/ products/gemini-enterprise-for-customer-experience, 2026
work page 2026
-
[4]
How generative ai voice agents will transform medicine.npj Digital Medicine, 8(1):353, 2025
Scott J Adams, Julián N Acosta, and Pranav Rajpurkar. How generative ai voice agents will transform medicine.npj Digital Medicine, 8(1):353, 2025
work page 2025
-
[5]
Brown presses banks on voice authentication ser- vices, 2023
Senate Banking Committee. Brown presses banks on voice authentication ser- vices, 2023. URL https://www.banking.senate.gov/newsroom/majority/ brown-presses-banks-voice-authentication-services . U.S. Senate press re- lease
work page 2023
-
[6]
Benchmarking audio deepfake detection robustness in real-world communication scenarios
Haohan Shi, Xiyu Shi, Safak Dogan, Saif Alzubi, Tianjin Huang, and Yunxiao Zhang. Benchmarking audio deepfake detection robustness in real-world communication scenarios. In2025 33rd European Signal Processing Conference (EUSIPCO), page 566–570. IEEE,
-
[7]
URL http://dx.doi.org/10.23919/ EUSIPCO63237.2025.11226601
doi: 10.23919/eusipco63237.2025.11226601. URL http://dx.doi.org/10.23919/ EUSIPCO63237.2025.11226601
-
[8]
High-Quality, Low-Delay Music Coding in the Opus Codec
Jean-Marc Valin, Gregory Maxwell, Timothy B. Terriberry, and Koen V os. High-quality, low- delay music coding in the opus codec, 2016. URLhttps://arxiv.org/abs/1602.04845
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[9]
Webrtc audio codec and processing requirements
Jean-Marc Valin and Cary Bran. Webrtc audio codec and processing requirements. Technical report, 2016. URLhttps://datatracker.ietf.org/doc/html/rfc7874
work page 2016
-
[10]
YouTube. How Content ID works, 2024. URL https://support.google.com/youtube/ answer/2797370
-
[11]
Iustina Andronic, Ludwig Kürzinger, Edgar Ricardo Chavez Rosas, Gerhard Rigoll, and Bern- hard U. Seeber. Mp3 compression to diminish adversarial noise in end-to-end speech recognition,
- [12]
-
[13]
Waveguard: Understanding and mitigating audio adversarial examples, 2021
Shehzeen Hussain, Paarth Neekhara, Shlomo Dubnov, Julian McAuley, and Farinaz Koushanfar. Waveguard: Understanding and mitigating audio adversarial examples, 2021. URL https: //arxiv.org/abs/2103.03344
-
[14]
Attacker’s noise can manipulate your audio-based llm in the real world, 2025
Vinu Sankar Sadasivan, Soheil Feizi, Rajiv Mathews, and Lun Wang. Attacker’s noise can manipulate your audio-based llm in the real world, 2025. URL https://arxiv.org/abs/ 2507.06256
-
[15]
Roee Ziv, Raz Lapid, and Moshe Sipper. Breaking audio large language models by attacking only the encoder: A universal targeted latent-space audio attack, 2025. URL https://arxiv. org/abs/2512.23881
-
[16]
High Fidelity Neural Audio Compression
Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. High fidelity neural audio compression, 2022. URLhttps://arxiv.org/abs/2210.13438
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Synthesizing Robust Adversarial Examples
Anish Athalye, Logan Engstrom, Andrew Ilyas, and Kevin Kwok. Synthesizing robust adver- sarial examples, 2018. URLhttps://arxiv.org/abs/1707.07397
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models, 2023. URL https: //arxiv.org/abs/2307.15043. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal, 2024. URL https://arxiv.org/abs/2402.04249
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
HireVue. Ai in hiring, 2025. URLhttps://www.hirevue.com/ai-in-hiring
work page 2025
-
[21]
Spotify strengthens AI protections for artists, songwriters, and producers, 2025
Spotify. Spotify strengthens AI protections for artists, songwriters, and producers, 2025. URL https://newsroom.spotify.com/2025-09-25/ spotify-strengthens-ai-protections/
work page 2025
-
[22]
Moshi: a speech-text foundation model for real-time dialogue
Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Zeghidour. Moshi: a speech-text foundation model for real-time dialogue, 2024. URLhttps://arxiv.org/abs/2410.00037
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
High-fidelity audio compression with improved rvqgan, 2023
Rithesh Kumar, Prem Seetharaman, Alejandro Luebs, Ishaan Kumar, and Kundan Kumar. High-fidelity audio compression with improved rvqgan, 2023. URL https://arxiv.org/ abs/2306.06546
-
[24]
Nicholas Carlini, Pratyush Mishra, Tavish Vaidya, Yuankai Zhang, Micah Sherr, Clay Shields, David Wagner, and Wenchao Zhou. Hidden voice commands. In25th USENIX Security Symposium (USENIX Security 16), pages 513–530, 2016
work page 2016
-
[25]
Audio Adversarial Examples: Targeted Attacks on Speech-to-Text
Nicholas Carlini and David Wagner. Audio adversarial examples: Targeted attacks on speech- to-text, 2018. URLhttps://arxiv.org/abs/1801.01944
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[26]
Xuejing Yuan, Yuxuan Chen, Yue Zhao, Yunhui Long, Xiaokang Liu, Kai Chen, Shengzhi Zhang, Heqing Huang, Xiaofeng Wang, and Carl A. Gunter. Commandersong: A systematic approach for practical adversarial voice recognition, 2018. URL https://arxiv.org/abs/ 1801.08535
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[27]
Robust audio adversarial example for a physical attack
Hiromu Yakura and Jun Sakuma. Robust audio adversarial example for a physical attack. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-2019, page 5334–5341. International Joint Conferences on Artificial Intelligence Organi- zation, August 2019. doi: 10.24963/ijcai.2019/741. URL http://dx.doi.org/10.24963...
-
[28]
Imperceptible, Robust, and Targeted Adversarial Examples for Automatic Speech Recognition
Yao Qin, Nicholas Carlini, Ian Goodfellow, Garrison Cottrell, and Colin Raffel. Imperceptible, robust, and targeted adversarial examples for automatic speech recognition, 2019. URL https: //arxiv.org/abs/1903.10346
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[29]
Imperio: Robust over-the-air adversarial examples for automatic speech recognition systems,
Lea Schönherr, Thorsten Eisenhofer, Steffen Zeiler, Thorsten Holz, and Dorothea Kolossa. Imperio: Robust over-the-air adversarial examples for automatic speech recognition systems,
- [30]
-
[31]
{SMACK}: Semantically meaningful adversarial audio attack
Zhiyuan Yu, Yuanhaur Chang, Ning Zhang, and Chaowei Xiao. {SMACK}: Semantically meaningful adversarial audio attack. In32nd USENIX security symposium (USENIX security 23), pages 3799–3816, 2023
work page 2023
-
[32]
Speechguard: Exploring the adversarial robustness of multimodal large language models, 2024
Raghuveer Peri, Sai Muralidhar Jayanthi, Srikanth Ronanki, Anshu Bhatia, Karel Mundnich, Saket Dingliwal, Nilaksh Das, Zejiang Hou, Goeric Huybrechts, Srikanth Vishnubhotla, Daniel Garcia-Romero, Sundararajan Srinivasan, Kyu J Han, and Katrin Kirchhoff. Speechguard: Exploring the adversarial robustness of multimodal large language models, 2024. URL https:...
-
[33]
Audiojailbreak: Jailbreak attacks against end-to-end large audio-language models, 2026
Guangke Chen, Fu Song, Zhe Zhao, Xiaojun Jia, Yang Liu, Yanchen Qiao, Weizhe Zhang, Weiping Tu, Yuhong Yang, and Bo Du. Audiojailbreak: Jailbreak attacks against end-to-end large audio-language models, 2026. URLhttps://arxiv.org/abs/2505.14103
-
[34]
When good sounds go adversarial: Jailbreaking audio-language models with benign inputs, 2026
Hiskias Dingeto, Taeyoun Kwon, Dasol Choi, Bodam Kim, DongGeon Lee, Haon Park, JaeHoon Lee, and Jongho Shin. When good sounds go adversarial: Jailbreaking audio-language models with benign inputs, 2026. URLhttps://arxiv.org/abs/2508.03365. 11
-
[35]
Cocaine noodles: exploiting the gap between human and machine speech recognition
Tavish Vaidya, Yuankai Zhang, Micah Sherr, and Clay Shields. Cocaine noodles: exploiting the gap between human and machine speech recognition. In9th USENIX Workshop on Offensive Technologies (WOOT 15), 2015
work page 2015
-
[36]
Dol- phinattack: Inaudible voice commands
Guoming Zhang, Chen Yan, Xiaoyu Ji, Tianchen Zhang, Taimin Zhang, and Wenyuan Xu. Dol- phinattack: Inaudible voice commands. InProceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, CCS ’17, page 103–117. ACM, October 2017. doi: 10.1145/3133956.3134052. URLhttp://dx.doi.org/10.1145/3133956.3134052
-
[37]
Adversarial Attacks Against Automatic Speech Recognition Systems via Psychoacoustic Hiding
Lea Schönherr, Katharina Kohls, Steffen Zeiler, Thorsten Holz, and Dorothea Kolossa. Adver- sarial attacks against automatic speech recognition systems via psychoacoustic hiding, 2018. URLhttps://arxiv.org/abs/1808.05665
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[38]
Yuxuan Chen, Xuejing Yuan, Jiangshan Zhang, Yue Zhao, Shengzhi Zhang, Kai Chen, and XiaoFeng Wang. {Devil’s} whisper: A general approach for physical adversarial attacks against commercial black-box speech recognition devices. In29th USENIX security symposium (USENIX Security 20), pages 2667–2684, 2020
work page 2020
-
[39]
V oice jailbreak attacks against gpt-4o, 2024
Xinyue Shen, Yixin Wu, Michael Backes, and Yang Zhang. V oice jailbreak attacks against gpt-4o, 2024. URLhttps://arxiv.org/abs/2405.19103
-
[40]
Advwave: Stealthy adversarial jailbreak attack against large audio-language models, 2024
Mintong Kang, Chejian Xu, and Bo Li. Advwave: Stealthy adversarial jailbreak attack against large audio-language models, 2024. URLhttps://arxiv.org/abs/2412.08608
-
[41]
Muting whisper: A universal acoustic adversarial attack on speech foundation models, 2024
Vyas Raina, Rao Ma, Charles McGhee, Kate Knill, and Mark Gales. Muting whisper: A universal acoustic adversarial attack on speech foundation models, 2024. URL https:// arxiv.org/abs/2405.06134
-
[42]
Conversational AI in banking: Benefits, examples & trends, 2025
Retell AI. Conversational AI in banking: Benefits, examples & trends, 2025. URL https: //www.retellai.com/blog/conversational-ai-in-banking
work page 2025
-
[43]
How voice-first AI is redefining global banking cus- tomer support in 2025, 2025
Fluid AI. How voice-first AI is redefining global banking cus- tomer support in 2025, 2025. URL https://www.fluid.ai/blog/ voice-first-ai-is-redefining-banking-customer-support
work page 2025
-
[44]
Ai voice interview: Use cases, benefits & 2026 guide, 2025
HeyMilo. Ai voice interview: Use cases, benefits & 2026 guide, 2025. URL https://www.heymilo.ai/blog/ ai-voice-interview-the-impact-of-ai-interviewer-technology-on-hiring-efficiency
work page 2026
-
[45]
How voice AI is transforming recruitment in 2025, 2025
Apollo Technical. How voice AI is transforming recruitment in 2025, 2025. URL https: //www.apollotechnical.com/how-voice-ai-is-transforming-recruitment/
work page 2025
-
[46]
Towards Deep Learning Models Resistant to Adversarial Attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks, 2019. URL https://arxiv. org/abs/1706.06083
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[47]
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen2-audio technical report,
-
[48]
URLhttps://arxiv.org/abs/2407.10759
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Audio flamingo 3: Advancing audio intelligence with fully open large audio language models,
Arushi Goel, Sreyan Ghosh, Jaehyeon Kim, Sonal Kumar, Zhifeng Kong, Sang gil Lee, Chao- Han Huck Yang, Ramani Duraiswami, Dinesh Manocha, Rafael Valle, and Bryan Catanzaro. Audio flamingo 3: Advancing audio intelligence with fully open large audio language models,
-
[50]
URLhttps://arxiv.org/abs/2507.08128
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. Qwen2.5-omni technical report, 2025. URLhttps://arxiv.org/abs/2503.20215
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Efficient adversarial training in llms with continuous attacks, 2024
Sophie Xhonneux, Alessandro Sordoni, Stephan Günnemann, Gauthier Gidel, and Leo Schwinn. Efficient adversarial training in llms with continuous attacks, 2024. URL https://arxiv. org/abs/2405.15589. 12
-
[53]
Neural codec- based adversarial sample detection for speaker verification, 2024
Xuanjun Chen, Jiawei Du, Haibin Wu, Jyh-Shing Roger Jang, and Hung yi Lee. Neural codec- based adversarial sample detection for speaker verification, 2024. URL https://arxiv.org/ abs/2406.04582
-
[54]
Sequential randomized smoothing for adversarially robust speech recognition
Raphael Olivier and Bhiksha Raj. Sequential randomized smoothing for adversarially robust speech recognition. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, page 6372–6386. Association for Computational Linguistics, 2021. doi: 10.18653/v1/2021.emnlp-main.514. URL http://dx.doi.org/10.18653/v1/2021. emnlp-main.514
-
[55]
Soundstream: An end-to-end neural audio codec, 2021
Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund, and Marco Tagliasacchi. Soundstream: An end-to-end neural audio codec, 2021. URL https://arxiv.org/abs/ 2107.03312
-
[56]
Speechtokenizer: Unified speech tokenizer for speech large language models, 2024
Xin Zhang, Dong Zhang, Shimin Li, Yaqian Zhou, and Xipeng Qiu. Speechtokenizer: Unified speech tokenizer for speech large language models, 2024. URL https://arxiv.org/abs/ 2308.16692
-
[57]
Zhihao Du, Shiliang Zhang, Kai Hu, and Siqi Zheng. Funcodec: A fundamental, reproducible and integrable open-source toolkit for neural speech codec, 2023. URL https://arxiv.org/ abs/2309.07405
-
[58]
Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling, 2025
Shengpeng Ji, Ziyue Jiang, Wen Wang, Yifu Chen, Minghui Fang, Jialong Zuo, Qian Yang, Xize Cheng, Zehan Wang, Ruiqi Li, Ziang Zhang, Xiaoda Yang, Rongjie Huang, Yidi Jiang, Qian Chen, Siqi Zheng, and Zhou Zhao. Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling, 2025. URL https://arxiv.org/abs/2408.16532
-
[59]
Robust Speech Recognition via Large-Scale Weak Supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision, 2022. URL https: //arxiv.org/abs/2212.04356
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[60]
Pengi: An audio language model for audio tasks, 2024
Soham Deshmukh, Benjamin Elizalde, Rita Singh, and Huaming Wang. Pengi: An audio language model for audio tasks, 2024. URLhttps://arxiv.org/abs/2305.11834
-
[61]
Liu, Leonid Karlinsky, and James Glass
Yuan Gong, Hongyin Luo, Alexander H. Liu, Leonid Karlinsky, and James Glass. Listen, think, and understand, 2024. URLhttps://arxiv.org/abs/2305.10790
-
[62]
SALMONN: Towards Generic Hearing Abilities for Large Language Models
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, and Chao Zhang. Salmonn: Towards generic hearing abilities for large language models, 2024. URLhttps://arxiv.org/abs/2310.13289
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shiliang Zhang, Zhijie Yan, Chang Zhou, and Jingren Zhou. Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models, 2023. URLhttps://arxiv.org/abs/2311.07919
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[64]
Audiolm: a language modeling approach to audio generation, 2023
Zalán Borsos, Raphaël Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matt Sharifi, Dominik Roblek, Olivier Teboul, David Grangier, Marco Tagliasacchi, and Neil Zeghidour. Audiolm: a language modeling approach to audio generation, 2023. URL https://arxiv.org/abs/2209.03143
-
[65]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, Lei He, Sheng Zhao, and Furu Wei. Neural codec language models are zero-shot text to speech synthesizers, 2023. URL https://arxiv.org/ abs/2301.02111
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[66]
Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre Défossez. Simple and controllable music generation, 2024. URL https: //arxiv.org/abs/2306.05284. 13 Appendix A Details on Cross-Codec Generalization Table 4:Cross-codec generalization. CodecAttack re-instantiated on Mimi [20] and DAC [21] (S3b, Qwen2.5-Omn...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.