Finding Missing Input Validation in TEEs via LLM-Assisted Symbolic Execution
Pith reviewed 2026-05-22 04:53 UTC · model grok-4.3
The pith
SymTEE uses LLMs to generate mock environments that let symbolic execution find missing input validations in TEE code without any real hardware setup.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
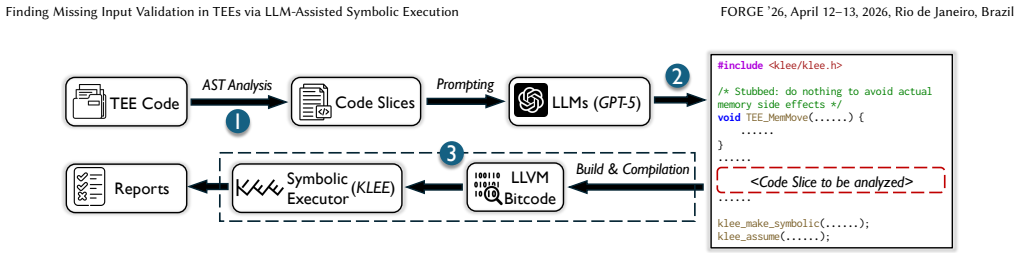
SymTEE extracts TEE code slices that may lack sufficient input validation via AST analysis, then employs an LLM to automatically convert those slices into KLEE-compatible harness programs that include lightweight mock execution environments, allowing symbolic execution to expose the vulnerabilities. On a set of 26 vulnerabilities consisting of 11 real-world and 15 synthetic cases, the framework reaches 100 percent precision and 92.3 percent recall while averaging only $0.05 in analysis cost per case.
What carries the argument
LLM-generated KLEE harness programs that embed lightweight mock execution environments, which enable symbolic analysis of extracted TEE code slices without requiring actual TEE hardware or full runtime configurations.
If this is right
- 100 percent precision implies reported issues require no manual filtering for false alarms.
- 92.3 percent recall means the large majority of existing missing-validation problems are caught.
- An average cost of $0.05 makes repeated or large-scale scans economically practical.
- The same workflow applies equally to both real-world and synthetic vulnerability examples.
- The method supplies a scalable alternative for security analysis of trusted computing systems.
Where Pith is reading between the lines
- Similar LLM-driven mock generation could be tried for other classes of bugs inside hardware-isolated environments.
- Continued LLM capability gains might push recall to 100 percent on the same task.
- Embedding the pipeline inside continuous-integration tools could let TEE developers run checks automatically.
- The lowered setup barrier may let smaller teams perform security reviews that previously required specialized hardware access.
Load-bearing premise
The large language model can reliably translate extracted TEE code slices into correct KLEE-compatible harness programs whose mock environments are faithful enough for symbolic analysis to reveal missing input validations.
What would settle it
Apply SymTEE to a new collection of TEE applications containing documented missing-input-validation bugs and check whether the generated harnesses consistently expose those bugs through symbolic execution or instead miss them or produce false paths.
Figures



read the original abstract
Trusted Execution Environments (TEEs) provide hardware-enforced isolation that protects sensitive code and data from untrusted software. Despite their strong security guarantees, analyzing TEE applications remains challenging due to the high cost and complexity of configuring complete TEE build and runtime environments, as well as the limited observability imposed by hardware isolation. This paper presents SymTEE, a novel large language model (LLM)-assisted symbolic execution framework for detecting missing input validation issues in TEE applications without requiring real TEE setups. SymTEE begins by leveraging Abstract Syntax Tree (AST) analysis to extract TEE code slices that may lack sufficient input validation, and then employs an LLM (GPT-5 in our case) to automatically convert the extracted slices into KLEE-compatible harness programs containing lightweight mock execution environments for symbolic analysis. Evaluations on 26 vulnerabilities (11 real-world and 15 synthetic) show that SymTEE achieves 100% precision and 92.3% recall in detecting missing input validation vulnerabilities while incurring an average analysis cost of only $0.05. These results demonstrate the effectiveness and practicality of SymTEE's pioneering paradigm of LLM-assisted symbolic execution, where LLMs autonomously generate mock environments to enable automated security analysis without complex setup, providing a more accessible and scalable framework for trusted computing systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SymTEE, a framework that uses AST analysis to extract code slices from TEE applications potentially lacking input validation, then employs an LLM (GPT-5) to automatically generate KLEE-compatible harness programs with lightweight mock execution environments. Symbolic execution via KLEE is then applied to detect missing input validations without requiring actual TEE hardware or full runtime setups. The evaluation on 26 cases (11 real-world vulnerabilities and 15 synthetic) reports 100% precision and 92.3% recall at an average cost of $0.05 per analysis, positioning the work as a scalable, low-setup paradigm for TEE security analysis.
Significance. If the LLM-generated mocks preserve sufficient TEE semantics for KLEE to reach and expose validation bugs, the approach could meaningfully reduce the cost and complexity of analyzing isolated TEE code. The reported aggregate metrics and low per-analysis cost indicate practical potential for automated security tooling in trusted computing, particularly if future work strengthens the validation of the mock-generation step.
major comments (3)
- [Evaluation] Evaluation section: The central claim of 92.3% recall (and thus the overall effectiveness) depends on the LLM-generated lightweight mock environments faithfully reproducing the control- and data-flow conditions needed to expose missing input validations. The manuscript provides no per-case audit of the generated harnesses, no comparison against hand-written reference harnesses for the 11 real-world cases, and no explicit validation that TEE-specific elements (entry points, attestation flows, or isolation boundaries) are preserved rather than hallucinated or simplified away.
- [Evaluation] Evaluation section: Aggregate metrics are reported for the full set of 26 cases, but no breakdown is given separating performance on the 11 real-world vulnerabilities from the 15 synthetic ones. Without this disaggregation or a description of how the synthetic cases were constructed, it is difficult to determine whether the 100% precision / 92.3% recall results generalize beyond the evaluated set.
- [Method] Method section: The pipeline relies on the LLM to translate extracted slices into correct KLEE harnesses whose mock environments are adequate for symbolic detection. The manuscript does not report how often LLM outputs required manual repair, nor does it quantify the frequency or nature of semantic omissions that could suppress or fabricate the very conditions the analysis targets.
minor comments (2)
- [Abstract] Abstract and introduction: The phrase 'GPT-5' should be clarified (model version, access date, or whether it denotes a specific configuration) to allow reproducibility.
- [Evaluation] The paper would benefit from a short table or appendix listing the 11 real-world cases with their sources and the key TEE features each exercises.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of our evaluation and methodology. We address each major comment in detail below and indicate the changes we will make to the manuscript.
read point-by-point responses
-
Referee: [Evaluation] The central claim of 92.3% recall depends on the LLM-generated lightweight mock environments faithfully reproducing the control- and data-flow conditions needed to expose missing input validations. The manuscript provides no per-case audit of the generated harnesses, no comparison against hand-written reference harnesses for the 11 real-world cases, and no explicit validation that TEE-specific elements (entry points, attestation flows, or isolation boundaries) are preserved rather than hallucinated or simplified away.
Authors: We recognize the value of providing more transparency on the mock environment generation. Although the original manuscript focused on aggregate results, we did conduct per-case reviews during development to ensure that the mocks captured necessary TEE semantics such as entry points and basic isolation. To address this concern, we will include in the revised Evaluation section a summary of the validation process for the mocks, including examples of preserved elements for both real-world and synthetic cases. A full side-by-side comparison with hand-written harnesses is not feasible within the scope of this work as it would require duplicating the effort for each case manually; however, the absence of false positives (100% precision) provides indirect evidence that the mocks did not introduce spurious behaviors. We will also add explicit discussion on how attestation flows are mocked using symbolic return values. revision: partial
-
Referee: [Evaluation] Aggregate metrics are reported for the full set of 26 cases, but no breakdown is given separating performance on the 11 real-world vulnerabilities from the 15 synthetic ones. Without this disaggregation or a description of how the synthetic cases were constructed, it is difficult to determine whether the 100% precision / 92.3% recall results generalize beyond the evaluated set.
Authors: We agree that disaggregating the results would improve the reader's ability to assess generalizability. In the revised manuscript, we will present separate metrics for the 11 real-world vulnerabilities and the 15 synthetic cases. We will also add a description of how the synthetic cases were constructed. revision: yes
-
Referee: [Method] The pipeline relies on the LLM to translate extracted slices into correct KLEE harnesses whose mock environments are adequate for symbolic detection. The manuscript does not report how often LLM outputs required manual repair, nor does it quantify the frequency or nature of semantic omissions that could suppress or fabricate the very conditions the analysis targets.
Authors: This is a valid observation. We will update the Method section to report the rate at which LLM-generated harnesses required manual intervention. We will also discuss the steps taken to mitigate semantic omissions, such as post-generation checks against the original slices, and quantify any instances where omissions were detected and corrected. revision: yes
Circularity Check
No circularity: results derived from independent labeled test cases
full rationale
The paper describes an empirical tool SymTEE that extracts code slices via AST analysis and uses an LLM to synthesize KLEE harnesses with mock environments for symbolic execution. Precision and recall are measured directly against a fixed collection of 26 externally labeled vulnerabilities (11 real-world plus 15 synthetic), which function as independent ground truth rather than quantities constructed from the method's own definitions or fitted parameters. No equations, self-referential definitions, or load-bearing self-citations appear in the provided derivation; the central performance claims rest on observable outcomes that can be reproduced by re-running the tool on the same test suite. The framework is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-generated mock execution environments are sufficiently faithful to real TEE behavior for symbolic execution to expose missing input validations.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SymTEE begins by leveraging Abstract Syntax Tree (AST) analysis to extract TEE code slices... employs an LLM (GPT-5) to automatically convert the extracted slices into KLEE-compatible harness programs containing lightweight mock execution environments
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
KLEE explores execution paths driven by the symbolic inputs... searches for concrete values that violate the klee_assert oracle
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Waqas Ahmed, Aamir Rasool, Abdul Rehman Javed, Neeraj Kumar, Thippa Reddy Gadekallu, Zunera Jalil, and Natalia Kryvinska. 2021. Security in Next Generation Mobile Payment Systems: A Comprehensive Survey.IEEE Access9 (2021), 115932– 115950
work page 2021
-
[2]
Sunil Anasuri. 2023. Confidential Computing Using Trusted Execution Environ- ments.International Journal of AI, BigData, Computational and Management Stud- ies4, 2 (Jun. 2023), 97–110
work page 2023
-
[3]
Matthew Areno and Jim Plusquellic. 2012. Securing Trusted Execution Environ- ments with PUF Generated Secret Keys. In2012 IEEE 11th International Conference on Trust, Security and Privacy in Computing and Communications. 1188–1193
work page 2012
-
[4]
Roberto Baldoni, Emilio Coppa, Daniele Cono D’elia, Camil Demetrescu, and Irene Finocchi. 2018. A Survey of Symbolic Execution Techniques.ACM Comput. Surv.51, 3, Article 50 (May 2018), 39 pages
work page 2018
-
[5]
Fabrice Bellard. 2005. QEMU, a fast and portable dynamic translator. InProceed- ings of the Annual Conference on USENIX Annual Technical Conference(Anaheim, CA)(ATEC ’05). USENIX Association, USA, 41
work page 2005
-
[6]
Marcel Busch, Aravind Machiry, Chad Spensky, Giovanni Vigna, Christopher Kruegel, and Mathias Payer. 2023. TEEzz: Fuzzing Trusted Applications on COTS Android Devices. In2023 IEEE Symposium on Security and Privacy (SP). 1204–1219
work page 2023
-
[7]
Cristian Cadar, Daniel Dunbar, and Dawson Engler. 2008. KLEE: unassisted and automatic generation of high-coverage tests for complex systems programs. InProceedings of the 8th USENIX Conference on Operating Systems Design and Implementation(San Diego, California)(OSDI’08). USENIX Association, USA, 209–224
work page 2008
-
[8]
David Cerdeira, Nuno Santos, Pedro Fonseca, and Sandro Pinto. 2020. SoK: Understanding the Prevailing Security Vulnerabilities in TrustZone-assisted TEE Systems. In2020 IEEE Symposium on Security and Privacy (SP). 1416–1432
work page 2020
-
[9]
Liheng Chen, Zheming Li, Zheyu Ma, Yuan Li, Baojian Chen, and Chao Zhang
-
[10]
EnclaveFuzz: Finding Vulnerabilities in SGX Applications. In31st An- nual Network and Distributed System Security Symposium, NDSS 2024, San Diego, California, USA, February 26 - March 1, 2024. The Internet Society
work page 2024
-
[11]
Vitaly Chipounov, Volodymyr Kuznetsov, and George Candea. 2012. The S2E Platform: Design, Implementation, and Applications.ACM Trans. Comput. Syst. 30, 1, Article 2 (Feb. 2012), 49 pages
work page 2012
-
[12]
Intel Corporation. 2025. Intel®Software Guard Extensions (Intel® SGX). https://www.intel.com/content/www/us/en/products/docs/accelerator- engines/software-guard-extensions.html. [Accessed 05-11-2025]
work page 2025
-
[13]
Leonardo De Moura and Nikolaj Bjørner. 2011. Satisfiability modulo theories: introduction and applications.Commun. ACM54, 9 (Sept. 2011), 69–77
work page 2011
-
[14]
Amit Dua, Siddharth Sekhar Barpanda, Neeraj Kumar, and Sudeep Tanwar. 2020. Trustful: A Decentralized Public Key Infrastructure and Identity Management System. In2020 IEEE Globecom Workshops (GC Wkshps. 1–6
work page 2020
-
[15]
Guoyun Duan, Yuanzhi Fu, Boyang Zhang, Peiyao Deng, Jianhua Sun, Hao Chen, and Zhiwen Chen. 2023. TEEFuzzer: A fuzzing framework for trusted execution environments with heuristic seed mutation.Future Gener. Comput. Syst.144 (2023), 192–204
work page 2023
-
[16]
Zachary Englhardt, Richard Li, Dilini Nissanka, Zhihan Zhang, Girish Narayan- swamy, Joseph Breda, Xin Liu, Shwetak Patel, and Vikram Iyer. 2024. Exploring and Characterizing Large Language Models for Embedded System Development and Debugging. InExtended Abstracts of the CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI EA ’24). ...
work page 2024
-
[17]
Shufan Fei, Zheng Yan, Wenxiu Ding, and Haomeng Xie. 2021. Security Vulnera- bilities of SGX and Countermeasures: A Survey.ACM Comput. Surv.54, 6, Article 126 (July 2021), 36 pages
work page 2021
-
[18]
Fabian Fleischer, Marcel Busch, and Phillip Kuhrt. 2020. Memory corruption attacks within Android TEEs: a case study based on OP-TEE. InProceedings of the 15th International Conference on A vailability, Reliability and Security(Virtual Event, Ireland)(ARES ’20). Association for Computing Machinery, New York, NY, USA, Article 53, 9 pages
work page 2020
-
[19]
Akalanka Galappaththi, Sarah Nadi, and Christoph Treude. 2024. An Empiri- cal Study of API Misuses of Data-Centric Libraries. InProceedings of the 18th ACM/IEEE International Symposium on Empirical Software Engineering and Mea- surement(Barcelona, Spain)(ESEM ’24). Association for Computing Machinery, New York, NY, USA, 245–256
work page 2024
-
[20]
Lee Harrison, Hayawardh Vijayakumar, Rohan Padhye, Koushik Sen, and Michael Grace. 2020. PARTEMU: Enabling Dynamic Analysis of Real-World TrustZone Software Using Emulation. In29th USENIX Security Symposium (USENIX Security 20). USENIX Association, 789–806
work page 2020
-
[21]
Junda He, Christoph Treude, and David Lo. 2025. LLM-Based Multi-Agent Systems for Software Engineering: Literature Review, Vision, and the Road Ahead.ACM Trans. Softw. Eng. Methodol.34, 5, Article 124 (May 2025), 30 pages
work page 2025
-
[22]
Patrick Jauernig, Ahmad-Reza Sadeghi, and Emmanuel Stapf. 2020. Trusted Execution Environments: Properties, Applications, and Challenges.IEEE Security & Privacy18, 2 (2020), 56–60
work page 2020
-
[23]
Mustakimur Rahman Khandaker, Yueqiang Cheng, Zhi Wang, and Tao Wei. 2020. COIN Attacks: On Insecurity of Enclave Untrusted Interfaces in SGX. InPro- ceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems(Lausanne, Switzerland)(ASPLOS ’20). Association for Computing Machinery, New York...
work page 2020
-
[24]
Wenhao Li, Yubin Xia, Long Lu, Haibo Chen, and Binyu Zang. 2019. TEEv: virtualizing trusted execution environments on mobile platforms. InProceedings of the 15th ACM SIGPLAN/SIGOPS International Conference on Virtual Execu- tion Environments(Providence, RI, USA)(VEE 2019). Association for Computing Machinery, New York, NY, USA, 2–16
work page 2019
- [25]
-
[26]
David Lo. 2023. Trustworthy and Synergistic Artificial Intelligence for Software Engineering: Vision and Roadmaps. In2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE). 69–85
work page 2023
- [27]
-
[28]
Sanoop Mallissery and Yu-Sung Wu. 2023. Demystify the Fuzzing Methods: A Comprehensive Survey.ACM Comput. Surv.56, 3, Article 71 (Oct. 2023), 38 pages
work page 2023
-
[29]
Ruijie Meng, Van-Thuan Pham, Marcel Böhme, and Abhik Roychoudhury. 2025. AFLNet Five Years Later: On Coverage-Guided Protocol Fuzzing.IEEE Transac- tions on Software Engineering51, 4 (2025), 960–974
work page 2025
-
[30]
Zahra Mousavi, Chadni Islam, Muhammad Ali Babar, Alsharif Abuadbba, and Kristen Moore. 2025. Detecting Misuse of Security APIs: A Systematic Review. ACM Comput. Surv.57, 12, Article 303 (July 2025), 39 pages
work page 2025
-
[31]
Sarah Nadi, Stefan Krüger, Mira Mezini, and Eric Bodden. 2016. Jumping through hoops: why do Java developers struggle with cryptography APIs?. InProceedings of the 38th International Conference on Software Engineering(Austin, Texas)(ICSE ’16). Association for Computing Machinery, New York, NY, USA, 935–946
work page 2016
-
[32]
Olivier Nourry, Yutaro Kashiwa, Bin Lin, Gabriele Bavota, Michele Lanza, and Yasutaka Kamei. 2023. The Human Side of Fuzzing: Challenges Faced by Devel- opers during Fuzzing Activities.ACM Trans. Softw. Eng. Methodol.33, 1, Article 14 (Nov. 2023), 26 pages
work page 2023
-
[33]
Arm Limited (or its affiliates). 2025. ARM TrustZone Technology. https://developer.arm.com/documentation/100690/0200/ARM-TrustZone- technology. [Accessed 05-11-2025]
work page 2025
-
[34]
Mohamed Sabt, Mohammed Achemlal, and Abdelmadjid Bouabdallah. 2015. Trusted Execution Environment: What It is, and What It is Not. In2015 IEEE Trustcom/BigDataSE/ISPA, Vol. 1. 57–64. FORGE ’26, April 12–13, 2026, Rio de Janeiro, Brazil Ma et al
work page 2015
-
[35]
Jieke Shi, Zhou Yang, and David Lo. 2025. Efficient and Green Large Language Models for Software Engineering: Literature Review, Vision, and the Road Ahead. ACM Trans. Softw. Eng. Methodol.34, 5, Article 137 (May 2025), 22 pages
work page 2025
-
[36]
Yan Shoshitaishvili, Ruoyu Wang, Christopher Salls, Nick Stephens, Mario Polino, Andrew Dutcher, John Grosen, Siji Feng, Christophe Hauser, Christopher Kruegel, and Giovanni Vigna. 2016. SOK: (State of) The Art of War: Offensive Techniques in Binary Analysis. In2016 IEEE Symposium on Security and Privacy (SP). 138–157
work page 2016
-
[37]
Bo Yang, Kang Yang, Zhenfeng Zhang, Yu Qin, and Dengguo Feng. 2016. AEP-M: Practical Anonymous E-Payment for Mobile Devices Using ARM TrustZone and Divisible E-Cash. InInformation Security, Matt Bishop and Anderson C A Nascimento (Eds.). Springer International Publishing, Cham, 130–146
work page 2016
-
[38]
Joobeom Yun, Fayozbek Rustamov, Juhwan Kim, and Youngjoo Shin. 2022. Fuzzing of Embedded Systems: A Survey.ACM Comput. Surv.55, 7, Article 137 (Dec. 2022), 33 pages
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.