EnCAgg: Enhanced Clustering Aggregation for Robust Federated Learning against Dynamic Model Poisoning
Pith reviewed 2026-05-22 05:04 UTC · model grok-4.3
The pith
Known benign clients anchor low-dimensional clustering to filter variable poisoning in federated learning
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EnCAgg shows that anchoring gradient analysis with known benign clients, projecting to the two most divergent dimensions for density-based clustering, synthesizing pseudo-gradients at the benign cluster boundary, and performing re-clustering recovers benign gradients previously treated as noise, thereby allowing accurate separation of malicious updates from benign ones even when the number of attackers is unknown and changes over time.
What carries the argument
The EnCAgg pipeline of density-based low-dimensional clustering anchored by known benign clients, boundary pseudo-gradient generation, and low-dimensional re-clustering to recover outliers
If this is right
- Malicious gradients can be identified and removed without prior knowledge of their exact number or fixed detection thresholds
- Benign gradients that appear as outliers due to non-identical local data are recovered and included in aggregation
- The defense adapts automatically to changing numbers and strategies of poisoning clients over rounds
- Higher overall model accuracy results from retaining a larger share of clean gradients than fixed-cluster or threshold-based alternatives
Where Pith is reading between the lines
- Secure operation of large federated systems may require maintaining at least a minimal set of verified benign clients as operational anchors
- The reference-based clustering idea could transfer to other distributed training settings that have partial trust information
- Reducing the need for manual threshold selection could lower the barrier to deploying federated learning in production
Load-bearing premise
A small number of known benign clients exist and can serve as reliable references for distinguishing malicious gradients from benign ones despite client data heterogeneity and dynamic poisoning strategies
What would settle it
An experiment in which the known benign reference clients themselves exhibit extreme data heterogeneity that overlaps with poisoning patterns, causing the density clustering and re-clustering steps to discard a large fraction of the remaining benign gradients
Figures





read the original abstract
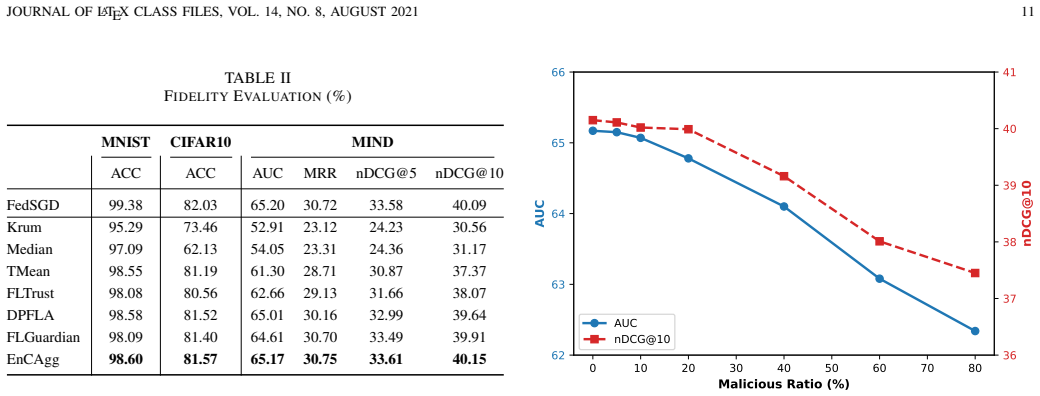
Federated learning faces increasing threats from model poisoning attacks, which harms its application to improve privacy. Existing defense methods typically rely on fixed thresholds or perform clustering with a fixed number of clusters to distinguish malicious gradients from benign ones. However, these methods are difficult to adapt to dynamic poisoning strategies of malicious clients, and often result in the loss of benign gradients due to the heterogeneity of clients' local datasets. To address these problems, we propose a novel robust aggregation method that leverages a small number of known benign clients as references, enabling accurate identification and filtering of malicious gradients while retaining as many benign gradients as possible, even when the number of malicious clients is unknown and variable. First, we introduce a density-based low-dimensional gradient clustering method, which projects gradients onto the two most divergent dimensions and applies density-based clustering to identify malicious gradients while retaining clustered benign gradients and potentially benign outliers. Second, we design an enhancing clustering low-dimensional gradient generator model, which learns to generate pseudo-gradients aligned with the boundary of the benign cluster. These pseudo-gradients act as bridges to connect sparse benign gradient outliers. Third, we introduce low-dimensional gradient re-clustering that clusters the generated pseudo-gradients together with real gradients to recover benign gradients misclassified as noise points, enabling more benign gradients to participate in aggregation. Extensive experiments on the MNIST, CIFAR-10, and MIND datasets demonstrate that our method exhibits superior fidelity and robustness under dynamic poisoning scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EnCAgg, a three-stage robust aggregation method for federated learning to defend against dynamic model poisoning attacks. It uses a small set of known benign clients as references to project gradients onto the two most divergent dimensions for density-based clustering, which identifies malicious gradients while keeping clustered benign gradients and potential outliers. A learned 'enhancing clustering low-dimensional gradient generator model' then generates pseudo-gradients aligned with the benign cluster boundary to bridge sparse benign outliers. Finally, low-dimensional gradient re-clustering incorporates these pseudo-gradients with real ones to recover misclassified benign gradients for aggregation. The method claims to handle unknown and variable numbers of malicious clients without fixed thresholds or cluster counts. Experiments on MNIST, CIFAR-10, and MIND datasets are reported to demonstrate superior fidelity and robustness compared to existing methods.
Significance. Should the central claims hold under the reported experimental conditions, the approach offers a promising way to maintain high utility in federated learning while providing robustness to adaptive poisoning without requiring knowledge of the attacker count or sacrificing many benign updates due to client heterogeneity. The integration of a generator for pseudo-gradients to handle outliers in clustering is a distinctive contribution that could influence future defense designs in distributed learning.
major comments (1)
- [First stage description] The projection of gradients onto the two most divergent dimensions (first stage, density-based low-dimensional gradient clustering) is defined relative to the small set of known benign references. If an attacker crafts updates that match benign statistics in those two coordinates while differing in other directions of the full gradient space, both the initial density clustering and the later re-clustering step can misclassify malicious points as benign. This directly undermines the central claim of accurate identification and filtering of malicious gradients under dynamic poisoning with unknown attacker count.
minor comments (2)
- The abstract states that experiments demonstrate superior fidelity and robustness but provides no quantitative metrics, attack models, or baseline comparisons; the results section should include these details with statistical significance tests for each dataset.
- [Second stage description] The generator model is described at a high level without explicit equations for its loss function or training procedure; adding these would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thorough review and valuable feedback. We address the major comment below and indicate the planned revisions to the manuscript.
read point-by-point responses
-
Referee: The projection of gradients onto the two most divergent dimensions (first stage, density-based low-dimensional gradient clustering) is defined relative to the small set of known benign references. If an attacker crafts updates that match benign statistics in those two coordinates while differing in other directions of the full gradient space, both the initial density clustering and the later re-clustering step can misclassify malicious points as benign. This directly undermines the central claim of accurate identification and filtering of malicious gradients under dynamic poisoning with unknown attacker count.
Authors: We appreciate the referee pointing out this potential attack vector. The two dimensions are selected as those maximizing divergence among the known benign reference gradients, with the intent of capturing the dominant directions of benign variation in the high-dimensional space. Under our threat model, malicious clients lack direct knowledge of the private benign references and thus the exact projection axes; crafting updates that precisely align in those two coordinates while still achieving effective poisoning across the remaining dimensions is non-trivial. Nevertheless, we acknowledge that a fully adaptive attacker with knowledge of the projection could attempt to evade detection in the projected space. To address this, we will revise the manuscript by adding a dedicated limitations subsection that explicitly discusses this scenario, along with new experiments evaluating performance against adaptive attackers that mimic benign statistics in the selected dimensions. We will also clarify the assumptions in the threat model section. revision: yes
Circularity Check
No circularity: algorithmic pipeline is self-contained
full rationale
The paper describes EnCAgg as a multi-stage algorithmic pipeline consisting of low-dimensional projection onto the two most divergent dimensions, density-based clustering to identify malicious gradients while retaining benign ones and outliers, a learned generator model that produces pseudo-gradients to bridge sparse benign points, and subsequent re-clustering to recover misclassified benign gradients. No equations, derivations, or parameter-fitting steps are shown that reduce the claimed robustness or filtering guarantees to a fitted input, self-definition, or self-citation chain. The method is presented as an independent construction relying on the stated procedures, known benign references, and experimental results on MNIST, CIFAR-10, and MIND, making the derivation self-contained without circular reduction to its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- projection dimensions
axioms (1)
- domain assumption A small number of known benign clients are available to serve as references for identifying malicious gradients.
invented entities (1)
-
Enhancing clustering low-dimensional gradient generator model
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
projects gradients onto the two most divergent dimensions and applies density-based clustering
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
density-based low-dimensional gradient clustering method... DBSCAN
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Manipulating the byzantine: Optimizing model poisoning attacks and defenses for federated learning,
V . Shejwalkar and A. Houmansadr, “Manipulating the byzantine: Optimizing model poisoning attacks and defenses for federated learning,” inNetwork and Distributed Systems Security (NDSS) Symposium. Internet Society, 2021. [Online]. Available: https: //par.nsf.gov/servlets/purl/10286354
-
[2]
Sine: Similarity is not enough for mitigating local model poisoning attacks in federated learning,
H. Kasyap and S. Tripathy, “Sine: Similarity is not enough for mitigating local model poisoning attacks in federated learning,”IEEE Transactions on Dependable and Secure Computing, vol. 21, no. 5, pp. 4481–4494, 2024
work page 2024
-
[3]
Fedimp: Parameter importance- based model poisoning attack against federated learning system,
X. Li, N. Wang, S. Yuan, and Z. Guan, “Fedimp: Parameter importance- based model poisoning attack against federated learning system,” Computers & Security, vol. 144, p. 103936, 2024. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0167404824002414
work page 2024
-
[4]
Machine learning with adversaries: Byzantine tolerant gradient descent,
P. Blanchard, E. M. El Mhamdi, R. Guerraoui, and J. Stainer, “Machine learning with adversaries: Byzantine tolerant gradient descent,” inAdvances in Neural Information Processing Systems, I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, Eds., vol. 30. Curran Associates, Inc., 2017. [Online]. Available: https://p...
work page 2017
-
[5]
Byzantine-robust distributed learning: Towards optimal statistical rates,
D. Yin, Y . Chen, R. Kannan, and P. Bartlett, “Byzantine-robust distributed learning: Towards optimal statistical rates,” inProceedings of the 35th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, J. Dy and A. Krause, Eds., vol. 80. PMLR, 10–15 Jul 2018, pp. 5650–5659. [Online]. Available: https://proceedings.ml...
work page 2018
-
[6]
The hidden vulnerability of distributed learning in Byzantium,
E. M. El Mhamdi, R. Guerraoui, and S. Rouault, “The hidden vulnerability of distributed learning in Byzantium,” inProceedings of the 35th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, J. Dy and A. Krause, Eds., vol. 80. PMLR, 10–15 Jul 2018, pp. 3521–3530. [Online]. Available: https://proceedings.mlr.press/v8...
work page 2018
-
[7]
Faba: An algorithm for fast aggregation against byzantine attacks in distributed neural networks,
Q. Xia, Z. Tao, Z. Hao, and Q. Li, “Faba: An algorithm for fast aggregation against byzantine attacks in distributed neural networks,” IJCAI. [Online]. Available: https://par.nsf.gov/biblio/10119268
-
[8]
Can you really backdoor federated learning?
Z. Sun, P. Kairouz, A. T. Suresh, and H. B. McMahan, “Can you really backdoor federated learning?” 2019. [Online]. Available: https://arxiv.org/abs/1911.07963
-
[9]
Model: A model poisoning defense framework for federated learning via truth discovery,
M. Wu, B. Zhao, Y . Xiao, C. Deng, Y . Liu, and X. Liu, “Model: A model poisoning defense framework for federated learning via truth discovery,” IEEE Transactions on Information Forensics and Security, vol. 19, pp. 8747–8759, 2024
work page 2024
-
[10]
Dpfla: Defending private federated learning against poisoning attacks,
X. Feng, W. Cheng, C. Cao, L. Wang, and V . S. Sheng, “Dpfla: Defending private federated learning against poisoning attacks,”IEEE Transactions on Services Computing, vol. 17, no. 4, pp. 1480–1491, 2024
work page 2024
-
[11]
X. Zhou, X. Chen, S. Liu, X. Fan, Q. Sun, L. Chen, M. Qiu, and T. Xiang, “Flguardian: Defending against model poisoning attacks via fine-grained detection in federated learning,”IEEE Transactions on Information Forensics and Security, vol. 20, pp. 5396–5410, 2025
work page 2025
-
[12]
FLAME: Taming backdoors in federated learning,
T. D. Nguyen, P. Rieger, H. Chen, H. Yalame, H. M ¨ollering, H. Fereidooni, S. Marchal, M. Miettinen, A. Mirhoseini, S. Zeitouni, F. Koushanfar, A.-R. Sadeghi, and T. Schneider, “FLAME: Taming backdoors in federated learning,” in31st USENIX Security Symposium (USENIX Security 22). Boston, MA: USENIX Association, Aug. 2022, pp. 1415–1432. [Online]. Availab...
work page 2022
-
[13]
Fedmp: A multi-pronged defense algorithm against byzantine poisoning attacks in federated learning,
K. Zhao, L. Wang, F. Yu, B. Zeng, and Z. Pang, “Fedmp: A multi-pronged defense algorithm against byzantine poisoning attacks in federated learning,”Computer Networks, vol. 257, p. 110990, 2025. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S1389128624008223
work page 2025
-
[14]
Local model poisoning attacks to Byzantine-Robust federated learning,
M. Fang, X. Cao, J. Jia, and N. Gong, “Local model poisoning attacks to Byzantine-Robust federated learning,” in29th USENIX Security Symposium (USENIX Security 20). USENIX Association, Aug. 2020, pp. 1605–1622. [Online]. Available: https://www.usenix.org/conference/ usenixsecurity20/presentation/fang
work page 2020
-
[15]
L. Li, W. Xu, T. Chen, G. B. Giannakis, and Q. Ling, “Rsa: Byzantine- robust stochastic aggregation methods for distributed learning from heterogeneous datasets,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, no. 01, pp. 1544–1551, Jul. 2019. [Online]. Available: https://ojs.aaai.org/index.php/AAAI/article/view/ 3968
work page 2019
-
[16]
Data poisoning attacks against federated learning systems,
V . Tolpegin, S. Truex, M. E. Gursoy, and L. Liu, “Data poisoning attacks against federated learning systems,” inComputer Security – ESORICS 2020, L. Chen, N. Li, K. Liang, and S. Schneider, Eds. Cham: Springer International Publishing, 2020, pp. 480–501
work page 2020
-
[17]
Attack of the tails: Yes, you really can backdoor federated learning,
H. Wang, K. Sreenivasan, S. Rajput, H. Vishwakarma, S. Agarwal, J.-y. Sohn, K. Lee, and D. Papailiopoulos, “Attack of the tails: Yes, you really can backdoor federated learning,” inAdvances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33. Curran Associates, Inc., 2020, pp. 16 070– 16 08...
work page 2020
-
[18]
A little is enough: Circumventing defenses for distributed learning,
G. Baruch, M. Baruch, and Y . Goldberg, “A little is enough: Circumventing defenses for distributed learning,” in Advances in Neural Information Processing Systems, H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alch ´e-Buc, E. Fox, and R. Garnett, Eds., vol. 32. Curran Associates, Inc., 2019. [Online]. Available: https://proceedings.neurips.cc/paper fil...
work page 2019
-
[19]
Ua-fedrec: Untargeted attack on federated news recommendation,
J. Yi, F. Wu, B. Zhu, J. Yao, Z. Tao, G. Sun, and X. Xie, “Ua-fedrec: Untargeted attack on federated news recommendation,” inProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, ser. KDD ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 5428–5438. [Online]. Available: https://doi.org/10.1145/3580305.3599923
-
[20]
Fedghost: Data-free model poisoning enhancement in federated learning,
Z. Ma, X. Huang, Z. Wang, Z. Qin, X. Wang, and J. Ma, “Fedghost: Data-free model poisoning enhancement in federated learning,”IEEE Transactions on Information Forensics and Security, vol. 20, pp. 2096– 2108, 2025
work page 2096
-
[21]
Covert model poisoning against federated learning: Algorithm design and op- timization,
K. Wei, J. Li, M. Ding, C. Ma, Y .-S. Jeon, and H. V . Poor, “Covert model poisoning against federated learning: Algorithm design and op- timization,”IEEE Transactions on Dependable and Secure Computing, vol. 21, no. 3, pp. 1196–1209, 2024
work page 2024
-
[22]
Dmpa: Model poisoning attacks on decentralized federated learning for model differences,
C. Feng, Y . Li, Y . Gao, A. H. Celdr ´an, J. von der Assen, G. Bovet, and B. Stiller, “Dmpa: Model poisoning attacks on decentralized federated learning for model differences,” 2025. [Online]. Available: https://arxiv.org/abs/2502.04771
-
[23]
Communication-Efficient Learning of Deep Networks from Decentralized Data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y. Arcas, “Communication-Efficient Learning of Deep Networks from Decentralized Data,” inProceedings of the 20th International Conference on Artificial Intelligence and Statistics, ser. Proceedings of Machine Learning Research, A. Singh and J. Zhu, Eds., vol. 54. PMLR, 20–22 Apr 2017, pp. 1273–1282. [...
work page 2017
-
[24]
Fltrust: Byzantine- robust federated learning via trust bootstrapping,
X. Cao, M. Fang, J. Liu, and N. Z. Gong, “Fltrust: Byzantine- robust federated learning via trust bootstrapping,” in28th Annual Network and Distributed System Security Symposium, NDSS 2021, virtually, February 21-25, 2021. The Internet Society,
work page 2021
-
[25]
[Online]. Available: https://www.ndss-symposium.org/ndss-paper/ fltrust-byzantine-robust-federated-learning-via-trust-bootstrapping/
-
[26]
Shieldfl: Mitigating model poisoning attacks in privacy-preserving federated learning,
Z. Ma, J. Ma, Y . Miao, Y . Li, and R. H. Deng, “Shieldfl: Mitigating model poisoning attacks in privacy-preserving federated learning,” IEEE Trans. Inf. Forensics Secur., vol. 17, pp. 1639–1654, 2022. [Online]. Available: https://doi.org/10.1109/TIFS.2022.3169918
-
[27]
Tdfl: Truth discovery based byzantine robust federated learning,
C. Xu, Y . Jia, L. Zhu, C. Zhang, G. Jin, and K. Sharif, “Tdfl: Truth discovery based byzantine robust federated learning,”IEEE Transactions on Parallel and Distributed Systems, vol. 33, no. 12, pp. 4835–4848, 2022
work page 2022
-
[28]
Flair: Defense against model poisoning attack in federated learning,
A. Sharma, W. Chen, J. Zhao, Q. Qiu, S. Bagchi, and S. Chaterji, “Flair: Defense against model poisoning attack in federated learning,” inProceedings of the 2023 ACM Asia Conference on Computer and Communications Security, ser. ASIA CCS ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 553–566. [Online]. Available: https://doi.org/10....
-
[29]
Flshield: A validation based federated learning framework to defend against poisoning attacks,
E. Kabir, Z. Song, M. R. Ur Rashid, and S. Mehnaz, “Flshield: A validation based federated learning framework to defend against poisoning attacks,” in2024 IEEE Symposium on Security and Privacy (SP), 2024, pp. 2572–2590
work page 2024
-
[30]
Zeno: Distributed stochastic gradient descent with suspicion-based fault-tolerance,
C. Xie, S. Koyejo, and I. Gupta, “Zeno: Distributed stochastic gradient descent with suspicion-based fault-tolerance,” inProceedings of the 36th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, K. Chaudhuri and R. Salakhutdinov, Eds., vol. 97. PMLR, 09–15 Jun 2019, pp. 6893–6901. [Online]. Available: https://pro...
work page 2019
-
[31]
MIND: A large-scale dataset for news recommendation,
F. Wu, Y . Qiao, J.-H. Chen, C. Wu, T. Qi, J. Lian, D. Liu, X. Xie, J. Gao, W. Wu, and M. Zhou, “MIND: A large-scale dataset for news recommendation,” inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault, Eds. Online: Association for Computational Linguistics, Jul. 2...
work page 2020
-
[32]
Neural news recommendation with multi-head self-attention,
C. Wu, F. Wu, S. Ge, T. Qi, Y . Huang, and X. Xie, “Neural news recommendation with multi-head self-attention,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), K. Inui, J. Jiang, V . Ng, and X. Wan, Eds. Hong Kong, China: Asso...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.