Label-Efficient Dataset Pruning via Semi-Supervised Pseudo-Labeling
Pith reviewed 2026-05-25 05:23 UTC · model grok-4.3
The pith
A small randomly labeled subset and semi-supervised pseudo-labeling lets supervised pruning methods select reliable coresets from mostly unlabeled data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SemiPrune generates pseudo-labels for unlabeled examples by training a semi-supervised model on a small randomly chosen labeled subset, then uses the resulting pseudo-labeled pool to compute training dynamics that indicate example difficulty, and finally selects a coreset with any supervised pruning method.
What carries the argument
Pseudo-label-induced training dynamics for difficulty estimation and coreset selection after semi-supervised learning on a small labeled subset.
If this is right
- Existing supervised pruning algorithms can now be applied directly to largely unlabeled pools without modification.
- Pruning performance improves on datasets whose distribution differs from common pretraining data.
- Annotation budgets can be reduced while still producing competitive coresets on standard, corrupted, and long-tailed image benchmarks.
- Difficulty signals come from dynamics on the target distribution rather than external features.
Where Pith is reading between the lines
- The initial small labeled subset could itself be chosen actively rather than randomly to further improve pseudo-label quality.
- Iterative pseudo-label refinement during the pruning process might reduce error propagation from early mistakes.
- The same pseudo-label pipeline could be tested on non-image modalities where pretrained models are even less reliable.
Load-bearing premise
The pseudo-labels produced by semi-supervised learning on the small labeled subset are accurate enough that the resulting training dynamics reliably indicate example difficulty for coreset selection.
What would settle it
On a domain-shifted dataset, train models on coresets chosen by SemiPrune versus by a pretrained-feature baseline and check whether the SemiPrune coreset yields lower test accuracy.
Figures










read the original abstract
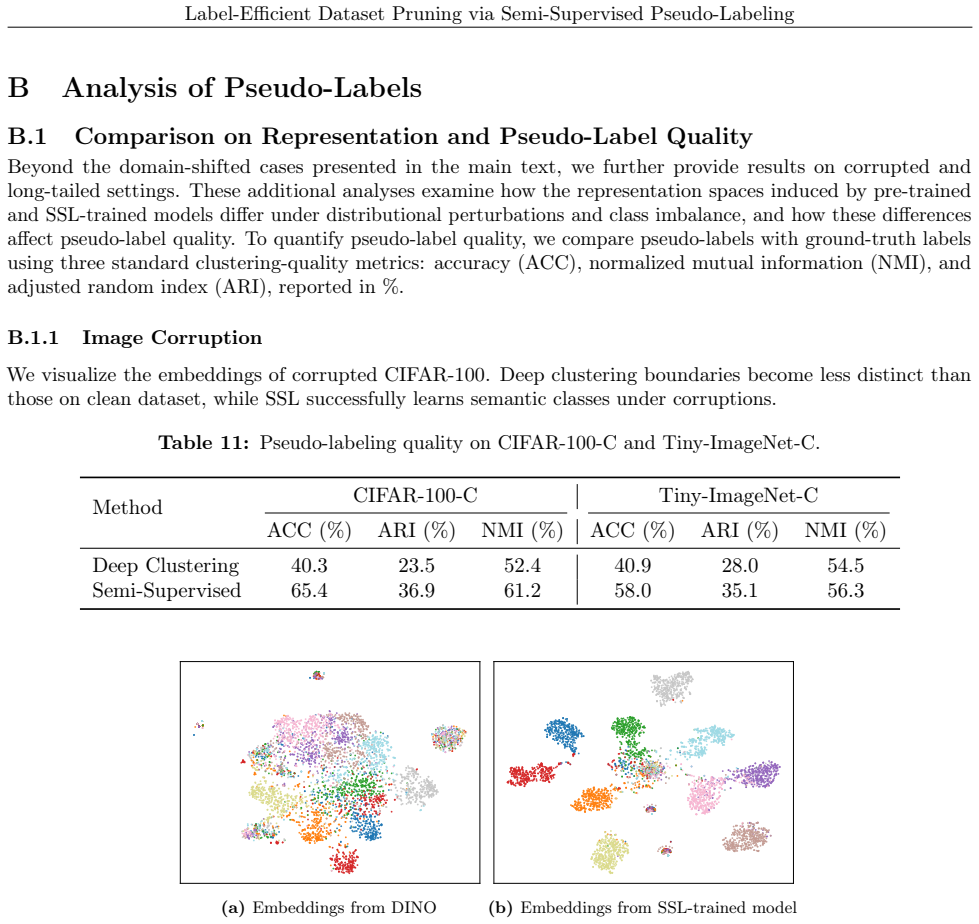
Dataset pruning reduces the storage and training costs of deep learning by selecting an informative subset from a large dataset. However, most existing pruning methods require fully labeled data, which limits their applicability in realistic settings where unlabeled data are abundant and annotation is costly. Recent label-free pruning methods address this issue, but they rely on features from pretrained models to estimate example difficulty. This dependence can be unreliable when the target dataset differs substantially from the pretraining distribution. We propose SemiPrune, a label-efficient dataset pruning framework, using only a small randomly labeled subset, that uses semi-supervised learning to generate pseudo-labels for unlabeled data, allowing existing supervised pruning methods that require label information to be seamlessly applied to the resulting pseudo-labeled training pool. We then estimate example difficulty from pseudo-label-induced training dynamics and select a coreset. By learning directly from the target dataset, our method better captures the target distribution and provides more reliable signals for difficulty estimation and coreset selection. We validate our approach on domain-specific, image-corrupted, and long-tailed datasets, where it achieves state-of-the-art performance among label-free and label-efficient baselines, while also demonstrating competitive performance on standard benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SemiPrune, a label-efficient dataset pruning method that uses a small randomly labeled subset to train a semi-supervised model, generates pseudo-labels for the remaining data, and then applies existing supervised pruning techniques (based on training dynamics) to select a coreset. It claims this captures the target distribution better than pretrained-feature methods and achieves SOTA among label-free/label-efficient baselines on domain-specific, corrupted, and long-tailed datasets while remaining competitive on standard benchmarks.
Significance. If the central mechanism holds, the work would meaningfully extend dataset pruning to realistic low-label regimes without relying on potentially mismatched pretrained models, directly addressing annotation cost and distribution shift issues. The approach re-uses existing supervised difficulty estimators on a pseudo-labeled pool, which is a pragmatic strength if the induced dynamics remain faithful.
major comments (2)
- [§3 (method description)] The central claim (abstract and §3) that 'pseudo-label-induced training dynamics' reliably indicate example difficulty for coreset selection rests on an unexamined assumption: that SSL pseudo-labels from a small random labeled subset produce monotonic loss/gradient signals with respect to true difficulty. No derivation, bound, or even correlation analysis is provided showing this holds under domain shift, corruption, or long-tailed distributions, where confirmation bias in SSL is known to distort per-example losses.
- [§4 (experimental validation)] Experiments (presumably §4) report SOTA performance on the highlighted regimes but provide no validation of pseudo-label accuracy, no ablations on labeled-subset size, and no comparison of difficulty rankings before/after pseudo-labeling. Without these, it is impossible to attribute gains to the proposed mechanism rather than incidental factors.
minor comments (1)
- [§3] Notation for the semi-supervised component and the difficulty estimator should be introduced with explicit equations rather than prose descriptions to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below and will revise the manuscript accordingly to strengthen the presentation of the method and experiments.
read point-by-point responses
-
Referee: [§3 (method description)] The central claim (abstract and §3) that 'pseudo-label-induced training dynamics' reliably indicate example difficulty for coreset selection rests on an unexamined assumption: that SSL pseudo-labels from a small random labeled subset produce monotonic loss/gradient signals with respect to true difficulty. No derivation, bound, or even correlation analysis is provided showing this holds under domain shift, corruption, or long-tailed distributions, where confirmation bias in SSL is known to distort per-example losses.
Authors: We agree that the current manuscript provides no theoretical derivation or bound and does not include an explicit correlation analysis between pseudo-label-induced difficulty scores and ground-truth difficulty scores. The empirical results on domain-specific, corrupted, and long-tailed data offer indirect support for the mechanism, but this is insufficient to fully address the concern. In the revision we will add a correlation study (using the small labeled subset where ground-truth labels are available) to quantify how well pseudo-label dynamics preserve difficulty rankings. revision: yes
-
Referee: [§4 (experimental validation)] Experiments (presumably §4) report SOTA performance on the highlighted regimes but provide no validation of pseudo-label accuracy, no ablations on labeled-subset size, and no comparison of difficulty rankings before/after pseudo-labeling. Without these, it is impossible to attribute gains to the proposed mechanism rather than incidental factors.
Authors: We acknowledge that the submitted manuscript omits direct validation of pseudo-label accuracy, ablations over labeled-subset size, and before/after comparisons of difficulty rankings. These additions are feasible and will be included in the revised version to better isolate the contribution of the pseudo-labeling step. We will report pseudo-label accuracy on held-out labeled data, vary the labeled fraction from 1% to 10%, and show rank correlations of difficulty scores computed with versus without pseudo-labels. revision: yes
Circularity Check
No significant circularity; method is self-contained empirical proposal
full rationale
The paper proposes SemiPrune as a practical framework that applies existing supervised pruning techniques to a pseudo-labeled pool generated via standard SSL on a small labeled subset. No equations, derivations, or parameter-fitting steps are described in the provided text that reduce a claimed prediction or result to its own inputs by construction. The central claim rests on the empirical performance of reusing off-the-shelf difficulty estimators on the SSL output rather than on any self-referential mathematical identity or load-bearing self-citation chain. This is the most common honest finding for applied method papers without internal derivations.
Axiom & Free-Parameter Ledger
free parameters (1)
- fraction of randomly labeled data
axioms (1)
- domain assumption Semi-supervised learning produces pseudo-labels sufficiently accurate for downstream difficulty estimation on the target dataset
Reference graph
Works this paper leans on
-
[1]
Deep Learning Scaling is Predictable, Empirically
Deep learning scaling is predictable, empirically , author=. arXiv preprint arXiv:1712.00409 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:1909.12673 , year=
A constructive prediction of the generalization error across scales , author=. arXiv preprint arXiv:1909.12673 , year=
-
[3]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Data and parameter scaling laws for neural machine translation , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2021
-
[4]
Advances in Neural Information Processing Systems , volume=
Beyond neural scaling laws: beating power law scaling via data pruning , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
International Conference on Learning Representations , year=
An Empirical Study of Example Forgetting during Deep Neural Network Learning , author=. International Conference on Learning Representations , year=
-
[8]
International Conference on Learning Representations , year=
Selection via Proxy: Efficient Data Selection for Deep Learning , author=. International Conference on Learning Representations , year=
-
[9]
Advances in Neural Information Processing Systems , volume=
Identifying mislabeled data using the area under the margin ranking , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Large-scale dataset pruning with dynamic uncertainty , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[11]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Spanning training progress: Temporal dual-depth scoring (tdds) for enhanced dataset pruning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[12]
Advances in neural information processing systems , volume=
Deep learning on a data diet: Finding important examples early in training , author=. Advances in neural information processing systems , volume=
-
[13]
The Eleventh International Conference on Learning Representations , year=
Coverage-centric Coreset Selection for High Pruning Rates , author=. The Eleventh International Conference on Learning Representations , year=
-
[14]
Adyasha Maharana and Prateek Yadav and Mohit Bansal , booktitle=. \. 2024 , url=
work page 2024
-
[15]
The Eleventh International Conference on Learning Representations , year=
Moderate Coreset: A Universal Method of Data Selection for Real-world Data-efficient Deep Learning , author=. The Eleventh International Conference on Learning Representations , year=
-
[16]
Forty-first International Conference on Machine Learning , year=
Mind the Boundary: Coreset Selection via Reconstructing the Decision Boundary , author=. Forty-first International Conference on Machine Learning , year=
-
[17]
Advances in neural information processing systems , volume=
Coresets via bilevel optimization for continual learning and streaming , author=. Advances in neural information processing systems , volume=
-
[18]
International Conference on Machine Learning , pages=
Probabilistic bilevel coreset selection , author=. International Conference on Machine Learning , pages=. 2022 , organization=
work page 2022
-
[19]
Forty-first International Conference on Machine Learning , year=
Refined Coreset Selection: Towards Minimal Coreset Size under Model Performance Constraints , author=. Forty-first International Conference on Machine Learning , year=
-
[20]
Balancing Feature Similarity and Label Variability for Optimal Size-Aware One-shot Subset Selection , author=. 2024 , booktitle=
work page 2024
-
[21]
arXiv preprint arXiv:2002.03206 , year=
Characterizing structural regularities of labeled data in overparameterized models , author=. arXiv preprint arXiv:2002.03206 , year=
- [22]
-
[23]
International Conference on Machine Learning , pages=
Lightweight Dataset Pruning without Full Training via Example Difficulty and Prediction Uncertainty , author=. International Conference on Machine Learning , pages=. 2025 , organization=
work page 2025
-
[24]
International Conference on Machine Learning , pages=
Grad-match: Gradient matching based data subset selection for efficient deep model training , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[25]
Advances in neural information processing systems , volume=
Fixmatch: Simplifying semi-supervised learning with consistency and confidence , author=. Advances in neural information processing systems , volume=
-
[26]
Eleventh International Conference on Learning Representations , year=
FreeMatch: Self-adaptive Thresholding for Semi-supervised Learning , author=. Eleventh International Conference on Learning Representations , year=
-
[27]
Bartoldson and Bhavya Kailkhura and Atul Prakash , booktitle=
Haizhong Zheng and Elisa Tsai and Yifu Lu and Jiachen Sun and Brian R. Bartoldson and Bhavya Kailkhura and Atul Prakash , booktitle=. 2025 , url=
work page 2025
-
[28]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Zero-Shot Coreset Selection via Iterative Subspace Sampling , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[29]
International Conference on Learning Representations , year=
Theoretical Analysis of Self-Training with Deep Networks on Unlabeled Data , author=. International Conference on Learning Representations , year=
-
[30]
Advances in neural information processing systems , volume=
Unsupervised learning of visual features by contrasting cluster assignments , author=. Advances in neural information processing systems , volume=
-
[31]
arXiv preprint arXiv:2303.17896 , year=
Exploring the limits of deep image clustering using pretrained models , author=. arXiv preprint arXiv:2303.17896 , year=
-
[32]
Transactions on Machine Learning Research , issn=
Maxime Oquab and Timoth. Transactions on Machine Learning Research , issn=. 2024 , url=
work page 2024
-
[33]
Effective Data Pruning through Score Extrapolation , author=. 2026 , url=
work page 2026
-
[34]
Revisiting Semi-Supervised Learning in the Era of Foundation Models , author=
-
[35]
Advances in neural information processing systems , volume=
Retrieve: Coreset selection for efficient and robust semi-supervised learning , author=. Advances in neural information processing systems , volume=
-
[36]
International Conference on Learning Representations , year=
Deep Batch Active Learning by Diverse, Uncertain Gradient Lower Bounds , author=. International Conference on Learning Representations , year=
-
[37]
International Conference on Machine Learning , pages=
Active Learning on a Budget: Opposite Strategies Suit High and Low Budgets , author=. International Conference on Machine Learning , pages=. 2022 , organization=
work page 2022
-
[38]
The Twelfth International Conference on Learning Representations , year=
InfoBatch: Lossless Training Speed Up by Unbiased Dynamic Data Pruning , author=. The Twelfth International Conference on Learning Representations , year=
-
[39]
The Thirteenth International Conference on Learning Representations , year=
Instance-dependent Early Stopping , author=. The Thirteenth International Conference on Learning Representations , year=
-
[40]
The Twelfth International Conference on Learning Representations , year=
Repeated Random Sampling for Minimizing the Time-to-Accuracy of Learning , author=. The Twelfth International Conference on Learning Representations , year=
-
[41]
Workshop on challenges in representation learning, ICML , volume=
Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks , author =. Workshop on challenges in representation learning, ICML , volume=. 2013 , organization=
work page 2013
-
[42]
Advances in neural information processing systems , volume=
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results , author=. Advances in neural information processing systems , volume=
-
[43]
Advances in neural information processing systems , volume=
Unsupervised data augmentation for consistency training , author=. Advances in neural information processing systems , volume=
-
[44]
Advances in neural information processing systems , volume=
Flexmatch: Boosting semi-supervised learning with curriculum pseudo labeling , author=. Advances in neural information processing systems , volume=
-
[45]
The Eleventh International Conference on Learning Representations , year=
SoftMatch: Addressing the Quantity-Quality Tradeoff in Semi-supervised Learning , author=. The Eleventh International Conference on Learning Representations , year=
-
[46]
Agarwalla, Abhinav , title =
-
[47]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Revisiting Semi-Supervised Learning in the Era of Foundation Models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[48]
International conference on machine learning , pages=
A simple framework for contrastive learning of visual representations , author=. International conference on machine learning , pages=. 2020 , organization=
work page 2020
-
[49]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Momentum contrast for unsupervised visual representation learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[50]
International Conference on Machine Learning , pages=
BWS: Best Window Selection Based on Sample Scores for Data Pruning across Broad Ranges , author=. International Conference on Machine Learning , pages=. 2024 , organization=
work page 2024
-
[51]
Proceedings of the European conference on computer vision (ECCV) , pages=
Deep clustering for unsupervised learning of visual features , author=. Proceedings of the European conference on computer vision (ECCV) , pages=
-
[52]
Advances in neural information processing systems , volume=
Mixmatch: A holistic approach to semi-supervised learning , author=. Advances in neural information processing systems , volume=
-
[53]
Advances in neural information processing systems , volume=
Semi-supervised learning by entropy minimization , author=. Advances in neural information processing systems , volume=
-
[54]
International Conference on Learning Representations , year=
Self-labelling via simultaneous clustering and representation learning , author=. International Conference on Learning Representations , year=
-
[55]
European conference on computer vision , pages=
Scan: Learning to classify images without labels , author=. European conference on computer vision , pages=. 2020 , organization=
work page 2020
-
[56]
Advances in neural information processing systems , volume=
Bootstrap your own latent-a new approach to self-supervised learning , author=. Advances in neural information processing systems , volume=
-
[57]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Emerging properties in self-supervised vision transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[58]
Proceedings of the AAAI conference on artificial intelligence , volume=
Semantic-enhanced image clustering , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[59]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
-
[60]
DINOv2: Learning Robust Visual Features without Supervision
Dinov2: Learning robust visual features without supervision , author=. arXiv preprint arXiv:2304.07193 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
European conference on computer vision , pages=
Food-101--mining discriminative components with random forests , author=. European conference on computer vision , pages=. 2014 , organization=
work page 2014
-
[62]
2010 IEEE computer society conference on computer vision and pattern recognition , pages=
Sun database: Large-scale scene recognition from abbey to zoo , author=. 2010 IEEE computer society conference on computer vision and pattern recognition , pages=. 2010 , organization=
work page 2010
-
[63]
2004 conference on computer vision and pattern recognition workshop , pages=
Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories , author=. 2004 conference on computer vision and pattern recognition workshop , pages=. 2004 , organization=
work page 2004
- [64]
-
[65]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
work page 2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.