Machine Intelligence that Understands Visual and Linguistic Information and Interacts with Humans and Environments
Pith reviewed 2026-06-30 17:37 UTC · model grok-4.3
The pith
Three new transformer models advance image captioning, visual dialog, and embodied instruction following.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
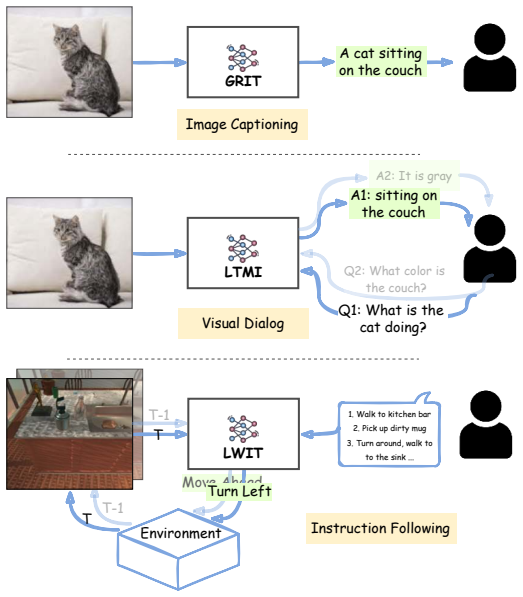
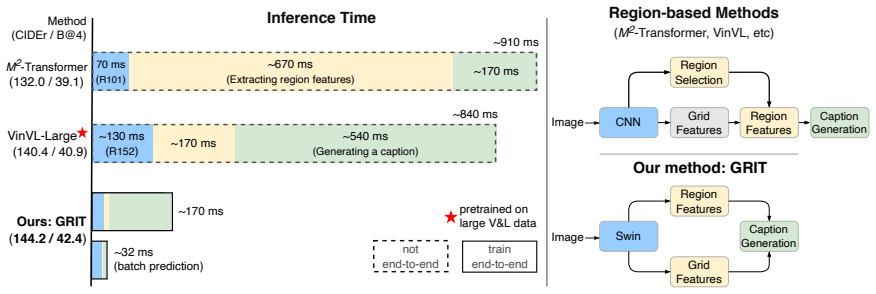
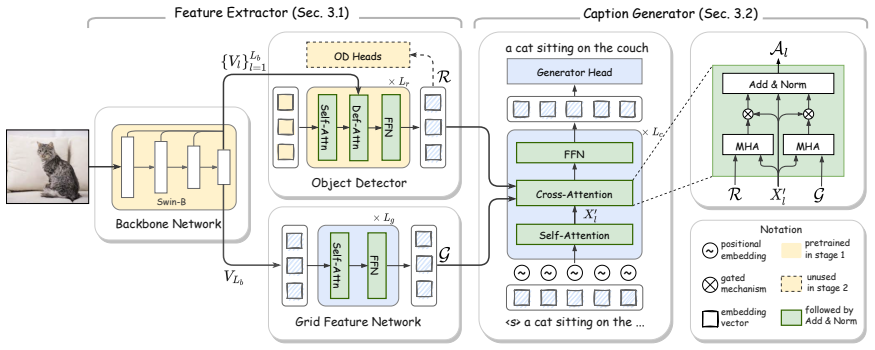
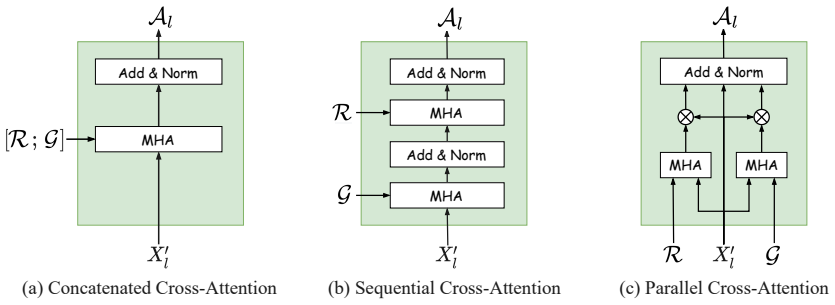
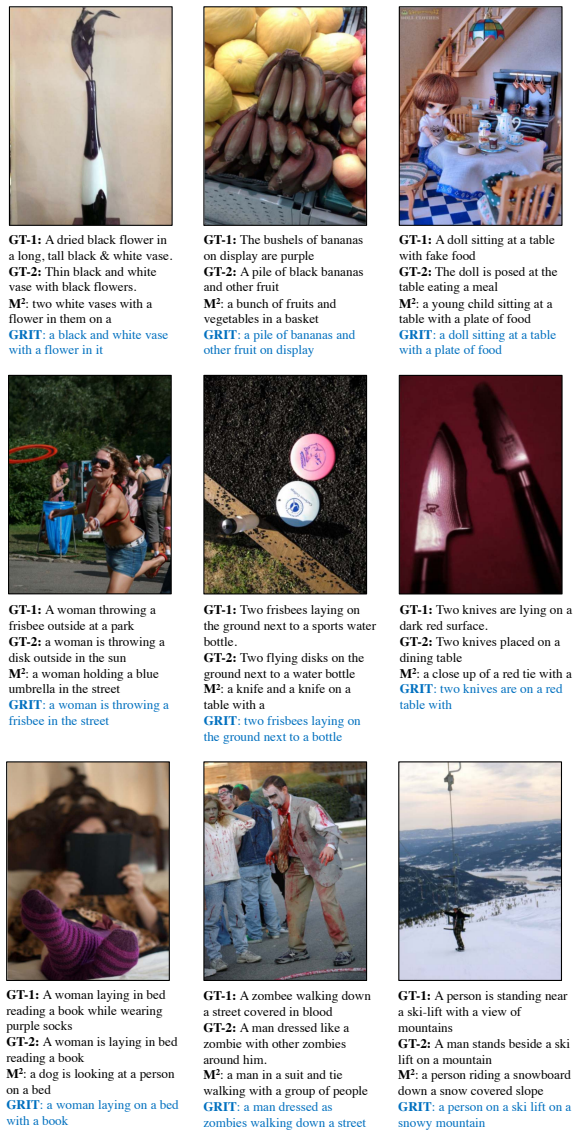
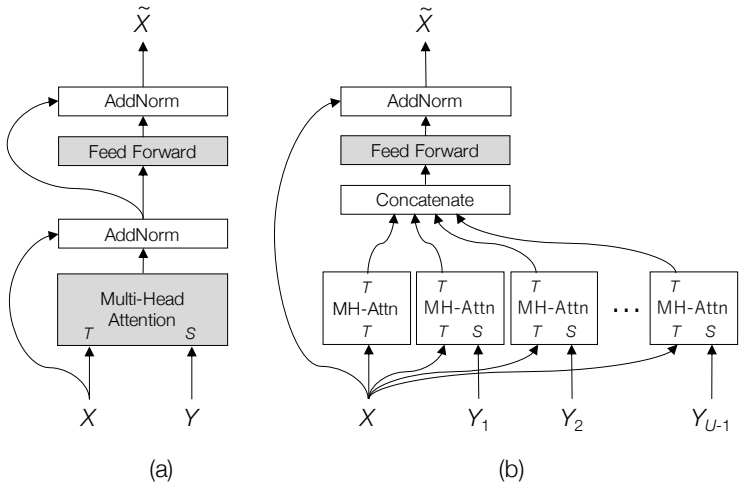
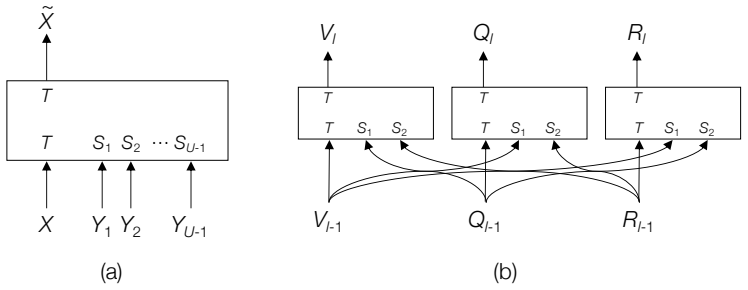
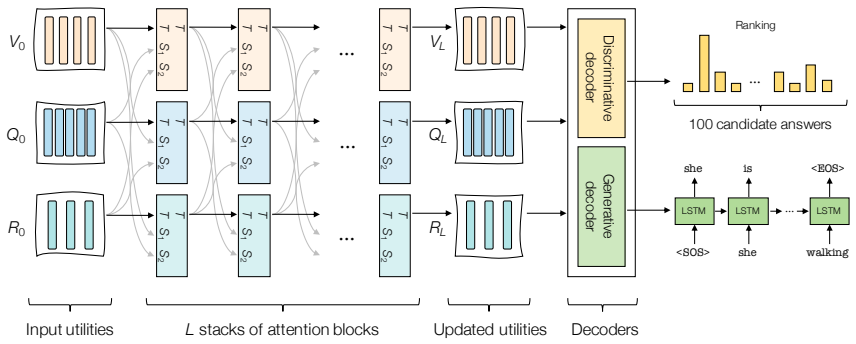
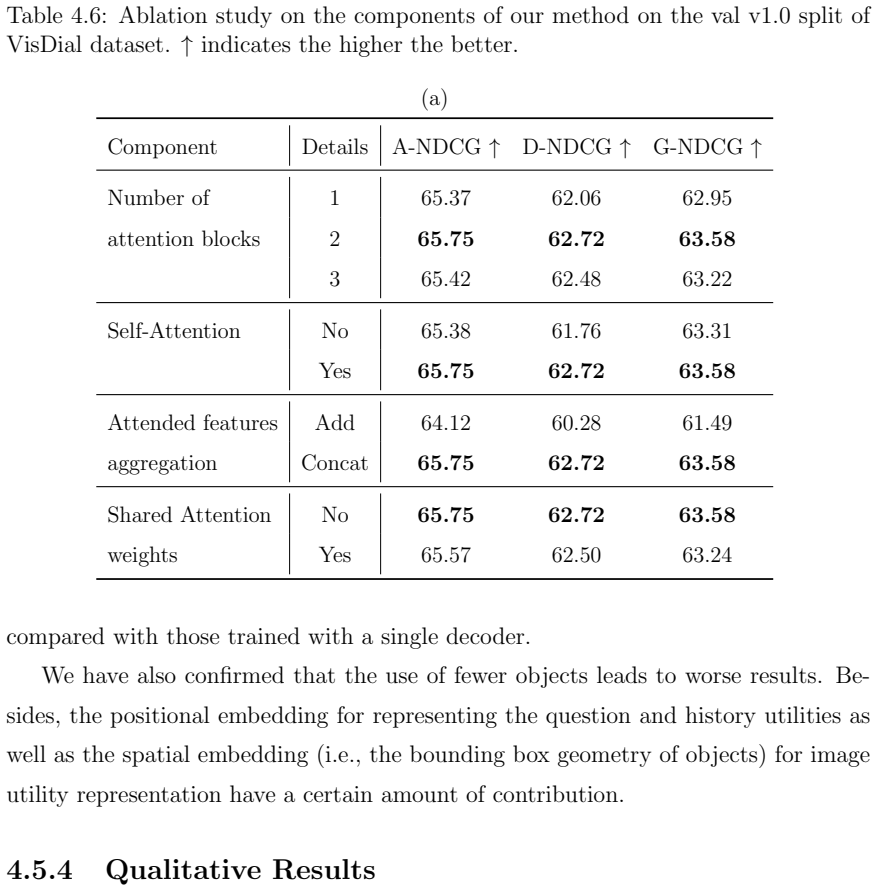
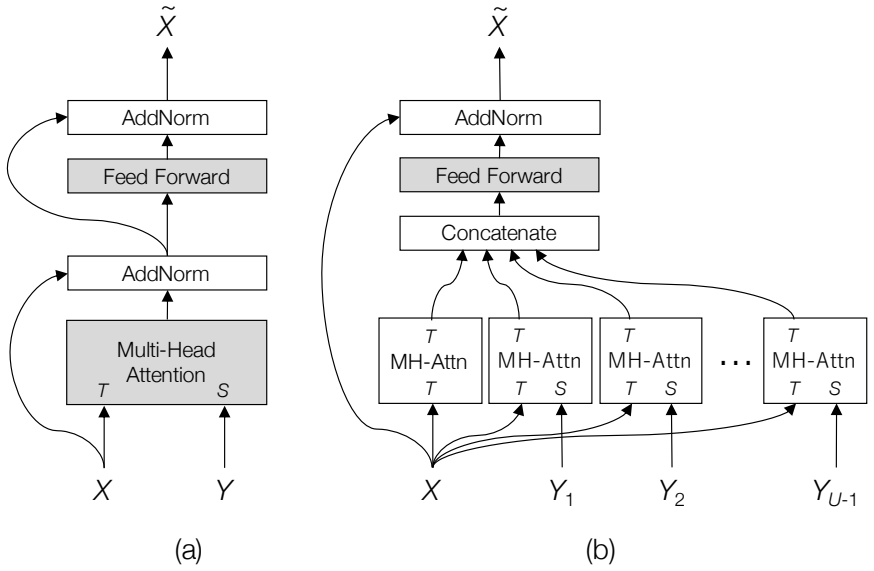
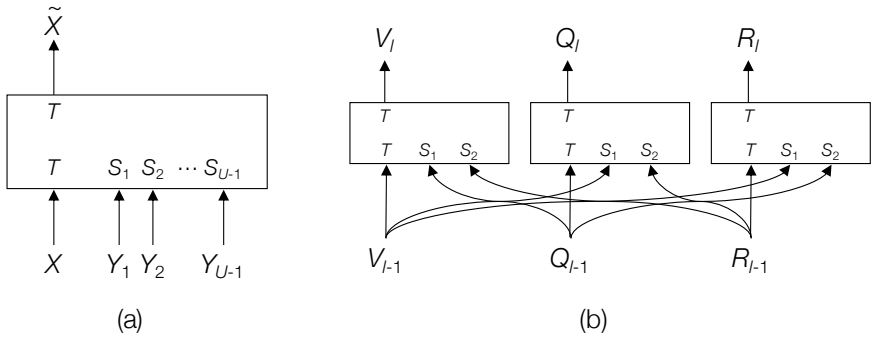
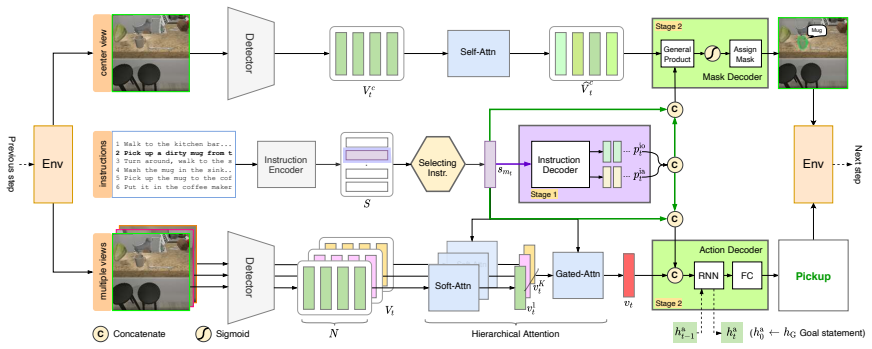
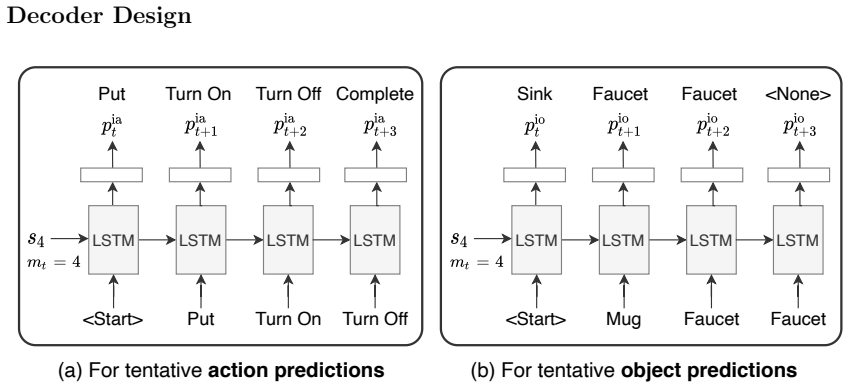
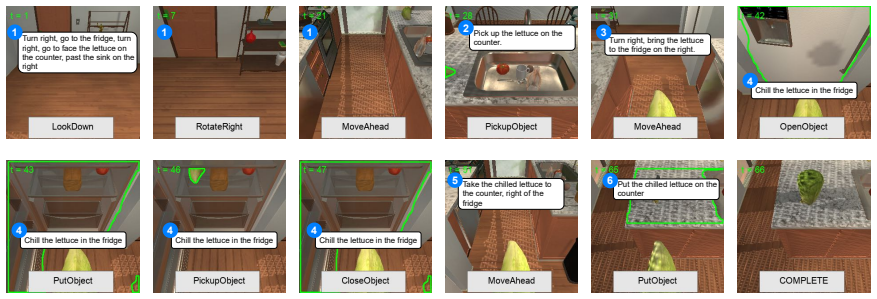
GRIT integrates grid and region features using a DETR-based detector for end-to-end image captioning that outperforms prior methods in accuracy and speed. LTMI employs a specialized attention block to match the power of a standard Transformer extension on VisDial while using less than one-tenth the parameters. The instruction-following framework decodes language directives independently of visuals to predict a tentative sequence, then fuses it with visual features using multiple egocentric views and hierarchical attention to achieve state-of-the-art 8.37% unseen success on ALFRED.
What carries the argument
GRIT grid-region fusion in a transformer-only architecture; LTMI specialized attention block for multi-input modeling; two-stage language decoding with hierarchical attention for embodied agents.
If this is right
- Image captioning systems can train end-to-end without separate region detectors and run faster at inference.
- Visual dialog agents can process multiple inputs with far lower parameter counts while retaining performance.
- Embodied agents can better localize objects and follow instructions by separating language interpretation from visual fusion.
- Hybrid feature approaches and staged decoding become viable patterns for other vision-language tasks.
- Overall, agents that handle visual and linguistic information become more efficient and capable for assistive and robotic uses.
Where Pith is reading between the lines
- The lightweight attention design in LTMI could extend to other multi-modal settings with many inputs, such as video dialog.
- Combining elements from GRIT and the two-stage framework might create a single model for both static captioning and dynamic instruction following.
- The reported success rate on ALFRED suggests testing the framework on additional embodied benchmarks to measure generalization.
- Parameter reductions shown in LTMI raise the possibility of running these models on resource-limited hardware.
Load-bearing premise
Reported gains on the three tasks come from the architectural choices of grid-region fusion, specialized attention, and two-stage decoding rather than training details or baseline differences.
What would settle it
Independent re-implementation of the three models and baselines on the same datasets, checking whether accuracy, speed, parameter counts, and success rates remain superior.
Figures



















read the original abstract
Advancements at the intersection of computer vision and natural language processing are crucial for applications like assistive tech, multimedia querying, and robotics. This dissertation proposes novel architectures to improve intelligent agents across three key vision-language tasks: image captioning, visual dialog, and interactive instruction following. First, we address limitations in visual representation for image captioning. Traditional models rely on region-based features from CNN detectors, which lack global context and suffer from high computational overhead. We propose GRIT (Grid and Region-based Image captioning Transformer), a transformer-only architecture. By integrating grid and region features using a DETR-based detector, GRIT enables end-to-end training and out-performs prior methods in both inference accuracy and speed. Second, we tackle visual dialog, which requires multi-turn conversation about an image. The challenge lies in efficiently modeling interactions between multiple inputs (image, question, history). We introduce LTMI (Light-weight Transformer for Many Inputs). Utilizing a specialized attention block, an LTMI layer matches the representational power of a standard Transformer extension while utilizing less than one-tenth of its parameters, as validated on the VisDial dataset. Finally, we study interactive instruction-following for embodied AI using the ALFRED dataset. We propose a framework featuring a two-stage instruction interpretation: it first decodes language directives independently of visual context to predict a tentative action-object sequence, which is then fused with visual features for final execution. Using multiple egocentric views and hierarchical attention, our method accurately localizes objects and achieves a state-of-the-art unseen success rate of 8.37%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This dissertation proposes three architectures for vision-language tasks: GRIT, a DETR-based transformer that fuses grid and region features for end-to-end image captioning claimed to outperform priors in accuracy and speed; LTMI, a lightweight transformer using a specialized attention block that matches standard transformer power with <1/10 parameters on VisDial; and a two-stage instruction-following framework with language decoding independent of vision followed by visual fusion, achieving 8.37% unseen success on ALFRED via multiple egocentric views and hierarchical attention.
Significance. If the performance claims are substantiated with controls, the parameter efficiency of LTMI and the end-to-end training enabled by GRIT could advance practical multimodal systems for robotics and dialog. The ALFRED result addresses a challenging embodied task, but the absence of any experimental validation, baselines, or ablations in the manuscript prevents assessing whether these contributions are meaningful or attributable to the named components.
major comments (3)
- [Abstract] Abstract: The central claim that GRIT 'out-performs prior methods in both inference accuracy and speed' and enables end-to-end training via grid-region fusion supplies no numerical results, baseline comparisons, error bars, or ablation studies, which is load-bearing for validating the architectural contribution over dataset or training differences.
- [Abstract] Abstract: The assertion that LTMI 'matches the representational power of a standard Transformer extension while utilizing less than one-tenth of its parameters' is presented without any table, figure, or quantitative comparison on VisDial (e.g., no reported accuracy, parameter counts, or matched baselines), undermining evaluation of the specialized attention block.
- [Abstract] Abstract: The state-of-the-art claim of 8.37% unseen success rate on ALFRED is given as a specific number, yet the text provides no baseline results, ablation on the two-stage decoding, details on the hierarchical attention, or analysis of how multiple egocentric views contribute, making it impossible to attribute gains to the proposed framework.
minor comments (1)
- [Abstract] The abstract uses terms like 'grid and region features' and 'specialized attention block' without brief definitions or references to prior work on DETR or VisDial, which would aid clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for quantitative substantiation of claims. The full dissertation contains detailed experimental results, tables, baselines, and ablations across its chapters; we will revise the abstract to incorporate key numbers and references to these sections.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that GRIT 'out-performs prior methods in both inference accuracy and speed' and enables end-to-end training via grid-region fusion supplies no numerical results, baseline comparisons, error bars, or ablation studies, which is load-bearing for validating the architectural contribution over dataset or training differences.
Authors: The GRIT chapter includes COCO benchmark results with specific metrics (e.g., CIDEr, BLEU scores), inference speed comparisons, and ablations on grid-region fusion versus prior region-only methods, along with end-to-end training details. We will revise the abstract to report these quantitative outcomes and direct readers to the relevant tables. revision: yes
-
Referee: [Abstract] Abstract: The assertion that LTMI 'matches the representational power of a standard Transformer extension while utilizing less than one-tenth of its parameters' is presented without any table, figure, or quantitative comparison on VisDial (e.g., no reported accuracy, parameter counts, or matched baselines), undermining evaluation of the specialized attention block.
Authors: The LTMI chapter reports VisDial results with accuracy figures, parameter counts for LTMI versus standard transformers, and direct comparisons. We will update the abstract to include these specific numbers and performance metrics. revision: yes
-
Referee: [Abstract] Abstract: The state-of-the-art claim of 8.37% unseen success rate on ALFRED is given as a specific number, yet the text provides no baseline results, ablation on the two-stage decoding, details on the hierarchical attention, or analysis of how multiple egocentric views contribute, making it impossible to attribute gains to the proposed framework.
Authors: The instruction-following chapter provides ALFRED results with baselines, ablations on the two-stage language-then-vision decoding and hierarchical attention, plus analysis of multiple egocentric views. We will expand the abstract to reference these supporting experiments and key findings. revision: yes
Circularity Check
No circularity: performance claims rest on empirical results, not self-referential derivations
full rationale
The manuscript proposes three architectures (GRIT, LTMI, two-stage instruction framework) and reports empirical metrics (accuracy/speed gains, parameter reduction, 8.37% ALFRED success). No equations, fitted parameters, uniqueness theorems, or first-principles derivations appear in the provided text. Claims are presented as experimental outcomes rather than mathematical reductions that loop back to inputs. No self-citation chains or ansatzes are invoked to justify core results. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shridhar, J
M. Shridhar, J. Thomason, D. Gordon, Y. Bisk, W. Han, R. Mottaghi, L. Zettle- moyer, and D. Fox. Alfred: A benchmark for interpreting grounded instructions for everyday tasks. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020
2020
-
[2]
Gradient- based learning applied to document recognition
Yann LeCun, L´ eon Bottou, Yoshua Bengio, Patrick Haffner, et al. Gradient- based learning applied to document recognition. InProceedings of the IEEE, 1998
1998
-
[3]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, pages 5998–6008, 2017
2017
-
[4]
Imagenet classification with deep convolutional neural networks
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. InAdvances in Neural Information Processing Systems, volume 25, 2012
2012
-
[5]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. InarXiv preprint arXiv:1409.1556, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[6]
Deep residual learn- ing for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learn- ing for image recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016
2016
-
[7]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. InarXiv:2010.11929, 2020. 107
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[8]
Faster r-cnn: Towards real-time object detection with region proposal networks
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. InAdvances in Neural Information Processing Systems, pages 91–99, 2015
2015
-
[9]
Girshick
Kaiming He, Georgia Gkioxari, Piotr Doll´ ar, and Ross B. Girshick. Mask R- CNN. InProceedings of the IEEE International Conference on Computer Vi- sion, pages 2980–2988. IEEE Computer Society, 2017
2017
-
[10]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InProceedings of the Conference on Computer Vision and Pattern Recognition, 2009
2009
-
[11]
Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey
Longlong Jing and Yingli Tian. Self-supervised visual feature learning with deep neural networks: A survey. InCoRR, volume abs/1902.06162, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[12]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In arXiv preprint arXiv:1810.04805, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[13]
Im- proving language understanding by generative pre-training
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Im- proving language understanding by generative pre-training. InTechnical report. OpenAI, 2018
2018
-
[14]
Language Models are Few-Shot Learners
Tom B Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Ka- plan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InarXiv preprint arXiv:2005.14165, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[15]
Deep fragment embeddings for bidirectional image sentence mapping
Andrej Karpathy, Armand Joulin, and Li F Fei-Fei. Deep fragment embeddings for bidirectional image sentence mapping. InAdvances in Neural Information Processing Systems, volume 27, 2014
2014
-
[16]
Show and tell: A neural image caption generator
Oriol Vinyals, Alexander Toshev, Samy Bengio, and Dumitru Erhan. Show and tell: A neural image caption generator. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3156–3164, 2015. 108
2015
-
[17]
Vqa: Visual question answering
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Ba- tra, C Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, pages 2425–2433, 2015
2015
-
[18]
Visual dialog
Abhishek Das, Satwik Kottur, Khushi Gupta, Avi Singh, Deshraj Yadav, Jos´ e MF Moura, Devi Parikh, and Dhruv Batra. Visual dialog. InProceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 326–335, 2017
2017
-
[19]
Anderson, Q
P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. S¨ underhauf, I. Reid, S. Gould, and A. van den Hengel. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018
2018
-
[20]
Fried, R
D. Fried, R. Hu, V. Cirik, A. Rohrbach, J. Andreas, L.-P. Morency, T. Berg- Kirkpatrick, K. Saenko, D. Klein, and T. Darrell. Speaker-follower models for vision-and-language navigation. InAdvances in Neural Information Processing Systems, 2018
2018
-
[21]
F. Zhu, Y. Zhu, X. Chang, and X. Liang. Vision-language navigation with self- supervised auxiliary reasoning tasks. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020
2020
-
[22]
Polylingual multimodal learning
Aditya Mogadala. Polylingual multimodal learning. InECML PKDD Doctoral Consortium, page 155. Citeseer, 2015
2015
-
[23]
C.-Y. Ma, J. Lu, Z. Wu, G. AlRegib, Z. Kira, R. Socher, and C. Xiong. Self- monitoring navigation agent via auxiliary progress estimation. InProceedings of International Conference on Learning Representations, 2019
2019
-
[24]
MIT Press, 2016
Ian Goodfellow, Yoshua Bengio, Aaron Courville, and Yoshua Bengio.Deep learning, volume 1. MIT Press, 2016
2016
-
[25]
Some methods of speeding up the convergence of iteration methods
Boris T Polyak. Some methods of speeding up the convergence of iteration methods. InUssr computational mathematics and mathematical physics, vol- ume 4, pages 1–17. Elsevier, 1964. 109
1964
-
[26]
On the importance of initialization and momentum in deep learning
Ilya Sutskever, James Martens, George Dahl, and Geoffrey Hinton. On the importance of initialization and momentum in deep learning. InProceedings of International Conference on Machine Learning, pages 1139–1147. PMLR, 2013
2013
-
[27]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimiza- tion. InarXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[28]
Adaptive subgradient methods for online learning and stochastic optimization
John Duchi, Elad Hazan, and Yoram Singer. Adaptive subgradient methods for online learning and stochastic optimization. InJournal of machine learning research, volume 12, 2011
2011
-
[29]
Hinton, Simon Osindero, and Yee Whye Teh
Geoffrey E. Hinton, Simon Osindero, and Yee Whye Teh. A fast learning algo- rithm for deep belief nets.Neural Computation, 18:1527–1554, 2006
2006
-
[30]
The perceptron: a probabilistic model for information stor- age and organization in the brain.Psychological review, 65(6):386, 1958
Frank Rosenblatt. The perceptron: a probabilistic model for information stor- age and organization in the brain.Psychological review, 65(6):386, 1958
1958
-
[31]
Learning internal representations by error propagation
David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning internal representations by error propagation. Technical report, California Univ San Diego La Jolla Inst for Cognitive Science, 1985
1985
-
[32]
Learning representations by back-propagating errors
David E Rumelhart, Geoffrey E Hinton, Ronald J Williams, et al. Learning representations by back-propagating errors. InCognitive modeling, volume 5, page 1, 1988
1988
-
[33]
Long short-term memory
Sepp Hochreiter and J¨ urgen Schmidhuber. Long short-term memory. InNeural computation, volume 9, pages 1735–1780, 1997
1997
-
[34]
Swin transformer: Hierarchical vision transformer us- ing shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer us- ing shifted windows. InProceedings of the IEEE International Conference on Computer Vision, pages 10012–10022, 2021
2021
-
[35]
Show, attend and tell: Neural image caption generation with visual attention
Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, and Yoshua Bengio. Show, attend and tell: Neural image caption generation with visual attention. InProceedings of International Conference on Machine Learning, pages 2048–2057, 2015. 110
2048
-
[36]
Self-critical sequence training for image captioning
Steven J Rennie, Etienne Marcheret, Youssef Mroueh, Jerret Ross, and Vaib- hava Goel. Self-critical sequence training for image captioning. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7008–7024, 2017
2017
-
[37]
Knowing when to look: Adaptive attention via a visual sentinel for image captioning
Jiasen Lu, Caiming Xiong, Devi Parikh, and Richard Socher. Knowing when to look: Adaptive attention via a visual sentinel for image captioning. InPro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 375–383, 2017
2017
-
[38]
Bottom-up and top-down attention for image captioning and visual question answering
Peter Anderson, Xiaodong He, Chris Buehler, Damien Teney, Mark Johnson, Stephen Gould, and Lei Zhang. Bottom-up and top-down attention for image captioning and visual question answering. InProceedings of the IEEE Confer- ence on Computer Vision and Pattern Recognition, pages 6077–6086, 2018
2018
-
[39]
Dual-level collaborative transformer for image captioning
Yunpeng Luo, Jiayi Ji, Xiaoshuai Sun, Liujuan Cao, Yongjian Wu, Feiyue Huang, Chia-Wen Lin, and Rongrong Ji. Dual-level collaborative transformer for image captioning. InProceedings of the AAAI Conference on Artificial In- telligence, pages 2286–2293, 2021
2021
-
[40]
Dual global en- hanced transformer for image captioning
Tiantao Xian, Zhixin Li, Canlong Zhang, and Huifang Ma. Dual global en- hanced transformer for image captioning. InNeural Networks, volume 148, pages 129–141, 2022
2022
-
[41]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InProceedings of the European Conference on Computer Vision, pages 213–229, 2020
2020
-
[42]
Deformable detr: Deformable transformers for end-to-end object detection
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection. In Proceedings of International Conference of Learning Representations, 2021
2021
-
[43]
Microsoft coco: Common 111 objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ ar, and C Lawrence Zitnick. Microsoft coco: Common 111 objects in context. InProceedings of the European Conference on Computer Vision, pages 740–755. Springer, 2014
2014
-
[44]
Zirui Wang, Jiahui Yu, Adams Wei Yu, Zihang Dai, Yulia Tsvetkov, and Yuan Cao. Simvlm: Simple visual language model pretraining with weak supervision. InarXiv:2108.10904, 2021
-
[45]
Deep visual-semantic alignments for generating image descriptions
Andrej Karpathy and Li Fei-Fei. Deep visual-semantic alignments for generating image descriptions. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3128–3137, 2015
2015
-
[46]
In defense of grid features for visual question answering
Huaizu Jiang, Ishan Misra, Marcus Rohrbach, Erik Learned-Miller, and Xinlei Chen. In defense of grid features for visual question answering. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 10267–10276, 2020
2020
-
[47]
Rstnet: Captioning with adaptive attention on visual and non-visual words
Xuying Zhang, Xiaoshuai Sun, Yunpeng Luo, Jiayi Ji, Yiyi Zhou, Yongjian Wu, Feiyue Huang, and Rongrong Ji. Rstnet: Captioning with adaptive attention on visual and non-visual words. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 15465–15474, 2021
2021
-
[48]
You only look at one sequence: Rethinking trans- former in vision through object detection
Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, and Wenyu Liu. You only look at one sequence: Rethinking trans- former in vision through object detection. InAdvances in Neural Information Processing Systems, 2021
2021
-
[49]
Vidt: An efficient and effective fully transformer-based object detector
Hwanjun Song, Deqing Sun, Sanghyuk Chun, Varun Jampani, Dongyoon Han, Byeongho Heo, Wonjae Kim, and Ming-Hsuan Yang. Vidt: An efficient and effective fully transformer-based object detector. InarXiv:2110.03921, 2021
-
[50]
E2e-vlp: End-to-end vision-language pre-training enhanced by visual learning
Haiyang Xu, Ming Yan, Chenliang Li, Bin Bi, Songfang Huang, Wenming Xiao, and Fei Huang. E2e-vlp: End-to-end vision-language pre-training enhanced by visual learning. InarXiv:2106.01804, 2021
-
[51]
Learning to collocate neural mod- ules for image captioning
Xu Yang, Hanwang Zhang, and Jianfei Cai. Learning to collocate neural mod- ules for image captioning. InProceedings of the IEEE International Conference on Computer Vision, pages 4250–4260, 2019. 112
2019
-
[52]
Entangled transformer for image captioning
Guang Li, Linchao Zhu, Ping Liu, and Yi Yang. Entangled transformer for image captioning. InProceedings of the IEEE International Conference on Computer Vision, pages 8928–8937, 2019
2019
-
[53]
Attention on atten- tion for image captioning
Lun Huang, Wenmin Wang, Jie Chen, and Xiao-Yong Wei. Attention on atten- tion for image captioning. InProceedings of the IEEE International Conference on Computer Vision, pages 4634–4643, 2019
2019
-
[54]
X-linear attention networks for image captioning
Yingwei Pan, Ting Yao, Yehao Li, and Tao Mei. X-linear attention networks for image captioning. InProceedings of the IEEE International Conference on Computer Vision, pages 10971–10980, 2020
2020
-
[55]
Meshed-memory transformer for image captioning
Marcella Cornia, Matteo Stefanini, Lorenzo Baraldi, and Rita Cucchiara. Meshed-memory transformer for image captioning. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 10578–10587, 2020
2020
-
[56]
Image cap- tioning: Transforming objects into words
Simao Herdade, Armin Kappeler, Kofi Boakye, and Joao Soares. Image cap- tioning: Transforming objects into words. InAdvances in Neural Information Processing Systems, 2019
2019
-
[57]
Normalized and geometry-aware self-attention network for image captioning
Longteng Guo, Jing Liu, Xinxin Zhu, Peng Yao, Shichen Lu, and Hanqing Lu. Normalized and geometry-aware self-attention network for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion, pages 10327–10336, 2020
2020
-
[58]
Vinvl: Revisiting visual representations in vision-language models
Pengchuan Zhang, Xiujun Li, Xiaowei Hu, Jianwei Yang, Lei Zhang, Lijuan Wang, Yejin Choi, and Jianfeng Gao. Vinvl: Revisiting visual representations in vision-language models. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5579–5588, 2021
2021
-
[59]
Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations
Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A Shamma, Michael Bernstein, and Li Fei-Fei. Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations. InInternational Journal of Computer Vision, volume 123, pages 32–73, 2017. 113
2017
-
[60]
The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale
Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Uijlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, Tom Duerig, and Vittorio Ferrari. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. InInternational Journal of Computer Vision, ...
1956
-
[61]
Objects365: A large-scale, high-quality dataset for object detection
Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, and Jian Sun. Objects365: A large-scale, high-quality dataset for object detection. InProceedings of the IEEE International Conference on Computer Vision, pages 8430–8439, 2019
2019
-
[62]
nocaps: novel object captioning at scale
Harsh Agrawal, Karan Desai, Yufei Wang, Xinlei Chen, Rishabh Jain, Mark Johnson, Dhruv Batra, Devi Parikh, Stefan Lee, and Peter Anderson. nocaps: novel object captioning at scale. InProceedings of the IEEE International Conference on Computer Vision, pages 8948–8957, 2019
2019
-
[63]
Coco-stuff: Thing and stuff classes in context
Holger Caesar, Jasper Uijlings, and Vittorio Ferrari. Coco-stuff: Thing and stuff classes in context. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2018
2018
-
[64]
Karpathy/neuraltalk: Neuraltalk is a python+numpy project for learning multimodal recurrent neural networks that describe images with sen- tences
Karpathy. Karpathy/neuraltalk: Neuraltalk is a python+numpy project for learning multimodal recurrent neural networks that describe images with sen- tences
-
[65]
Artemis: Affective language for visual art
Panos Achlioptas, Maks Ovsjanikov, Kilichbek Haydarov, Mohamed Elhoseiny, and Leonidas J Guibas. Artemis: Affective language for visual art. InPro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 11569–11579, 2021
2021
-
[66]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the Annual Meeting of the Association for Computational Linguistics, pages 311–318, 2002. 114
2002
-
[67]
Meteor: An automatic metric for mt eval- uation with improved correlation with human judgments
Satanjeev Banerjee and Alon Lavie. Meteor: An automatic metric for mt eval- uation with improved correlation with human judgments. InProceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, pages 65–72, 2005
2005
-
[68]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, 2004
2004
-
[69]
Cider: Consensus-based image description evaluation
Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. Cider: Consensus-based image description evaluation. InProceedings of the IEEE Con- ference on Computer Vision and Pattern Recognition, pages 4566–4575, 2015
2015
-
[70]
Spice: Semantic propositional image caption evaluation
Peter Anderson, Basura Fernando, Mark Johnson, and Stephen Gould. Spice: Semantic propositional image caption evaluation. InProceedings of the Euro- pean Conference on Computer Vision, pages 382–398, 2016
2016
-
[71]
spaCy 2: Natural language understand- ing with Bloom embeddings, convolutional neural networks and incremental parsing
Matthew Honnibal and Ines Montani. spaCy 2: Natural language understand- ing with Bloom embeddings, convolutional neural networks and incremental parsing. To appear, 2017
2017
-
[72]
Adam: A Method for Stochastic Optimiza- tion
Diederik P Kingma and Jimmy Ba. Adam: A Method for Stochastic Optimiza- tion. InProceedings of International Conference on Representation Learning, 2015
2015
-
[73]
Unified vision-language pre-training for image captioning and vqa
Luowei Zhou, Hamid Palangi, Lei Zhang, Houdong Hu, Jason Corso, and Jian- feng Gao. Unified vision-language pre-training for image captioning and vqa. InProceedings of the AAAI Conference on Artificial Intelligence, pages 13041– 13049, 2020
2020
-
[74]
Oscar: Object-semantics aligned pre-training for vision-language tasks
Xiujun Li, Xi Yin, Chunyuan Li, Pengchuan Zhang, Xiaowei Hu, Lei Zhang, Lijuan Wang, Houdong Hu, Li Dong, Furu Wei, et al. Oscar: Object-semantics aligned pre-training for vision-language tasks. InProceedings of the European Conference on Computer Vision, pages 121–137, 2020
2020
-
[75]
Boosting image captioning with attributes
Ting Yao, Yingwei Pan, Yehao Li, Zhaofan Qiu, and Tao Mei. Boosting image captioning with attributes. InProceedings of the IEEE International Conference on Computer Vision, pages 4894–4902, 2017. 115
2017
-
[76]
Reflective de- coding network for image captioning
Lei Ke, Wenjie Pei, Ruiyu Li, Xiaoyong Shen, and Yu-Wing Tai. Reflective de- coding network for image captioning. InProceedings of the IEEE International Conference on Computer Vision, pages 8888–8897, 2019
2019
-
[77]
Exploring visual relationship for image captioning
Ting Yao, Yingwei Pan, Yehao Li, and Tao Mei. Exploring visual relationship for image captioning. InProceedings of the European Conference on Computer Vision, pages 684–699, 2018
2018
-
[78]
Look back and pre- dict forward in image captioning
Yu Qin, Jiajun Du, Yonghua Zhang, and Hongtao Lu. Look back and pre- dict forward in image captioning. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8367–8375, 2019
2019
-
[79]
Auto-encoding scene graphs for image captioning
Xu Yang, Kaihua Tang, Hanwang Zhang, and Jianfei Cai. Auto-encoding scene graphs for image captioning. InProceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition, pages 10685–10694, 2019
2019
-
[80]
Improving image captioning by leveraging intra- and inter-layer global representation in transformer network
Jiayi Ji, Yunpeng Luo, Xiaoshuai Sun, Fuhai Chen, Gen Luo, Yongjian Wu, Yue Gao, and Rongrong Ji. Improving image captioning by leveraging intra- and inter-layer global representation in transformer network. InProceedings of the AAAI Conference on Artificial Intelligence, pages 1655–1663, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.