Batch Normalization Amplifies Memorization and Privacy Risks
Pith reviewed 2026-06-30 14:12 UTC · model grok-4.3
The pith
Batch normalization makes deep neural networks memorize outlier samples more, leading to increased privacy leakage through membership inference attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
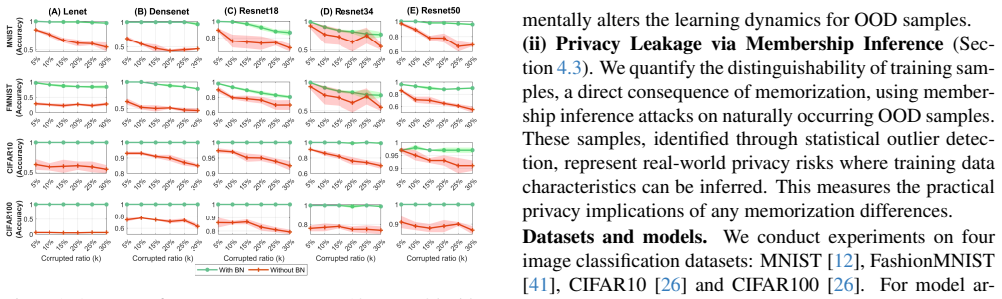
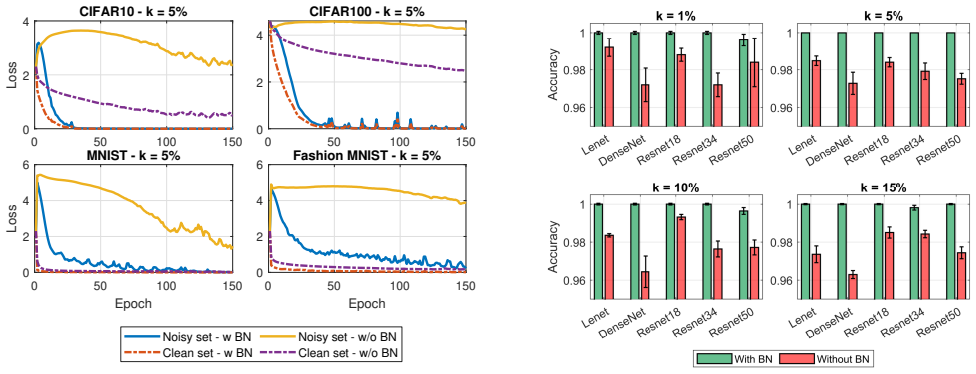
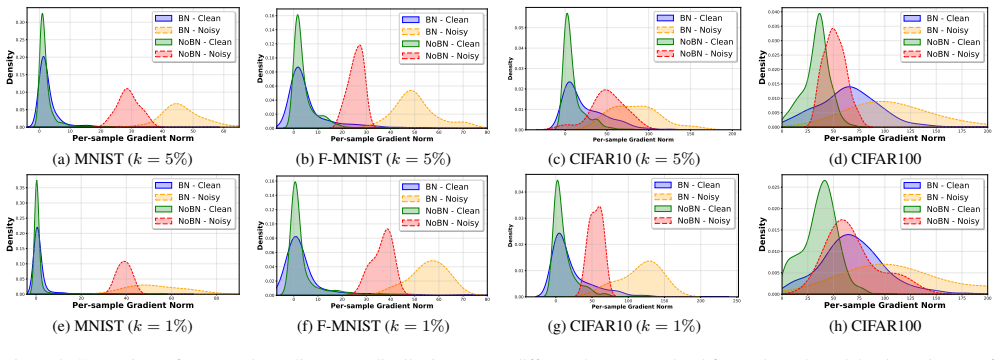
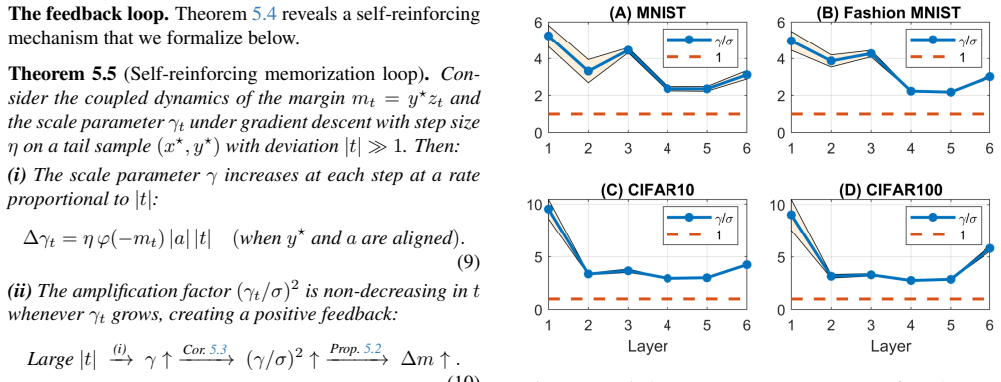
Batch Normalization amplifies the per-step influence of outlier samples during training, resulting in substantially higher memorization of such samples and greater susceptibility to membership inference attacks. This is shown consistently across datasets and architectures, with theoretical analysis confirming the mechanism of increased influence.
What carries the argument
Amplification of per-step gradient influence of outlier samples by batch normalization layers.
If this is right
- Models trained with batch normalization will exhibit higher rates of unintended memorization of out-of-distribution samples.
- Membership inference attacks will succeed more often against models that use batch normalization.
- The theoretical mechanism of influence amplification provides a way to understand and potentially mitigate the effect.
- Practical training choices involving normalization layers carry privacy implications.
- Removing batch normalization can reduce privacy vulnerabilities in some settings.
Where Pith is reading between the lines
- Alternative normalization techniques might be explored to achieve similar training benefits with lower privacy costs.
- The effect could compound with other factors like dataset size or model capacity in large-scale training.
- Privacy-preserving methods such as differential privacy might need adjustment when batch normalization is used.
- Developers of models for sensitive applications should test for this amplified memorization risk specifically.
Load-bearing premise
The increase in memorization and privacy risks from batch normalization will generalize beyond the specific datasets, architectures, and attack methods used in the experiments.
What would settle it
Finding a dataset and architecture where adding batch normalization does not increase the success rate of membership inference attacks on outlier samples.
Figures



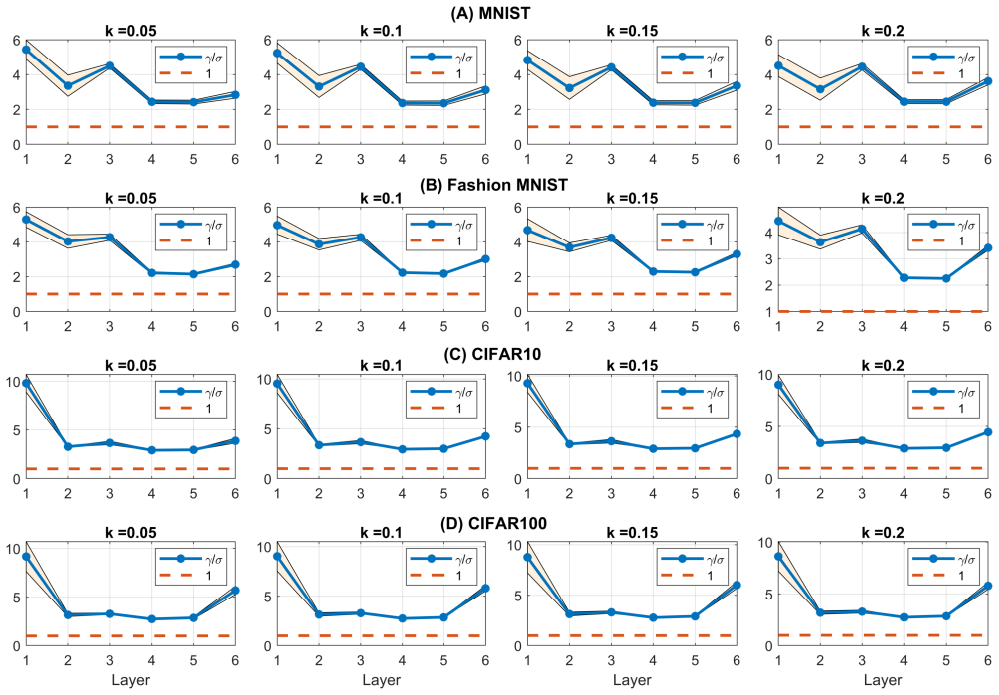
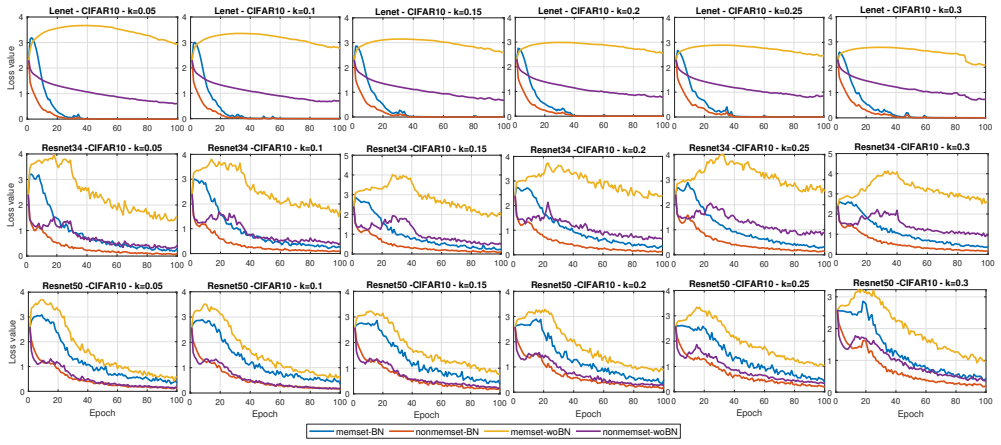
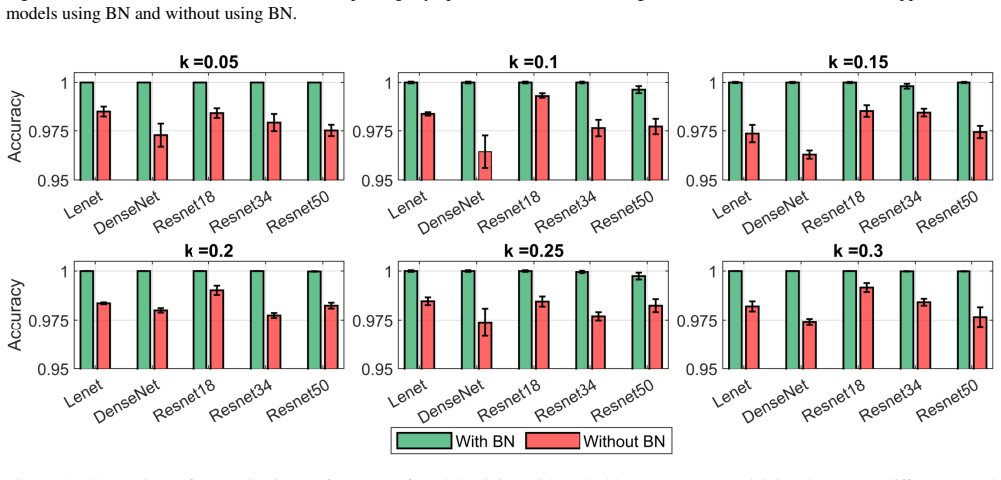

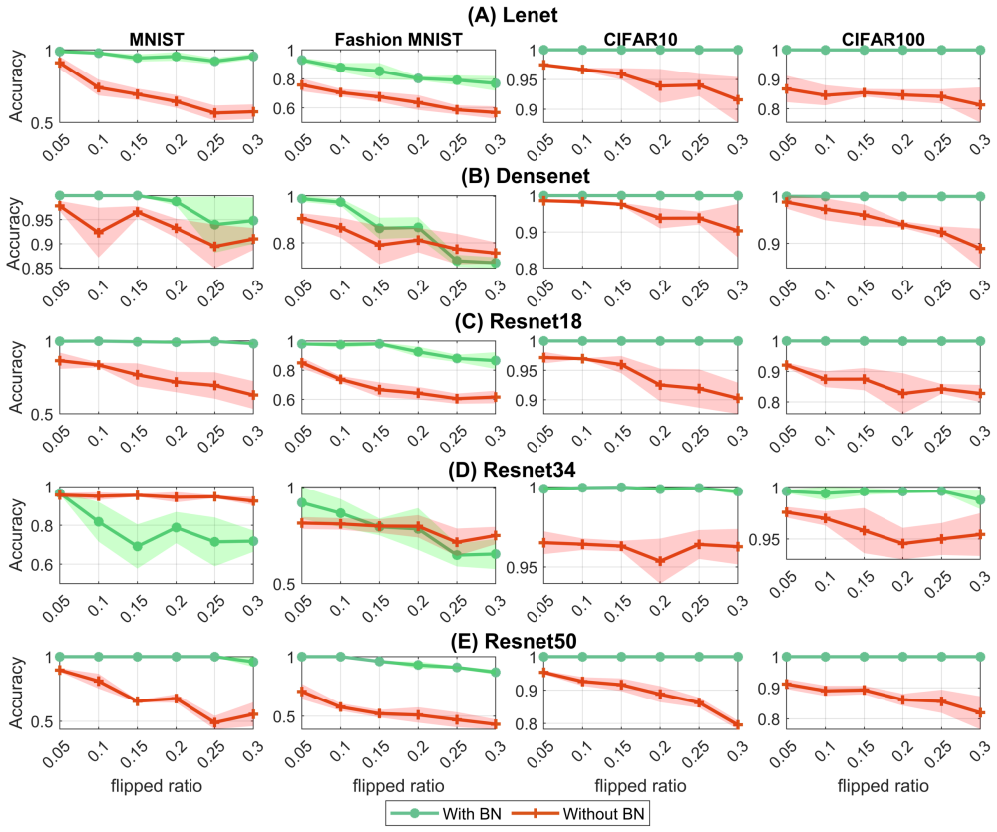
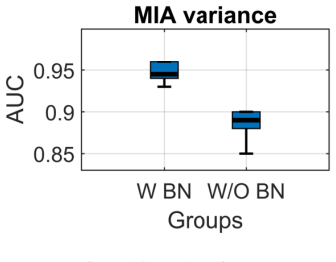


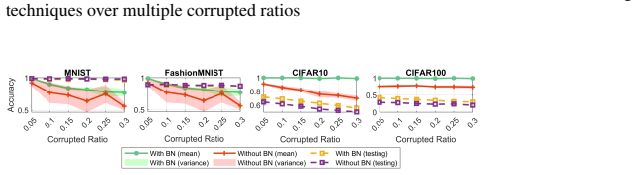
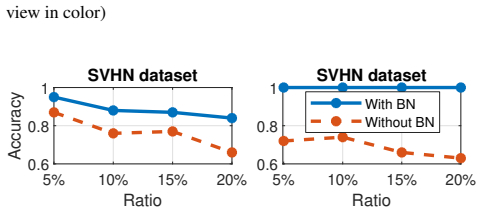
read the original abstract
Batch Normalization (BN) is widely adopted to enable faster convergence and more stable training of deep neural networks. However, its impact on privacy and memorization has remained largely unexplored. In this work, we investigate the effect of BN layers on the memorization of atypical or outlier samples and its implications for privacy leakage. We conduct an extensive empirical study using three complementary approaches: (i) unintended memorization of out-of-distribution training samples, (ii) per-sample influence measured via gradient norms, and (iii) susceptibility to membership inference attacks (MIA). Across multiple datasets and architectures, we consistently observe that BN substantially increases the memorization of outliers compared to models without BN. Critically, this amplified memorization translates directly into privacy vulnerabilities: models with BN exhibit significantly higher susceptibility to MIAs. We complement our empirical findings with a theoretical analysis showing that BN amplifies the per-step influence of outlier samples during training, providing mechanistic insight into this phenomenon. Our results highlight an underappreciated privacy risk associated with BN and provide both practical and theoretical insights into how normalization layers can amplify the influence of rare or sensitive training examples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Batch Normalization (BN) substantially increases memorization of outlier samples in deep neural networks relative to non-BN models, directly elevating privacy risks via higher membership inference attack (MIA) success rates. This is supported by an extensive empirical study across multiple datasets and architectures using three complementary methods—unintended memorization of out-of-distribution samples, per-sample influence via gradient norms, and MIA susceptibility—plus a theoretical analysis demonstrating that BN amplifies the per-step influence of outliers during training.
Significance. If the central attribution to BN holds after controlling for training dynamics, the result would be significant: it identifies a concrete privacy risk in a ubiquitous training component and supplies both multi-method empirical evidence and a mechanistic explanation. Such a finding could influence normalization choices in privacy-sensitive applications and motivate further study of how architectural choices interact with memorization.
major comments (1)
- [Empirical Study] The BN versus non-BN comparisons (empirical study section) do not report whether the two conditions were trained to matched final test accuracy, training loss, or effective convergence. Because BN typically accelerates and stabilizes optimization, non-BN models trained for a fixed epoch count or with identical hyperparameters may simply remain under-optimized; this alone can alter gradient norms and membership signals, undermining the claim that observed differences are attributable to BN rather than optimization trajectory.
minor comments (1)
- [Abstract] The abstract and introduction would benefit from an explicit statement of the precise datasets, architectures, and hyperparameter-matching protocol used, to allow immediate assessment of scope and controls.
Simulated Author's Rebuttal
We thank the referee for highlighting this important methodological consideration in our empirical comparisons. We address the concern directly below.
read point-by-point responses
-
Referee: [Empirical Study] The BN versus non-BN comparisons (empirical study section) do not report whether the two conditions were trained to matched final test accuracy, training loss, or effective convergence. Because BN typically accelerates and stabilizes optimization, non-BN models trained for a fixed epoch count or with identical hyperparameters may simply remain under-optimized; this alone can alter gradient norms and membership signals, undermining the claim that observed differences are attributable to BN rather than optimization trajectory.
Authors: We agree this is a valid concern and a potential confound. The experiments in the current manuscript trained both BN and non-BN models for the same fixed number of epochs using identical hyperparameters (as is common practice), without explicitly matching final test accuracy or training loss. To isolate the effect of BN from optimization trajectory differences, we will revise the manuscript to include additional experiments in which non-BN models are trained for more epochs until their test accuracy matches the BN models. We will then re-evaluate gradient norms and MIA success rates under these matched conditions and report the results. If the amplified memorization effect persists, this will strengthen the attribution to BN; if not, we will qualify the claims accordingly. revision: yes
Circularity Check
No significant circularity; empirical and theoretical components are independent
full rationale
The paper reports empirical measurements of outlier memorization, gradient norms, and MIA success rates across datasets/architectures, plus a separate theoretical analysis of per-step influence amplification by BN. No equations, fitted parameters, or self-citations are shown reducing the central claim to a definitional identity or prior author result. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: ICML
Arpit, D., Jastrzebski, S., Ballas, N., Krueger, D., Bengio, E., Kanwal, A., Maharaj, T., Fischer, A., Courville, A., Bengio, Y ., et al.: A closer look at memorization in deep networks. In: ICML. pp. 233–242 (2017) 2
2017
-
[2]
NeurIPS34, 10876– 10889 (2021) 8
Baldock, R., Maennel, H., Neyshabur, B.: Deep learning through the lens of example difficulty. NeurIPS34, 10876– 10889 (2021) 8
2021
-
[3]
In: W ACV
Benz, P., Zhang, C., Karjauv, A., Kweon, I.S.: Revisiting batch normalization for improving corruption robustness. In: W ACV . pp. 494–503 (2021) 8
2021
-
[4]
In: CVPR
Benz, P., Zhang, C., Kweon, I.S.: Batch normalization in- creases adversarial vulnerability and decreases adversarial transferability: A non-robust feature perspective. In: CVPR. pp. 7818–7827 (2021) 8
2021
-
[5]
NeurIPS31(2018) 1, 8
Bjorck, N., Gomes, C.P., Selman, B., Weinberger, K.Q.: Un- derstanding batch normalization. NeurIPS31(2018) 1, 8
2018
-
[6]
Carlini, N., Chien, S., Nasr, M., Song, S., Terzis, A., Tramer, F.: Membership inference attacks from first principles. In: SP. pp. 1897–1914 (2022) 1, 2, 5
1914
-
[7]
USENIX (2023) 1, 2
Carlini, N., Hayes, J., Nasr, M., Jagielski, M., Choquette- Choo, C.A., Balle, B., Tramer, F., Wallace, E., Song, D., et al.: Extracting training data from diffusion models. USENIX (2023) 1, 2
2023
-
[8]
NeurIPS35, 13263–13276 (2022) 2, 5
Carlini, N., Jagielski, M., Zhang, C., Papernot, N., Terzis, 8 A., Tramer, F.: The privacy onion effect: Memorization is relative. NeurIPS35, 13263–13276 (2022) 2, 5
2022
-
[9]
In: USENIX
Carlini, N., Liu, C., Kos, J., Erlingsson, ´U., Song, D.: The secret sharer: Evaluating and testing unintended memoriza- tion in neural networks. In: USENIX. pp. 267–284 (2019) 1, 2, 3
2019
-
[10]
In: NeurIPS
Carlini, N., Terzis, A., Jagielski, M., Tramer, F., Papernot, N., Zhang, C.: The privacy onion effect: memorization is relative. In: NeurIPS. NIPS ’22, Red Hook, NY , USA (2022) 1
2022
-
[11]
In: USENIX
Carlini, N., Tramer, F., Wallace, E., Jagielski, M., Herbert- V oss, A., Lee, K., Roberts, A., Brown, T., Song, D., Erlings- son, U., et al.: Extracting training data from large language models. In: USENIX. pp. 2633–2650 (2021) 5
2021
-
[12]
SPM29(6), 141–142 (2012) 3
Deng, L.: The mnist database of handwritten digit images for machine learning research. SPM29(6), 141–142 (2012) 3
2012
-
[13]
Doshi, D., Das, A., He, T., Gromov, A.: To grok or not to grok: Disentangling generalization and memorization on corrupted algorithmic datasets (2024),https://arxiv. org/abs/2310.130618
-
[14]
In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H
Feldman, V ., Zhang, C.: What neural networks memorize and why: Discovering the long tail via influence estimation. In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H. (eds.) NeurIPS. vol. 33, pp. 2881–2891 (2020) 1, 2, 4, 7
2020
-
[15]
NeurIPS33, 2881–2891 (2020) 2, 3
Feldman, V ., Zhang, C.: What neural networks memorize and why: Discovering the long tail via influence estimation. NeurIPS33, 2881–2891 (2020) 2, 3
2020
-
[16]
Batch Normalization is a Cause of Adversarial Vulnerability
Galloway, A., Golubeva, A., Tanay, T., Moussa, M., Taylor, G.W.: Batch normalization is a cause of adversarial vulnera- bility. arXiv preprint arXiv:1905.02161 (2019) 8
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[17]
NeurIPS36, 697–738 (2023) 8
Ghose, A., Gupta, A., Yu, Y ., Poupart, P.: Batchnorm allows unsupervised radial attacks. NeurIPS36, 697–738 (2023) 8
2023
-
[18]
In: CVPR
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR. pp. 770–778 (2016) 3
2016
-
[19]
NeurIPS37, 88236– 88278 (2024) 8
Hintersdorf, D., Struppek, L., Kersting, K., Dziedzic, A., Boenisch, F.: Finding nemo: Localizing neurons responsible for memorization in diffusion models. NeurIPS37, 88236– 88278 (2024) 8
2024
-
[20]
Neural Com- put.9(1), 1–42 (1997) 8
Hochreiter, S., Schmidhuber, J.: Flat minima. Neural Com- put.9(1), 1–42 (1997) 8
1997
-
[21]
In: CVPR
Huang, G., Liu, Z., Van Der Maaten, L., Weinberger, K.Q.: Densely connected convolutional networks. In: CVPR. pp. 4700–4708 (2017) 3
2017
-
[22]
In: ICLR
Ioffe, S., Szegedy, C.: Batch normalization: Accelerating deep network training by reducing internal covariate shift. In: ICLR. pp. 448–456 (2015) 1, 2, 8
2015
-
[23]
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
Keskar, N.S., Mudigere, D., Nocedal, J., Smelyanskiy, M., Tang, P.T.P.: On large-batch training for deep learn- ing: Generalization gap and sharp minima. arXiv preprint arXiv:1609.04836 (2016) 8
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[24]
In: ICML
Koh, P.W., Liang, P.: Understanding black-box predictions via influence functions. In: ICML. pp. 1885–1894. PMLR (2017) 4
2017
-
[25]
Kong, F., Liu, F., Xu, K., et al.: Why does batch normaliza- tion induce the model vulnerability on adversarial images? WWW26, 1073–1091 (2023) 1
2023
-
[26]
Krizhevsky, A., Hinton, G., et al.: Learning multiple layers of features from tiny images (2009) 3
2009
-
[27]
LeCun, Y ., Bottou, L., Bengio, Y ., Haffner, P.: Gradient- based learning applied to document recognition. Proc. IEEE 86(11), 2278–2324 (2002) 3
2002
-
[28]
NeurIPS35, 34689–34708 (2022) 1, 8
Lyu, K., Li, Z., Arora, S.: Understanding the generaliza- tion benefit of normalization layers: Sharpness reduction. NeurIPS35, 34689–34708 (2022) 1, 8
2022
- [29]
-
[30]
Conference on Empirical Methods in Natural Language Processing (2022)
Mireshghallah, F., Goyal, K., Uniyal, A., Berg-Kirkpatrick, T., Shokri, R.: Quantifying privacy risks of masked language models using membership inference attacks. arXiv preprint arXiv:2203.03929 (2022) 5
-
[31]
arXiv preprint arXiv:2105.13929 (2021) 8
Mo, F., Borovykh, A., Malekzadeh, M., Haddadi, H., Demetriou, S.: Quantifying information leakage from gra- dients. arXiv preprint arXiv:2105.13929 (2021) 8
-
[32]
NeurIPS30 (2017) 8
Neyshabur, B., Bhojanapalli, S., McAllester, D., Srebro, N.: Exploring generalization in deep learning. NeurIPS30 (2017) 8
2017
-
[33]
Santurkar, S., Tsipras, D., Ilyas, A., Madry, A.: How does batch normalization help optimization? NeurIPS31(2018) 1, 6, 7, 8
2018
-
[34]
Shokri, R., Stronati, M., Song, C., Shmatikov, V .: Member- ship inference attacks against machine learning models. In: SP. pp. 3–18. IEEE (2017) 1, 2
2017
-
[35]
In: USENIX
Song, C., Shokri, R.: Systematic evaluation of privacy risks of machine learning models. In: USENIX. pp. 2615–2632 (2021) 2
2021
-
[36]
arXiv preprint arXiv:2105.14602 (2021) 8
Stephenson, C., Padhy, S., Ganesh, A., Hui, Y ., Tang, H., Chung, S.: On the geometry of generalization and memorization in deep neural networks. arXiv preprint arXiv:2105.14602 (2021) 8
-
[37]
NeurIPS35, 38274– 38290 (2022) 3
Tirumala, K., Markosyan, A., Zettlemoyer, L., Aghajanyan, A.: Memorization without overfitting: Analyzing the train- ing dynamics of large language models. NeurIPS35, 38274– 38290 (2022) 3
2022
-
[38]
In: ICML
Wang, H., Zhang, A., Zheng, S., Shi, X., Li, M., Wang, Z.: Removing batch normalization boosts adversarial training. In: ICML. pp. 23433–23445. PMLR (2022) 1, 8
2022
-
[39]
NeurIPS37, 60475–60516 (2024) 8
Wang, W., Dziedzic, A., Backes, M., Boenisch, F.: Lo- calizing memorization in ssl vision encoders. NeurIPS37, 60475–60516 (2024) 8
2024
-
[40]
In: AISTATS
Wongso, S., Ghosh, R., Motani, M.: Using sliced mutual in- formation to study memorization and generalization in deep neural networks. In: AISTATS. pp. 11608–11629. PMLR (2023) 8
2023
-
[41]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Xiao, H., Rasul, K., V ollgraf, R.: Fashion-mnist: a novel im- age dataset for benchmarking machine learning algorithms. arXiv preprint arXiv:1708.07747 (2017) 3
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
In: ICLR (2020) 8
Xie, C., Yuille, A.: Intriguing properties of adversarial train- ing at scale. In: ICLR (2020) 8
2020
-
[43]
In: Big Data
Yao, Z., Gholami, A., Keutzer, K., Mahoney, M.W.: Pyhes- sian: Neural networks through the lens of the hessian. In: Big Data. pp. 581–590 (2020) 1 9
2020
-
[44]
In: ICTAI
Zhang, B., Ma, S.: Achieving both model accuracy and ro- bustness by adversarial training with batch norm shaping. In: ICTAI. pp. 591–598. IEEE (2022) 1, 8
2022
-
[45]
Understanding deep learning requires rethinking generalization
Zhang, C., Bengio, S., Hardt, M., Recht, B., Vinyals, O.: Un- derstanding deep learning requires rethinking generalization. arXiv preprint arXiv:1611.03530 (2016) 3
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[46]
In: ICLR (2017) 2
Zhang, C., Bengio, S., Hardt, M., Recht, B., Vinyals, O.: Un- derstanding deep learning requires rethinking generalization. In: ICLR (2017) 2
2017
-
[47]
NeurIPS36, 39321–39362 (2023) 3 Contents A
Zhang, C., Ippolito, D., Lee, K., Jagielski, M., Tram `er, F., Carlini, N.: Counterfactual memorization in neural language models. NeurIPS36, 39321–39362 (2023) 3 Contents A . Theory extended 10 A.1 . Theory proofs . . . . . . . . . . . . . . . . . 10 A.2 . Theoretical Analysis for Memorization Ac- celeration . . . . . . . . . . . . . . . . . . 11 A.3 . T...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.