A Controlled Synthetic Benchmark for Educational Aspect-Based Sentiment Analysis
Pith reviewed 2026-06-29 21:53 UTC · model grok-4.3
The pith
A controlled synthetic corpus of 10,000 course reviews supplies a reproducible benchmark for educational aspect-based sentiment analysis where public labeled data is scarce.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
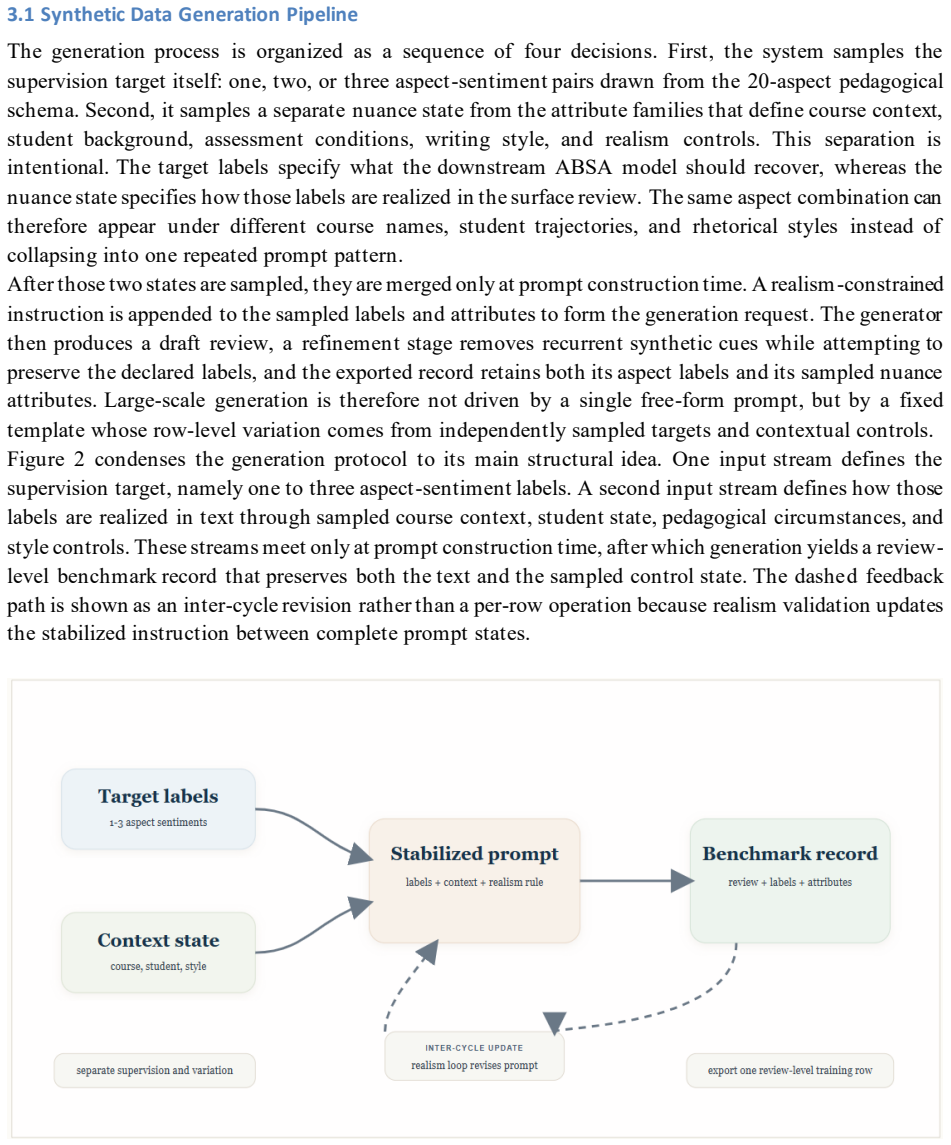
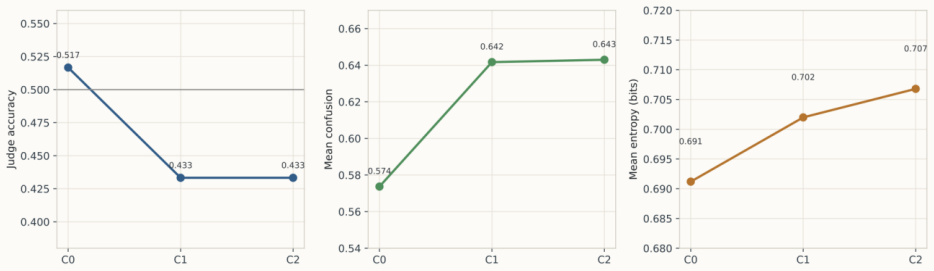
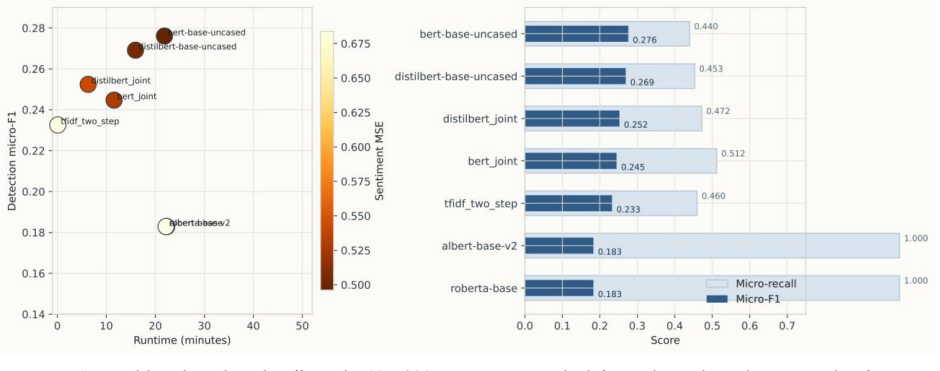
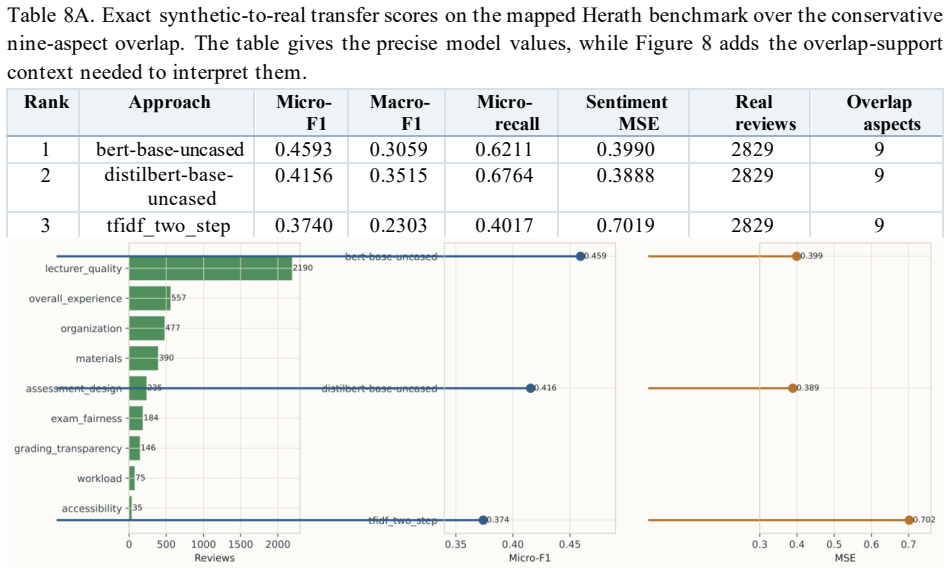
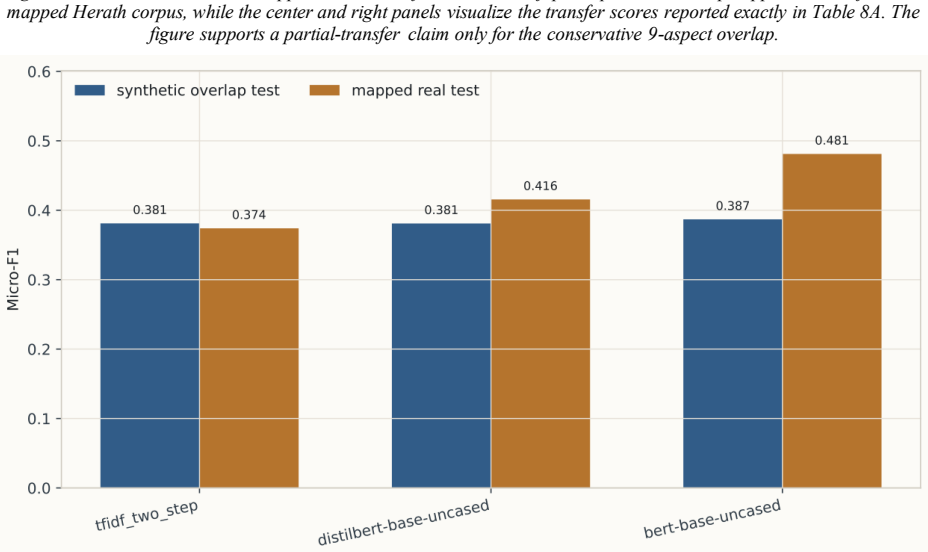
By sampling target aspect labels together with nuance attributes and then applying a three-cycle judge-editor procedure to refine the generation prompt, the authors produce a 10,000-review corpus whose explicit splits and 20-aspect schema allow controlled evaluation of educational ABSA; on this benchmark the strongest local model reaches 0.2930 micro-F1 while zero-shot large-language-model inference reaches 0.2519 micro-F1, and the same model achieves 0.4593 micro-F1 on a 9-aspect overlap with real student reviews, indicating partial synthetic-to-real transfer.
What carries the argument
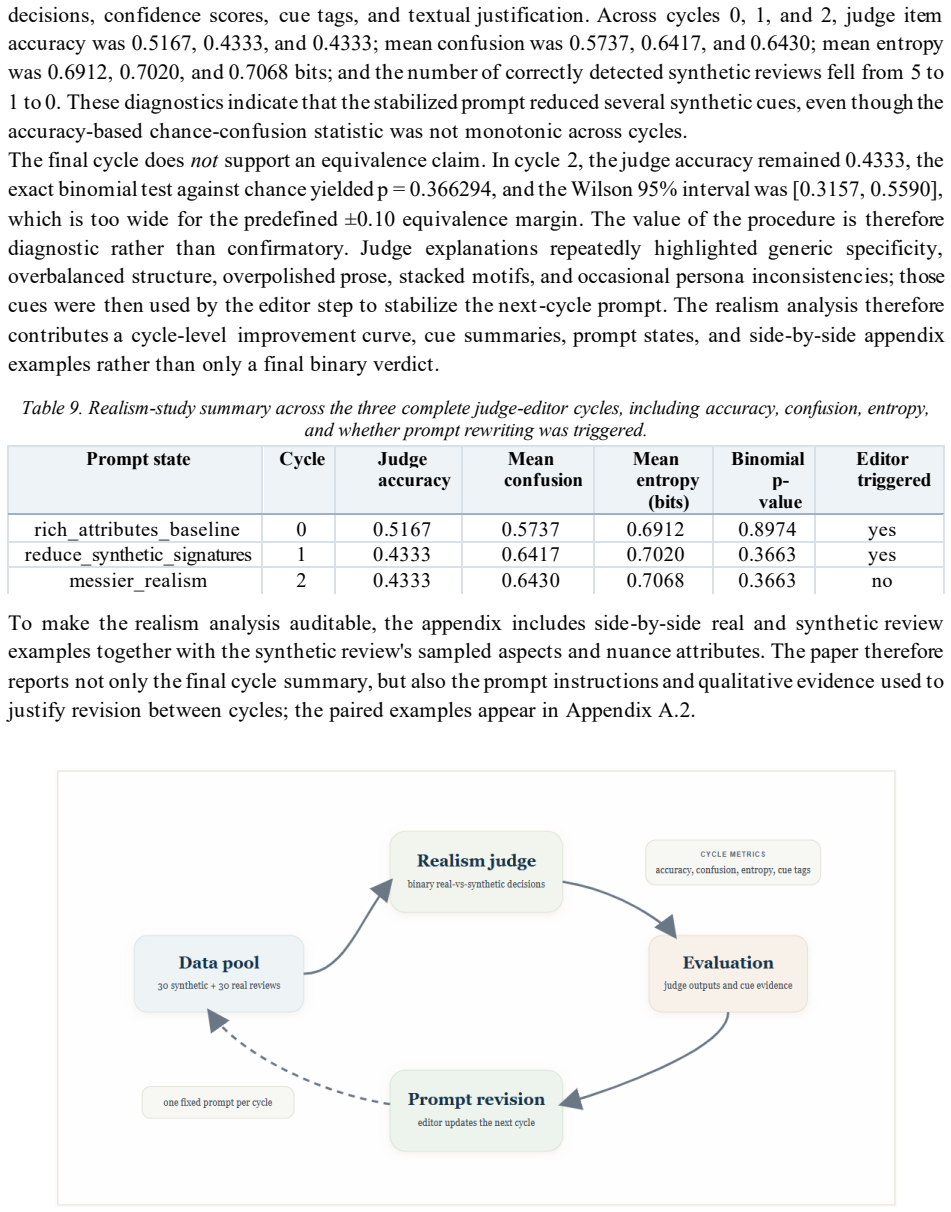
The three-cycle judge-editor prompt refinement procedure that iteratively stabilizes generation of reviews whose aspect labels and nuance attributes match the intended pedagogical schema.
If this is right
- BERT trained on the synthetic data reaches 0.2930 micro-F1 on held-out synthetic reviews and 0.4593 micro-F1 on overlapping real reviews.
- GPT-5.2 zero-shot inference reaches 0.2519 micro-F1, placing large-model batch inference close to compact joint encoders.
- The 20-aspect schema and fixed train-validation-test splits enable direct comparison of TF-IDF, two-step transformer, and joint-encoder approaches.
- Realism and faithfulness diagnostics quantify remaining label noise after prompt stabilization.
- The corpus supplies the first public, aspect-labeled resource for educational ABSA.
Where Pith is reading between the lines
- The same sampling-plus-refinement loop could be reused to create benchmarks for other domains where labeled feedback is institutionally restricted.
- Targeted adjustments to the judge-editor cycle could be tested to reduce the observed gap between synthetic and real performance.
- The benchmark could serve as a controlled testbed for methods that adapt models across the synthetic-to-real distribution shift without additional real annotations.
Load-bearing premise
The labels and text distributions produced by the three-cycle refinement are close enough to real educational reviews that models trained on the synthetic corpus will transfer meaningfully to authentic student feedback.
What would settle it
Models trained only on the synthetic corpus achieve no better than random performance when evaluated on held-out authentic student reviews that use the same 20-aspect schema.
Figures



read the original abstract
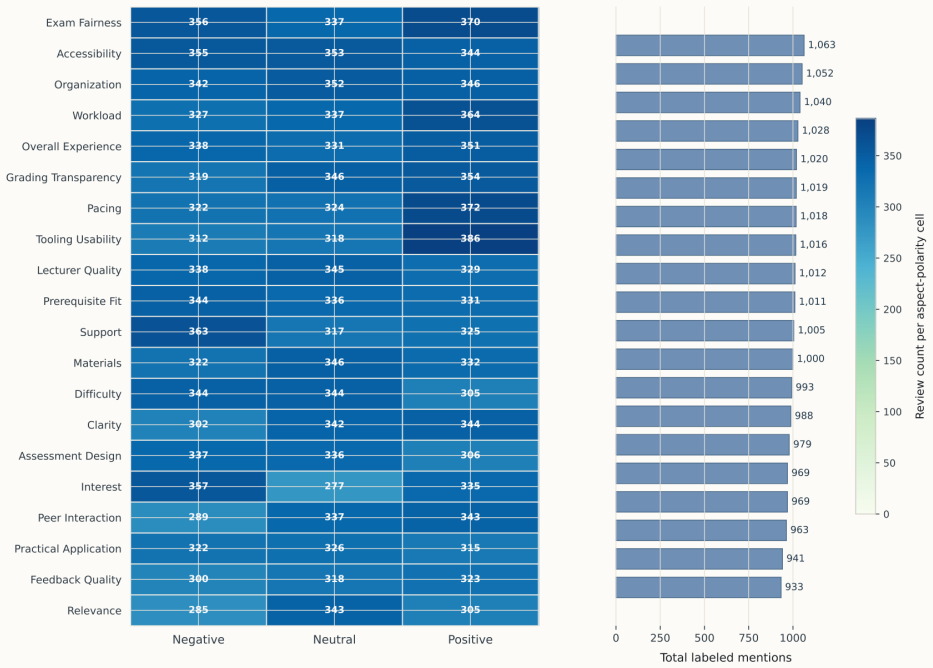
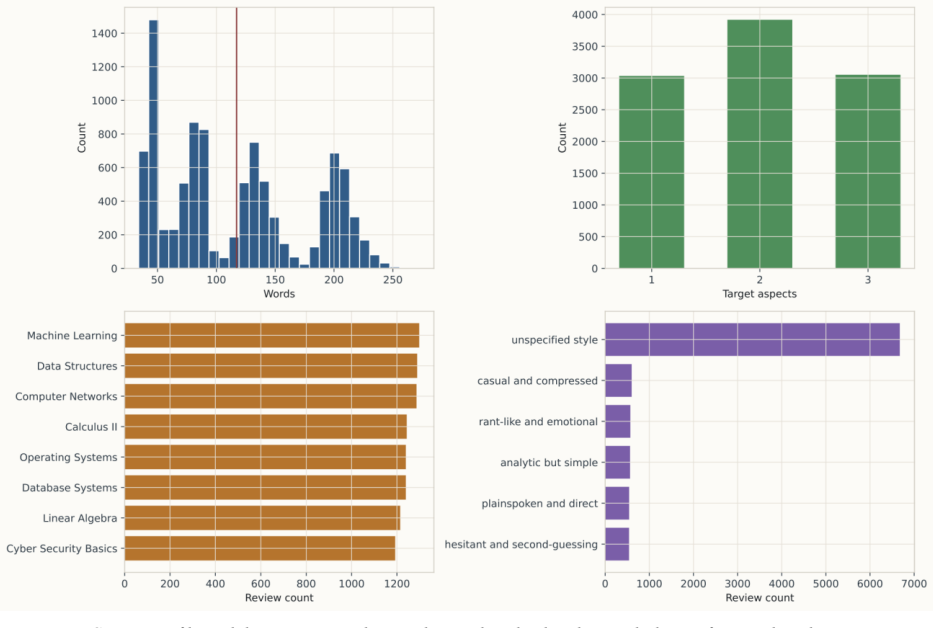
Educational aspect-based sentiment analysis (ABSA) can support course improvement, but public aspect-labeled student feedback remains scarce because educational reviews are private, institution-specific, and expensive to annotate. This study introduces a controlled synthetic benchmark for educational ABSA built from 10,000 synthetic course reviews with explicit train-validation-test splits and a 20-aspect pedagogical schema spanning instructional quality, assessment and course management, learning demand, learning environment, and engagement. The corpus is generated with sampled target labels, sampled nuance attributes, and a realism-tuned prompt refined through a three-cycle judge-editor procedure. On the resulting benchmark, local baselines with TF-IDF, two-step transformers, and joint encoders show that the task is nontrivial; the strongest untuned model, BERT, reaches a held-out detection micro-F1 of 0.2760, while a modest lower-rate BERT schedule improves this to 0.2930. Full-test GPT-based inference with gpt-5.2 reaches 0.2519 micro-F1 in zero-shot mode and 0.2501 with retrieval-based few-shot prompting, placing batch inference above the classical baseline and close to the compact joint encoders. A conservative external evaluation on 2,829 mapped student-feedback reviews from Herath et al. yields a micro-F1 of 0.4593 for BERT on a 9-aspect overlap, indicating partial synthetic-to-real transfer. Realism and faithfulness analyses are reported as generator diagnostics that clarify how the benchmark was stabilized and where label noise remains. The study therefore contributes a synthetic educational ABSA corpus, a documented generation procedure, and a reproducible benchmark setting for a domain in which public labeled data remain difficult to obtain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a controlled synthetic benchmark for educational aspect-based sentiment analysis consisting of 10,000 generated course reviews with explicit train-validation-test splits and a 20-aspect pedagogical schema covering instructional quality, assessment, learning demand, environment, and engagement. Reviews are produced by sampling target labels and nuance attributes followed by a three-cycle judge-editor prompt refinement; the work reports that the task is nontrivial, with BERT reaching 0.2930 micro-F1 on held-out synthetic data (improved from 0.2760), GPT-5.2 achieving 0.2519 zero-shot, and BERT obtaining 0.4593 micro-F1 on a 9-aspect overlap with mapped real student reviews from Herath et al., together with generator realism and faithfulness diagnostics.
Significance. If the synthetic corpus and its diagnostics establish sufficient distributional similarity to authentic educational feedback, the benchmark supplies a much-needed public resource in a domain where labeled student reviews are scarce due to privacy and annotation costs. The explicit splits, documented generation procedure, baseline comparisons, and conservative external mapping evaluation constitute concrete strengths that can support reproducible research on ABSA for course improvement; the modest F1 scores correctly signal that the task remains challenging rather than artificially easy.
major comments (1)
- [External Evaluation] External Evaluation section: the 0.4593 micro-F1 result on the 9-aspect overlap with Herath et al. is load-bearing for the partial-transfer claim, yet the manuscript provides no explicit mapping table or decision rules showing how the 20-aspect schema was reduced and aligned to the real-data aspects (including sentiment polarity correspondence); without this, it is impossible to rule out that the reported score partly reflects mapping artifacts rather than genuine synthetic-to-real generalization.
minor comments (3)
- [§3] §3 (Generation Procedure): the three-cycle judge-editor refinement is described at a high level, but the exact judge criteria, acceptance thresholds, and quantitative faithfulness metrics (e.g., label-noise rates per aspect) are not tabulated, reducing the ability of readers to replicate or extend the control parameters.
- [Abstract] Abstract and §4: model names such as 'gpt-5.2' and 'lower-rate BERT schedule' should be accompanied by precise version identifiers or hyper-parameter settings in a table so that the 0.2519 and 0.2930 numbers can be reproduced exactly.
- [Aspect Schema] Table of aspects: adding one or two illustrative synthetic review snippets per aspect would help readers judge whether the 20-aspect schema captures pedagogically meaningful distinctions without excessive overlap.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the recommendation of minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [External Evaluation] External Evaluation section: the 0.4593 micro-F1 result on the 9-aspect overlap with Herath et al. is load-bearing for the partial-transfer claim, yet the manuscript provides no explicit mapping table or decision rules showing how the 20-aspect schema was reduced and aligned to the real-data aspects (including sentiment polarity correspondence); without this, it is impossible to rule out that the reported score partly reflects mapping artifacts rather than genuine synthetic-to-real generalization.
Authors: We agree that the absence of an explicit mapping table weakens the external evaluation. The 9-aspect overlap was obtained by manual semantic alignment of our pedagogical schema to the aspects reported in Herath et al., with polarity labels preserved where possible; however, the decision rules and correspondence table were omitted from the manuscript. We will add a dedicated table (and accompanying paragraph) in the revised External Evaluation section that enumerates (i) the 9 retained aspects, (ii) the source aspect(s) from the 20-aspect schema that were merged or mapped to each, (iii) the explicit reduction rules, and (iv) the polarity correspondence. This addition will make the mapping fully reproducible and allow readers to judge potential artifacts. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper is a data-generation and baseline-evaluation study that constructs a synthetic corpus via prompt-based sampling and a documented three-cycle judge-editor refinement, then reports empirical micro-F1 scores on held-out splits and on a mapped external real-review set. No derivation chain, equations, fitted parameters, or first-principles predictions exist that could reduce to inputs by construction; the transfer claim rests on the external Herath et al. mapping and the reported realism diagnostics rather than any internal self-definition or self-citation load-bearing step.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The sampled target labels and nuance attributes combined with the refined prompt yield text whose aspect-sentiment distribution approximates real educational reviews.
Reference graph
Works this paper leans on
-
[1]
Gikandi, D
J.W. Gikandi, D. Morrow, and N.E. Davis. 2011. Online formative assessment in higher education: A review of the literature . Computers & Education, 57(4), 2333-2351
2011
-
[2]
Maria Pontiki, Haris Papageorgiou, Dimitrios Galanis, Ion Androutsopoulos, John Pavlopoulos, and Suresh Manandhar. 2014. SemEval-2014 Task 4: Aspect Based Sentiment Analysis . Proceedings of the 8th International Workshop on Semantic Evaluation, pages 27 -35
2014
-
[3]
Maria Pontiki, Dimitris Galanis, Haris Papageorgiou, Ion Androutsopoulos, Suresh Manandhar, Mohammad AL -Smadi, Mahmoud Al -Ayyoub, Yanyan Zhao, Bing Qin, Orphée De Clercq, Véronique Hoste, Marianna Apidianaki, Xavier Tannier, Natalia Loukachevitch, Evgeniy Kotelnikov, Nuria Bel, Salud María Jiménez -Zafra, and Gülşen Eryiğit. 2016. SemEval-2016 Task 5: A...
2016
-
[4]
Jacob Devlin, Ming -Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding . Proceedings of NAACL -HLT 2019, pages 4171-4186
2019
-
[5]
Yice Zhang, Yifan Yang, Bin Liang, Shiwei Chen, Bing Qin, and Ruifeng Xu. 2023. An Empirical Study of Sentiment -Enhanced Pre-Training for Aspect -Based Sentiment Analysis . Findings of ACL 2023, pages 9633-9651
2023
-
[6]
Zhuoyan Li, Hangxiao Zhu, Zhuoran Lu, and Ming Yin. 2023. Synthetic Data Generation with Large Language Models for Text Classification: Potential and Limitations . EMNLP 2023, pages 10443-10461
2023
-
[7]
Charles Welch and Rada Mihalcea. 2016. Targeted Sentiment to Understand Student Comments . COLING 2016, pages 2471 -2481. 38
2016
-
[8]
Janaka Chathuranga, Shanika Ediriweera, Ravindu Hasantha, Pranidhith Munasinghe, and Surangika Ranathunga. 2018. Annotating Opinions and Opinion Targets in Student Course Feedback. LREC 2018 Workshop paper
2018
-
[9]
Nikola Nikolić, Olivera Grljević, and Aleksandar Kovačević. 2020. Aspect-based sentiment analysis of reviews in the domain of higher education . The Electronic Library, 38(1), 44-64
2020
-
[10]
Thanveer Shaik, Xiaohui Tao, Yan Li, Christopher Dann, Jacquie McDonald, Petrea Redmond, and Linda Galligan. 2022. A Review of the Trends and Challenges in Adopting Natural Language Processing Methods for Education Feedback Analysis . IEEE Access, 10, 56720-56739
2022
-
[11]
Missaka Herath, Kushan Chamindu, Hashan Maduwantha, and Surangika Ranathunga. 2022. Dataset and Baseline for Automatic Student Feedback Analysis . Proceedings of the 13th Conference on Language Resources and Evaluation, pages 2042 -2049
2022
-
[12]
Ting-Wei Hsu, Chung -Chi Chen, Hen -Hsen Huang, and Hsin -Hsi Chen. 2021. Semantics - Preserved Data Augmentation for Aspect -Based Sentiment Analysis . Proceedings of EMNLP 2021, pages 4067-4079
2021
-
[13]
Timo Schick and Hinrich Schütze. 2021. Exploiting Cloze -Questions for Few -Shot Text Classification and Natural Language Inference . Proceedings of EACL 2021, pages 255 -269
2021
-
[14]
Hang Yan, Junqi Dai, Tuo Ji, Xipeng Qiu, and Zheng Zhang. 2021. A Unified Generative Framework for Aspect-Based Sentiment Analysis . Proceedings of ACL-IJCNLP 2021, pages 2416- 2429
2021
-
[15]
Jian Liu, Zhiyang Teng, Leyang Cui, Hanmeng Liu, and Yue Zhang. 2021. Solving Aspect Category Sentiment Analysis as a Text Generation Task . Proceedings of EMNLP 2021, pages 4406-4416
2021
-
[16]
Michelangelo Misuraca, Germana Scepi, and Maria Spano. 2021. Using Opinion Mining as an educational analytic: An integrated strategy for the analysis of students’ feedback . Studies in Educational Evaluation, 68, 100979
2021
-
[17]
Thanveer Shaik, Xiaohui Tao, Christopher Dann, Haoran Xie, Yan Li, and Linda Galligan. 2023. Sentiment analysis and opinion mining on educational data: A survey . Natural Language Processing Journal, 2, 100003
2023
-
[18]
Charalampos Dervenis, Giannis Kanakis, and Panos Fitsilis. 2024. Sentiment analysis of student feedback: A comparative study employing lexicon and machine learning techniques . Studies in Educational Evaluation, 83, 101406
2024
-
[19]
Aleksandra Edwards and Jose Camacho -Collados. 2024. Language Models for Text Classification: Is In-Context Learning Enough? . Proceedings of LREC -COLING 2024, pages 10058-10072
2024
-
[20]
John Hattie and Helen Timperley. 2007. The Power of Feedback. Review of Educational Research, 77(1), 81-112
2007
-
[21]
David Carless and David Boud. 2018. The development of student feedback literacy: enabling uptake of feedback . Assessment & Evaluation in Higher Education , 43(8), 1315-1325
2018
-
[22]
Michael Henderson, Michael Phillips, Tracii Ryan, David Boud, Phillip Dawson, Elizabeth Molloy, and Paige Mahoney. 2019. Conditions that enable effective feedback . Higher Education Research & Development , 38(7), 1401-1416
2019
-
[23]
Swapna Gottipati, Venky Shankararaman, and Jeff Rongsheng Lin. 2018. Text analytics approach to extract course improvement suggestions from students’ feedback . Research and Practice in Technology Enhanced Learning , 13, 6
2018
-
[24]
Maija Hujala, Antti Knutas, Timo Hynninen, and Heli Arminen. 2020. Improving the quality of teaching by utilising written student feedback: A streamlined process . Computers & Education , 157, 103965. 39
2020
-
[25]
Feng, Varun Gangal, Jason Wei, Sarath Chandar, Soroush Vosoughi, Teruko Mitamura, and Eduard Hovy
Steven Y. Feng, Varun Gangal, Jason Wei, Sarath Chandar, Soroush Vosoughi, Teruko Mitamura, and Eduard Hovy. 2021. A Survey of Data Augmentation Approaches for NLP . Findings of ACL 2021, pages 968-988
2021
-
[26]
Yu Meng, Jiaxin Huang, Yu Zhang, and Jiawei Han. 2022. Generating Training Data with Language Models: Towards Zero -Shot Language Understanding . Advances in Neural Information Processing Systems 35
2022
-
[27]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. Self-Instruct: Aligning Language Models with Self -Generated Instructions . Proceedings of ACL 2023, pages 13484 -13508
2023
-
[28]
Siddharth Varia, Shuai Wang, Kishaloy Halder, Robert Vacareanu, Miguel Ballesteros, Yassine Benajiba, Neha Anna John, Rishita Anubhai, Smaranda Muresan, and Dan Roth. 2023. Instruction Tuning for Few-Shot Aspect -Based Sentiment Analysis . Proceedings of WASSA 2023, pages 28 - 37
2023
-
[29]
Robert Vacareanu, Siddharth Varia, Kishaloy Halder, Shuai Wang, Giovanni Paolini, Neha Anna John, Miguel Ballesteros, and Smaranda Muresan. 2024. A Weak Supervision Approach for Few - Shot Aspect Based Sentiment Analysis . Proceedings of EACL 2024, pages 2381 -2395
2024
-
[30]
Wenxuan Zhang, Yue Deng, Bing Liu, Sinno Jialin Pan, and Lidong Bing. 2024. Sentiment Analysis in the Era of Large Language Models: A Reality Check . Findings of NAACL 2024, pages 3892-3910
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.