Reliable Extraction of Clinical Follow-Up Instructions: A Hybrid Neural-Symbolic Pipeline
Pith reviewed 2026-06-29 18:40 UTC · model grok-4.3
The pith
A hybrid pipeline extracts clinical follow-up action-date pairs at 0.99 F1 by separating neural tagging from deterministic arithmetic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
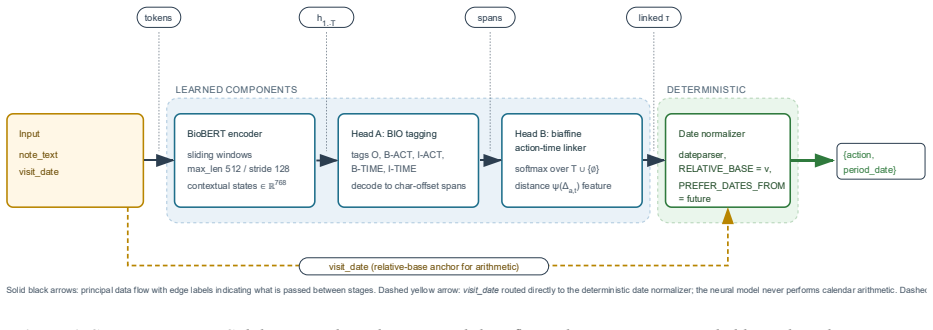
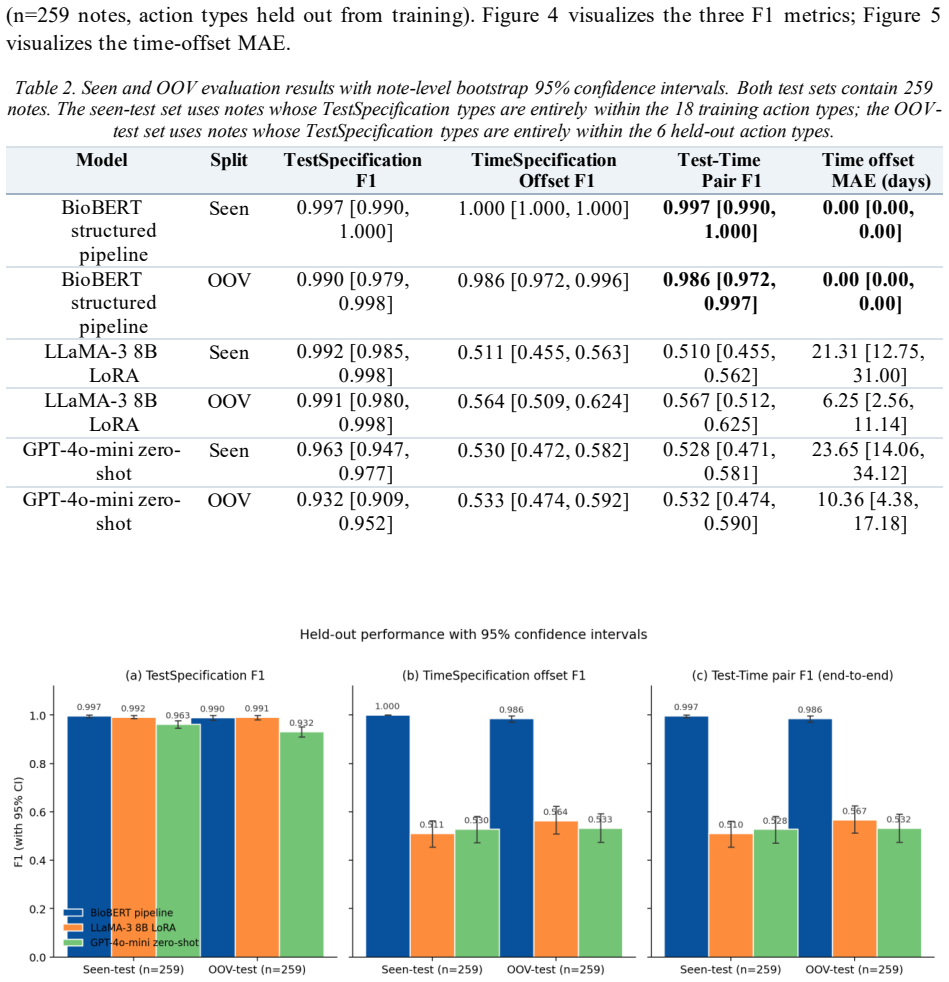
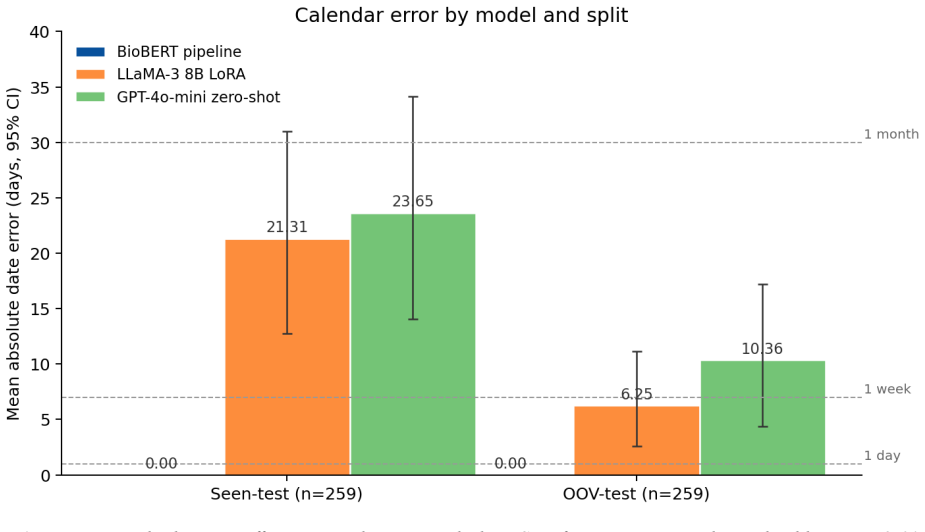
The pipeline defines TestSpecification and TimeSpecification entities linked by a ScheduledFor relation; a neural tagger and linker identify them in text, after which an ontology canonicalizes the 28 possible actions and a deterministic converter turns time expressions into day offsets. On 259-note seen and OOV splits this yields Test-Time Pair F1 of 0.997 and 0.986 with 0.00-day mean absolute error. Generative baselines reach high action F1 yet only 0.51-0.57 pair F1, with non-overlapping confidence intervals.
What carries the argument
ScheduledFor relation between TestSpecification and TimeSpecification entities, extracted neurally then normalized symbolically via ontology and deterministic day-offset conversion.
If this is right
- The method generalizes to actions held out from training, maintaining high pair F1.
- Explicit separation of entity extraction from date arithmetic produces exact day offsets where generative decoding does not.
- The approach surfaces concrete failure modes of pure generation on linking and arithmetic tasks.
- The benchmark identifies transfer to real EHR notes as the required next validation step.
Where Pith is reading between the lines
- The same split between learned recognition and rule-based calculation could be applied to other clinical extraction tasks that require precise temporal offsets.
- High performance on OOV actions suggests the ontology plus deterministic normalizer removes the main source of date errors once entities are found.
- If real notes contain more varied phrasing than the synthetic set, the neural tagging stage would become the new bottleneck rather than the arithmetic stage.
- The zero-day MAE result indicates that once the ScheduledFor link is correct the rest of the pipeline introduces no additional timing error.
Load-bearing premise
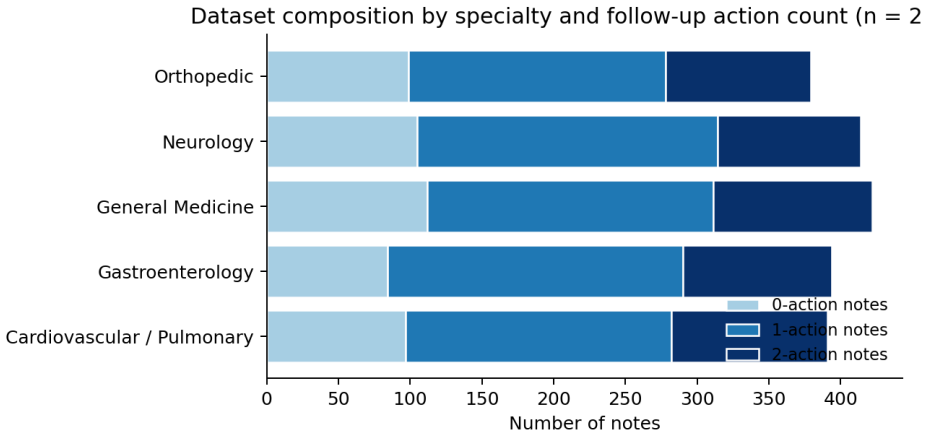
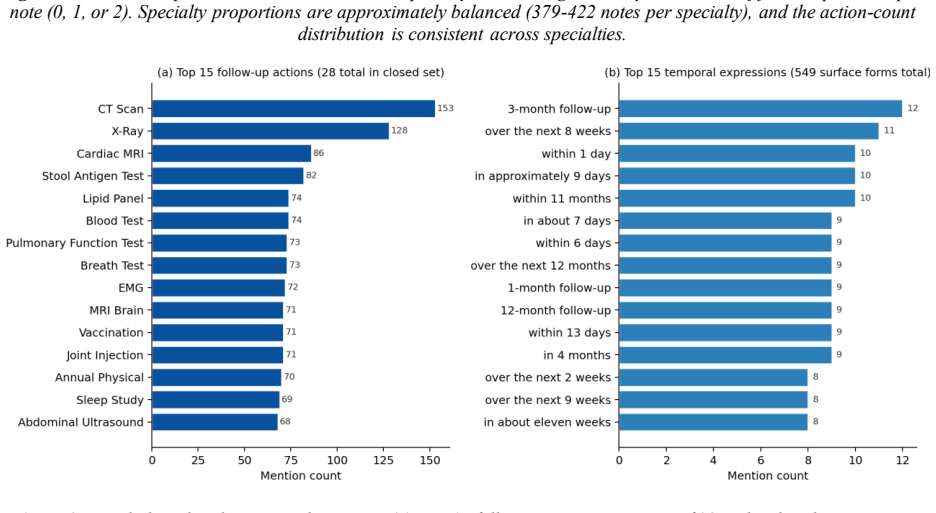
The 2,000-note synthetic outpatient corpus with action-disjoint splits captures the linguistic variety, time-expression ambiguity, and action distribution of real clinical notes.
What would settle it
Running the same pipeline and generative baselines on a held-out collection of real EHR outpatient notes and comparing pair F1 and day MAE would show whether the reported advantage survives outside the synthetic corpus.
Figures
read the original abstract
Objective. Outpatient notes carry follow-up instructions pairing actions with future times ("MRI brain in two weeks"). Extracting (action, date) pairs supports scheduling and audit, but generative extractors miss the date because linking and arithmetic are implicit in decoding. We test a hybrid neural-symbolic pipeline against direct generation. Methods. We define TestSpecification and TimeSpecification entities and a ScheduledFor relation. BioBERT feeds BIO tagging and a biaffine linker; entities are canonicalized via a 28-action ontology and times normalized to day offsets deterministically. We evaluate on a 2,000-note synthetic outpatient corpus with action-disjoint splits (18 train, 6 OOV-test) against zero-shot GPT-4o-mini and LoRA-fine-tuned LLaMA-3 8B with note-level bootstrap 95% CIs. Results. On 259-note seen and OOV splits the hybrid pipeline achieves Test-Time Pair F1 of 0.997 and 0.986 with 0.00-day MAE. Baselines reach high action F1 (LLaMA-3 0.992; GPT-4o-mini 0.963 seen) but Pair F1 stays at 0.51-0.57 (LLaMA-3) and 0.53 (GPT-4o-mini), CIs non-overlapping with the hybrid. Conclusion. Separating learned entity extraction from deterministic date arithmetic outperforms generation on this benchmark, generalizes to held-out actions, and exposes failure modes. Transfer to real EHR notes is the next validation; a first-pass realism check is in Limitations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a hybrid neural-symbolic pipeline for extracting follow-up instructions as (action, time) pairs from outpatient clinical notes. It uses BioBERT for BIO tagging and biaffine linking to identify TestSpecification and TimeSpecification entities and ScheduledFor relations, followed by canonicalization with a 28-action ontology and deterministic time normalization to day offsets. Evaluated on a 2,000-note synthetic corpus with action-disjoint train/test splits (including OOV actions), the pipeline achieves Test-Time Pair F1 of 0.997 (seen) and 0.986 (OOV) with 0.00-day MAE, significantly outperforming zero-shot GPT-4o-mini and LoRA-fine-tuned LLaMA-3 8B baselines whose Pair F1 remains around 0.5-0.57 despite high action F1.
Significance. If the synthetic corpus adequately represents real clinical notes, the result demonstrates that separating learned entity extraction from deterministic symbolic date handling can achieve near-perfect performance and generalization to held-out actions, where end-to-end generative models fail on linking and arithmetic. The bootstrap 95% CIs and explicit OOV splits provide reproducible evidence of robustness on the benchmark.
major comments (2)
- [Methods (corpus and evaluation)] Methods (synthetic corpus generation and evaluation setup): The headline claims of Test-Time Pair F1 0.997/0.986 and 0.00-day MAE rest exclusively on the 2,000-note synthetic outpatient corpus with action-disjoint splits. The paper states in the Conclusion that transfer to real EHR notes is the next validation and references a first-pass realism check in Limitations, but no quantitative evidence is provided that the corpus replicates the linguistic variety, time-expression ambiguity, or action distribution of authentic clinical notes. This assumption is load-bearing for the Objective's claim of reliability in a clinical setting.
- [Results] Results (baseline comparison): The non-overlapping CIs are a strength, but the generative baselines' low Pair F1 (0.51-0.57) is attributed to failures in linking and arithmetic; without ablation showing that the hybrid's deterministic normalization is the decisive factor (vs. the ontology or linker), it is unclear whether the gap would persist on more varied data.
minor comments (1)
- [Abstract / Methods] The abstract and Methods should explicitly state the number of bootstrap samples and how note-level aggregation is performed for the 95% CIs to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Methods (corpus and evaluation)] Methods (synthetic corpus generation and evaluation setup): The headline claims of Test-Time Pair F1 0.997/0.986 and 0.00-day MAE rest exclusively on the 2,000-note synthetic outpatient corpus with action-disjoint splits. The paper states in the Conclusion that transfer to real EHR notes is the next validation and references a first-pass realism check in Limitations, but no quantitative evidence is provided that the corpus replicates the linguistic variety, time-expression ambiguity, or action distribution of authentic clinical notes. This assumption is load-bearing for the Objective's claim of reliability in a clinical setting.
Authors: We agree the synthetic corpus is central and that no quantitative metrics comparing it to real notes are provided. The corpus was deliberately constructed with action-disjoint splits and controlled time expressions to isolate OOV generalization and deterministic normalization effects. The manuscript already states in Conclusion and Limitations that real-EHR transfer is future work. We will revise Limitations to more explicitly discuss potential gaps in linguistic variety and ambiguity relative to authentic notes and will temper claims about immediate clinical deployment. revision: partial
-
Referee: [Results] Results (baseline comparison): The non-overlapping CIs are a strength, but the generative baselines' low Pair F1 (0.51-0.57) is attributed to failures in linking and arithmetic; without ablation showing that the hybrid's deterministic normalization is the decisive factor (vs. the ontology or linker), it is unclear whether the gap would persist on more varied data.
Authors: The attribution follows directly from the baselines achieving high action F1 yet low Pair F1, pointing to linking and arithmetic as the failure modes. The hybrid architecture separates these steps by design. We acknowledge an explicit ablation isolating the deterministic normalizer is absent. We will add a clarifying sentence in Results/Discussion noting this limitation and that future work could include such ablations on more varied data. revision: partial
- Quantitative evidence that the synthetic corpus replicates linguistic variety, time-expression ambiguity, or action distributions of real clinical notes
Circularity Check
No circularity; purely empirical evaluation on held-out synthetic splits
full rationale
The paper defines a hybrid pipeline (BIO tagging + biaffine linker + deterministic normalization via 28-action ontology) and reports Test-Time Pair F1 and MAE directly on action-disjoint held-out splits of a 2,000-note synthetic corpus. No equations, parameters, or claims reduce by construction to fitted inputs or self-citations; the central results are measured performance numbers on unseen data. The authors explicitly flag transfer to real EHR notes as future work, confirming the evaluation is self-contained against the stated benchmark.
Axiom & Free-Parameter Ledger
free parameters (1)
- 28-action ontology
axioms (1)
- domain assumption Time expressions in outpatient notes can be mapped to exact day offsets using deterministic rules without residual ambiguity
Reference graph
Works this paper leans on
-
[1]
Y. Wang, L. Wang, M. Rastegar-Mojarad, S. Moon, F. Shen, N. Afzal, S. Liu, Y. Zeng, S. Mehrabi, S. Sohn, H. Liu, Clinical information extraction applications: a literature review, J. Biomed. Inform. 77 (2018) 34 -49. https://doi.org/10.1016/j.jbi.2017.11.011
-
[2]
G.K. Savova, J.J. Masanz, P.V. Ogren, J. Zheng, S. Sohn, K.C. Kipper -Schuler, C.G. Chute, Mayo clinical Text Analysis and Knowledge Extraction System (cTAKES): architecture, component evaluation and applications, J. Am. Med. Inform. Assoc. 17 (2010) 50 7-513. https://doi.org/10.1136/jamia.2009.001560
-
[3]
W. Sun, A. Rumshisky, O. Uzuner, Evaluating temporal relations in clinical text: 2012 i2b2 Challenge, J. Am. Med. Inform. Assoc. 20 (2013) 806 -813. https://doi.org/10.1136/amiajnl -2013-001628
-
[4]
W.F. Styler IV, S. Bethard, S. Finan, M. Palmer, S. Pradhan, P.C. de Groen, B. Erickson, T. Miller, C. Lin, G. Savova, J. Pustejovsky, Temporal annotation in the clinical domain, Trans. Assoc. Comput. Linguist. 2 (2014) 143-154. https://doi.org/10.1162/tacl_a_00172
-
[5]
S. Bethard, L. Derczynski, G. Savova, J. Pustejovsky, M. Verhagen, SemEval -2015 Task 6: Clinical TempEval, in: Proc. 9th Int. Workshop Semantic Eval. (SemEval 2015), Association for Computational Linguistics, Denver, CO, 2015, pp. 806 -814. https://doi.org/10.18653/v1/S15 -2136
-
[6]
S. Bethard, G. Savova, M. Palmer, J. Pustejovsky, SemEval-2016 Task 12: Clinical TempEval, in: Proc. 10th Int. Workshop Semantic Eval. (SemEval 2016), Association for Computational Linguistics, San Diego, CA, 2016, pp. 1052 -1062. https://doi.org/10.18653/v1/S16 -1165
-
[7]
J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, BERT: pre -training of deep bidirectional transformers for language understanding, in: Proc. 2019 Conf. North Am. Chapter Assoc. Comput. Linguist.: Hum. Lang. Technol., Association for Computational Linguist ics, Minneapolis, MN, 2019, pp. 4171 -4186. https://doi.org/10.18653/v1/N19 -1423
-
[8]
J. Lee, W. Yoon, S. Kim, D. Kim, S. Kim, C.H. So, J. Kang, BioBERT: a pre -trained biomedical language representation model for biomedical text mining, Bioinformatics 36 (2020) 1234 -1240. https://doi.org/10.1093/bioinformatics/btz682
-
[9]
E. Alsentzer, J.R. Murphy, W. Boag, W.-H. Weng, D. Jin, T. Naumann, M. McDermott, Publicly available clinical BERT embeddings, in: Proc. 2nd Clin. Nat. Lang. Process. Workshop, Association for Computational Linguistics, Minneapolis, MN, 2019, pp. 72 -78. https://doi.org/10.18653/v1/W19 -1909
-
[10]
Y. Gu, R. Tinn, H. Cheng, M. Lucas, N. Usuyama, X. Liu, T. Naumann, J. Gao, H. Poon, Domain-specific language model pretraining for biomedical natural language processing, ACM Trans. Comput. Healthc. 3 (2021) 2:1-2:23. https://doi.org/10.1145/3458754
-
[11]
X. Yang, A. Chen, N. PourNejatian, H.C. Shin, K.E. Smith, C. Parisien, C. Compas, C. Martin, M.G. Flores, Y. Zhang, T. Magoc, C.A. Harle, G. Lipori, D.A. Mitchell, W.R. Hogan, E.A. Shenkman, J. Bian, Y. Wu, A large language model for electronic health records, NPJ Digit. Med. 5 (2022) 194. https://doi.org/10.1038/s41746-022- 00742 -2
-
[12]
doi: 10.18653/v1/2022.emnlp-main.130
M. Agrawal, S. Hegselmann, H. Lang, Y. Kim, D. Sontag, Large language models are few -shot clinical information extractors, in: Proc. 2022 Conf. Empir. Methods Nat. Lang. Process. (EMNLP), Association for Computational Linguistics, Abu Dhabi, 2022, pp. 1998-2022. https://doi.org/10.18653/v1/2022.emnlp-main.130
-
[14]
Strotgen, M
J. Strotgen, M. Gertz, HeidelTime: high quality rule -based extraction and normalization of temporal expressions, in: Proc. 5th Int. Workshop Semantic Eval. (SemEval 2010), Association for Computational Linguistics, Uppsala, 2010, pp. 321 -324
2010
-
[15]
Chang, C.D
A.X. Chang, C.D. Manning, SUTime: a library for recognizing and normalizing time expressions, in: Proc. 8th Int. Conf. Lang. Resour. Eval. (LREC 2012), European Language Resources Association, Istanbul, 2012, pp. 3735-3740
2012
-
[16]
C. Lin, T. Miller, D. Dligach, S. Bethard, G. Savova, A BERT-based universal model for both within- and cross-sentence clinical temporal relation extraction, in: Proc. 2nd Clin. Nat. Lang. Process. Workshop, Association for Computational Linguistics, Minneapolis, MN, 2019, pp. 65-71. https://doi.org/10.18653/v1/W19- 1908. 17
-
[17]
M. Eberts, A. Ulges, Span-based joint entity and relation extraction with transformer pre-training, in: Proc. 24th Eur. Conf. Artif. Intell. (ECAI 2020), IOS Press, Santiago de Compostela, 2020, pp. 2006 -2013. https://doi.org/10.3233/FAIA200321
-
[18]
Dozat, C.D
T. Dozat, C.D. Manning, Deep biaffine attention for neural dependency parsing, in: Proc. 5th Int. Conf. Learn. Represent. (ICLR 2017), Toulon, 2017
2017
-
[19]
M. Wornow, Y. Xu, R. Thapa, B. Patel, E. Steinberg, S. Fleming, M.A. Pfeffer, J.A. Fries, N.H. Shah, The shaky foundations of large language models and foundation models for electronic health records, NPJ Digit. Med. 6 (2023) 135. https://doi.org/10.1038/s41746 -023-00879 -8
-
[20]
Y. Hu, Q. Chen, J. Du, X. Peng, V.K. Keloth, X. Zuo, Y. Zhou, Z. Li, X. Jiang, Z. Lu, K. Roberts, H. Xu, Improving large language models for clinical named entity recognition via prompt engineering, J. Am. Med. Inform. Assoc. 31 (2024) 1812 -1820. https://doi.org/10.1093/jamia/ocad259
-
[21]
Kweon, J
S. Kweon, J. Kim, J. Kim, S. Im, E. Cho, S. Bae, J. Oh, G. Lee, J.H. Moon, S.C. You, S. Baek, C.H. Han, Y.B. Jung, Y. Jo, E. Choi, Publicly shareable clinical large language model built on synthetic clinical notes, in: Findings Assoc. Comput. Linguist.: ACL 2024, Association for Computational Linguistics, Bangkok, 2024, pp. 5148-5168
2024
-
[22]
M. Loni, F. Poursalim, M. Asadi, A. Gharehbaghi, A review on generative AI models for synthetic medical text, time series, and longitudinal data, NPJ Digit. Med. 8 (2025) 281. https://doi.org/10.1038/s41746-024-01409- w
-
[23]
J.L. Callen, J.I. Westbrook, A. Georgiou, J. Li, Failure to follow -up test results for ambulatory patients: a systematic review, J. Gen. Intern. Med. 27 (2012) 1334 -1348. https://doi.org/10.1007/s11606 -011-1949-5
-
[24]
M. Yetisgen-Yildiz, M.L. Gunn, F. Xia, T.H. Payne, A text processing pipeline to extract recommendations from radiology reports, J. Biomed. Inform. 46 (2013) 354 -362. https://doi.org/10.1016/j.jbi.2012.12.005
-
[25]
J. Dagdelen, A. Dunn, S. Lee, N. Walker, A.S. Rosen, G. Ceder, K.A. Persson, A. Jain, Structured information extraction from scientific text with large language models, Nat. Commun. 15 (2024) 1418. https://doi.org/10.1038/s41467 -024-45563 -x
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.