Towards Generalization-Oriented Models for Vehicle Routing Problems with Mixture-of-Experts
Pith reviewed 2026-06-29 19:44 UTC · model grok-4.3
The pith
A mixture-of-experts model with residual refinement and instance-level gating improves generalization across distribution shifts in deep reinforcement learning for vehicle routing problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
R2E-IG partitions the policy network into residual-refined expert modules, routes each input instance to suitable modules via a learned instance-level gating mechanism, and trains the whole system on mixed distributions whose relative weights are adjusted by Dynamic Weight Adaption; this combination yields competitive performance against state-of-the-art baselines on both in-distribution and out-of-distribution instances across synthetic and benchmark datasets.
What carries the argument
Residual Refined Experts with Instance-level Gating (R2E-IG) architecture, which partitions the policy into multiple modules, refines each via residuals, and uses a gating network to produce distribution-aware instance representations that route inputs to appropriate modules.
If this is right
- R2E-IG can be integrated into existing DRL-based VRP solvers to raise their performance on both in- and out-of-distribution cases.
- The same residual-expert plus instance-gating pattern applies to other combinatorial routing problems that suffer from distribution shift.
- Dynamic reweighting of training distributions during learning produces policies whose quality is less sensitive to the original sampling distribution.
- Instance-level representations learned by the gate provide an explicit signal of which training distributions were most informative for a given test instance.
Where Pith is reading between the lines
- The gating network may be inspected after training to identify which synthetic distributions most improve robustness, offering a diagnostic for future data-generation strategies.
- If the residual refinement inside experts is the main source of expressiveness, the same refinement trick could be applied to non-expert DRL architectures without the full mixture-of-experts overhead.
- Extending the mixed-distribution training to include real-world VRP traces rather than only synthetic generators would test whether the reported gains survive when the shift is no longer artificially constructed.
Load-bearing premise
The mixed-distribution training mechanism with Dynamic Weight Adaption will successfully emphasize informative distributions and produce distribution-aware instance representations via the gating mechanism without introducing harmful bias or instability.
What would settle it
A controlled experiment in which R2E-IG is trained exactly as described yet fails to match or exceed baseline performance on held-out out-of-distribution instances drawn from the same generators used in the paper.
Figures
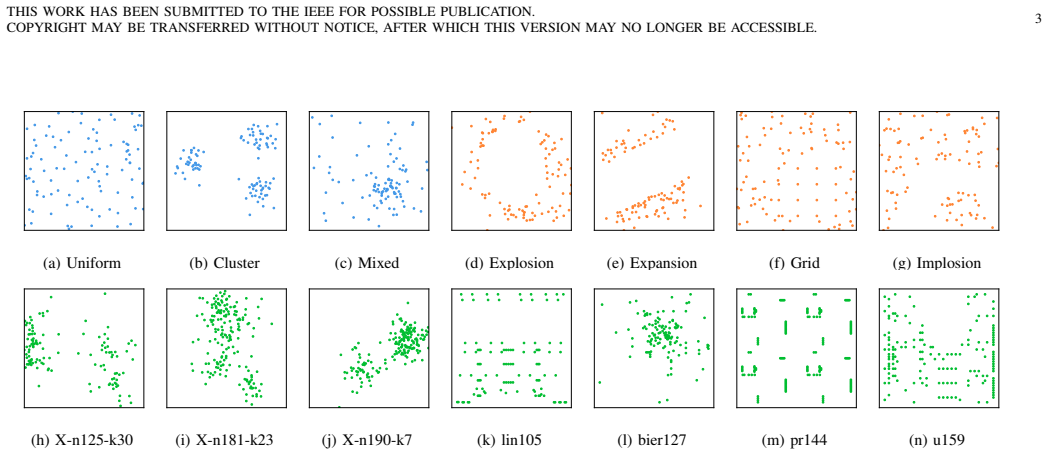
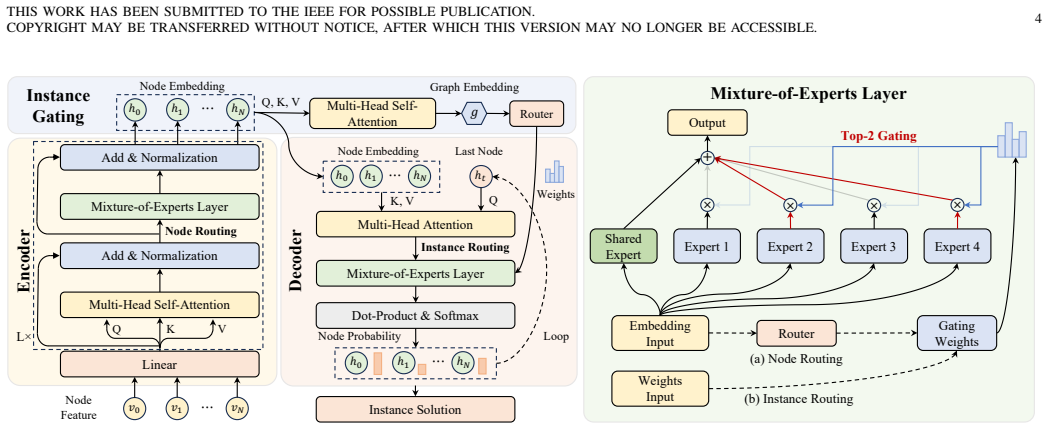
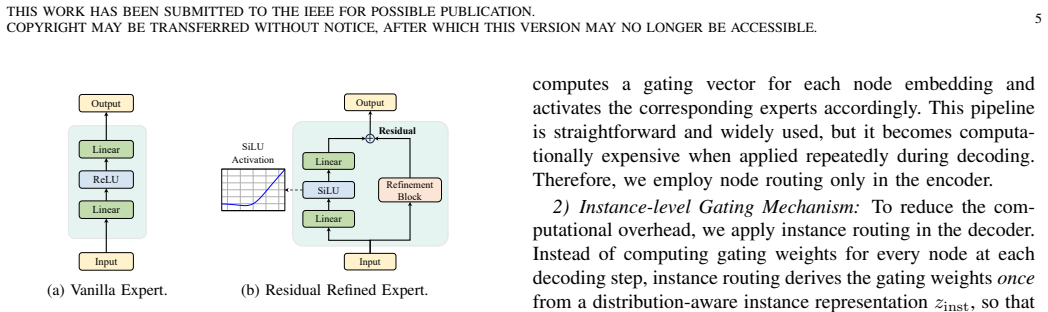

read the original abstract
In recent years, Deep Reinforcement Learning (DRL) has achieved substantial progress on Vehicle Routing Problems (VRPs). However, existing DRL-based methods are typically trained on instances generated from a uniform distribution, which limits their performance under real-world distribution shifts. In this paper, we aim to develop a generalization-oriented model that partitions the policy network into multiple modules and adaptively recombines modules to form specific policies during inference. Specifically, we propose Residual Refined Experts with Instance-level Gating (R2E-IG) to improve cross-distribution generalization. Our contributions are threefold: (1) We introduce a Residual Refined Expert (R2E) architecture that enhance expert expressiveness via residual refinement; (2) We design an instance-level gating mechanism that learns distribution-aware instance representations and routes inputs to suitable modules; (3) We propose a mixed-distribution training mechanism equipped with Dynamic Weight Adaption (DWA), which dynamically reweights training data from different distributions to emphasize more informative ones. Extensive experiments show that R2E-IG achieves competitive performance against state-of-the-art baselines on both in-distribution and out-of-distribution instances across synthetic and benchmark datasets. Moreover, R2E-IG is generic and can be easily integrated into existing DRL-based methods to further improve performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Residual Refined Experts with Instance-level Gating (R2E-IG), a mixture-of-experts architecture for DRL-based solvers on Vehicle Routing Problems. It partitions the policy into modules that are adaptively recombined at inference via residual refinement of experts, an instance-level gating network that produces distribution-aware representations, and a mixed-distribution training procedure that uses Dynamic Weight Adaptation (DWA) to reweight data from different distributions. The central empirical claim is that R2E-IG matches or exceeds state-of-the-art baselines on both in-distribution and out-of-distribution instances drawn from synthetic and benchmark sets, and that the architecture can be plugged into existing DRL methods.
Significance. If the reported performance holds under the full experimental protocol, the work directly addresses a recognized limitation of current DRL-VRP methods (training on a single uniform distribution) and supplies a modular, reusable template that improves cross-distribution robustness without requiring changes to the underlying solver. The provision of architectural definitions, the training procedure, and direct comparative tables on both synthetic and benchmark data constitutes a reproducible empirical contribution; the absence of hidden boundedness or identifiability assumptions further strengthens the result.
minor comments (3)
- [§3.2] §3.2 (Instance-level gating): the description of how the gating network output is combined with the expert outputs should explicitly state whether the gate produces a hard or soft selection and how ties or low-confidence assignments are handled.
- [§4.3] §4.3 (Dynamic Weight Adaptation): the update rule for the DWA weights is presented without a convergence or stability argument; a short remark on the observed range of weight values across training runs would help readers assess whether the mechanism remains well-behaved.
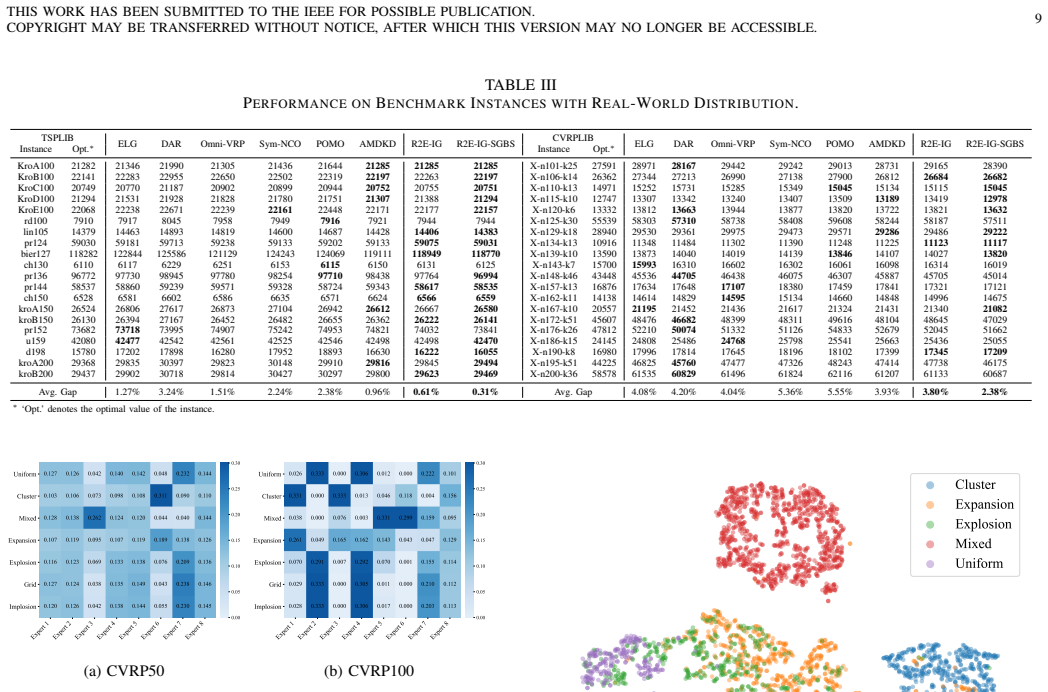
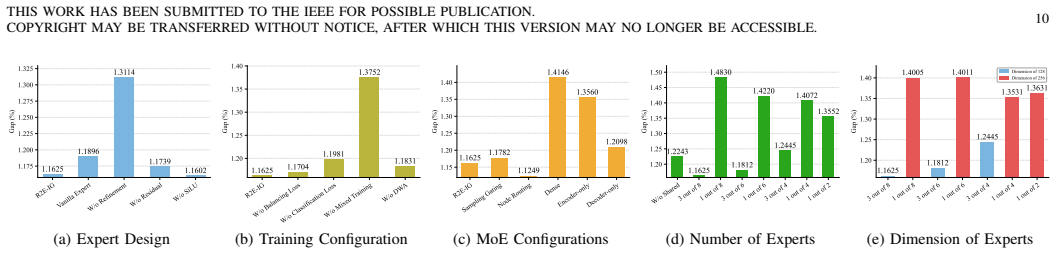
- [Table 2] Table 2 (synthetic OOD results): the caption should list the exact number of independent training seeds and whether the reported gaps are statistically significant (e.g., via paired t-test or bootstrap).
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and the recommendation of minor revision. The referee's description accurately reflects the R2E-IG architecture, its components (residual refinement, instance-level gating, and DWA-based mixed-distribution training), and the empirical focus on cross-distribution generalization for DRL-VRP solvers.
Circularity Check
No significant circularity
full rationale
The paper proposes an architectural model (R2E-IG) consisting of residual refined experts, instance-level gating, and mixed-distribution training with DWA. No equations, derivations, or uniqueness theorems are presented that reduce claimed performance or generalization to fitted parameters or self-citations by construction. The central claims rest on empirical results from training the defined architecture on mixed data and evaluating on in/out-of-distribution instances, which are independent of any self-referential reduction. The method is self-contained as a reproducible neural architecture proposal with standard training procedures.
Axiom & Free-Parameter Ledger
free parameters (1)
- Dynamic Weight Adaption weights
invented entities (2)
-
Residual Refined Expert (R2E)
no independent evidence
-
Instance-level gating mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Vehicle routing problem and related algorithms for logistics distribution: A literature review and classification,
G. D. Konstantakopoulos, S. P. Gayialis, and E. P. Kechagias, “Vehicle routing problem and related algorithms for logistics distribution: A literature review and classification,”Operational Research, vol. 22, no. 3, pp. 2033–2062, 2022
2033
-
[2]
A review on learning to solve combinatorial optimisation problems in manufacturing,
C. Zhang, Y . Wu, Y . Ma, W. Song, Z. Le, Z. Cao, and J. Zhang, “A review on learning to solve combinatorial optimisation problems in manufacturing,”IET Collaborative Intelligent Manufacturing, vol. 5, no. 1, p. e12072, 2023
2023
-
[3]
Neural air- port ground handling,
Y . Wu, J. Zhou, Y . Xia, X. Zhang, Z. Cao, and J. Zhang, “Neural air- port ground handling,”IEEE Transactions on Intelligent Transportation Systems, vol. 24, no. 12, pp. 15 652–15 666, 2023
2023
-
[4]
Machine learning for combinato- rial optimization: a methodological tour d’horizon,
Y . Bengio, A. Lodi, and A. Prouvost, “Machine learning for combinato- rial optimization: a methodological tour d’horizon,”European Journal of Operational Research, vol. 290, no. 2, pp. 405–421, 2021
2021
-
[5]
Attention, learn to solve routing problems!
W. Kool, H. van Hoof, and M. Welling, “Attention, learn to solve routing problems!” inInternational Conference on Learning Representations, 2018
2018
-
[6]
Pomo: Policy optimization with multiple optima for reinforcement learning,
Y .-D. Kwon, J. Choo, B. Kim, I. Yoon, Y . Gwon, and S. Min, “Pomo: Policy optimization with multiple optima for reinforcement learning,”Advances in Neural Information Processing Systems, vol. 33, pp. 21 188–21 198, 2020
2020
-
[7]
New benchmark instances for the capacitated vehicle routing problem,
E. Uchoa, D. Pecin, A. Pessoa, M. Poggi, T. Vidal, and A. Subramanian, “New benchmark instances for the capacitated vehicle routing problem,” European Journal of Operational Research, vol. 257, no. 3, pp. 845–858, 2017
2017
-
[8]
Tsplib—a traveling salesman problem library,
G. Reinelt, “Tsplib—a traveling salesman problem library,”ORSA journal on computing, vol. 3, no. 4, pp. 376–384, 1991
1991
-
[9]
Learning the travelling salesperson problem requires rethinking generalization,
C. K. Joshi, Q. Cappart, L.-M. Rousseau, and T. Laurent, “Learning the travelling salesperson problem requires rethinking generalization,” International Conference on Principles and Practice of Constraint Programming, 2021
2021
-
[10]
Learning to solve routing problems via distributionally robust optimization,
Y . Jiang, Y . Wu, Z. Cao, and J. Zhang, “Learning to solve routing problems via distributionally robust optimization,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 9, 2022, pp. 9786–9794
2022
-
[11]
Learning generalizable models for vehicle routing problems via knowl- edge distillation,
J. Bi, Y . Ma, J. Wang, Z. Cao, J. Chen, Y . Sun, and Y . M. Chee, “Learning generalizable models for vehicle routing problems via knowl- edge distillation,”Advances in Neural Information Processing Systems, vol. 35, pp. 31 226–31 238, 2022
2022
-
[12]
Ensemble-based deep reinforcement learning for vehicle routing problems under distribution shift,
Y . Jiang, Z. Cao, Y . Wu, W. Song, and J. Zhang, “Ensemble-based deep reinforcement learning for vehicle routing problems under distribution shift,”Advances in Neural Information Processing Systems, vol. 36, pp. 53 112–53 125, 2023
2023
-
[13]
Towards generalizable neural solvers for vehicle routing problems via ensemble with trans- ferrable local policy,
C. Gao, H. Shang, K. Xue, D. Li, and C. Qian, “Towards generalizable neural solvers for vehicle routing problems via ensemble with trans- ferrable local policy,” inProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24, 8 2024, pp. 6914– 6922
2024
-
[14]
On the generalization of neural combinatorial optimization heuristics,
S. Manchanda, S. Michel, D. Drakulic, and J.-M. Andreoli, “On the generalization of neural combinatorial optimization heuristics,” inJoint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, 2022, pp. 426–442
2022
-
[15]
Towards omni- generalizable neural methods for vehicle routing problems,
J. Zhou, Y . Wu, W. Song, Z. Cao, and J. Zhang, “Towards omni- generalizable neural methods for vehicle routing problems,” inInter- national Conference on Machine Learning. PMLR, 2023, pp. 42 769– 42 789
2023
-
[16]
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruanet al., “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Pointer networks,
O. Vinyals, M. Fortunato, and N. Jaitly, “Pointer networks,”Advances in Neural Information Processing Systems, vol. 28, 2015
2015
-
[20]
Neural com- binatorial optimization with reinforcement learning,
I. Bello, H. Pham, Q. V . Le, M. Norouzi, and S. Bengio, “Neural com- binatorial optimization with reinforcement learning,” inInternational Conference on Learning Representations, 2017
2017
-
[21]
Reinforcement learning for solving the vehicle routing problem,
M. Nazari, A. Oroojlooy, L. Snyder, and M. Tak ´ac, “Reinforcement learning for solving the vehicle routing problem,”Advances in Neural Information Processing Systems, vol. 31, 2018. THIS WORK HAS BEEN SUBMITTED TO THE IEEE FOR POSSIBLE PUBLICATION. COPYRIGHT MAY BE TRANSFERRED WITHOUT NOTICE, AFTER WHICH THIS VERSION MAY NO LONGER BE ACCESSIBLE. 12
2018
-
[22]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[23]
Learning combinatorial optimization algorithms over graphs,
H. Dai, E. Khalil, Y . Zhang, B. Dilkina, and L. Song, “Learning combinatorial optimization algorithms over graphs,”Advances in Neural Information Processing Systems, vol. 30, 2017
2017
-
[24]
C. K. Joshi, T. Laurent, and X. Bresson, “An efficient graph convo- lutional network technique for the travelling salesman problem,”arXiv preprint arXiv:1906.01227, 2019
-
[25]
Generalize a small pre-trained model to arbitrarily large tsp instances,
Z.-H. Fu, K.-B. Qiu, and H. Zha, “Generalize a small pre-trained model to arbitrarily large tsp instances,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 8, 2021, pp. 7474–7482
2021
-
[26]
Deep policy dynamic programming for vehicle routing problems,
W. Kool, H. van Hoof, J. Gromicho, and M. Welling, “Deep policy dynamic programming for vehicle routing problems,” inInternational Conference on Integration of Constraint Programming, Artificial Intel- ligence, and Operations Research. Springer, 2022, pp. 190–213
2022
-
[27]
Neural large neighborhood search for the capacitated vehicle routing problem,
A. Hottung and K. Tierney, “Neural large neighborhood search for the capacitated vehicle routing problem,” inECAI 2020. IOS Press, 2020, pp. 443–450
2020
-
[28]
Graph neural network guided local search for the traveling salesperson problem,
B. Hudson, Q. Li, M. Malencia, and A. Prorok, “Graph neural network guided local search for the traveling salesperson problem,” inInterna- tional Conference on Learning Representations, 2022
2022
-
[29]
Neurolkh: Combining deep learning model with lin-kernighan-helsgaun heuristic for solving the traveling salesman problem,
L. Xin, W. Song, Z. Cao, and J. Zhang, “Neurolkh: Combining deep learning model with lin-kernighan-helsgaun heuristic for solving the traveling salesman problem,”Advances in Neural Information Process- ing Systems, vol. 34, pp. 7472–7483, 2021
2021
-
[30]
Learning 2- opt heuristics for the traveling salesman problem via deep reinforcement learning,
P. R. d O Costa, J. Rhuggenaath, Y . Zhang, and A. Akcay, “Learning 2- opt heuristics for the traveling salesman problem via deep reinforcement learning,” inAsian Conference on Machine Learning. PMLR, 2020, pp. 465–480
2020
-
[31]
Learning 3-opt heuristics for traveling salesman problem via deep reinforcement learning,
J. Sui, S. Ding, R. Liu, L. Xu, and D. Bu, “Learning 3-opt heuristics for traveling salesman problem via deep reinforcement learning,” inAsian Conference on Machine Learning. PMLR, 2021, pp. 1301–1316
2021
-
[32]
Learning to search feasible and infea- sible regions of routing problems with flexible neural k-opt,
Y . Ma, Z. Cao, and Y . M. Chee, “Learning to search feasible and infea- sible regions of routing problems with flexible neural k-opt,”Advances in Neural Information Processing Systems, vol. 36, pp. 49 555–49 578, 2023
2023
-
[33]
Deep reinforcement learning for multi-period facility location pk-median dynamic location problem,
C. Miao, Y . Zhang, T. Wu, F. Deng, and C. Chen, “Deep reinforcement learning for multi-period facility location pk-median dynamic location problem,” inProceedings of the 32nd ACM International Conference on Advances in Geographic Information Systems, 2024, pp. 173–183
2024
-
[34]
Learning to dispatch for job shop scheduling via deep reinforcement learning,
C. Zhang, W. Song, Z. Cao, J. Zhang, P. S. Tan, and X. Chi, “Learning to dispatch for job shop scheduling via deep reinforcement learning,” Advances in Neural Information Processing Systems, vol. 33, pp. 1621– 1632, 2020
2020
-
[35]
An End-to-End Learning Approach for Solving Capacitated Location-Routing Problems
C. Miao, Y . Zhang, T. Wu, F. Deng, and C. Chen, “An end-to-end learning approach for solving capacitated location-routing problems,” arXiv preprint arXiv:2511.02525, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Distance-aware attention reshaping for enhancing generalization of neural solvers,
Y . Wang, Y .-H. Jia, W.-N. Chen, and Y . Mei, “Distance-aware attention reshaping for enhancing generalization of neural solvers,”IEEE Trans- actions on Neural Networks and Learning Systems, 2025
2025
-
[37]
Sym-nco: Leveraging symmetricity for neural combinatorial optimization,
M. Kim, J. Park, and J. Park, “Sym-nco: Leveraging symmetricity for neural combinatorial optimization,”Advances in Neural Information Processing Systems, vol. 35, pp. 1936–1949, 2022
1936
-
[38]
Generalize learned heuristics to solve large-scale vehicle routing problems in real-time,
Q. Hou, J. Yang, Y . Su, X. Wang, and Y . Deng, “Generalize learned heuristics to solve large-scale vehicle routing problems in real-time,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[39]
Meta-sage: Scale meta-learning scheduled adaptation with guided exploration for mitigating scale shift on combinatorial optimization,
J. Son, M. Kim, H. Kim, and J. Park, “Meta-sage: Scale meta-learning scheduled adaptation with guided exploration for mitigating scale shift on combinatorial optimization,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 32 194–32 210
2023
-
[40]
Neural combinatorial optimization with heavy decoder: Toward large scale generalization,
F. Luo, X. Lin, F. Liu, Q. Zhang, and Z. Wang, “Neural combinatorial optimization with heavy decoder: Toward large scale generalization,” Advances in Neural Information Processing Systems, vol. 36, pp. 8845– 8864, 2023
2023
-
[41]
Bq- nco: Bisimulation quotienting for generalizable neural combinatorial optimization,
D. Drakulic, S. Michel, F. Mai, A. Sors, and J.-M. Andreoli, “Bq- nco: Bisimulation quotienting for generalizable neural combinatorial optimization,”Advances in Neural Information Processing Systems, 2023
2023
-
[42]
Multi-task learning for routing problem with cross-problem zero-shot generalization,
F. Liu, X. Lin, Z. Wang, Q. Zhang, T. Xialiang, and M. Yuan, “Multi-task learning for routing problem with cross-problem zero-shot generalization,” inProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 1898–1908
2024
-
[43]
Mvmoe: Multi-task vehicle routing solver with mixture-of-experts,
J. Zhou, Z. Cao, Y . Wu, W. Song, Y . Ma, J. Zhang, and C. Xu, “Mvmoe: Multi-task vehicle routing solver with mixture-of-experts,” in International Conference on Machine Learning. PMLR, 2024, pp. 61 804–61 824
2024
-
[44]
Adaptive mixtures of local experts,
R. A. Jacobs, M. I. Jordan, S. J. Nowlan, and G. E. Hinton, “Adaptive mixtures of local experts,”Neural Computation, vol. 3, no. 1, pp. 79–87, 1991
1991
-
[45]
Hierarchical mixtures of experts and the em algorithm,
M. I. Jordan and R. A. Jacobs, “Hierarchical mixtures of experts and the em algorithm,”Neural Computation, vol. 6, no. 2, pp. 181–214, 1994
1994
-
[46]
Outrageously large neural networks: The sparsely- gated mixture-of-experts layer,
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. V . Le, G. E. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely- gated mixture-of-experts layer,”International Conference on Learning Representations, 2017
2017
-
[47]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,”Journal of Machine Learning Research, vol. 23, no. 120, pp. 1–39, 2022
2022
-
[48]
Mixture-of-experts with expert choice routing,
Y . Zhou, T. Lei, H. Liu, N. Du, Y . Huang, V . Zhao, A. M. Dai, Q. V . Le, J. Laudonet al., “Mixture-of-experts with expert choice routing,” Advances in Neural Information Processing Systems, vol. 35, pp. 7103– 7114, 2022
2022
-
[49]
From sparse to soft mixtures of experts,
J. Puigcerver, C. Riquelme, B. Mustafa, and N. Houlsby, “From sparse to soft mixtures of experts,” inInternational Conference on Learning Representations, 2024
2024
-
[50]
2024.OpenMoE: An Early Effort on Open Mixture-of-Experts Lan- guage Models
F. Xue, Z. Zheng, Y . Fu, J. Ni, Z. Zheng, W. Zhou, and Y . You, “Open- moe: An early effort on open mixture-of-experts language models,” arXiv preprint arXiv:2402.01739, 2024
-
[51]
Base layers: Simplifying training of large, sparse models,
M. Lewis, S. Bhosale, T. Dettmers, N. Goyal, and L. Zettlemoyer, “Base layers: Simplifying training of large, sparse models,” inInternational Conference on Machine Learning. PMLR, 2021, pp. 6265–6274
2021
-
[52]
Evomoe: An evolutional mixture-of-experts training frame- work via dense-to-sparse gate,
X. Nie, X. Miao, S. Cao, L. Ma, Q. Liu, J. Xue, Y . Miao, Y . Liu, Z. Yang, and B. Cui, “Evomoe: An evolutional mixture-of-experts training frame- work via dense-to-sparse gate,”arXiv preprint arXiv:2112.14397, 2021
-
[53]
End-to-end object detection with transformers,
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in European Conference on Computer Vision. Springer, 2020, pp. 213– 229
2020
-
[54]
Speechmoe2: Mixture-of- experts model with improved routing,
Z. You, S. Feng, D. Su, and D. Yu, “Speechmoe2: Mixture-of- experts model with improved routing,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 7217–7221
2022
-
[55]
Multimodal contrastive learning with limoe: the language-image mix- ture of experts,
B. Mustafa, C. Riquelme, J. Puigcerver, R. Jenatton, and N. Houlsby, “Multimodal contrastive learning with limoe: the language-image mix- ture of experts,”Advances in Neural Information Processing Systems, vol. 35, pp. 9564–9576, 2022
2022
-
[56]
Twenty years of mixture of experts,
S. E. Yuksel, J. N. Wilson, and P. D. Gader, “Twenty years of mixture of experts,”IEEE Transactions on Neural Networks and Learning Systems, vol. 23, no. 8, pp. 1177–1193, 2012
2012
- [57]
-
[58]
No free lunch theorems for optimization,
D. H. Wolpert and W. G. Macready, “No free lunch theorems for optimization,”IEEE Transactions on Evolutionary Computation, vol. 1, no. 1, pp. 67–82, 2002
2002
-
[59]
Evolving diverse tsp instances by means of novel and creative mutation operators,
J. Bossek, P. Kerschke, A. Neumann, M. Wagner, F. Neumann, and H. Trautmann, “Evolving diverse tsp instances by means of novel and creative mutation operators,” inProceedings of the 15th ACM/SIGEVO Conference on Foundations of Genetic Algorithms, 2019, pp. 58–71
2019
-
[60]
Simple statistical gradient-following algorithms for connectionist reinforcement learning,
R. J. Williams, “Simple statistical gradient-following algorithms for connectionist reinforcement learning,”Machine Learning, vol. 8, no. 3, pp. 229–256, 1992
1992
-
[61]
An extension of the lin-kernighan-helsgaun tsp solver for constrained traveling salesman and vehicle routing problems,
K. Helsgaun, “An extension of the lin-kernighan-helsgaun tsp solver for constrained traveling salesman and vehicle routing problems,”Roskilde: Roskilde University, vol. 12, pp. 966–980, 2017
2017
-
[62]
Simulation-guided beam search for neural combinatorial optimization,
J. Choo, Y .-D. Kwon, J. Kim, J. Jae, A. Hottung, K. Tierney, and Y . Gwon, “Simulation-guided beam search for neural combinatorial optimization,”Advances in Neural Information Processing Systems, vol. 35, pp. 8760–8772, 2022
2022
-
[63]
Visualizing data using t-sne,
L. v. d. Maaten and G. Hinton, “Visualizing data using t-sne,”Journal of Machine Learning Research, vol. 9, no. Nov, pp. 2579–2605, 2008
2008
-
[64]
Multi-task reinforcement learning with soft modularization,
R. Yang, H. Xu, Y . Wu, and X. Wang, “Multi-task reinforcement learning with soft modularization,”Advances in Neural Information Processing Systems, vol. 33, pp. 4767–4777, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.