EviACT: An Evidence-to-Action Framework for Agentic Program Repair
Pith reviewed 2026-06-29 15:33 UTC · model grok-4.3
The pith
Coordinating retrieval, compile, and test evidence across stages raises agentic program repair resolve rates by 1.6-6 percentage points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
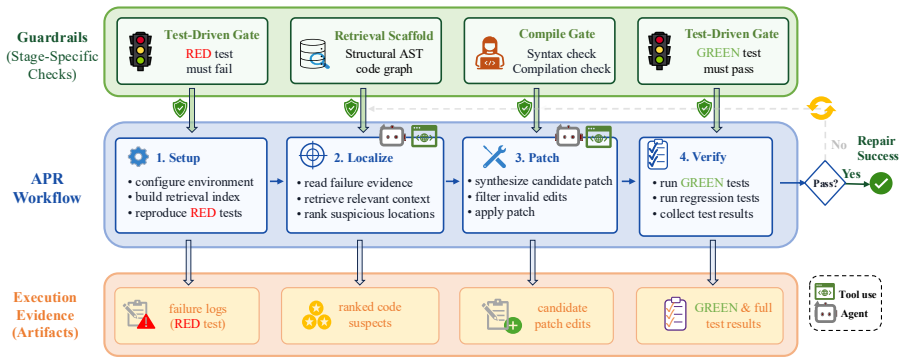
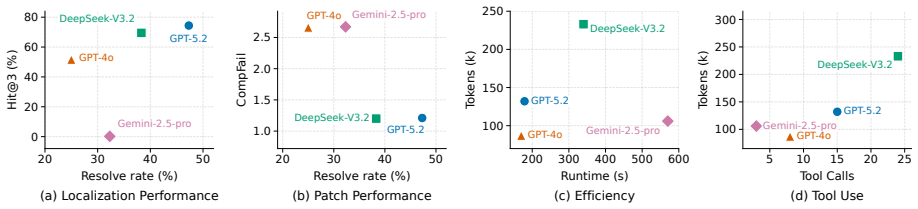
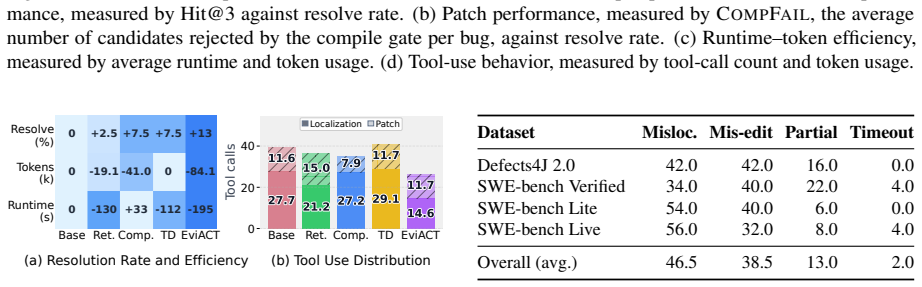
EviACT is an agentic APR framework that coordinates three evidence-driven guardrails across repair stages. The retrieval scaffold grounds repair context, the compile gate filters invalid edits, and the test-driven gate checks target-test recovery before full regression. Across four benchmarks, EviACT improves resolve rate over the strongest reported comparable baselines by 1.6-6.0 percentage points and shows 70.1-88.6% lower reported per-bug API cost where baseline costs are available. Ablations and diagnostics suggest that these gains are associated with the coordinated evidence-to-action chain, making agentic APR more effective and efficient.
What carries the argument
The evidence-to-action chain of three guardrails: retrieval scaffold for context, compile gate for validity, and test-driven gate for recovery.
If this is right
- Agentic systems can better localize bugs using grounded retrieval evidence.
- Invalid patches are filtered earlier by compile checks, saving resources.
- Target test recovery is verified before full regression testing.
- Overall resolve rates increase while API costs decrease on benchmarks.
- Agentic APR becomes more effective and efficient through coordinated evidence use.
Where Pith is reading between the lines
- The guardrail approach might apply to other agentic coding tasks such as feature addition or refactoring.
- Similar evidence coordination could reduce token usage in long-context agent interactions.
- Testing the framework on additional benchmarks or with different LLMs would further validate the chain's contribution.
- Adapting the gates for dynamic or non-deterministic environments could extend its use.
Load-bearing premise
The improvements are due to the coordinated evidence-to-action chain rather than differences in prompt design, model versions, or baseline implementations.
What would settle it
An experiment that fixes the underlying model, prompts, and baseline code while varying only the presence of the three guardrails and measures resolve rates and costs.
Figures


read the original abstract
LLM-based agents have moved automated program repair (APR) from fixed-context patch generation to interactive repository-level repair. However, existing agentic APR systems still struggle to use execution evidence to guide localization, patch generation, and validation. We propose EviACT (Evidence-to-Action), an agentic APR framework that coordinates three evidence-driven guardrails across repair stages. The retrieval scaffold grounds repair context, the compile gate filters invalid edits, and the test-driven gate checks target-test recovery before full regression. Across four benchmarks, EviACT improves resolve rate over the strongest reported comparable baselines by 1.6-6.0 percentage points and shows 70.1-88.6% lower reported per-bug API cost where baseline costs are available. Ablations and diagnostics suggest that these gains are associated with the coordinated evidence-to-action chain, making agentic APR more effective and efficient.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EviACT, an agentic APR framework that coordinates three evidence-driven guardrails (retrieval scaffold, compile gate, test-driven gate) across localization, patch generation, and validation stages. It reports that this yields 1.6-6.0 percentage point gains in resolve rate over the strongest reported comparable baselines across four benchmarks, together with 70.1-88.6% lower per-bug API cost where baselines report costs, and presents ablations and diagnostics as evidence that the gains are associated with the coordinated evidence-to-action chain.
Significance. If the reported deltas can be shown to arise from the proposed guardrails under controlled re-implementations, the work would supply a concrete coordination pattern that improves both effectiveness and efficiency in repository-level APR. The explicit use of ablations to link mechanism to outcome is a methodological strength that strengthens the contribution relative to purely empirical claims.
major comments (2)
- [§4 (Experimental Setup)] §4 (Experimental Setup) and the abstract: the manuscript does not state whether the 'strongest reported comparable baselines' were re-executed under identical conditions (same LLM backend and version, temperature/top-p, iteration budget, and prompt templates outside the new guardrails). Without this control the 1.6-6.0 pp resolve-rate claim cannot be attributed to the three guardrails rather than prompt or model differences.
- [§5 (Ablations)] Results tables and §5 (Ablations): no statistical significance tests, confidence intervals, or variance estimates are reported for the resolve-rate deltas across the four benchmarks; this is load-bearing for the cross-benchmark claim that the coordinated chain produces consistent gains.
minor comments (1)
- The abstract could briefly indicate the four benchmarks by name and the number of bugs per benchmark to allow readers to assess scope without consulting the full evaluation section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [§4 (Experimental Setup)] §4 (Experimental Setup) and the abstract: the manuscript does not state whether the 'strongest reported comparable baselines' were re-executed under identical conditions (same LLM backend and version, temperature/top-p, iteration budget, and prompt templates outside the new guardrails). Without this control the 1.6-6.0 pp resolve-rate claim cannot be attributed to the three guardrails rather than prompt or model differences.
Authors: We acknowledge the point. The abstract and evaluation explicitly compare against the strongest reported results from the literature rather than re-executions under matched conditions. The manuscript therefore does not control for LLM backend, temperature, prompt templates, or iteration budget, and the observed deltas cannot be attributed solely to the guardrails. We will revise the abstract and §4 to state this limitation explicitly and to qualify the claims accordingly. revision: yes
-
Referee: [§5 (Ablations)] Results tables and §5 (Ablations): no statistical significance tests, confidence intervals, or variance estimates are reported for the resolve-rate deltas across the four benchmarks; this is load-bearing for the cross-benchmark claim that the coordinated chain produces consistent gains.
Authors: We agree that the lack of statistical tests weakens the cross-benchmark claims. In the revision we will add bootstrap confidence intervals for the resolve-rate deltas and, where sample sizes permit, paired significance tests (e.g., McNemar’s test) to supply variance estimates and assess consistency of the gains. revision: yes
Circularity Check
No circularity in empirical evaluation chain
full rationale
The manuscript presents an empirical framework (EviACT) with three guardrails evaluated on four benchmarks via resolve-rate and cost metrics against external baselines, plus ablations. No derivation chain, equations, fitted parameters presented as predictions, or self-citation load-bearing steps appear in the abstract or described content. Central claims rest on direct benchmark comparisons rather than any reduction to self-defined inputs or prior author results by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yiwei Hu, Zhen Liu, Kedie Shu, Shenghua Guan, De- qing Zou, Shouhuai Xu, Bin Yuan, and Hai Jin
Tdflow: Agentic workflows for test driven soft- ware engineering.arXiv e-prints, pages arXiv–2510. Yiwei Hu, Zhen Liu, Kedie Shu, Shenghua Guan, De- qing Zou, Shouhuai Xu, Bin Yuan, and Hai Jin. 2025. {SoK}: Automated vulnerability repair: Methods, tools, and assessments. In34th USENIX Security Symposium (USENIX Security 25), pages 4421–4440. 9 Carlos E J...
-
[2]
Trident: Controlling side effects in automated program repair.IEEE Transactions on Software En- gineering, 48(12):4717–4732. Qwen Team. 2024. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115. Haifeng Ruan, Yuntong Zhang, and Abhik Roychoud- hury. 2024. Specrover: Code intent extraction via llms.arXiv preprint arXiv:2408.02232. Xunzhu Tang, Jiechao...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Setup: check out the buggy revision and prepare the environment
-
[4]
RED: run the originally failing target test and collect failure evidence
-
[5]
Localize: use RED evidence and the repository index to identify suspicious files, symbols, and line ranges
-
[6]
Patch: generate one minimal candidate edit over the localized working set
-
[7]
Compile: apply the edit and run syntax or build checks
-
[8]
GREEN: rerun the originally failing target test and require it to pass
-
[9]
When asked to localize, output only the requested localization JSON
Validate: run full regression validation before accepting the patch. When asked to localize, output only the requested localization JSON. When asked to patch, output only the requested edit JSON or unified diff. Do not include explanations unless explicitly requested by the controller. B.2 Localization Prompt Localization Prompt Goal: localize the bug usi...
-
[10]
Read the RED log first
-
[11]
Extract the failing test, assertion or exception message, and relevant stack frames
-
[12]
Derive primary symbols from stack frames, test names, assertion text, and error messages
-
[13]
Query the repository index using symbol lookup before textual search
-
[14]
Read matched AST spans before selecting suspects
-
[15]
Inspect caller, callee, import, inheritance, or reference spans only when they are structurally connected to the RED evidence
-
[16]
red_test
Keep the working set small and evidence-grounded. Output only valid JSON in the following schema: { "red_test": "name of the failing target test", "red_failure_summary": "one-sentence failure summary", "failure_contract": [ "behavior that should hold but is violated" ], "primary_symbols": [ "symbol names derived from RED evidence" ], "suspects": [ { "file...
-
[17]
Patch only files that are supported by the suspect spans unless additional context is necessary
-
[18]
Preserve unrelated behavior and avoid broad rewrites
-
[19]
Do not hardcode behavior only for the observed failing test
-
[20]
Ensure that the edit applies cleanly and preserves syntax
-
[21]
path": "relative/path/to/file
If the previous candidate failed to apply, compile, or pass GREEN, use the diagnostic context to revise only the relevant part of the patch. Output only valid JSON in the following schema: [ { "path": "relative/path/to/file", "ops": [ { "type": "replace", "start_line": 10, "end_line": 12, "text": "replacement code with preserved indentation\n" } ] } ] The...
2024
-
[22]
Setup Process:Run test suite Process:Run test suite Output:test.trigger.log Output:red.log [TD RED]
-
[23]
Exception
Localize Process: •Read log file •Search for "Exception" keyword •Read MappingIterator.java Process: •Readred.log [TD RED] •Lookup ObjectMapper#setDateFormat • Read span of BaseSettings.java [Retrieval] Output: Located file: MappingIterator.java× Output: Located file: BaseSettings.java✓ API calls: 11, Tokens: 35.4K API calls: 6, Tokens: 20.6K
-
[24]
Patch Process: •Read MappingIterator.java •Generate 1 attempt •Generate 2 attempt •Generate 3 attempt •Generate 4 attempt •... Process: • Read span of TestConfig.java and BaseSettings.java [Retrieval] •Generate 1 patch •Compile check [Compile] •Verify withgreen.log [TD GREEN] Output:19 attempts Output:1 attempt, success API calls: 20, Tokens: 203.9K, Comp...
-
[25]
Verify Process: •Run full test suite •19 failures remain Process: •Run full test suite •All tests passed Output:Result: Failed, Time: 1129s, Total tokens: 239.3K Output:Result: Success, Time: 153.6s, Total tokens: 50.9K 16
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.